当前位置:网站首页>CVPR 2022 | 常见3D损坏和数据增强
CVPR 2022 | 常见3D损坏和数据增强
2022-07-05 20:15:00 【3D视觉工坊】
论文链接:https://arxiv.org/abs/2203.01441
论文名称:3D Common Corruptions and Data Augmentation(CVPR2022[Oral])
项目地址:https://3dcommoncorruptions.epfl.ch/
摘要
我们引入了一组图像转换,可用作评估模型鲁棒性的损坏以及用于训练神经网络的数据增强机制。所提出的转换的主要区别在于,与现有方法(如常见的损坏 [27])不同,场景的几何形状被包含在转换中 - 从而导致更可能在现实世界中发生的损坏。我们还引入了一组语义损坏(例如自然对象遮挡。)
我们展示了这些转换是“高效的”(可以即时计算)、“可扩展”(可以应用于大多数图像数据集)、暴露现有模型的脆弱性,并且在用作“3D”时可以有效地使模型更加健壮的数据增强机制。对几个任务和数据集的评估表明,将 3D 信息纳入基准测试和训练为鲁棒性研究开辟了一个有前途的方向。
介绍
部署在现实世界中的计算机视觉模型会遇到来自其训练数据的自然发生的分布偏移。这些变化的范围从较低层次的失真,如运动模糊和光照变化,到语义上的失真,如物体遮挡。它们中的每一个都代表了一个模型的可能失败模式,并经常被证明会导致极不可靠的预测[15, 23, 27, 31, 67]。因此,在现实世界中部署这些模型之前,对这些转变的脆弱性进行系统测试是至关重要的。
这项工作提出了一套分布式转变,以测试模型的稳健性。与之前提出的在图像上进行统一的二维修改的偏移相比,如Common Corruptions (2DCC) [27],我们的偏移结合了三维信息来产生与场景几何形状一致的偏移。这导致了更有可能在现实世界中发生的转变(见图1)。

由此产生的集合包括20个损坏,每个都代表了来自训练数据的分布转移,我们将其表示为3D常见损坏(3DCC)。3DCC涉及现实世界的几个方面,如相机运动、天气、遮挡、景深和照明。图2提供了所有损坏的概况。如图1所示,与仅有的2D方法相比,3DCC中的损坏现象更加多样化和现实化。

我们在第5节中表明,旨在提高鲁棒性的方法,包括那些具有多样化数据增强的方法,在3DCC下的性能会急剧下降。此外,我们观察到,3DCC暴露的鲁棒性问题与通过逼真合成产生的损坏有很大的关联。因此,3DCC可以作为一个挑战。
受此启发,我们的框架也引入了新的三维数据增强。与二维增强相比,它们考虑到了场景的几何形状,从而使模型能够针对更真实的损坏建立不变性。我们在第5.3节中表明,它们极大地提高了模型对这些损坏的鲁棒性,包括那些不能被二维增强所解决的损坏。
所建议的损坏是以编程方式产生的,其参数是公开的,可以对鲁棒性进行细粒度的分析,例如通过不断增加三维运动的模糊度。它们的计算效率很高,可以在训练过程中作为数据增强进行即时计算,而计算成本的增加很小。它们也是可扩展的,即它们可以应用于标准的视觉数据集,例如ImageNet[12],而这些数据集并不带有三维标签。
相关工作
这项工作提出了一个以数据为中心的稳健性方法[52, 63]。在篇幅有限的情况下,我们对一些相关的主题进行了概述。
