当前位置:网站首页>Flink 解析(七):时间窗口
Flink 解析(七):时间窗口
2022-07-06 09:32:00 【Stray_Lambs】
目录
在 ProcessWindowFunction 中使用 per-window state
时间概念
由于Flink框架中实时流处理事件中,时间在计算中起到很大的作用。例如进行时间序列分析、基于特定时间段(窗口)进行聚合或者是重要情况下的事件处理。Flink的DataStream支持三种time:EventTime、IngestTime和ProcessingTime,并且有大量的基于time的operator。
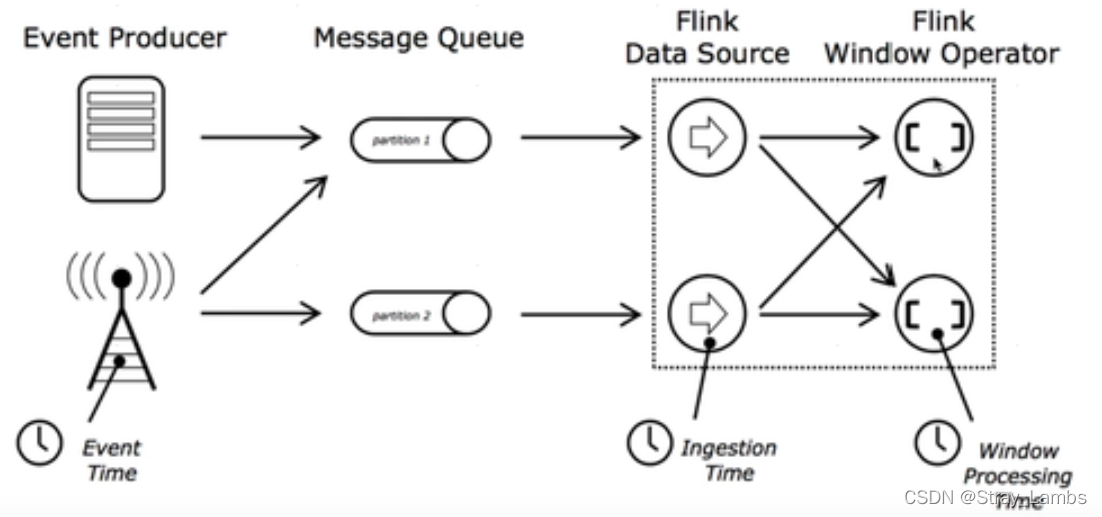
这三种时间进行比较:
- EventTime
- 事件生成的时间,在进入Flink之间就已经存在,可以从event的字段中抽取
- 必须指定watermarks的生成方式
- 优势:确定性,在乱序、延时或者数据重复等情况下,都能给出正确的结果
- 弱点:处理无序事件时性能和延迟受到影响
- IngestTime(基本上很少用…)
- 事件进入Flink的时间,即在source里获取的当前系统的时间,后续操作统一使用该时间
- 不需要指定watermarks的生成方式(自动生成)
- 弱点:不能处理无序时间和延迟数据
- ProcessingTime
- 执行操作的机器的当前系统时间(每个算子都不一样)
- 不需要流和机器之间的协调
- 优势:最佳的性能和最低的延迟
- 弱点:不确定性,容易受到各种因素影响(例如event产生的速度、到达flink的速度、在算子之间传输速度等),压根就不管顺序和延迟
综上所述:
- 性能:ProcessingTime>IngestTime>EventTime
- 延迟:ProcessingTime<IngestTime<EventTime
- 确定性:ProcessingTime<IngestTime<EventTime
如果不设置Time类型,默认是processingTime,一般工程上基本上使用的都是EventTime。若是需要使用EventTime,则需要在source之后明确指定Timestamp Assigner & Watermark Generator。
WaterMarks与窗口概念
在讲水位watermarks之前,我们可以考虑一下水位要解决的问题是什么。在实际的流式计算工作场景中,事件的顺序对于计算结果的正确性有着一定的影响,但是,因为网络延迟或者存储自身的原因,导致了数据出现了延迟以及乱序的情况,比如第一秒产生的数据在第5秒才到。
所以针对这个问题,Flink提出了watermark,专门处理EventTime窗口计算,其本质其实就是一个时间戳。因为对于迟到数据late element,不可能一直无限期等待,必须有一个机制来保证一个特定的时间后,必须取触发window去进行计算,这种机制就是watermark,可以理解为 watermark是一种告诉Flink消息延迟多少的方式,等待多久迟到数据。一般是由Flink Source或者自定义的watermark生成器按照需求生成,然后跟着普通数据流流向下游算子,接收到watermark的算子会根据新到来的watermark进行取一个max的操作。
watermark数据结构
在Flink DataStream中流动着多种不一样的元素,统称为StreamElement,StreamElement可以是StreamRecord、Watermark、StreamStatus、LatencyMarker中的任何一种类型,是一个抽象类(Flink类承载消息的基类),其他四种类型继承StreamElement。
public abstract class StreamElement {
//判断是否是Watermark
public final boolean isWatermark() {
return getClass() == Watermark.class;
}
//判断是否为StreamStatus
public final boolean isStreamStatus() {
