当前位置:网站首页>Flink parsing (VII): time window
Flink parsing (VII): time window
2022-07-06 17:29:00 【Stray_ Lambs】
Catalog
Tumbling Windows Scroll the window
Sliding Windows The sliding window
Session Windows Session window
Trigger (Fire) And clear (Purge)
WindowAssigner default Triggers
built-in Triggers And customization Triggers
Window Functions Window function
Incremental aggregated ProcessWindowFunction
Use ReduceFunction Incremental aggregation
Use AggregateFunction Incremental aggregation
stay ProcessWindowFunction Use in per-window state
Some considerations about late data
Consider the size of the state
The concept of time
because Flink In the framework, real-time stream processing events , Time plays a great role in calculation . For example, time series analysis 、 Based on a specific time period ( window ) Aggregation or event handling in important cases .Flink Of DataStream Supports three time:EventTime、IngestTime and ProcessingTime, And there are a lot of based on time Of operator.
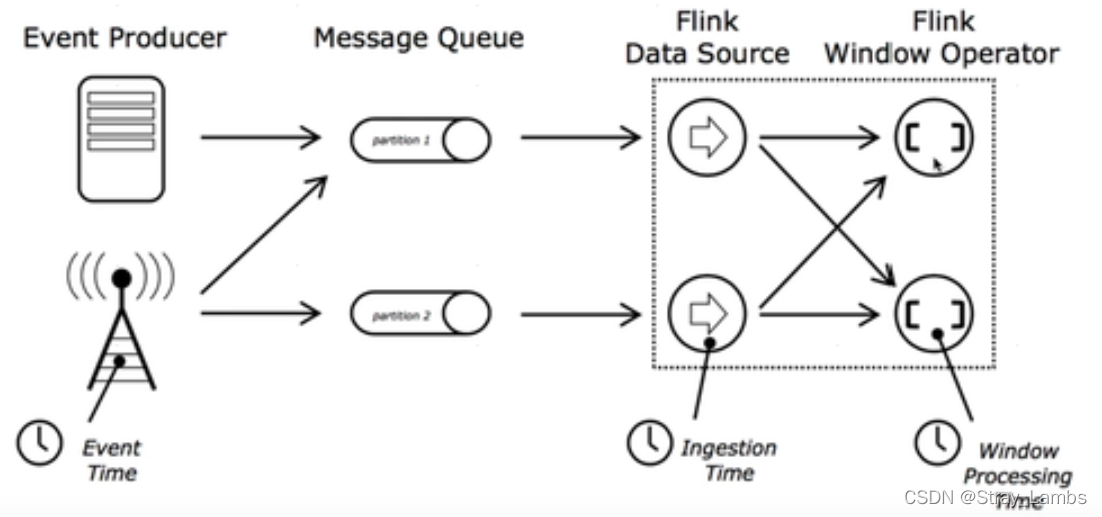
Compare these three times :
- EventTime
- The time when the event was generated , When entering Flink Already exists between , It can be downloaded from event In the field of
- Must specify watermarks How to generate
- advantage : deterministic , In disorder 、 In case of delay or data repetition , Can give the right results
- weaknesses : Performance and latency are affected when processing out of order events
- IngestTime( It's rarely used …)
- Events enter Flink Time for , That is to say source The current system time obtained in , Use this time for subsequent operations
- You don't have to specify watermarks How to generate ( Automatic generation )
- weaknesses : Can't handle out of order time and delay data
- ProcessingTime
- The current system time of the machine performing the operation ( Every operator is different )
- There is no need for coordination between flows and machines
- advantage : Best performance and lowest latency
- weaknesses : uncertainty , Vulnerable to various factors ( for example event Speed produced 、 arrive flink The speed of 、 Transmission speed between operators, etc ), Regardless of sequence and delay
in summary :
- performance :ProcessingTime>IngestTime>EventTime
- Delay :ProcessingTime<IngestTime<EventTime
- deterministic :ProcessingTime<IngestTime<EventTime
If not set Time type , The default is processingTime, commonly Basically, the project uses EventTime. If necessary EventTime, You need to in source Then specify Timestamp Assigner & Watermark Generator.
