当前位置:网站首页>Financial risk control practice -- feature derivation based on time series
Financial risk control practice -- feature derivation based on time series
2022-07-05 06:28:00 【Grateful_ Dead424】
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")I wrote it for you 35 A function , Let's look at it one by one
# lately p Months ,inv>0 Number of months
def Num(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.where(df>0,1,0).sum(axis=1)
return inv+'_num'+str(p),auto_value
# lately p Months ,inv=0 Number of months
def Nmz(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.where(df==0,1,0).sum(axis=1)
return inv+'_nmz'+str(p),auto_value
# lately p Months ,inv>0 Is the number of months >=1
def Evr(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
arr=np.where(df>0,1,0).sum(axis=1)
auto_value = np.where(arr,1,0)
return inv+'_evr'+str(p),auto_value
# lately p Months ,inv mean value
def Avg(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.nanmean(df,axis = 1 )
return inv+'_avg'+str(p),auto_value
# lately p Months ,inv and
def Tot(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.nansum(df,axis = 1)
return inv+'_tot'+str(p),auto_value
# lately (2,p+1) Months ,inv and
def Tot2T(inv,p):
df=data.loc[:,inv+'2':inv+str(p+1)]
auto_value=df.sum(1)
return inv+'_tot2t'+str(p),auto_value
# lately p Months ,inv Maximum
def Max(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.nanmax(df,axis = 1)
return inv+'_max'+str(p),auto_value
# lately p Months ,inv minimum value
def Min(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.nanmin(df,axis = 1)
return inv+'_min'+str(p),auto_value
# lately p Months , The last time inv>0 The number of months to now
def Msg(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
df_value=np.where(df>0,1,0)
auto_value=[]
for i in range(len(df_value)):
row_value=df_value[i,:]
if row_value.max()<=0:
indexs='0'
auto_value.append(indexs)
else:
indexs=1
for j in row_value:
if j>0:
break
indexs+=1
auto_value.append(indexs)
return inv+'_msg'+str(p),auto_value
# lately p Months , The last time inv=0 The number of months to now
def Msz(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
df_value=np.where(df==0,1,0)
auto_value=[]
for i in range(len(df_value)):
row_value=df_value[i,:]
if row_value.max()<=0:
indexs='0'
auto_value.append(indexs)
else:
indexs=1
for j in row_value:
if j>0:
break
indexs+=1
auto_value.append(indexs)
return inv+'_msz'+str(p),auto_value
# During the month inv/( lately p Months inv The average of )
def Cav(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = df[inv+'1']/np.nanmean(df,axis = 1 )
return inv+'_cav'+str(p),auto_value
# During the month inv/( lately p Months inv The minimum value of )
def Cmn(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = df[inv+'1']/np.nanmin(df,axis = 1 )
return inv+'_cmn'+str(p),auto_value
# lately p Months , Every two months inv The maximum growth of
def Mai(inv,p):
arr=np.array(data.loc[:,inv+'1':inv+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
auto_value.append(np.nanmax(value_lst))
return inv+'_mai'+str(p),auto_value
# lately p Months , Every two months inv The maximum reduction of
def Mad(inv,p):