return getClass() == StreamStatus.class;
}
//判断是否为StreamRecord
public final boolean isRecord() {
return getClass() == StreamRecord.class;
}
//判断是否为LatencyMarker
public final boolean isLatencyMarker() {
return getClass() == LatencyMarker.class;
}
//转换为StreamRecord
public final <E> StreamRecord<E> asRecord() {
return (StreamRecord<E>) this;
}
//转换为Watermark
public final Watermark asWatermark() {
return (Watermark) this;
}
//转换为StreamStatus
public final StreamStatus asStreamStatus() {
return (StreamStatus) this;
}
//转换为LatencyMarker
public final LatencyMarker asLatencyMarker() {
return (LatencyMarker) this;
}
}其中,watermark是继承了StreamElement。Watermark 是和事件一个级别的抽象,其内部包含一个成员变量时间戳timestamp,标识当前数据的时间进度。Watermark实际上作为数据流的一部分随数据流流动。
目前Flink有两种生成watermark的方式
- Punctuated:通过数据流中某些特殊标记事件来触发新水位线的生成。这种方式下窗口的触发与时间无关,而是决定于何时收到标记事件,即数据流中每一个递增的eventTime都会产生一个Watermark。在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求很高的场景才会选择Punctuated的方式生成watermark。
- Periodic:周期性的(如一定时间间隔或者达到一定的记录条数)产生的一个Watermark。在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延迟。
所以Watermark的生成方式需要根据业务场景的不同进行不同的选择。
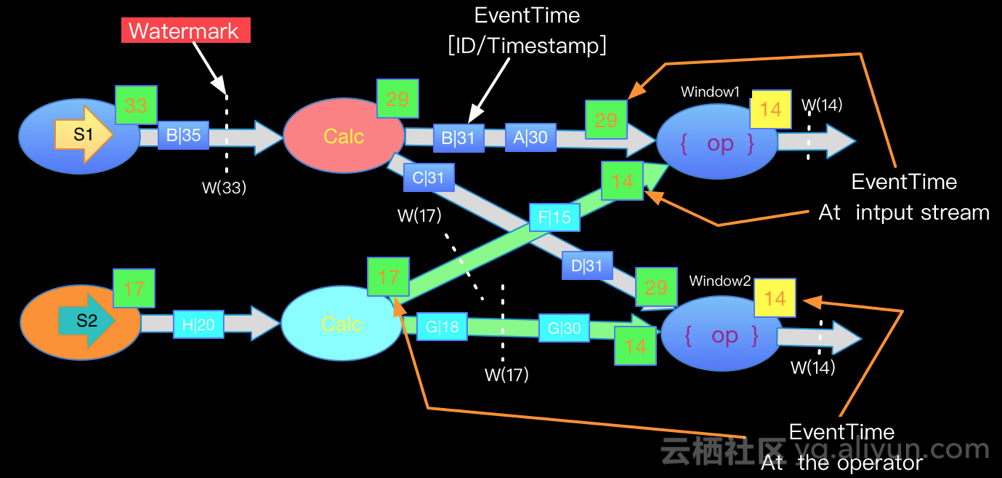
多源watermark处理
如果在实际的流处理过程中,一个job存在着多个source的数据,例如经过了groupby分组之后,相同的key就会shuffle到同一个节点中,并且具有不同的watermark。因为Flink内部为了保证watermark保持单调递增,Flink会选择所有流入的EventTime中最小的一个向下游流出。从而保证watermark的单调递增和保证数据的完整性。如下图(这里放一下其他大佬的图):
窗口
Flink中的窗口可以分成:滚动窗口(Tumbling Window,无重叠),滑动窗口(Sliding Window,可能有重叠),会话窗口(Session Window,活动间隙),全局窗口(Gobal Window)
一般程序中指定完keyed之后,定义window assigner。Window assigner 定义了 stream 中的元素如何被分发到各个窗口。 你可以在 window(...)(用于 keyed streams)或 windowAll(...) (用于 non-keyed streams)中指定一个 WindowAssigner。 WindowAssigner 负责将 stream 中的每个数据分发到一个或多个窗口中。 Flink 为最常用的情况提供了一些定义好的 window assigner,也就是 tumbling windows、 sliding windows、 session windows 和 global windows。 你也可以继承 WindowAssigner 类来实现自定义的 window assigner。 所有内置的 window assigner(除了 global window)都是基于时间分发数据的,processing time 或 event time 均可。