WaterMarks And window concept
Talking about water level watermarks Before , We can consider what the problem of water level is . In the actual working scenario of streaming Computing , The sequence of events has a certain impact on the correctness of the calculation results , however , Because of network delay or storage itself , This leads to data delay and disorder , For example, the data generated in the first second is 5 Seconds to arrive .
So in response to this problem ,Flink Put forward watermark, Designed to handle EventTime Window calculation , Its essence is actually a timestamp . Because for late data late element, It is impossible to wait indefinitely , There must be a mechanism to ensure that after a specific time , Trigger must be taken window To calculate , This mechanism is watermark, It can be understood as watermark It's a kind of telling Flink How much message delay , Wait for how long late data . It's usually by Flink Source Or custom watermark The generator generates , Then follow the ordinary data flow to the downstream operator , Received watermark The operator of will be based on the new watermark Conduct Take a max The operation of .
watermark data structure
stay Flink DataStream There are many different elements flowing in , Collectively referred to as StreamElement,StreamElement It can be StreamRecord、Watermark、StreamStatus、LatencyMarker Any type in , Is an abstract class (Flink Class is the base class that hosts messages ), The other four types inherit StreamElement.
public abstract class StreamElement {
// Judge whether it is Watermark
public final boolean isWatermark() {
return getClass() == Watermark.class;
}
// Judge whether it is StreamStatus
public final boolean isStreamStatus() {
return getClass() == StreamStatus.class;
}
// Judge whether it is StreamRecord
public final boolean isRecord() {
return getClass() == StreamRecord.class;
}
// Judge whether it is LatencyMarker
public final boolean isLatencyMarker() {
return getClass() == LatencyMarker.class;
}
// Convert to StreamRecord
public final <E> StreamRecord<E> asRecord() {
return (StreamRecord<E>) this;
}
// Convert to Watermark
public final Watermark asWatermark() {
return (Watermark) this;
}
// Convert to StreamStatus
public final StreamStatus asStreamStatus() {
return (StreamStatus) this;
}
// Convert to LatencyMarker
public final LatencyMarker asLatencyMarker() {
return (LatencyMarker) this;
}
}among ,watermark Is inherited StreamElement.Watermark It's a level of abstraction with Events , It contains a member variable timestamp inside timestamp, Identify the time progress of the current data .Watermark In fact, as part of the data flow, it flows with the data stream .
at present Flink There are two kinds of generation watermark The way
- Punctuated: The generation of new watermarks is triggered by some special marked events in the data stream . In this way, the trigger of window has nothing to do with time , It depends on When a tag event is received , That is, every incremental eventTime There will be a Watermark. In actual production Punctuated The way is TPS A lot of Watermark To some extent, it puts pressure on the downstream operators , Therefore, only in scenes with high real-time requirements will we choose Punctuated Generated by watermark.
- Periodic: Periodic ( Such as a certain time interval or a certain number of records ) One of the things that came out Watermark. In actual production Periodic The way We must combine the two dimensions of time and accumulation to continue to produce periodically Watermark, Otherwise, in extreme cases, there will be a great delay .
therefore Watermark We need to choose different generation methods according to different business scenarios .