arr=np.array(data.loc[:,inv+'1':inv+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k+1] - df_value[k]
value_lst.append(minus)
auto_value.append(np.nanmax(value_lst))
return inv+'_mad'+str(p),auto_value
# lately p Months ,inv Standard deviation
def Std(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.nanstd(df,axis = 1)
return inv+'_std'+str(p),auto_value
# lately p Months ,inv The coefficient of variation of
def Cva(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value=np.nanstd(df,axis = 1 )/np.nanmean(df,axis = 1)
return inv+'_cva'+str(p),auto_value
#( During the month inv) - ( lately p Months inv The average of )
def Cmm(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = df[inv+'1'] - np.nanmean(df,axis = 1 )
return inv+'_cmm'+str(p),auto_value
#( During the month inv) - ( lately p Months inv The minimum value of )
def Cnm(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = df[inv+'1'] - np.nanmin(df,axis = 1 )
return inv+'_cnm'+str(p),auto_value
#( During the month inv) - ( lately p Months inv The maximum of )
def Cxm(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = df[inv+'1'] - np.nanmax(df,axis = 1 )
return inv+'_cxm'+str(p),auto_value
#( ( During the month inv) - ( lately p Months inv The maximum of ) ) / ( lately p Months inv The maximum of ) )
def Cxp(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
temp = np.nanmin(df,axis = 1 )
auto_value = (df[inv+'1'] - temp )/ temp
return inv+'_cxp'+str(p),auto_value
# lately p Months ,inv It's very bad
def Ran(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = np.nanmax(df,axis = 1 ) - np.nanmin(df,axis = 1 )
return inv+'_ran'+str(p),auto_value
# lately min( Time on book,p ) Months , The number of months increased in the latter month compared with the previous month
def Nci(inv,p):
arr=np.array(data.loc[:,inv+'1':inv+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
value_ng = np.where(np.array(value_lst)>0,1,0).sum()
auto_value.append(np.nanmax(value_ng))
return inv+'_nci'+str(p),auto_value
# lately min( Time on book,p ) Months , The number of months decreased in the latter month compared with the previous month
def Ncd(inv,p):
arr=np.array(data.loc[:,inv+'1':inv+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
value_ng = np.where(np.array(value_lst)<0,1,0).sum()
auto_value.append(np.nanmax(value_ng))
return inv+'_ncd'+str(p),auto_value
# lately min( Time on book,p ) Months , Adjacent months inv Equal number of months
def Ncn(inv,p):
arr=np.array(data.loc[:,inv+'1':inv+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
value_ng = np.where(np.array(value_lst)==0,1,0).sum()
auto_value.append(np.nanmax(value_ng))
return inv+'_ncn'+str(p),auto_value
#If lately min( Time on book,p ) Months , For any month i , There are inv[i] > inv[i+1] ,
# Strictly increasing , And inv > 0 be flag = 1 Else flag = 0
def Bup(inv,p):
arr=np.array(data.loc[:,inv+'1':inv+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
index = 0
for k in range(len(df_value)-1):
if df_value[k] > df_value[k+1]:
break
index =+ 1
if index == p:
value= 1
else:
value = 0
auto_value.append(value)
return inv+'_bup'+str(p),auto_value