基于损坏的鲁棒性基准:一些研究已经提出了鲁棒性基准,以了解模型对损坏的脆弱性。一个流行的基准,常见损坏(2DCC)[27],在真实的图像上产生合成的损坏,暴露了图像识别模型的敏感性。它导致了一系列的工作,要么创造新的损坏,要么在其他数据集上为不同的任务应用类似的损坏[7,32,43,45,66,80] 。与这些作品相比,3DCC使用3D信息修改真实的图像,以产生真实的损坏。由此产生的图像与二维对应的图像相比,既在感观上有所不同,又在模型预测中暴露出不同的故障模式(见图1和8)。其他的工作是在现实世界中创建和捕捉损坏,例如ObjectNet[3]。虽然是现实的,但它需要大量的手工工作,而且不能扩展。一个更可扩展的方法是使用基于计算机图形的三维模拟器来生成损坏的数据[38],这可能会导致泛化的问题。3DCC旨在生成尽可能接近真实世界的损坏,同时保持可扩展性。
鲁棒性分析:工作使用现有的基准来探测不同方法的鲁棒性,如数据增强或自我监督训练,在几个分布变化下。最近的工作调查了合成和自然分布转变之间的关系[14,26,44,68]和架构进步的有效性[5,48,64]。我们选择了几种流行的方法来说明3DCC可以作为一个具有挑战性的基准(图6和7)。
提高鲁棒性:已经提出了许多方法来提高模型的鲁棒性,如用损坏的数据进行数据增强[22, 40, 41, 60],纹理变化[24, 26],图像合成[82, 85]和变换[29, 81]。虽然这些方法可以归纳到一些未见过的例子,但性能的提高是不均匀的[22, 61]。其他方法包括自我训练[76]、预训练[28, 50]、结构变化[5, 64]和多样化的集合[33, 51, 78, 79]。在这里,我们采用了一种以数据为中心的鲁棒性方法,即:i. 提供一大套现实的分布偏移;ii. 引入新的三维数据增强,提高对现实世界损坏的鲁棒性(5.3节)。
逼真的图像合成:涉及生成逼真图像的技术。这些技术中的一些最近被用来创建损坏数据。这些技术一般都是针对单一的真实世界的损坏。例子包括不利的天气条件[19, 30, 62, 69, 70],运动模糊[6, 49],景深[4, 17, 53, 71, 72],照明[25, 77],和噪音[21, 74]。它们可以被用于纯粹的艺术目的,也可以用于创建训练数据。我们的一些三维变换是这些方法的实例化,其下游目标是在一个统一的框架内测试和改善模型的鲁棒性,并有广泛的损坏。
图像修复:目的是使用经典的信号处理技术[18, 20, 35,42]或基于学习的方法[1,8,46,47,57,86,87]来消除图像中的损坏。我们与这些作品不同的是,我们生成了损坏的数据,而不是消除它,以使用它们作为基准或数据的增加。因此,在后者中,我们用这些损坏的数据进行训练,以鼓励模型不受损坏的影响,而不是作为一个预处理步骤来训练模型以去除损坏。
对抗性损坏:在输入中增加了难以察觉的最坏情况下的偏移来欺骗模型[11,36,41,67]。现实世界中大多数模型的失败案例都不是对抗性损坏的结果,而是自然发生的分布偏移。因此,我们在本文中的重点是产生在现实世界中可能发生的损坏。
生成常见3D损坏
3.1. 损坏类型
我们定义了不同的损坏类型,即景深、相机运动、灯光、视频、天气、视图变化、语义和噪声,在3DCC中产生了20种损坏。大多数损坏需要RGB图像和场景深度,而有些需要3D网格(见图3)。我们使用一套利用三维合成技术或图像形成模型的方法来产生不同的损坏类型,下面会详细解释。进一步的细节在补充文件中提供。