Multi-source watermark Handle
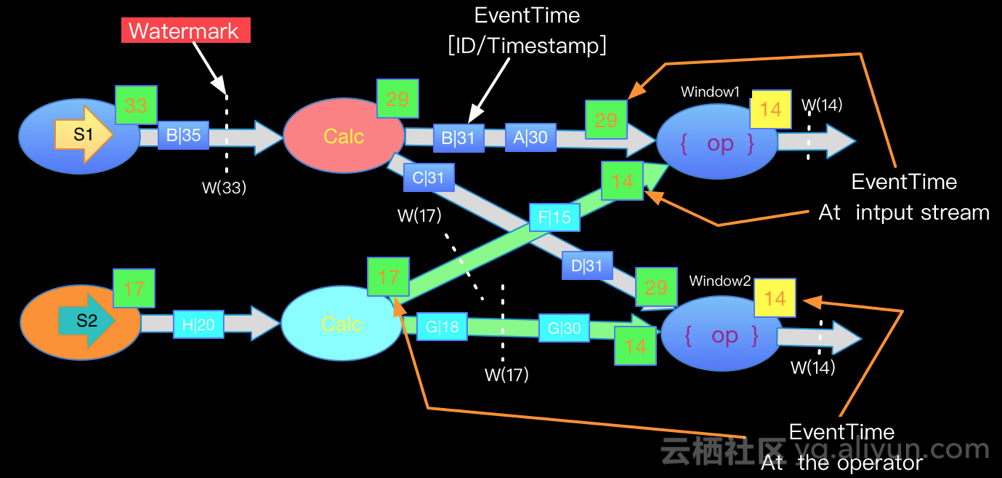
If in the actual process of stream processing , One job There are many source The data of , For example, after groupby After grouping , same key will shuffle To the same node , And it's different watermark. because Flink In order to ensure watermark Keep monotonically increasing ,Flink Will choose all the inflow EventTime The smallest of these flows downstream . To ensure that watermark Monotone increment of data and guarantee the integrity of data . Here's the picture ( Here are the pictures of other big men ):
window
Flink Windows in can be divided into : Scroll the window (Tumbling Window, No overlap ), The sliding window (Sliding Window, There may be overlap ), Session window (Session Window, Activity gap ), Global window (Gobal Window)
It is specified in the general procedure keyed after , Definition window assigner.Window assigner Defined stream How the elements in are distributed to the windows . You can window(...)( be used for keyed streams) or windowAll(...) ( be used for non-keyed streams) To designate a WindowAssigner. WindowAssigner Responsible for stream Each data in is distributed to one or more windows . Flink Provides some well-defined for the most common situations window assigner, That is to say tumbling windows、 sliding windows、 session windows and global windows. You can also Inherit WindowAssigner Class to implement custom window assigner. All built-in window assigner( except global window) All are Distribute data based on time Of ,processing time or event time All possible .
And time-based windows are used [start timestamp,end timestamp) Left closed right away To describe the size of the bed . stay Flink In the code , Dealing with time-based windows uses TimeWindow, It has a query start and end timestamp Method and return window can store the largest timestamp Methods maxTimestamp().
Tumbling Windows Scroll the window
Scrolling window assigner Distribute elements to windows of the specified size . The size of the scrolling window is fixed , And their respective ranges do not overlap .
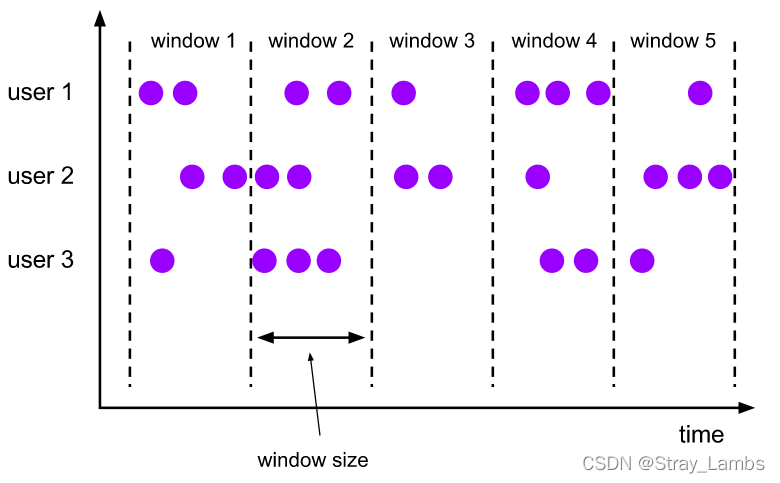
The time interval can be used Time.milliseconds(x)、Time.seconds(x)、Time.minutes(x) Wait to specify . Here is the official sample code .
DataStream<T> input = ...;
// rolling event-time window
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// rolling processing-time window
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.second(5)))
.<windowed transformation>(<window function>);
// A one-day roll event-time window , The offset for the -8 Hours
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>); As shown in the previous example , Scrolling window assigners You can also pass in optional offset Parameters . This parameter can be used to align windows . for instance , Not set up offset when , A scrolling window with a length of one hour will interact with linux Of epoch alignment . You will get as 1:00:00.000 - 1:59:59.999、2:00:00.000 - 2:59:59.999 etc. . If you want to change the alignment , You can set one offset. If set 15 Minutes of offset, You will get 1:15:00.000 - 2:14:59.999、2:15:00.000 - 3:14:59.999 etc. . An important offset Use cases are based on UTC-0 Adjust the time difference of the window . for instance , In China, you may set offset by Time.hours(-8).