而且基于时间的窗口用[start timestamp,end timestamp)左闭右开来描述床阔的大小。在Flink代码中,处理基于时间的窗口使用的是TimeWindow,它有查询开始和结束timestamp方法以及返回窗口所能存储的最大timestamp的方法maxTimestamp()。
Tumbling Windows 滚动窗口
滚动窗口的assigner分发元素到指定大小的窗口。滚动窗口的大小是固定的,且各自范围之间不重叠。
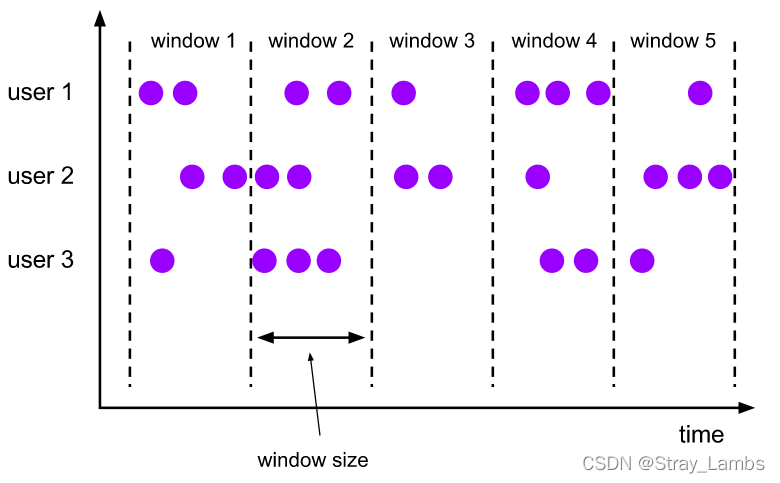
时间间隔可以用Time.milliseconds(x)、Time.seconds(x)、Time.minutes(x)等来指定。下面给一下官方的样例代码。
DataStream<T> input = ...;
// 滚动event-time窗口
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// 滚动processing-time窗口
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.second(5)))
.<windowed transformation>(<window function>);
// 长度为一天的滚动event-time窗口, 偏移量为-8小时
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>);如上一个例子所示,滚动窗口的 assigners 也可以传入可选的 offset 参数。这个参数可以用来对齐窗口。 比如说,不设置 offset 时,长度为一小时的滚动窗口会与 linux 的 epoch 对齐。 你会得到如 1:00:00.000 - 1:59:59.999、2:00:00.000 - 2:59:59.999 等。 如果你想改变对齐方式,你可以设置一个 offset。如果设置了 15 分钟的 offset, 你会得到 1:15:00.000 - 2:14:59.999、2:15:00.000 - 3:14:59.999 等。 一个重要的 offset 用例是根据 UTC-0 调整窗口的时差。比如说,在中国你可能会设置 offset 为 Time.hours(-8)。
Sliding Windows 滑动窗口
滑动窗口的assigner 分发元素到指定大小的窗口,窗口大小通过 window size 参数设置。 滑动窗口需要一个额外的滑动距离(滑动步长window slide)参数来控制生成新窗口的频率。 因此,如果 slide 小于窗口大小,滑动窗口可以允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
比如说,你设置了大小为 10 分钟,滑动距离 5 分钟的窗口,你会在每 5 分钟得到一个新的窗口, 里面包含之前 10 分钟到达的数据(如下图所示)。
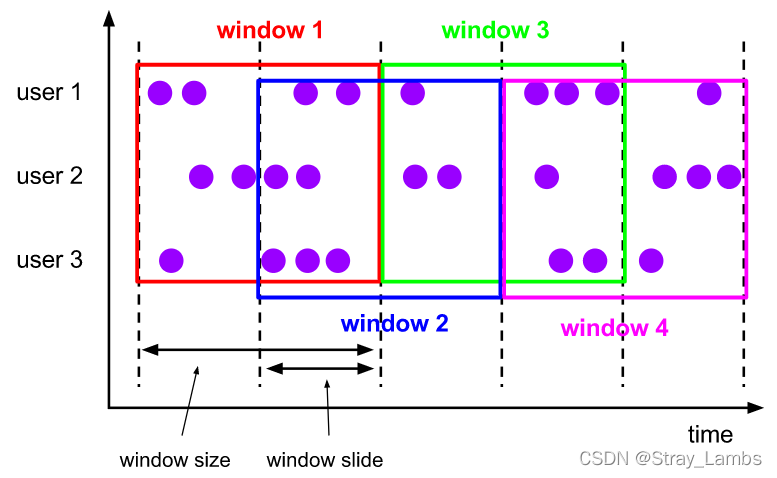
实例代码如下:
DataStream<T> input = ...;
// 滑动 event-time 窗口
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// 滑动 processing-time 窗口
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// 滑动 processing-time 窗口,偏移量为 -8 小时
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>);Session Windows 会话窗口