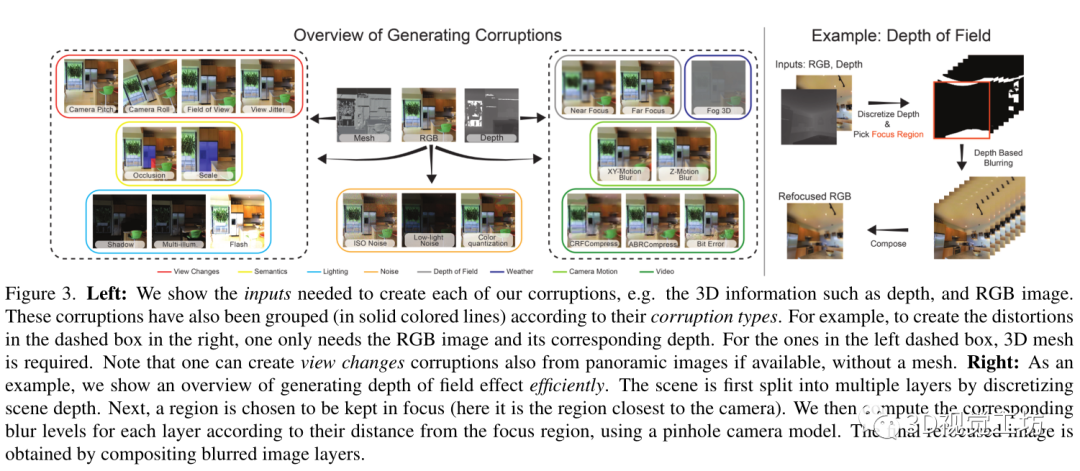
景深:损坏会产生重新聚焦的图像。它们使图像的一部分保持在焦点上,而其余部分则变得模糊不清。我们考虑采用分层方法[4,17],将场景分成多个层次。对于每一层,使用针孔相机模型计算出相应的模糊程度。然后用阿尔法混合法对模糊层进行合成。图3(右)显示了这个过程的概况。我们通过随机改变焦点区域到场景的近处或远处来产生近焦和远焦的损坏。
相机运动:由于相机在曝光过程中的移动而产生模糊的图像。为了产生这种效果,我们首先利用深度信息将输入图像转化为点云。然后,我们定义一个轨迹(相机运动)并沿着这个轨迹渲染新的视图。由于点云是由单一的RGB图像生成的,当相机移动时,它对场景的信息是不完整的。因此,渲染的视图会有不完整的假象。为了缓解这个问题,我们采用了[49]中的绘画方法。然后,生成的视图被组合起来以获得视差一致的运动模糊。当摄像机的主要运动是沿着图像的XY-平面或Z轴时,我们分别定义XY-运动模糊和Z-运动模糊。
照明:损坏通过添加新的光源和修改原始照明来改变场景的照明。我们使用Blender[10]来放置这些新的光源,并计算三维网格中特定视角的相应照度。对于闪光损坏,光源被放置在摄像机的位置,而对于阴影损坏,它被放置在摄像机外壳以外的随机不同位置。同样,对于多光照损坏,我们计算一组具有不同位置和亮度的随机光源的光照度。
视频:在视频的处理和流媒体过程中会出现损坏。利用场景三维,我们通过定义轨迹,使用单个图像的多个帧来创建一个视频,类似于运动模糊。受[80]的启发,我们产生了平均比特率(ABR)和恒定速率因子(CRF)作为H.265编解码器的压缩神器,以及比特误差来捕捉由不完善的视频传输通道引起的损坏。在对视频进行损坏后,我们挑选一个单帧作为最终的损坏图像。
天气:损坏通过由于介质中的干扰而掩盖场景的一部分来降低可见度。我们定义了一个单一的损坏,并将其表示为雾3D,以区别于2DCC中的雾损坏。我们使用雾的标准光学模型[19, 62, 70]。
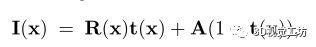
其中I(x)是像素x处产生的雾状图像,R(x)是干净的图像,A是大气光,t(x)是描述到达摄像机的光量的传输函数。当介质是均匀的,传输取决于与摄像机的距离,t(x)= exp (-βd(x)) 其中d(x)是场景深度,β是控制雾气厚度的衰减系数。
视角变化:是由于相机的外因和焦距的变化造成的。我们的框架能够使用Blender渲染以几种变化为条件的RGB图像,如视场、相机滚动和相机俯仰。这使我们能够以一种可控的方式分析模型对各种视图变化的敏感性。我们还生成了具有视图抖动的图像,可以用来分析模型预测是否会因视角的轻微变化而出现闪烁。
语义:除了视图的变化,我们还通过选择场景中的一个物体并改变其遮挡程度和比例来渲染图像。在遮挡损坏中,我们生成一个物体被其他物体遮挡的视图。这与像素的随机二维遮挡形成不自然的遮挡效果是不同的,例如在[13,48]中(见图1)。遮挡率可以被控制,以探测模型对遮挡变化的鲁棒性。同样地,在尺度损坏中,我们渲染一个物体与摄像机位置的不同距离的视图。请注意,这些损坏需要一个带有语义注释的网格,并且是自动生成的,类似于[2]。这与[3]相反,后者需要繁琐的手工操作。对象可以通过在场景中随机选取一个点或使用语义注释来选择。