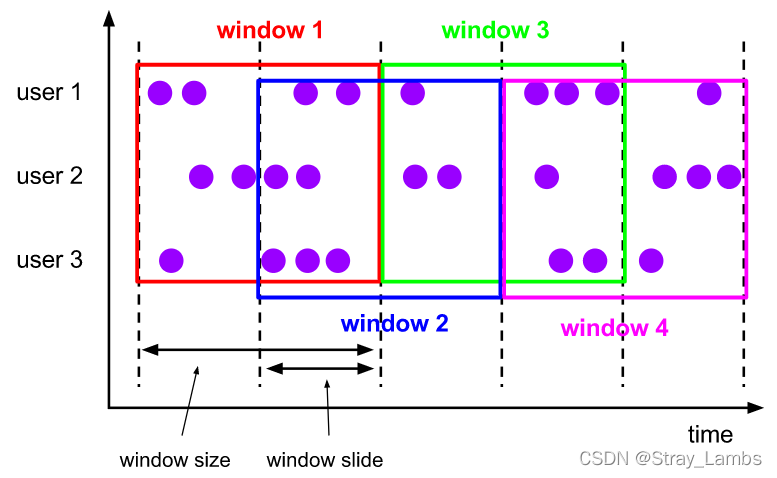
Sliding Windows The sliding window
Sliding window's assigner Distribute elements to windows of the specified size , Window size through window size Parameter setting . Sliding window requires one Extra sliding distance ( Sliding step window slide) Parameter to control the frequency of generating new windows . therefore , If slide Smaller than window size , Sliding windows allows windows to overlap . In this case , An element may be distributed to multiple windows .
for instance , You set the size to 10 minute , Sliding distance 5 Minute window , You will be in every 5 Minutes to get a new window , It contains the previous 10 Data arriving in minutes ( As shown in the figure below ).
The example code is as follows :
DataStream<T> input = ...;
// slide event-time window
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// slide processing-time window
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// slide processing-time window , The offset for the -8 Hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>);Session Windows Session window
Session window Of assigner Will group data by active session . And Scroll the window and The sliding window Different , Session windows do not overlap , And there is no fixed start or end time . The session window is It will be closed after a period of time without receiving data , That is, after an inactive interval . Conversation window assigner Sure Set a fixed session interval (session gap) or use session gap extractor function To dynamically define how long it counts as inactive . When the inactive period is exceeded , The current session will close , And distribute the next data to the new session window .
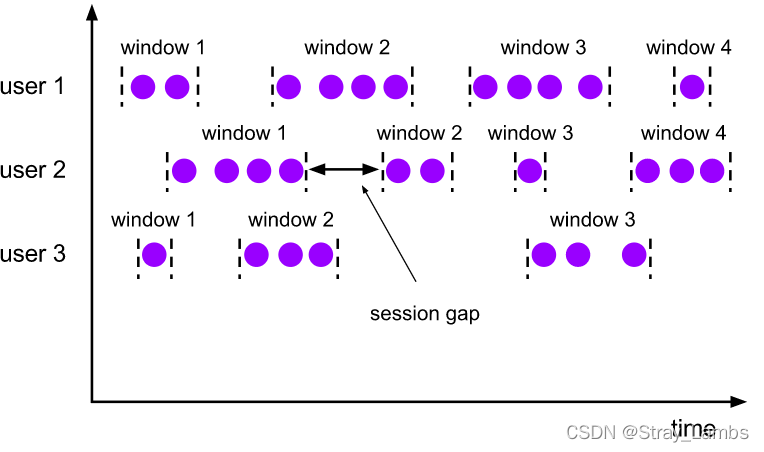
Dynamic intervals can be achieved by SessionWindowTimeGapExtractor Interface to specify .
DataStream<T> input = ...;
// With fixed interval event-time Session window
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// Set the dynamic interval event-time Session window
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element)-> {
// Determines and returns the session interval
}))
.<windowed transformation>(<window function>);
// With fixed interval processing-time session window
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// Set the dynamic interval processing-time Session window
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// Determines and returns the session interval
}))
.<windowed transformation>(<window function>);The session window has no fixed start or end time , So its calculation method is different from sliding window and rolling window . stay Flink Inside , The operator of the session window will create a window for each piece of data , Then merge the windows whose distance does not exceed the preset interval . Want windows to be merged , The session window needs to have a Trigger and Window Function, for instance
ReduceFunction、AggregateFunctionorProcessWindowFunction.