#If lately min( Time on book,p ) Months , For any month i , There are inv[i] < inv[i+1] ,
# Strictly decreasing , And inv > 0 be flag = 1 Else flag = 0
def Pdn(inv,p):
arr=np.array(data.loc[:,inv+'1':inv+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
index = 0
for k in range(len(df_value)-1):
if df_value[k+1] > df_value[k]:
break
index =+ 1
if index == p:
value= 1
else:
value = 0
auto_value.append(value)
return inv+'_pdn'+str(p),auto_value
# lately min( Time on book,p ) Months ,inv Pruning average of
def Trm(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = []
for i in range(len(df)):
trm_mean = list(df.loc[i,:])
trm_mean.remove(np.nanmax(trm_mean))
trm_mean.remove(np.nanmin(trm_mean))
temp=np.nanmean(trm_mean)
auto_value.append(temp)
return inv+'_trm'+str(p),auto_value
#( During the month inv - lately p Months inv Maximum ) / lately p Months inv Maximum of
def Cmx(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = (df[inv+'1'] - np.nanmax(df,axis = 1 )) /np.nanmax(df,axis = 1 )
return inv+'_cmx'+str(p),auto_value
#( During the month inv - lately p Months inv mean value ) / inv mean value
def Cmp(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = (df[inv+'1'] - np.nanmean(df,axis = 1 )) /np.nanmean(df,axis = 1 )
return inv+'_cmp'+str(p),auto_value
#( During the month inv - lately p Months inv minimum value ) /inv minimum value
def Cnp(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
auto_value = (df[inv+'1'] - np.nanmin(df,axis = 1 )) /np.nanmin(df,axis = 1 )
return inv+'_cnp'+str(p),auto_value
# lately min( Time on book,p ) The number of months from the current month with the maximum value of months
def Msx(inv,p):
df=data.loc[:,inv+'1':inv+str(p)]
df['_max'] = np.nanmax(df,axis = 1)
for i in range(1,p+1):
df[inv+str(i)] = list(df[inv+str(i)] == df['_max'])
del df['_max']
df_value = np.where(df==True,1,0)
auto_value=[]
for i in range(len(df_value)):
row_value=df_value[i,:]
indexs=1
for j in row_value:
if j == 1:
break
indexs+=1
auto_value.append(indexs)
return inv+'_msx'+str(p),auto_value
# lately p The average of months /((p,2p) Months inv mean value )
def Rpp(inv,p):
df1=data.loc[:,inv+'1':inv+str(p)]
value1=np.nanmean(df1,axis = 1 )
df2=data.loc[:,inv+str(p):inv+str(2*p)]
value2=np.nanmean(df2,axis = 1 )
auto_value = value1/value2
return inv+'_rpp'+str(p),auto_value
# lately p The average of months - ((p,2p) Months inv mean value )
def Dpp(inv,p):
df1=data.loc[:,inv+'1':inv+str(p)]
value1=np.nanmean(df1,axis = 1 )
df2=data.loc[:,inv+str(p):inv+str(2*p)]
value2=np.nanmean(df2,axis = 1 )
auto_value = value1 - value2
return inv+'_dpp'+str(p),auto_value
#( lately p Months inv Maximum )/ ( lately (p,2p) Months inv Maximum )
def Mpp(inv,p):
df1=data.loc[:,inv+'1':inv+str(p)]
value1=np.nanmax(df1,axis = 1 )
df2=data.loc[:,inv+str(p):inv+str(2*p)]
value2=np.nanmax(df2,axis = 1 )
auto_value = value1/value2
return inv+'_mpp'+str(p),auto_value
#( lately p Months inv minimum value )/ ( lately (p,2p) Months inv minimum value )
def Npp(inv,p):
df1=data.loc[:,inv+'1':inv+str(p)]
value1=np.nanmin(df1,axis = 1 )
df2=data.loc[:,inv+str(p):inv+str(2*p)]
value2=np.nanmin(df2,axis = 1 )
auto_value = value1/value2