噪声:损坏来自于不完善的相机传感器。我们引入了以前的2DCC基准中不存在的新的噪声损坏。对于低光噪声,我们降低了像素强度并增加了泊松-高斯分布的噪声,以反映低光成像环境[21]。ISO噪声也遵循泊松-高斯分布,有固定的光子噪声(以泊松为模型),以及变化的电子噪声(以高斯为模型)。我们还将颜色量化作为另一种降低RGB图像比特深度的损坏。只有我们的这个损坏子集不是基于三维信息的。
3.2. 初始化的3D常见损坏数据集
我们发布了我们管道的全部开放源代码,这使得我们可以在任何数据集上使用所实现的损坏。作为初始数据集,我们在16k Taskonomy[84]测试图像上应用了损坏。对于所有的损坏,除了那些改变场景的视图和语义,我们遵循2DCC的协议,并定义了5个移位强度,产生了大约100万张损坏的图像(16k×14×5)。直接应用这些方法来产生损坏,会导致与2DCC相比的未校准的移位强度。因此,为了能够与2DCC在更均匀的强度变化上进行统一比较,我们进行了一个校准步骤。对于在2DCC中直接对应的损坏,例如运动模糊,我们在3DCC中设置了损坏水平,使得对于2DCC中的每个位移强度,所有图像的平均SSIM[73]值在两个基准中都是相同的。对于在2DCC中没有对应的损坏,我们调整变形参数以增加移位强度,同时保持在与其他类似的SSIM范围内。对于视图变化和语义,我们用平滑变化的参数渲染32k图像,如滚动角度,使用Replica[65]数据集。图4显示了具有不同移位强度的损坏实例。

3.3. 将3DCC应用于标准视觉数据集
虽然我们采用了具有完整场景几何信息的数据集,如Taskonomy[84],但3DCC也可以应用于没有三维信息的标准数据集。我们在ImageNet[12]和COCO[39]验证集上举例说明,利用MiDaS[55]模型的深度预测,这是一个最先进的深度估计器。图5显示了具有近焦、远焦和雾状三维损坏的图像实例。生成的图像在物理上是合理的,这表明3DCC可以被社区用于其他数据集,以生成一组多样化的图像损坏。在第5.2.4节中,我们定量地证明了使用预测深度来生成3DCC的有效性。

四、3D数据增强
虽然基准测试使用损坏的图像作为测试数据,但人们也可以把它们作为训练数据的增强值,以建立对这些损坏的不变性。对我们来说就是这样,因为与2DCC不同,3DCC的设计是为了捕捉更有可能出现在真实世界的损坏,因此它也有一个合理的增强值。
因此,除了使用3DCC进行鲁棒性基准测试外,我们的框架也可以被视为新的数据增强策略,将3D场景的几何形状考虑在内。在我们的实验中,我们用以下损坏类型进行增强:景深、相机运动和照明。这些增强可以在训练过程中使用并行的实现方式有效地生成。例如,景深增强在单个V100 GPU上需要0.87秒(挂钟时间),批量大小为128张224×224分辨率的图像。作为比较,应用二维散焦模糊平均需要0.54秒。也可以预先计算增强过程中某些选定的部分,例如照明增强的照度,以提高效率。我们将这些机制纳入了我们的实施中。我们在第5.3节中表明,这些增强可以显著提高对现实世界的鲁棒性。
五、实验
我们进行了评估,证明3DCC可以暴露出2DCC无法捕捉到的模型(第5.2.1节)中的漏洞(第5.2.2节)。生成的损坏与昂贵的现实合成损坏相似(第5.2.3节),适用于没有三维信息的数据集(第5.2.4节)和语义任务(第5.2.5节)。最后,提议的三维数据增强从质量和数量上提高了鲁棒性(第5.3节)。请参阅项目页面,了解实时演示和更广泛的定性结果。