Global Windows Global window
Global window Of assigner take Have the same key All data is distributed to one Global window . Such a window mode Only if you specify a custom trigger Useful when . otherwise , Calculations don't happen , Because the global window has no natural end point to trigger the accumulated data .

The example code is as follows :
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>);Triggers Window trigger
Trigger Decided a window ( from window assigner Definition ) When can be window function Handle . Generally speaking ,watermark The timestamp >=window endTime And there is data in the window , It will trigger the calculation of the window . Every WindowAssigner There is one. default Trigger. If default trigger Unable to meet demand , Can be in trigger(...) Call the custom trigger.
Trigger The interface provides five methods to correspond to different events :
- onElement() Method is called when each element is added to the window .
- onEventTime() Method is registered in event-time timer Called when triggered .
- onProcessiongTime() Method is registered in processing-time timer Called when triggered .
- onMerge() Methods and stateful trigger relevant . This method will when two windows merge , Corresponding window trigger Merge the status of , For example, when using the session window .
- Last ,clear() Method handles the logic required when the corresponding window is removed .
There are two points to note :
1、 The first three methods By returning TriggerResult To decide trigger How to deal with events that arrive at the window . There are several solutions :
- CONTINUE: Do nothing
- FIRE: Trigger calculation
- PURGE: Empty the elements in the window
- FIRE_AND_PURGE: Trigger calculation , After the calculation, empty the elements in the window
2、 Any of the above methods can be used to register processing-time or event-time timer.
Trigger (Fire) And clear (Purge)
When trigger When determining that a window can be calculated , It will trigger , That is to say return FIRE or FIRE_AND_PURGE. This is a signal for the window operator to send the calculation result of the current window . If a window specifies ProcessWindowFunction, All elements will be passed to ProcessWindowFunction. If it is ReduceFunction or AggregateFunction, Then send the aggregated results directly .
When trigger When triggered , It can return to FIRE or FIRE_AND_PURGE. FIRE The contents of the triggered window will be preserved , and FIRE_AND_PURGE Will delete these contents . Flink Built in trigger By default FIRE, The status of the window will not be cleared .
Purge Only the contents of the window will be removed , Will not remove about the window meta-information and trigger The state of .
WindowAssigner default Triggers
WindowAssigner default Trigger Enough to cope with many situations . for instance , be-all event-time window assigner All default to EventTimeTrigger. This trigger Will be in watermark Trigger directly after crossing the end time of the window .
GlobalWindow Default trigger It will never trigger NeverTrigger. therefore , Use GlobalWindow when , You have to define a trigger.
When you are intrigger()A... Is specified in trigger when , You actually cover the currentWindowAssignerdefault trigger. for instance , If you specify aCountTriggertoTumblingEventTimeWindows, Your window will no longer trigger based on time , It is triggered according to the number of elements . If you want the response time , And the number of responses , You need to customize trigger 了 .
built-in Triggers And customization Triggers
Flink Contains some built-in trigger.
- As mentioned before
EventTimeTriggeraccording to watermark Measured event time Trigger . ProcessingTimeTriggeraccording to processing time Trigger .CountTriggerTriggered when the element in the window exceeds the preset limit .PurgingTriggerReceive another trigger And convert it into a that will clean up the data trigger.
If you need to implement custom trigger, You should look at this abstract class Trigger . Please note that , This API Still developing , So later Flink There may be changes in the version .
Window Functions Window function
Defined window assigner after , We need to specify when the window is triggered , How do we calculate the data in each window , This is it. window function The responsibility of the .
There are three kinds of window functions :ReduceFunction、AggregateFunction or ProcessWindowFunction. The first two are more efficient ( because Will pre aggregate , See State Size) because Flink Can be in After each data reaches the window, it will be aggregated incrementally (incrementally aggregate). and ProcessWindowFunction You will get a that can traverse all the data in the current window Iterable, And about this window meta-information.