return inv+'_npp'+str(p),auto_value Let's define a function , Directly encapsulate all the above functions
# First, execute all the following functions
# Define functions that call two parameters in batches
def auto_var2(inv,p):
#global data_new
try:
columns_name,values=Num(inv,p)
data_new[columns_name]=values
except:
print("Num PARSE ERROR",inv,p)
try:
columns_name,values=Nmz(inv,p)
data_new[columns_name]=values
except:
print("Nmz PARSE ERROR",inv,p)
try:
columns_name,values=Evr(inv,p)
data_new[columns_name]=values
except:
print("Evr PARSE ERROR",inv,p)
try:
columns_name,values=Avg(inv,p)
data_new[columns_name]=values
except:
print("Avg PARSE ERROR",inv,p)
try:
columns_name,values=Tot(inv,p)
data_new[columns_name]=values
except:
print("Tot PARSE ERROR",inv,p)
try:
columns_name,values=Tot2T(inv,p)
data_new[columns_name]=values
except:
print("Tot2T PARSE ERROR",inv,p)
try:
columns_name,values=Max(inv,p)
data_new[columns_name]=values
except:
print("Max PARSE ERROR",inv,p)
try:
columns_name,values=Min(inv,p)
data_new[columns_name]=values
except:
print("Min PARSE ERROR",inv,p)
try:
columns_name,values=Msg(inv,p)
data_new[columns_name]=values
except:
print("Msg PARSE ERROR",inv,p)
try:
columns_name,values=Msz(inv,p)
data_new[columns_name]=values
except:
print("Msz PARSE ERROR",inv,p)
try:
columns_name,values=Cav(inv,p)
data_new[columns_name]=values
except:
print("Cav PARSE ERROR",inv,p)
try:
columns_name,values=Cmn(inv,p)
data_new[columns_name]=values
except:
print("Cmn PARSE ERROR",inv,p)
try:
columns_name,values=Mai(inv,p)
data_new[columns_name]=values
except:
print("Mai PARSE ERROR",inv,p)
try:
columns_name,values=Mad(inv,p)
data_new[columns_name]=values
except:
print("Mad PARSE ERROR",inv,p)
try:
columns_name,values=Std(inv,p)
data_new[columns_name]=values
except:
print("Std PARSE ERROR",inv,p)
try:
columns_name,values=Cva(inv,p)
data_new[columns_name]=values
except:
print("Cva PARSE ERROR",inv,p)
try:
columns_name,values=Cmm(inv,p)
data_new[columns_name]=values
except:
print("Cmm PARSE ERROR",inv,p)
try:
columns_name,values=Cnm(inv,p)
data_new[columns_name]=values
except:
print("Cnm PARSE ERROR",inv,p)
try:
columns_name,values=Cxm(inv,p)
data_new[columns_name]=values
except:
print("Cxm PARSE ERROR",inv,p)
try:
columns_name,values=Cxp(inv,p)
data_new[columns_name]=values
except:
print("Cxp PARSE ERROR",inv,p)
try:
columns_name,values=Ran(inv,p)
data_new[columns_name]=values
except:
print("Ran PARSE ERROR",inv,p)
try:
columns_name,values=Nci(inv,p)
data_new[columns_name]=values
except:
print("Nci PARSE ERROR",inv,p)
try:
columns_name,values=Ncd(inv,p)
data_new[columns_name]=values
except:
print("Ncd PARSE ERROR",inv,p)
try:
columns_name,values=Ncn(inv,p)
data_new[columns_name]=values
except:
print("Ncn PARSE ERROR",inv,p)
try:
columns_name,values=Bup(inv,p)
data_new[columns_name]=values
except:
print("Bup PARSE ERROR",inv,p)
try:
columns_name,values=Pdn(inv,p)
data_new[columns_name]=values
except:
print("Pdn PARSE ERROR",inv,p)
try:
columns_name,values=Trm(inv,p)
data_new[columns_name]=values
except:
print("Trm PARSE ERROR",inv,p)
try:
columns_name,values=Cmx(inv,p)
data_new[columns_name]=values
