当前位置:网站首页>A Closer Look at How Fine-tuning Changes BERT
A Closer Look at How Fine-tuning Changes BERT
2022-07-06 07:51:00 【be_ humble】
A Closer Look at How Fine-tuning Changes BERT
ACL 2022, The author comes from every Utah University
Thesis link :[2102.12452] Probing Classifiers: Promises, Shortcomings, and Advances (arxiv.org)
After reading the title, I think it should be compared by using interpretable methods fine-tune Front and rear bert The model analyzes the effect of target task data , There may be some theoretical analysis , Proof and so on .
Abstract
First of all, let's talk about recent years as a whole pretrain Model fire , Usually in downstream tasks fine-tune, Perform better , The author reasoned fine-tune Added different label data representation Distance of , Then set the 5 A group of experiments proved , At the same time, I found that not all fine-tune Will make the model better , In the end, I mentioned fine-tune After representation The original spatial structure will still be preserved .
It seems that I think too much , Even the comparison of interpretable methods is useless , It's simply different label The vector is far away , Here's a look , It's not nonsense , original pretrain Our model does not perform directly in downstream tasks fine-tune good , Model applications are representation One after another fc layer softmax To classify , Of course fine-tune It's different label It's a long way away . Then we'll see what the exceptions are and how the author sets up experiments to compare the two spatial structures .
1. Introduction
First introduced Bert The paper , Then on fine-tune Use related work to introduce , Finally, I put forward myself motivation:fine-tuning How to change representation And why it works , Put forward 3 A question
- fine-tuning Whether it has always worked
- fine-tuning How to adjust representation
- fine-tuning stay bert Different laryers How much has changed
Use two kinds of probing Method :
- Based on classification probe
- Direct Probe
stay 5 Class different tasks (POS, Rely on header prediction , Deixis disambiguation , Function prediction , Text classification )
The conclusion is as follows :
fine-tune stay train and test The differences of , Generally, it has little effect on the results
fine-tune take representation Different label Distance increases , Different label Of cluster Distance increases
fine-tune Only slightly changed the top ,representation The relative position of the label cluster is preserved .
2. Preliminaries: Probing Methods
This paper mainly aims at representation analysis , The following mainly introduces the analysis method , Probe method
Classifier as Probes
Simply speaking , Is a classifier , The input is us bert At the top of the model embedding representation, The output is the classification result , adopt freeze embedding, Only train classifiers , Then compare the experimental results , Here the classifier is used twice fc, Followed by relu Activation and other super parameter settings
DirectProbe: Probing the Geometric Structure
Because it cannot be reflected directly with classifier probe representation The performance of the , Use similar clustering methods , according to embedding Get different clusters , Calculate the distance between clusters , The number of clusters is the same as label Number comparison , By calculating the distance between clusters Person coefficient To reflect the spatial similarity . To show fine-tune Before and after representation The difference .
Probe method , One by one classifier , A cluster , Express by clustering among clusters , Are very simple methods , I think I get the result like this , explain fine-tune The optimization of vector performance is not sufficient .
3. Experimental setup
3.1 representations
Use bert Different layers of the model , Different hidden_size Vector representation of , The model is for English text , Case insensitive (uncased), Use word segmentation subwords, Use average pooling to represent token representation, Code using huggingface Code .
3.2 Tasks
in the light of bert Common tasks , Covering grammatical and semantic tasks
POS Morphological tagging
DEP dependency parsing
PS-role Deixis disambiguation
Text -Classification Text classification , Use CLS As a sentence, it means