会话窗口的 assigner 会把数据按活跃的会话分组。 与滚动窗口和滑动窗口不同,会话窗口不会相互重叠,且没有固定的开始或结束时间。 会话窗口在一段时间没有收到数据之后会关闭,即在一段不活跃的间隔之后。 会话窗口的 assigner 可以设置固定的会话间隔(session gap)或 用 session gap extractor 函数来动态地定义多长时间算作不活跃。 当超出了不活跃的时间段,当前的会话就会关闭,并且将接下来的数据分发到新的会话窗口。
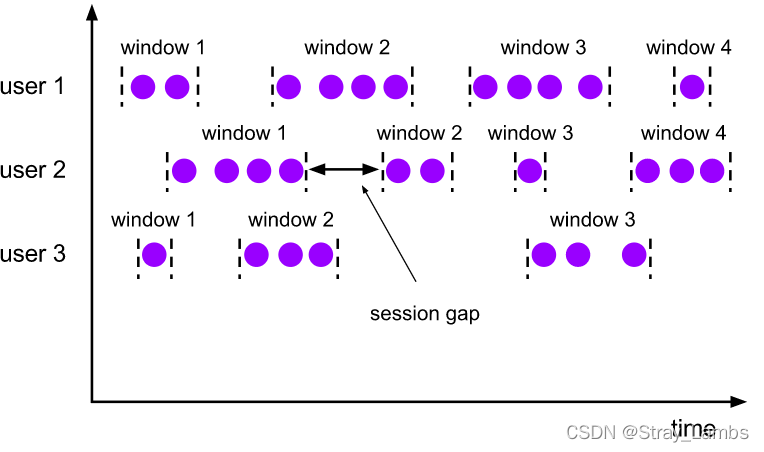
动态间隔可以通过实现 SessionWindowTimeGapExtractor 接口来指定。
DataStream<T> input = ...;
// 设置了固定间隔的event-time会话窗口
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// 设置了动态间隔的event-time会话窗口
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element)-> {
// 决定并返回会话间隔
}))
.<windowed transformation>(<window function>);
// 设置了固定间隔的 processing-time session 窗口
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// 设置了动态间隔的 processing-time 会话窗口
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
.<windowed transformation>(<window function>);会话窗口并没有固定的开始或结束时间,所以它的计算方法与滑动窗口和滚动窗口不同。在 Flink 内部,会话窗口的算子会为每一条数据创建一个窗口, 然后将距离不超过预设间隔的窗口合并。 想要让窗口可以被合并,会话窗口需要拥有支持合并的 Trigger 和 Window Function, 比如说
ReduceFunction、AggregateFunction或ProcessWindowFunction。
Global Windows 全局窗口
全局窗口的 assigner 将拥有相同 key 的所有数据分发到一个全局窗口。 这样的窗口模式仅在你指定了自定义的 trigger 时有用。 否则,计算不会发生,因为全局窗口没有天然的终点去触发其中积累的数据。

实例代码如下:
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>);Triggers 窗口触发
Trigger决定了一个窗口(由window assigner定义)何时可以被window function处理。一般来说,watermark的时间戳>=window endTime并且在窗口内有数据,就会触发窗口的计算。每个WindowAssigner都有一个默认的Trigger。如果默认trigger无法满足需求,可以在trigger(...)调用中指定自定义的trigger。
Trigger接口提供了五个方法来相应不同的事件:
- onElement() 方法在每个元素被加入窗口时调用。
- onEventTime()方法在注册的event-time timer触发时调用。
- onProcessiongTime()方法在注册的processing-time timer触发时调用。
- onMerge()方法与有状态的trigger相关。该方法会在两个窗口合并时,将窗口对应trigger的状态进行合并,比如使用会话窗口时。
- 最后,clear()方法处理在对应窗口被移除时所需的逻辑。
有两点需要注意:
1、前三个方法通过返回TriggerResult来决定trigger如何应对到达窗口的事件。应对方案有以下几种:
- CONTINUE:什么也不做
- FIRE:触发计算
- PURGE:清空窗口内的元素
- FIRE_AND_PURGE: 触发计算,计算结束后清空窗口内的元素
2、上面的任意方法都可以用来注册processing-time或event-time timer。
