We all know synchronized Keywords can achieve thread safety , But do you know the principle behind it ? Today we will talk about synchronized The reason behind thread synchronization , And related lock optimization strategies .
synchronized The principle behind it
synchronized Keywords are compiled , Will be formed before and after the synchronized block monitorenter and monitorexit These two bytecode instructions , These two bytecodes only need one to indicate an object to be locked or unlocked . If Java Object parameters are specified in the program , Then use this object as a lock .
If not specified , So based on synchronized Is it an instance method or a class method , Get the corresponding object instance or Class Object as the lock object . So we can know ,synchronized Keyword behind thread synchronization , It's actually Java Virtual machine specification for monitorenter and monitorexit The definition of .
stay Java Virtual machine specification for monitorenter and monitorexit Behavior description of , There are two points to note .
- synchronized Synchronization blocks are reentrant to the same thread , That is, there will be no problem of locking yourself up .
- The synchronization block is executed before the thread that has entered , It will block the entry of other threads .
synchronized The key word in JDK1.6 Before the release , Through the operating system Mutex Lock To achieve synchronization . And the operating system Mutex Lock Is an operating system level approach , You need to switch to kernel mode to execute . This requires a transition from user mode to kernel mode , So we say synchronized Synchronization is a heavyweight operation .
synchronized Lock the optimization
stay JDK1.6 In the version ,HotSpot The virtual machine development team has spent a lot of energy to implement various lock optimization technologies , Such as : Adaptive spin 、 Lock elimination 、 Lock foul language 、 Biased locking 、 Lightweight locks, etc . The most important one is : spinlocks 、 Lightweight lock 、 Bias lock these three , We will focus on these three lock optimizations .
Spin lock and adaptive spin
For heavyweight synchronous operations , The biggest consumption is actually the switching between kernel state and user state . But a lot of times , The operation time for sharing data may be very short , It takes less time than switching from kernel mode to user mode .
So someone thought : If there are multiple threads to acquire locks concurrently , If you can make the thread that requests the lock later 「 Wait a moment 」, Don't give up CPU Execution time of , See if the thread holding the lock will release the lock soon . To keep the thread waiting , We just need to let the thread execute a busy loop ( The spin ), This technology is called spin lock . In theory , If all threads acquire locks quickly 、 Release the lock , Then spin lock can bring great performance improvement . Spin locked in JDK 1.4.2 We have introduced , Default spin 10 Time . But the spin lock is off by default , stay JDK 1.6 It was changed to be enabled by default .
Spin waiting avoids the overhead of thread switching , But it still takes up processor time . If the lock is occupied for a period of time , The spin wait effect will be very good . But if the lock is occupied for a long time , Then the spinning thread will consume the processor resources in vain , This leads to a waste of performance .
In order to solve the performance consumption problem of spin lock in special cases , stay JDK1.6 The self-adaptive spin lock is introduced . Adaptive means that the spin time is no longer fixed , It is determined by the previous spin time on the same lock and the state of the lock owner . If on the same lock object , Spin wait has just successfully acquired a lock , Then the virtual machine thinks that this spin is likely to succeed again , This allows the thread to spin longer , For example, spin 100 Cycle .
But if for a lock , Spin is rarely successful . That virtual machine in order to avoid waste CPU resources , It is possible to omit the spin process . With spin lock , With the continuous improvement of program operation and performance monitoring information , The more accurate the virtual machine predicts the state of the lock , Virtual machines will also become smarter .
Lightweight lock
Lightweight locks are JDK1.6 New locking mechanism added , In the name 「 Lightweight 」 Is relative to the operating system Mutex this heavyweight lock . The reason for the birth of lightweight locks , Because for most locks , There is no competition throughout the synchronization cycle . If there is no competition , Then there is no need to use heavyweight locks , So a lightweight lock was born to improve efficiency .
For lightweight locks , The synchronization process is as follows :
- When the code enters the synchronized block , If the synchronization object is not locked ( The lock flag bit is 01 state ), Then the virtual opportunity creates a record called lock in the stack frame of the current thread (Lock Record) Space , Used to store the current lock object Mark Word Copy .
- The virtual machine will be used CAS The operation attempt will object Mark Word Update to point Lock Record The pointer to . If the update action succeeds , Then the thread will lock the object , And object Mark Word The lock flag of becomes 00, Indicates that the object is in a lightweight locked state .
In short , The synchronization process of lightweight locks can be summarized as : Use CAS operation , Establish a bidirectional pointer between the process stack frame and the lock object .
Without thread contention , Lightweight lock usage CAS Spin operation avoids the overhead of using mutexes , Improved efficiency . But if there is lock competition , In addition to the overhead of the mutex , And then something extra happened CAS operation . So in the case of competition , Lightweight locks are slower than traditional heavyweight locks .
Biased locking
Bias lock is JDK1.6 An optimization introduced in , It means that the lock will be biased towards the first thread to acquire it . If in the following execution , The lock was not acquired by other threads , Threads holding biased locks will never need to be synchronized again . For deflection lock , The synchronization process is as follows :
- Suppose that the current virtual machine starts the bias lock , So when the lock object is first acquired by the thread , The virtual machine will set the lock flag of the object to 01, The bias lock is set to 1. Use at the same time CAS Operation will thread ID Record in object MarkWord In . If CAS Successful operation , When the thread holding the biased lock enters the synchronization block corresponding to the lock , The virtual machine will no longer perform any synchronization operations .