except:
print("Cmx PARSE ERROR",inv,p)
try:
columns_name,values=Cmp(inv,p)
data_new[columns_name]=values
except:
print("Cmp PARSE ERROR",inv,p)
try:
columns_name,values=Cnp(inv,p)
data_new[columns_name]=values
except:
print("Cnp PARSE ERROR",inv,p)
try:
columns_name,values=Msx(inv,p)
data_new[columns_name]=values
except:
print("Msx PARSE ERROR",inv,p)
try:
columns_name,values=Rpp(inv,p)
data_new[columns_name]=values
except:
print("Rpp PARSE ERROR",inv,p)
try:
columns_name,values=Dpp(inv,p)
data_new[columns_name]=values
except:
print("Dpp PARSE ERROR",inv,p)
try:
columns_name,values=Mpp(inv,p)
data_new[columns_name]=values
except:
print("Mpp PARSE ERROR",inv,p)
try:
columns_name,values=Npp(inv,p)
data_new[columns_name]=values
except:
print("Npp PARSE ERROR",inv,p)
return data_new.columns.sizeThen we use a small demo Let's experiment
import pandas as pd
#data It is the original data set with features and labels
data = pd.read_excel('/Users/zhucan/Desktop/ Financial risk control practice / Lesson 3 materials /textdata.xlsx')
data
""" ft and gt Represents two variable names 1-12 Indicates correspondence 12 The corresponding value for each month of the month """
'''ft1 refer to The number of refuelling times calculated from the data within one month from the day of application '''
'''gt1 refer to The refueling amount calculated from the data within one month from the day of application '''
data.columns
#Index(['customer_id', 'ft1', 'ft2', 'ft3', 'ft4', 'ft5', 'ft6', 'ft7', 'ft8',
# 'ft9', 'ft10', 'ft11', 'ft12', 'TOB', 'gt1', 'gt2', 'gt3', 'gt4', 'gt5',
# 'gt6', 'gt7', 'gt8', 'gt9', 'gt10', 'gt11', 'gt12'],
# dtype='object')data_new = data.copy()
p = 4
inv = 'ft'
auto_data = pd.DataFrame()
for p in range(1,13):
for inv in ['ft','gt']:
auto_var2(inv,p)
# Mai PARSE ERROR ft 1
# Mad PARSE ERROR ft 1
# Trm PARSE ERROR ft 1
# Mai PARSE ERROR gt 1
# Mad PARSE ERROR gt 1
# Trm PARSE ERROR gt 1
# Trm PARSE ERROR ft 2
# Trm PARSE ERROR gt 2
# Rpp PARSE ERROR ft 7
# Dpp PARSE ERROR ft 7
# Mpp PARSE ERROR ft 7
# Npp PARSE ERROR ft 7
# Rpp PARSE ERROR gt 7
# Dpp PARSE ERROR gt 7
# Mpp PARSE ERROR gt 7
# Npp PARSE ERROR gt 7
# Rpp PARSE ERROR ft 8
# Dpp PARSE ERROR ft 8
# Mpp PARSE ERROR ft 8
# Npp PARSE ERROR ft 8
# Rpp PARSE ERROR gt 8
# Dpp PARSE ERROR gt 8
# Mpp PARSE ERROR gt 8
# Npp PARSE ERROR gt 8
# Rpp PARSE ERROR ft 9
# Dpp PARSE ERROR ft 9
# Mpp PARSE ERROR ft 9
# Npp PARSE ERROR ft 9
# Rpp PARSE ERROR gt 9
# Dpp PARSE ERROR gt 9
# Mpp PARSE ERROR gt 9
# Npp PARSE ERROR gt 9
# Rpp PARSE ERROR ft 10
# Dpp PARSE ERROR ft 10
# Mpp PARSE ERROR ft 10
# Npp PARSE ERROR ft 10
# Rpp PARSE ERROR gt 10
# Dpp PARSE ERROR gt 10
# Mpp PARSE ERROR gt 10
# Npp PARSE ERROR gt 10
# Rpp PARSE ERROR ft 11
# Dpp PARSE ERROR ft 11
# Mpp PARSE ERROR ft 11
# Npp PARSE ERROR ft 11
# Rpp PARSE ERROR gt 11
# Dpp PARSE ERROR gt 11
# Mpp PARSE ERROR gt 11
# Npp PARSE ERROR gt 11
# Tot2T PARSE ERROR ft 12
# Rpp PARSE ERROR ft 12
# Dpp PARSE ERROR ft 12
# Mpp PARSE ERROR ft 12
# Npp PARSE ERROR ft 12
# Tot2T PARSE ERROR gt 12
# Rpp PARSE ERROR gt 12
# Dpp PARSE ERROR gt 12
# Mpp PARSE ERROR gt 12
# Npp PARSE ERROR gt 12data_new.shape
#(5, 808)