触发(Fire)与清除(Purge)
当 trigger 认定一个窗口可以被计算时,它就会触发,也就是返回 FIRE 或 FIRE_AND_PURGE。 这是让窗口算子发送当前窗口计算结果的信号。 如果一个窗口指定了 ProcessWindowFunction,所有的元素都会传给 ProcessWindowFunction。 如果是 ReduceFunction 或 AggregateFunction,则直接发送聚合的结果。
当 trigger 触发时,它可以返回 FIRE 或 FIRE_AND_PURGE。 FIRE 会保留被触发的窗口中的内容,而 FIRE_AND_PURGE 会删除这些内容。 Flink 内置的 trigger 默认使用 FIRE,不会清除窗口的状态。
Purge 只会移除窗口的内容, 不会移除关于窗口的 meta-information 和 trigger 的状态。
WindowAssigner 默认的 Triggers
WindowAssigner 默认的 Trigger 足以应付诸多情况。 比如说,所有的 event-time window assigner 都默认使用 EventTimeTrigger。这个 trigger 会在 watermark 越过窗口结束时间后直接触发。
GlobalWindow 的默认 trigger 是永远不会触发的 NeverTrigger。因此,使用 GlobalWindow 时,你必须自己定义一个 trigger。
当你在trigger()中指定了一个 trigger 时, 你实际上覆盖了当前WindowAssigner默认的 trigger。 比如说,如果你指定了一个CountTrigger给TumblingEventTimeWindows,你的窗口将不再根据时间触发, 而是根据元素数量触发。如果你希望即响应时间,又响应数量,就需要自定义 trigger 了。
内置 Triggers 和自定义 Triggers
Flink 包含一些内置 trigger。
- 之前提到过的
EventTimeTrigger根据 watermark 测量的 event time 触发。 ProcessingTimeTrigger根据 processing time 触发。CountTrigger在窗口中的元素超过预设的限制时触发。PurgingTrigger接收另一个 trigger 并将它转换成一个会清理数据的 trigger。
如果你需要实现自定义的 trigger,你应该看看这个抽象类 Trigger 。 请注意,这个 API 仍在发展,所以在之后的 Flink 版本中可能会发生变化。
Window Functions 窗口函数
定义了 window assigner 之后,我们需要指定当窗口触发之后,我们如何计算每个窗口中的数据, 这就是 window function 的职责了。
窗口函数有三种:ReduceFunction、AggregateFunction 或 ProcessWindowFunction。 前两者执行起来更高效(因为会预聚合,详见 State Size)因为 Flink 可以在每条数据到达窗口后进行增量聚合(incrementally aggregate)。 而 ProcessWindowFunction 会得到能够遍历当前窗口内所有数据的 Iterable,以及关于这个窗口的 meta-information。
使用 ProcessWindowFunction 的窗口转换操作没有其他两种函数高效,因为 Flink 在窗口触发前必须缓存里面的所有数据。 ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 合并来提高效率。 这样做既可以增量聚合窗口内的数据,又可以从 ProcessWindowFunction 接收窗口的 metadata。 我们接下来看看每种函数的例子。
ReduceFunction
ReduceFunction 指定两条输入数据如何合并起来产生一条输出数据,输入和输出数据的类型必须相同。 Flink 使用 ReduceFunction 对窗口中的数据进行增量聚合。