- When another thread tries to acquire the lock , Depending on whether the lock object is currently in a locked state , Restore it to unlocked (01) Or lightweight locking (00) state . Subsequent synchronization , Just execute like the lightweight lock introduced above .
You can see that the deflection lock still needs to be done CAS operation , But compared with lightweight locks , The content to be set is greatly reduced , Therefore, it also improves some efficiency . Biased locking can improve program performance with synchronization but no competition . It's also a trade-off with benefits (Trade Off) Optimization of properties , in other words , It's not always good for the program to run , If most locks in a program are always accessed by multiple different threads , That biased pattern is redundant .
Optimized lock acquisition process
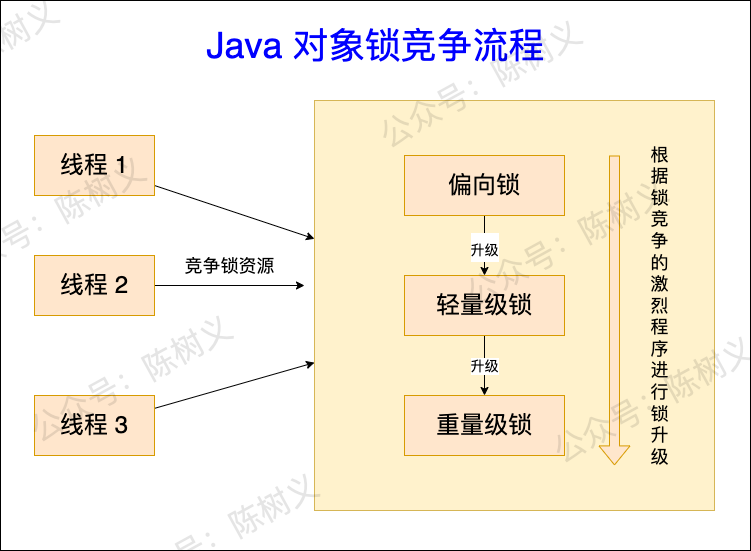
after JDK1.6 The optimization of the ,synchronized The process of synchronization mechanism becomes :
- First ,synchronized They will try to compete for lock resources in a lock biased way , If you can compete for the biased lock , It indicates that the locking is successful and returns directly .
- If the contention lock fails , This indicates that the current lock has been biased to other threads . You need to upgrade the lock to a lightweight lock , In the lightweight lock state , Threads competing for locks attempt to preempt lock resources according to the number of adaptive spins .
- If there is no competition for the lock in the lightweight lock state , You can only upgrade to the heavyweight lock . In the heavyweight lock state , Threads that do not compete for locks are blocked . The thread in the lock waiting state needs to wait for the thread that obtains the lock to trigger the wake-up .
The lock acquisition process above , It can be represented by the following schematic diagram :
summary
This article first briefly explains synchronized The principle of keyword synchronization , Actually by Java Virtual machine specification for monitorenter and monitorexit Support for , Thus making synchronized Can realize synchronization . and synchronized Synchronization is essentially through the operating system mutex Lock to achieve . Due to the operating system mutex Locks consume too much resources , So in JDK1.6 after HotSpot The virtual machine has done a series of lock optimization , The most important of all is : spinlocks 、 Lightweight lock 、 Biased locking . The reasons for the birth of these three locks , And the points of improvement are shown in the table below .
| present situation | Lock name | earnings | Use scenarios |
|---|---|---|---|
| Most of the time , It takes longer to wait for the lock than the operating system mutex It's much shorter | spinlocks | Reduce the overhead of switching between kernel mode and user mode | When a thread takes a short time to acquire a lock |
| Most of the time , There is no thread contention during lock synchronization | Lightweight lock | Compared with spin lock , Reduced spin time | No threads compete for locks |
| Most of the time , There is no thread contention during lock synchronization | Biased locking | Compared with lightweight locks , Reduce redundant object replication operations | No threads compete for locks |
You can see from the table above , spinlocks 、 Lightweight lock 、 Biased locking , Their optimization is gradually deepened .
- For heavyweight locks , Spin lock reduces the mutex of the kernel 、 User mode switching overhead .
- Lightweight lock , It's spin lock again Java Direct application in memory model , It also reduces the switching overhead between kernel state and user state .
- Biased locking , Compared with lightweight locks , Reduce redundant object replication operations , So it's more efficient .
Reference material
- In depth understanding of Java virtual machine :JVM Advanced features and best practices ( The first 2 edition )- Zhi-ming zhou - WeChat reading
- 【Java interview 】 Why introduce bias lock 、 Lightweight lock , Introduce the upgrade process - follow Mic Learning structure - Blog Garden
- I can't help saying that Java “ lock ” things - Meituan technical team
](/img/dc/5c8077c10cdc7ad6e6f92dedfbe797.png)