3.3 Fine tune settings
10 individual epoch, And it is pointed out that fine-tune And training classifier probe two-stage training process , Isn't that bullshit ,,
4. Analysis of experimental results
4.1 fine-tune performance
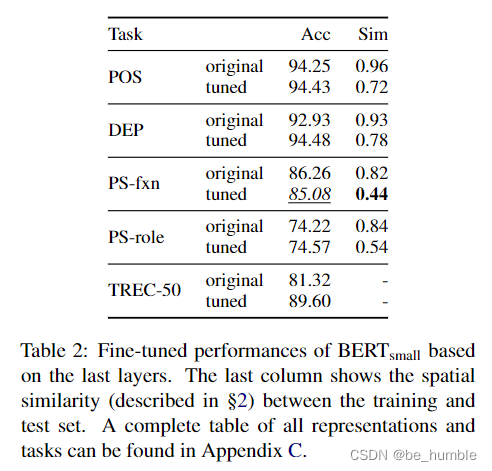
Experiments show that fine-tune Make the training set and test set diverge , And found in Bert-small Under the model PS-fxn Mission fine-tune The effect is worse , But the main reason is that the similarity between the training set and the test set is low , Then no specific reason was found ( I think this is nonsense , you fine-tune Data and test data are very different , that fine-tune Not only in the wrong direction , It is very possible that the effect is poor , And it's similar clip Wait for the model fine-tune There are also many with poor results )
4.2 The linearity of vector representation
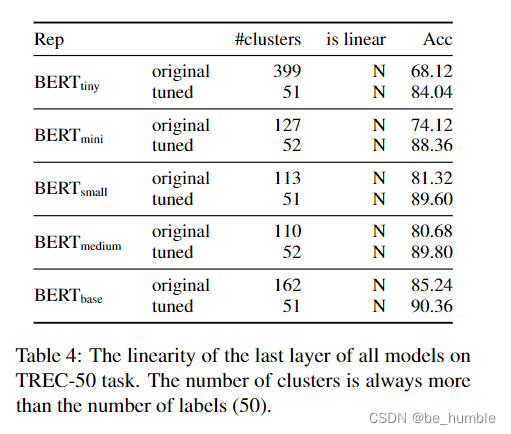
As shown in the result chart , It shows fine-tune After clustering, the number of clusters decreases , Linear enhancement . Fine tuning makes the original complex spatial representation simple , After fine tuning, the vector cluster has a purpose label Convergence mobile .
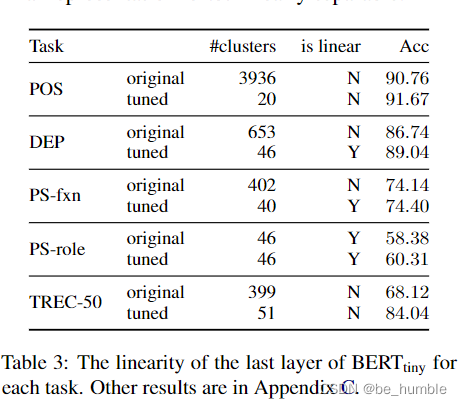
4.3 Spatial structure of labels
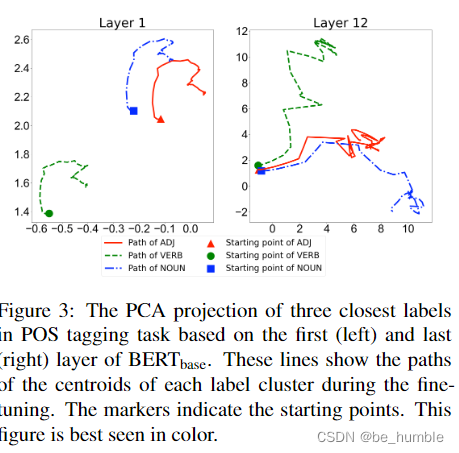
Above, bert-base Represented by vectors at the top and bottom PCA Dimension reduction result graph , indicate fine-tune Can make a difference label Increase the distance between clusters ( this fine-tune The effect increases , Isn't it obvious that the vector represents the increase of distance )
4.4 Cross task fine-tune
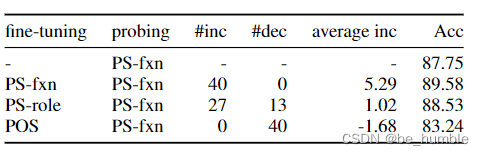
The author also considers that since fine-tune One task Will increase the corresponding label Distance of , So for others task Of label The distance should be reduced accordingly , Check the effect through the experiment above , Different task The task is going on fine-tune, And then again PS-fxn Probe test results , The results show that the tasks with high similarity fine-tune It is possible to cross-task fine-tune The effect is good , Low correlation task Conduct fine-tune It will reduce the effect .( The experimental feeling of this part is also obvious )
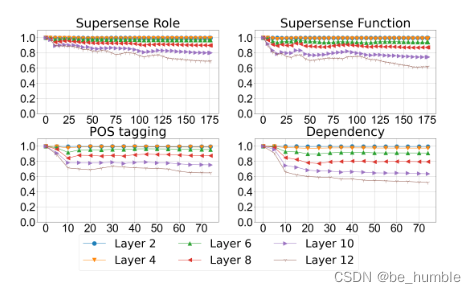
Finally, the vector representation of different layers person coefficient , prove fine-tune The information representation of the pre training model is hardly modified ,high layer The change is very small .
summary
To summarize this article , Mainly to describe fine-tune Why the effect is good , And then make a comparative analysis on the vector representation , Final analysis fine-tune Yes bert Different layer vectors represent the effect . Usage probe ( Based on the representation vector, then classify and cluster ), The experimental idea is very simple , The content of the proof is also the result we take for granted , But the article is well described , The experiment is full , Enough work , I think there is no reference value in methods after reading , But this kind of thing proves to be taken for granted , Sometimes it is necessary .
Usage probe ( Based on the representation vector, then classify and cluster ), The experimental idea is very simple , The content of the proof is also the result we take for granted , But the article is well described , The experiment is full , Enough work , I think there is no reference value in methods after reading , But this kind of thing proves to be taken for granted , Sometimes it is necessary .
Go home and work during recent holidays , I often play basketball every day , Bodybuilding , The time for study has been reduced a lot , Slower , I must refuel recently .
边栏推荐
- Scala language learning-08-abstract classes
- [redis] Introduction to NoSQL database and redis
- [count] [combined number] value series
- How to delete all the words before or after a symbol in word
- TS 类型体操 之 循环中的键值判断,as 关键字使用
- datax自检报错 /datax/plugin/reader/._drdsreader/plugin.json]不存在
- Simulation of holographic interferogram and phase reconstruction of Fourier transform based on MATLAB
- Transformer principle and code elaboration
- Data governance: misunderstanding sorting
- Qualitative risk analysis of Oracle project management system
猜你喜欢