ReduceFunction 可以像下面这样定义:
DataStream<Tuple2<String, Long>> input = ...;
//上面的例子是对窗口内元组的第二个属性求和。
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});AggregateFunction
ReduceFunction 是 AggregateFunction 的特殊情况。 AggregateFunction 接收三个类型:输入数据的类型(IN)、累加器的类型(ACC)和输出数据的类型(OUT)。 输入数据的类型是输入流的元素类型,AggregateFunction 接口有如下几个方法: 把每一条元素加进累加器、创建初始累加器、合并两个累加器、从累加器中提取输出(OUT 类型)。我们通过下例说明。
与 ReduceFunction 相同,Flink 会在输入数据到达窗口时直接进行增量聚合。
AggregateFunction 可以像下面这样定义:
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
// 上例计算了窗口内所有元素第二个属性的平均值。
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate());ProcessWindowFunction
ProcessWindowFunction 有能获取包含窗口内所有元素的 Iterable, 以及用来获取时间和状态信息的 Context 对象,比其他窗口函数更加灵活。 ProcessWindowFunction 的灵活性是以性能和资源消耗为代价的, 因为窗口中的数据无法被增量聚合,而需要在窗口触发前缓存所有数据。
ProcessWindowFunction 的签名如下:
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> implements Function {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
*
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
public abstract void process(
KEY key,
Context context,
Iterable<IN> elements,
Collector<OUT> out) throws Exception;
/**
* The context holding window metadata.
*/
public abstract class Context implements java.io.Serializable {
/**
* Returns the window that is being evaluated.
*/
public abstract W window();
/** Returns the current processing time. */
public abstract long currentProcessingTime();
/** Returns the current event-time watermark. */
public abstract long currentWatermark();
/**
* State accessor for per-key and per-window state.
*
* <p><b>NOTE:</b>If you use per-window state you have to ensure that you clean it up
* by implementing {@link ProcessWindowFunction#clear(Context)}.
*/
public abstract KeyedStateStore windowState();
/**
* State accessor for per-key global state.