Use ProcessWindowFunction The window conversion operation of is not as efficient as the other two functions , because Flink Before the window is triggered, you must cache the all data . ProcessWindowFunction It can be done with ReduceFunction or AggregateFunction Merge to improve efficiency . By doing so, you can incrementally aggregate the data in the window , Again from ProcessWindowFunction Receive window of metadata. Let's next look at examples of each function .
ReduceFunction
ReduceFunction Specifies how two pieces of input data are combined to produce one piece of output data , Input and output data must be of the same type . Flink Use ReduceFunction Incremental aggregation of data in the window .
ReduceFunction It can be defined as :
DataStream<Tuple2<String, Long>> input = ...;
// The above example is to sum the second attribute of tuples in the window .
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});AggregateFunction
ReduceFunction yes AggregateFunction In special circumstances . AggregateFunction Receive three types : Type of input data (IN)、 Type of accumulator (ACC) And the type of output data (OUT). The type of input data is the element type of the input stream ,AggregateFunction The interface has the following methods : Add each element to the accumulator 、 Create initial accumulator 、 Merge two accumulators 、 Extract the output from the accumulator (OUT type ). We illustrate with the following example .
And ReduceFunction identical ,Flink Incremental aggregation will be carried out directly when the input data reaches the window .
AggregateFunction It can be defined as :
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
// The above example calculates the average value of the second attribute of all elements in the window .
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate());ProcessWindowFunction
ProcessWindowFunction Can get all the elements in the window Iterable, And to obtain time and status information Context object , More flexible than other window functions . ProcessWindowFunction Flexibility is At the cost of performance and resource consumption Of , Because the data in the window cannot be incrementally aggregated , Before the window triggers Cache all data .
ProcessWindowFunction Whose signature is as follows :
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> implements Function {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
*
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
public abstract void process(
KEY key,
Context context,
Iterable<IN> elements,
Collector<OUT> out) throws Exception;
/**
* The context holding window metadata.
*/
public abstract class Context implements java.io.Serializable {
/**
* Returns the window that is being evaluated.
*/
public abstract W window();
/** Returns the current processing time. */
public abstract long currentProcessingTime();
/** Returns the current event-time watermark. */
public abstract long currentWatermark();
/**
* State accessor for per-key and per-window state.
*
* <p><b>NOTE:</b>If you use per-window state you have to ensure that you clean it up
* by implementing {@link ProcessWindowFunction#clear(Context)}.
*/
public abstract KeyedStateStore windowState();
/**
* State accessor for per-key global state.
*/
public abstract KeyedStateStore globalState();
}
}key Parameters from keyBy() Specified in the KeySelector elect . If so, give key stay tuple Medium index Or specified in string form of attribute name key, This key The type of will always Tuple, And you need to manually convert it to the correct size tuple To extract key.
ProcessWindowFunction It can be defined as :
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
The above example uses ProcessWindowFunction Count the elements in the window , And output the information of the window itself .
Be careful , Use ProcessWindowFunction To complete a simple aggregation task is Very inefficient Of . Incremental aggregated ProcessWindowFunction
ProcessWindowFunction It can be done with ReduceFunction or AggregateFunction Use it with , So that it can be carried out when the data reaches the window Incremental aggregation . When the window closes ,ProcessWindowFunction You will get the result of aggregation . In this way, it can incrementally aggregate the elements of the window and start from ProcessWindowFunction Get the metadata of the window in .
You can also deal with outdated WindowFunction Use incremental aggregation .
Use ReduceFunction Incremental aggregation
The following example shows how to ReduceFunction And ProcessWindowFunction Combine , Returns the smallest element in the window and the start time of the window .
DataStream<SensorReading> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
// Function definitions
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));
}
}
Use AggregateFunction Incremental aggregation
The following example shows how to AggregateFunction And ProcessWindowFunction Combine , Calculate the average value and corresponding to the window key Output together .
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate(), new MyProcessWindowFunction());
// Function definitions
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<Double, Tuple2<String, Double>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<Double> averages,
Collector<Tuple2<String, Double>> out) {
Double average = averages.iterator().next();
out.collect(new Tuple2<>(key, average));
}
}
stay ProcessWindowFunction Use in per-window state
In addition to access keyed state ( Any rich function can ),ProcessWindowFunction You can also use scope only “ Currently processing window ” Of keyed state. under these circumstances , understand per-window Medium window What it means is very important . There are several windows to understand :
- Windows defined in window operations : For example, it defines An hour long scrolling window or Two hours long 、 Slide the sliding window for an hour .