5.1. 序言
评价任务:3DCC可以应用于任何数据集,而不考虑目标任务,例如密集回归或低维分类。在这里,我们主要用表面法线和深度估计作为社区广泛采用的目标任务进行实验。我们注意到,与分类任务相比,解决这类任务的模型的鲁棒性还没有得到充分的探索(见第5.2.5节关于全景分割和物体识别的结果)。为了评估鲁棒性,我们计算了预测图像和地面真实图像之间的L1误差。
训练细节:我们在Taskonomy[84]上训练UNet[59]和DPT[54]模型,使用学习率5×10-4和权重衰减2×10-6。我们使用AMSGrad[56]对具有拉普拉斯先验的似然损失进行优化,遵循[79]。除非特别说明,所有的模型都使用相同的UNet骨架(如图6)。我们还试验了在Omnidata[17]上训练的DPT模型,该模型混合了多样化的训练数据集。按照[17],我们用学习率1×10-5、权重衰减2×10-6和角度&L1损失来训练。
5.2. 3D常见损坏基准测试
5.2.1 3DCC会暴露出漏洞
我们对现有的模型与3DCC进行了基准测试,以了解其脆弱性。然而,我们注意到,我们的主要贡献不是所进行的分析,而是基准本身。最先进的模型可能会随着时间的推移而改变,而3DCC的目的是确定稳健性趋势,与其他基准类似。
稳健性机制的影响:图6显示了不同鲁棒性机制在3DCC的表面法线和深度估计任务上的平均性能。这些机制的性能比基线有所提高,但与清洁数据上的性能相比仍有很大差距。这表明3DCC暴露了鲁棒性问题,可以作为模型的一个挑战性测试平台。2DCC增强模型返回的L1误差略低,表明多样化的二维数据增强只是部分地帮助对抗三维损坏。
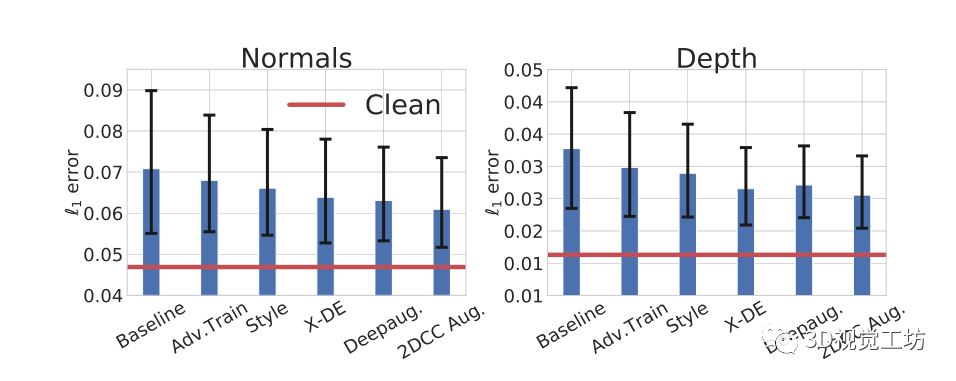
现有的鲁棒性机制被发现不足以解决由3DCC近似的真实世界的损坏问题。显示了在3DCC下具有不同鲁棒性机制的模型在表面法线(左)和深度(右)估计任务中的表现。这里所有的模型都是UNets,并且是用Taskonomy数据训练的。每个条形图显示了所有3DCC损坏的平均L1误差(越低越好)。黑色的误差条显示了最低和最高位移强度下的误差。红线表示基线模型在干净(未损坏)数据上的表现。这表示现有的鲁棒性机制,包括那些具有不同增强功能的机制,在3DCC下表现不佳。
数据集和架构的影响:我们在图7中对3DCC的性能进行了详细分解。我们首先观察到,在Taskonomy上训练的基线UNet和DPT模型具有相似的性能,特别是在视图变化的损坏上。通过用Omnidata的更大、更多样化的数据进行训练,DPT的性能有所提高。在用于分类的视觉变换器上也有类似的观察[5, 16]。这种改进在视图改变的情况下很明显,而对于其他的损坏,误差从0.069下降到0.061。这表明,将架构的进步与多样化的大型训练数据相结合,可以在对抗3DCC的鲁棒性方面发挥重要作用。此外,当与三维增强技术相结合时,它们可以提高对现实世界中损坏的鲁棒性(第5.3节)。
5.2.2 3DCC和2DCC中损坏的冗余度
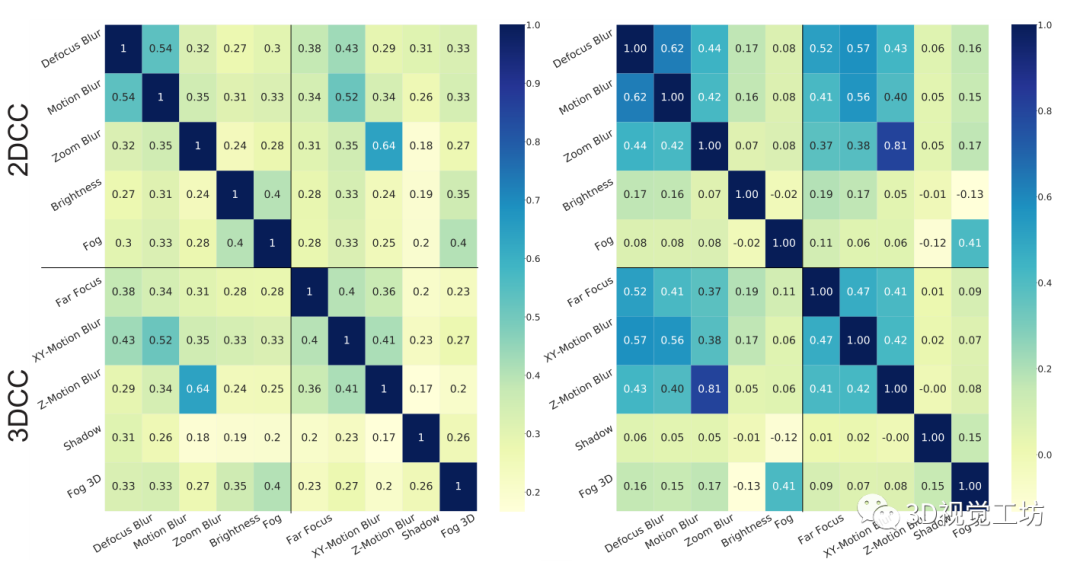