*/
public abstract KeyedStateStore globalState();
}
}key 参数由 keyBy() 中指定的 KeySelector 选出。 如果是给出 key 在 tuple 中的 index 或用属性名的字符串形式指定 key,这个 key 的类型将总是 Tuple, 并且你需要手动将它转换为正确大小的 tuple 才能提取 key。
ProcessWindowFunction 可以像下面这样定义:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
上例使用 ProcessWindowFunction 对窗口中的元素计数,并且将窗口本身的信息一同输出。
注意,使用 ProcessWindowFunction 完成简单的聚合任务是 非常低效的。 增量聚合的 ProcessWindowFunction
ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 搭配使用, 使其能够在数据到达窗口的时候进行增量聚合。当窗口关闭时,ProcessWindowFunction 将会得到聚合的结果。 这样它就可以增量聚合窗口的元素并且从 ProcessWindowFunction中获得窗口的元数据。
你也可以对过时的 WindowFunction 使用增量聚合。
使用 ReduceFunction 增量聚合
下例展示了如何将 ReduceFunction 与 ProcessWindowFunction 组合,返回窗口中的最小元素和窗口的开始时间。
DataStream<SensorReading> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
// Function definitions
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));
}
}
使用 AggregateFunction 增量聚合
下例展示了如何将 AggregateFunction 与 ProcessWindowFunction 组合,计算平均值并与窗口对应的 key 一同输出。
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate(), new MyProcessWindowFunction());
// Function definitions
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<Double, Tuple2<String, Double>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<Double> averages,
Collector<Tuple2<String, Double>> out) {
Double average = averages.iterator().next();
out.collect(new Tuple2<>(key, average));
}
}
在 ProcessWindowFunction 中使用 per-window state
除了访问 keyed state (任何富函数都可以),ProcessWindowFunction 还可以使用作用域仅为 “当前正在处理的窗口”的 keyed state。在这种情况下,理解 per-window 中的 window 指的是什么非常重要。 总共有以下几种窗口的理解:
- 在窗口操作中定义的窗口:比如定义了长一小时的滚动窗口或长两小时、滑动一小时的滑动窗口。
- 对应某个 key 的窗口实例:比如 以 user-id xyz 为 key,从 12:00 到 13:00 的时间窗口。 具体情况取决于窗口的定义,根据具体的 key 和时间段会产生诸多不同的窗口实例。
Per-window state 作用于后者。也就是说,如果我们处理有 1000 种不同 key 的事件, 并且目前所有事件都处于 [12:00, 13:00) 时间窗口内,那么我们将会得到 1000 个窗口实例, 且每个实例都有自己的 keyed per-window state。
process() 接收到的 Context 对象中有两个方法允许我们访问以下两种 state:
globalState(),访问全局的 keyed statewindowState(), 访问作用域仅限于当前窗口的 keyed state
如果你可能将一个 window 触发多次(比如当你的迟到数据会再次触发窗口计算, 或你自定义了根据推测提前触发窗口的 trigger),那么这个功能将非常有用。 这时你可能需要在 per-window state 中储存关于之前触发的信息或触发的总次数。
当使用窗口状态时,一定记得在删除窗口时清除这些状态。他们应该定义在 clear() 方法中。
Evictors
Flink 的窗口模型允许在 WindowAssigner 和 Trigger 之外指定可选的 Evictor。 如本文开篇的代码中所示,通过 evictor(...) 方法传入 Evictor。 Evictor 可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素。 Evictor 接口提供了两个方法实现此功能:
/**
* Optionally evicts elements. Called before windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* Optionally evicts elements. Called after windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);evictBefore() 包含在调用窗口函数前的逻辑,而 evictAfter() 包含在窗口函数调用之后的逻辑。 在调用窗口函数之前被移除的元素不会被窗口函数计算。