data_new.columns
#Index(['customer_id', 'ft1', 'ft2', 'ft3', 'ft4', 'ft5', 'ft6', 'ft7', 'ft8',
# 'ft9',
# ...
# 'gt_nci12', 'gt_ncd12', 'gt_ncn12', 'gt_bup12', 'gt_pdn12', 'gt_trm12',
# 'gt_cmx12', 'gt_cmp12', 'gt_cnp12', 'gt_msx12'],
# dtype='object', length=808)
边栏推荐
- Network security skills competition in Secondary Vocational Schools -- a tutorial article on middleware penetration testing in Guangxi regional competition
- C Primer Plus Chapter 15 (bit operation)
- Redis-01.初识Redis
- Sum of three terms (construction)
- [2020]GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
- 高斯消元 AcWing 884. 高斯消元解异或線性方程組
- Game theory acwing 894 Split Nim game
- How to make water ripple effect? This wave of water ripple effect pulls full of retro feeling
- Chinese remainder theorem acwing 204 Strange way of expressing integers
- 如何正确在CSDN问答进行提问
猜你喜欢
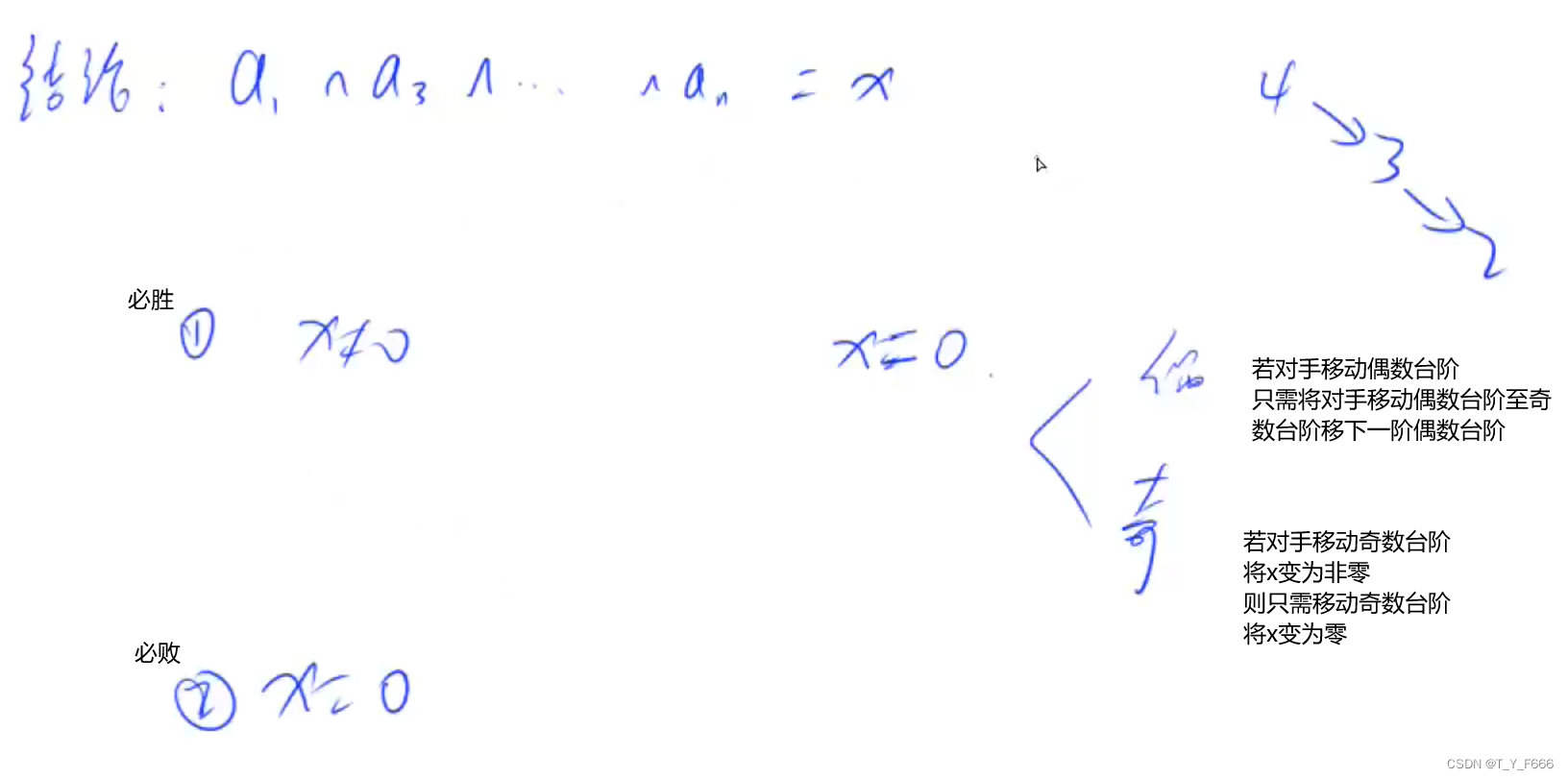
Game theory acwing 892 Steps Nim game