Google may return to the Chinese market after the Spring Festival.

Interview Reply of Zhuhai Jinshan
![Ble of Jerry [chapter]](/img/d8/d080ccaa4ee530ed21d62755808724.png)
Ble of Jerry [chapter]

In the era of digital economy, how to ensure security?
【T31ZL智能视频应用处理器资料】
Simulation of Michelson interferometer based on MATLAB

How to delete all the words before or after a symbol in word
Comparison of usage scenarios and implementations of extensions, equal, and like in TS type Gymnastics
Solution: intelligent site intelligent inspection scheme video monitoring system
智能终端设备加密防护的意义和措施

随机推荐
超级浏览器是指纹浏览器吗?怎样选择一款好的超级浏览器?
Entity class design for calculating age based on birthday
If Jerry's Bluetooth device wants to send data to the mobile phone, the mobile phone needs to open the notify channel first [article]
TS 类型体操 之 extends,Equal,Alike 使用场景和实现对比
Wonderful use of TS type gymnastics string
MES, APS and ERP are essential to realize fine production
Binary tree creation & traversal
TS 类型体操 之 循环中的键值判断,as 关键字使用
数据治理:元数据管理篇
How to delete all the words before or after a symbol in word
07- [istio] istio destinationrule (purpose rule)
Google可能在春节后回归中国市场。
Machine learning - decision tree
数据治理:主数据的3特征、4超越和3二八原则
继电反馈PID控制器参数自整定
Description of octomap averagenodecolor function
Three treasures of leeks and Chinese men's football team
Simulation of holographic interferogram and phase reconstruction of Fourier transform based on MATLAB
Inspiration from the recruitment of bioinformatics analysts in the Department of laboratory medicine, Zhujiang Hospital, Southern Medical University
leecode-C语言实现-15. 三数之和------思路待改进版