- Corresponding to a certain key Window instance : such as With user-id xyz by key, from 12:00 To 13:00 Time window of . The specific situation depends on the definition of the window , According to the concrete key And time periods will produce many different window instances .
Per-window state Act on the latter . in other words , If we deal with 1000 Species difference key Events , And at present, all events are in [12:00, 13:00) In the time window , Then we will get 1000 Window instances , And each instance has its own keyed per-window state.
process() The received Context There are two methods in the object that allow us to access the following two state:
globalState(), Access global keyed statewindowState(), Access scope is limited to the current window keyed state
If you could put one window Trigger multiple times ( For example, when your late data will trigger window calculation again , Or you have customized the window that triggers in advance according to speculation trigger), Then this function will be very useful . At this time, you may need to per-window state Information about the previous trigger or the total number of triggers is stored in .
When using window state , Be sure to clear these states when deleting windows . They should be defined in clear() In the method .
Evictors
Flink The window model of allows you to WindowAssigner and Trigger Specify optional Evictor. As shown in the code at the beginning of this article , adopt evictor(...) Methods the incoming Evictor. Evictor Can be in trigger After triggering 、 Remove elements from the window before or after calling the window function . Evictor Interface provides two methods to realize this function :
/**
* Optionally evicts elements. Called before windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* Optionally evicts elements. Called after windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);evictBefore() Contains the logic before calling the window function , and evictAfter() The logic contained after the window function call . Elements removed before calling the window function are not evaluated by the window function .
Flink There are three built-in evictor:
CountEvictor: Record only the number of elements specified by the user , Once the number of elements in the window exceeds this number , Redundant elements are removed from the beginning of the window cacheDeltaEvictor: receiveDeltaFunctionandthresholdParameters , Calculate the difference between the last element and all elements in the window cache , And remove the difference greater than or equal tothresholdThe elements of .TimeEvictor: receiveintervalParameters , In milliseconds . It finds the maximum number of elements in the window timestampmax_tsAnd remove the ratiomax_ts - intervalAll small elements .
By default , All built-in evictor The logic is executed before the window function is called .
To specify a evictor Pre polymerization can be avoided , Because all elements in the window must pass through before calculation evictor.
Flink There is no guarantee about the order of elements in the window . in other words , Even if evictor Remove an element from the beginning of the window cache , This element does not necessarily arrive at the window first or last .
Late data
In the use of event-time At the window , Data may be late , namely Flink For tracking event-time Progressive watermark Has crossed the end of the window timestamp after , The data arrived . In fact, late data is a special case of disordered data , The data came much longer than watermark The prediction of , As a result, the window has been closed before the data arrives .
Generally, for late data , take 3 There are two ways to deal with :
- Reactivate the closed window and recalculate to correct the result
- Collect the late data and process it separately
- Discard the late data as error information
Flink The default processing method is to discard directly , The other two are Side Output and Allowed Lateness.
Side Output Mechanism Late events can be Put a data flow branch separately , It's going to be window The by-product of the result of the calculation , So that users can get it and handle it specially .
Allowed Lateness Mechanism Allow users to set A maximum allowable late time .Flink After the window is closed, the state of the window will be saved until the allowed tardiness time is exceeded , Late events during this period will not be discarded , Instead, it triggers window recalculation by default . Because saving window state requires extra memory , And if window computing uses ProcessWindowFunction API It may also cause each late event to trigger a full computation of the window , It costs a lot , Therefore, it is not suitable to set the length of late time too long , We should not have too many late incidents , Otherwise, it should be considered to reduce the speed of water level increase or adjust the algorithm .
Allowed Lateness
By default ,watermark Once the window is over timestamp, Late data will be discarded directly . however Flink Allows you to specify the maximum window operator allowed lateness. Allowed lateness Defines how long an element can be late without being discarded , This parameter defaults to 0. stay watermark Beyond the end of the window 、 Add... At the end of the window allowed lateness Elements that arrive in the previous period of time , Will still be added to the window . Depends on the window trigger, An element that is late but not discarded may trigger the window again , such as EventTimeTrigger.