在图1中,对3DCC和2DCC进行了定性的比较。前者产生了更真实的损坏,而后者没有考虑到场景的三维性,而是在图像上进行了统一的修改。在图8中,我们旨在量化3DCC和2DCC之间的相似性。在图8的左边,我们计算了基线模型对一个损坏子集(全套在补充文件中)所做的清洁和损坏预测之间的L1误差的相关性。3DCC在基准内以及与2DCC相比都产生了较少的相关度(2DCC-2DCC的平均相关度为0.32,3DCC-3DCC为0.28,而2DCC-3DCC为0.30)。对于深度估计也得到了类似的结论(在补充文件中)。在右边,我们通过计算干净图像和损坏图像之间的L1误差,对RGB域进行了同样的分析,再次表明3DCC产生的相关性较低。
因此,3DCC有一个多样化的损坏集合,这些损坏与2DCC没有明显的重叠。
5.2.3 健全性:3DCC与昂贵的合成技术
3DCC的目的是暴露模型在某些真实世界的损坏中的脆弱性。这就要求3DCC生成的损坏与真实的损坏数据相似。由于生成这种标记的数据是昂贵的,而且很少有,作为一种代理评估,我们反而将3DCC的真实性与Adobe After Effects(AE)的合成进行比较,后者是一种商业产品,用于生成高质量的逼真数据,通常依赖于昂贵的手工过程。为了实现这一点,我们使用了Hypersim[58]数据集,它带有高分辨率的z-depth标签。然后我们使用3DCC和AE生成了200幅近景和远景的图像。图9显示了两种方法生成的图像样本,它们在感知上是相似的。接下来,我们计算了当输入来自3DCC或AE时,基线正常模型的预测误差。图10给出了'1'误差的散点图,显示了两种方法之间有很强的相关性,为0.80。为了校准和控制,我们还提供了来自2DCC的一些损坏的散点图以显示相关性的重要性。它们与AE的相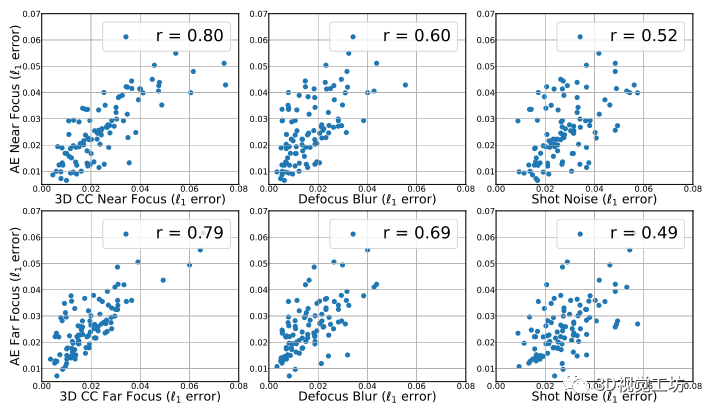
 关性明显较低,表明通过3DCC产生的景深效应与AE产生的数据相当匹配。
关性明显较低,表明通过3DCC产生的景深效应与AE产生的数据相当匹配。
5.3. 三维数据增强以提高稳健性
我们从质量和数量上证明了所提出的增强措施的有效性。我们评估了在Taskonomy上训练的UNet和DPT模型(T+UNet, T+DPT)以及在Omnidata上训练的DPT(O+DPT),以了解训练数据集和模型结构的影响。训练过程如第5.1节所述。对于其他模型,我们从O+DPT模型初始化,并在此基础上进行2DCC增强(O+DPT+2DCC)和3D增强(O+DPT+2DCC+3D)的训练,即我们提出的模型。
我们还使用来自[83]的串联任务一致性(X-TC)约束条件进一步训练了所提议的模型,在结果中表示为(Ours+X-TC)。最后,我们评估了用来自[9]的OASIS训练数据训练的模型(OASIS)。
定性评价:我们考虑了i. OASIS验证图像[9],ii. 5.2.3节中的AE损坏数据,iii. 手动收集的DSLR数据,以及iv. 野外的Y ouTube视频。图12显示,与基线相比,建议的模型所做的预测明显更加稳健。我们也建议观看这些片段并运行项目页面上的实时演示。

定量评价:在表1中,我们计算了模型在2DCC、3DCC、AE和OASIS验证集(无微调)上的误差。同样,建议的模型在不同的数据集上产生了较低的误差,显示了增强的有效性。请注意,在不牺牲野外清洁数据(即OASIS)性能的情况下,对损坏数据的鲁棒性得到了改善。