Record of problems in ollvm compilation

Genesis builds a new generation of credit system
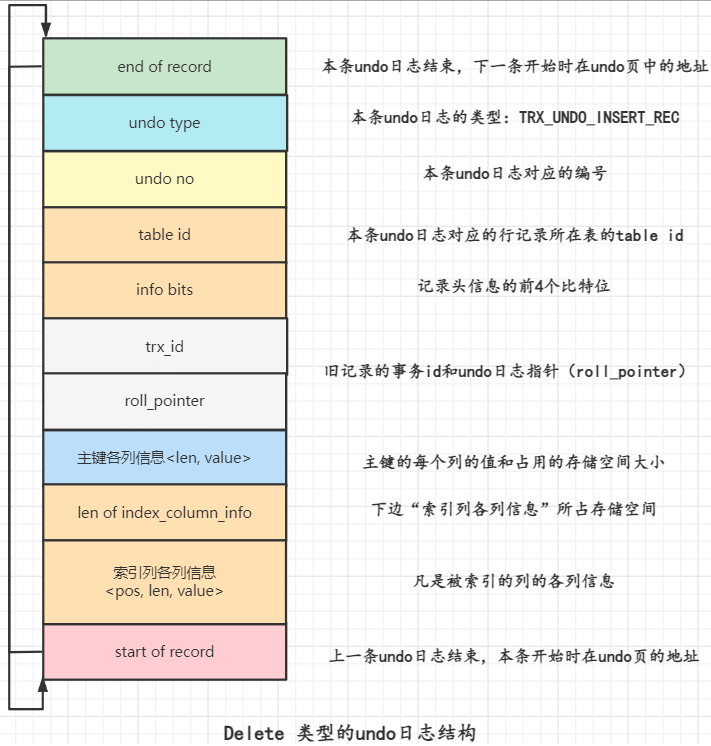
MySQL怎么运行的系列(八)14张图说明白MySQL事务原子性和undo日志原理

confidential! Netease employee data analysis internal training course, white whoring! (attach a data package worth 399 yuan)
VLAN experiment
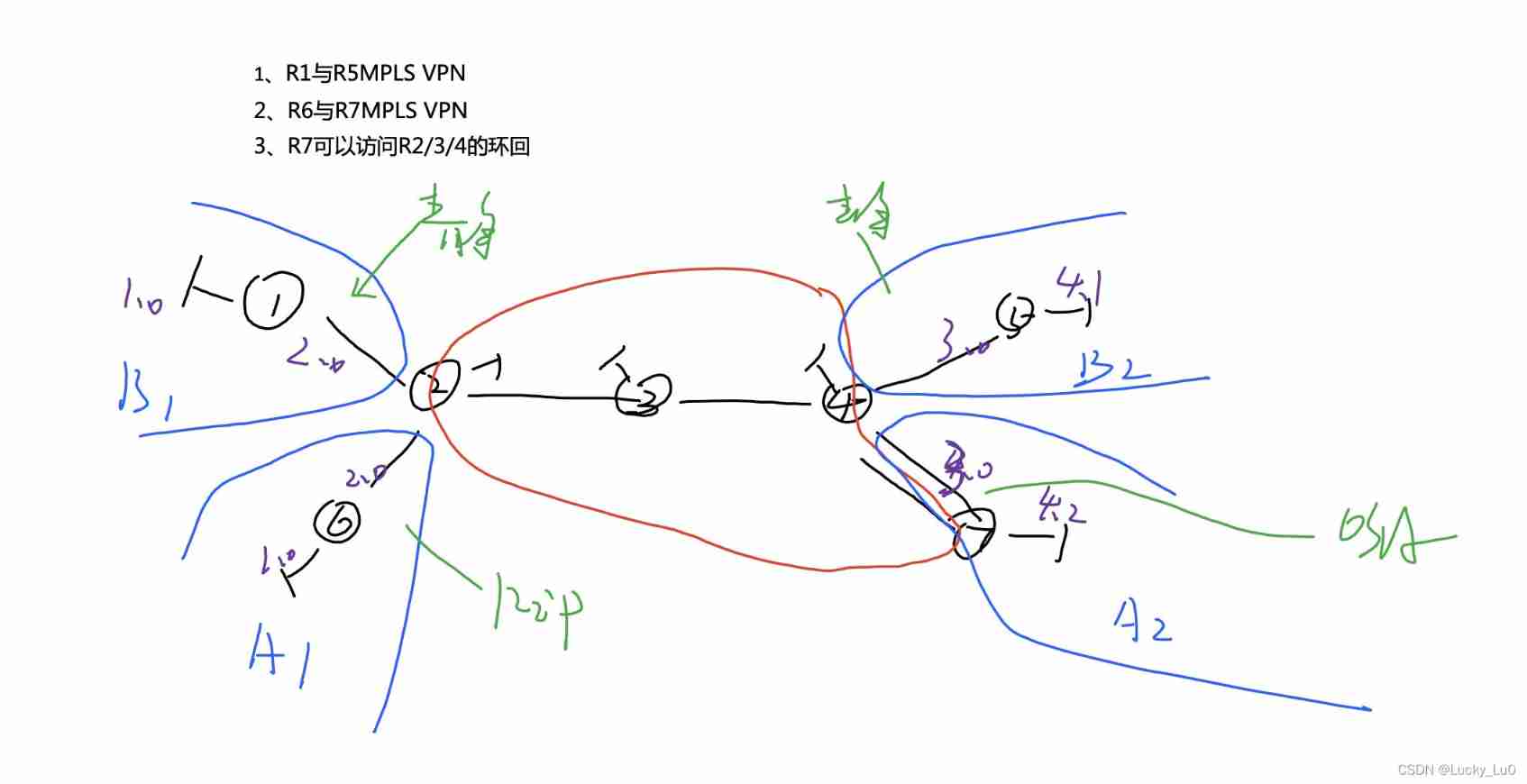
MPLS experiment
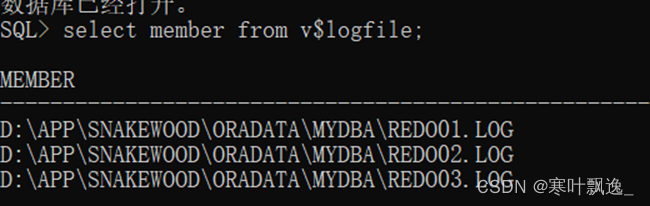
3.Oracle-控制文件的管理
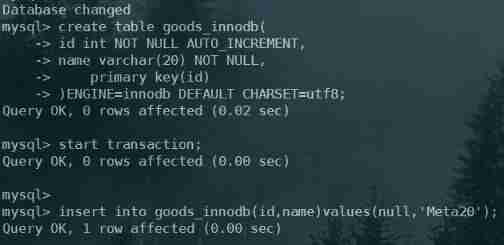
MySQL advanced part 2: storage engine

Stack acwing 3302 Expression evaluation
随机推荐
[Gaode map POI stepping pit] amap Placesearch cannot be used
求组合数 AcWing 887. 求组合数 III
‘mongoexport‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
Sorting out the latest Android interview points in 2022 to help you easily win the offer - attached is the summary of Android intermediate and advanced interview questions in 2022
Suppose a bank's ATM machine, which allows users to deposit and withdraw money. Now there is 200 yuan in an account, and both user a and user B have the right to deposit and withdraw money from this a
Chapter 6 relational database theory
2022-5-the fourth week daily
20220213-CTF MISC-a_ good_ Idea (use of stegsolve tool) -2017_ Dating_ in_ Singapore
Currently clicked button and current mouse coordinates in QT judgment interface
Single chip computer engineering experience - layered idea
博弈论 AcWing 893. 集合-Nim游戏
C job interview - casting and comparing - C job interview - casting and comparing
C Primer Plus Chapter 15 (bit operation)
将webApp或者H5页面打包成App
Using handler in a new thread
4.Oracle-重做日志文件管理
Client use of Argo CD installation
Gauss Cancellation acwing 884. Solution d'un système d'équations Xor linéaires par élimination gaussienne
H5 模块悬浮拖动效果
Gaussian elimination acwing 884 Gauss elimination for solving XOR linear equations