In order to achieve this function ,Flink The window state will be saved to allowed lateness Timeout will delete the window and its status ( Such as Window Lifecycle Described ).
By default ,allowed lateness Is set to 0. namely watermark Elements that arrive later are discarded .
You can specify as follows allowed lateness:
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.<windowed transformation>(<window function>);Use
GlobalWindowswhen , No data will be considered late , Because of the end of the global window timestamp yesLong.MAX_VALUE.
side output
adopt Flink Of Bypass output ( Side output stream ) function , You can get the data flow of late data .
First , You need to open the window stream Upper use sideOutputLateData(OutputTag) Indicates that you need to get late data . then , You can get the bypass output stream from the result of window operation .
final OutputTag<T> lateOutputTag = new OutputTag<T>("late-data"){};
DataStream<T> input = ...;
SingleOutputStreamOperator<T> result = input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.sideOutputLateData(lateOutputTag)
.<windowed transformation>(<window function>);
DataStream<T> lateStream = result.getSideOutput(lateOutputTag);Some considerations about late data
When greater than is specified 0 Of allowed lateness when , The window itself and its contents will still be watermark Leave after crossing the end of the window . At this time , If a late but not discarded data arrives , It may trigger this window again . This trigger is called late firing, And... Representing the first trigger window main firing To distinguish . If you use the session window ,late firing Existing windows may be further merged , Because they may connect existing 、 Unmerged windows .
You should pay attention to :late firing The emitted element should be treated as an update to the previous calculation , That is, your data flow will contain multiple results of the same computing task . Your application needs to consider these repeated results , Or remove duplicate parts .
Consider the size of the state
Windows can be defined over a long period of time ( Like a few days 、 Weeks or months ) And accumulate a lot of state . When you estimate the storage requirements calculated by the window , There are a few rules to remember :
Flink A copy of an element is created in each window it belongs to . therefore , Only one copy of an element will exist in the settings of the scrolling window ( An element belongs to only one window , Unless it's late ). By contrast , An element may be copied into multiple sliding windows , Just as we are Window Assigners As described in . therefore , Set a size to one day 、 A sliding window with a sliding distance of one second may not be a good idea .
ReduceFunctionandAggregateFunctionCan greatly reduce storage requirements , Because they will aggregate the arriving elements in place , And each window only stores one value . While usingProcessWindowFunctionYou need to accumulate all the elements in the window .Use
EvictorPre polymerization can be avoided , Because all the data in the window must pass through evictor To calculate .
Reference resources
[ Vernacular analysis ] Flink Of Watermark Mechanism - Rossi's thinking - Blog Garden
Apache Flink Ramble series (03) - Watermark- Alicloud developer community
边栏推荐
猜你喜欢

吴军三部曲见识(五) 拒绝伪工作者

关于Selenium启动Chrome浏览器闪退问题

Wu Jun's trilogy experience (VII) the essence of Commerce
C#版Selenium操作Chrome全屏模式显示(F11)
应用服务配置器(定时,数据库备份,文件备份,异地备份)

Shawshank's sense of redemption
数据仓库建模使用的模型以及分层介绍
Flink 解析(二):反压机制解析
JVM运行时数据区之程序计数器
04 products and promotion developed by individuals - data push tool
随机推荐
【逆向初级】独树一帜
EasyRE WriteUp
JVM 垃圾回收器之Serial SerialOld ParNew
Prototype chain inheritance
mysql 基本增删改查SQL语句
Akamai 反混淆篇
Flexible report v1.0 (simple version)
[reverse] repair IAT and close ASLR after shelling
mysql高級(索引,視圖,存儲過程,函數,修改密碼)
复盘网鼎杯Re-Signal Writeup
Only learning C can live up to expectations top3 demo exercise
06个人研发的产品及推广-代码统计工具
03个人研发的产品及推广-计划服务配置器V3.0
微信防撤回是怎么实现的?
Control transfer instruction
Akamai talking about risk control principles and Solutions
Connect to LAN MySQL
PostgreSQL 14.2, 13.6, 12.10, 11.15 and 10.20 releases
Final review of information and network security (based on the key points given by the teacher)
Redis quick start