六、总结和不足
我们引入了一个框架来测试和提高模型对现实世界分布变化的鲁棒性,特别是那些以三维为中心的分布变化。实验表明,所提出的3D共同损坏是一个具有挑战性的基准,它暴露了模型在现实世界可信的损坏下的脆弱性。此外,与基线相比,拟议的数据增强导致了更强大的预测。我们相信这项工作通过展示三维损坏在基准测试和训练中的作用,为鲁棒性研究开辟了一个有前途的方向。下面我们简要地讨论一些局限性。
3D质量:3DCC受3D数据质量的上限限制。正如我们所展示的,目前的3DCC是对真实世界的3D损坏的不完美但有用的近似。随着更高分辨率的感官数据和更好的深度预测模型,保真度有望提高。
非详尽的集合:我们的一组3D损坏和增强并不是详尽的。相反,它们是供研究人员试验的启动集。该框架可以被用来生成更多的特定领域的分布转变,并以最小的人工努力。
大规模的评估:虽然我们在分析中评估了一些最近的鲁棒性方法,但我们的主要目标是要表明3DCC成功地暴露了漏洞。因此,进行全面的稳健性分析超出了这项工作的范围。我们鼓励研究人员针对我们的损坏测试他们的模型。
平衡基准:我们没有明确地平衡我们的基准中的损坏类型,例如有相同数量的噪声和模糊的扭曲。我们的工作可以进一步受益于试图校准损坏基准的平均性能的加权策略,如[37]。
扩增的使用案例:虽然我们专注于鲁棒性,但调查它们在其他应用上的用处,如自我监督学习,可能是值得的。
评估任务:我们用密集的回归任务进行实验。然而,3DCC可以应用于不同的任务,包括分类和其他语义任务。使用我们的框架对语义模型的失败案例进行调查,例如对几个物体的平滑变化的遮挡率,可以提供有用的见解。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~
边栏推荐
- 无卷积骨干网络:金字塔Transformer,提升目标检测/分割等任务精度(附源代码)...
- About the priority of Bram IP reset
- sun.misc.BASE64Encoder报错解决方法[通俗易懂]
- ICTCLAS用的字Lucene4.9捆绑
- Leetcode brush question: binary tree 14 (sum of left leaves)
- Database logic processing function
- Debezium series: modify the source code to support UNIX_ timestamp() as DEFAULT value
- Guidelines for application of Shenzhen green and low carbon industry support plan in 2023
- 信息学奥赛一本通 1337:【例3-2】单词查找树 | 洛谷 P5755 [NOI2000] 单词查找树
- Based on vs2017 and cmake GUI configuration, zxing and opencv are used in win10 x64 environment, and simple detection of data matrix code is realized
猜你喜欢
基础篇——配置文件解析
Securerandom things | true and false random numbers
Based on vs2017 and cmake GUI configuration, zxing and opencv are used in win10 x64 environment, and simple detection of data matrix code is realized
leetcode刷题:二叉树16(路径总和)
Build your own website (16)
图嵌入Graph embedding学习笔记

leetcode刷题:二叉树18(最大二叉树)
leetcode刷题:二叉树13(相同的树)
微信小程序正则表达式提取链接
Leetcode skimming: binary tree 16 (path sum)
随机推荐
Schema和Model
[C language] three implementations of quick sorting and optimization details
After 95, Alibaba P7 published the payroll: it's really fragrant to make up this
关于BRAM IP复位的优先级
leetcode刷题:二叉树11(平衡二叉树)
[quick start of Digital IC Verification] 6. Quick start of questasim (taking the design and verification of full adder as an example)
Zero cloud new UI design
19 Mongoose模块化
model方法
c语言oj得pe,ACM入门之OJ~
Ffplay document [easy to understand]
【数字IC验证快速入门】6、Questasim 快速上手使用(以全加器设计与验证为例)
Reinforcement learning - learning notes 4 | actor critical
[quick start of Digital IC Verification] 9. Finite state machine (FSM) necessary for Verilog RTL design
Leetcode skimming: binary tree 17 (construct binary tree from middle order and post order traversal sequence)
字节跳动Dev Better技术沙龙成功举办,携手华泰分享Web研发效能提升经验
Jvmrandom cannot set seeds | problem tracing | source code tracing
Hong Kong stocks will welcome the "best ten yuan store". Can famous creative products break through through the IPO?
Fundamentals of deep learning convolutional neural network (CNN)
ICTCLAS用的字Lucene4.9捆绑