Flink 内置有三个 evictor:
CountEvictor: 仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除DeltaEvictor: 接收DeltaFunction和threshold参数,计算最后一个元素与窗口缓存中所有元素的差值, 并移除差值大于或等于threshold的元素。TimeEvictor: 接收interval参数,以毫秒表示。 它会找到窗口中元素的最大 timestampmax_ts并移除比max_ts - interval小的所有元素。
默认情况下,所有内置的 evictor 逻辑都在调用窗口函数前执行。
指定一个 evictor 可以避免预聚合,因为窗口中的所有元素在计算前都必须经过 evictor。
Flink 不对窗口中元素的顺序做任何保证。也就是说,即使 evictor 从窗口缓存的开头移除一个元素,这个元素也不一定是最先或者最后到达窗口的。
迟到数据
在使用 event-time 窗口时,数据可能会迟到,即 Flink 用来追踪 event-time 进展的 watermark 已经越过了窗口结束的 timestamp 后,数据才到达。实际上迟到数据就是乱序数据的一个特例,数据来的时间远超出了watermark的预计,导致窗口在数据到来之前就已经关闭了。
一般针对于迟到数据,采取3种方式处理:
- 重新激活已经关闭的窗口并重新计算以修正结果
- 将迟到数据收集起来另作处理
- 将迟到数据当成错误信息直接丢弃
Flink默认处理的方式是直接进行丢弃,其他两种分别是Side Output和Allowed Lateness。
Side Output机制可以将迟到事件单独放入一个数据流分支,这会作为 window 计算结果的副产品,以便用户获取并对其进行特殊处理。
Allowed Lateness机制允许用户设置一个允许的最大迟到时长。Flink 会在窗口关闭后一直保存窗口的状态直至超过允许迟到时长,这期间的迟到事件不会被丢弃,而是默认会触发窗口重新计算。因为保存窗口状态需要额外内存,并且如果窗口计算使用了 ProcessWindowFunction API 还可能使得每个迟到事件触发一次窗口的全量计算,代价比较大,所以允许迟到时长不宜设得太长,迟到事件也不宜过多,否则应该考虑降低水位线提高的速度或者调整算法。
Allowed Lateness
默认情况下,watermark 一旦越过窗口结束的 timestamp,迟到的数据就会被直接丢弃。 但是 Flink 允许指定窗口算子最大的 allowed lateness。 Allowed lateness 定义了一个元素可以在迟到多长时间的情况下不被丢弃,这个参数默认是 0。 在 watermark 超过窗口末端、到达窗口末端加上 allowed lateness 之前的这段时间内到达的元素, 依旧会被加入窗口。取决于窗口的 trigger,一个迟到但没有被丢弃的元素可能会再次触发窗口,比如 EventTimeTrigger。
为了实现这个功能,Flink 会将窗口状态保存到 allowed lateness 超时才会将窗口及其状态删除 (如 Window Lifecycle 所述)。
默认情况下,allowed lateness 被设为 0。即 watermark 之后到达的元素会被丢弃。
你可以像下面这样指定 allowed lateness:
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.<windowed transformation>(<window function>);使用
GlobalWindows时,没有数据会被视作迟到,因为全局窗口的结束 timestamp 是Long.MAX_VALUE。
side output
通过 Flink 的 旁路输出(侧输出流) 功能,你可以获得迟到数据的数据流。
首先,你需要在开窗后的 stream 上使用 sideOutputLateData(OutputTag) 表明你需要获取迟到数据。 然后,你就可以从窗口操作的结果中获取旁路输出流了。
final OutputTag<T> lateOutputTag = new OutputTag<T>("late-data"){};
DataStream<T> input = ...;
SingleOutputStreamOperator<T> result = input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.sideOutputLateData(lateOutputTag)
.<windowed transformation>(<window function>);
DataStream<T> lateStream = result.getSideOutput(lateOutputTag);迟到数据的一些考虑
当指定了大于 0 的 allowed lateness 时,窗口本身以及其中的内容仍会在 watermark 越过窗口末端后保留。 这时,如果一个迟到但未被丢弃的数据到达,它可能会再次触发这个窗口。 这种触发被称作 late firing,与表示第一次触发窗口的 main firing 相区别。 如果是使用会话窗口的情况,late firing 可能会进一步合并已有的窗口,因为他们可能会连接现有的、未被合并的窗口。
你应该注意:late firing 发出的元素应该被视作对之前计算结果的更新,即你的数据流中会包含一个相同计算任务的多个结果。你的应用需要考虑到这些重复的结果,或去除重复的部分。
关于状态大小的考量
窗口可以被定义在很长的时间段上(比如几天、几周或几个月)并且积累下很大的状态。 当你估算窗口计算的储存需求时,可以铭记几条规则:
Flink 会为一个元素在它所属的每一个窗口中都创建一个副本。 因此,一个元素在滚动窗口的设置中只会存在一个副本(一个元素仅属于一个窗口,除非它迟到了)。 与之相反,一个元素可能会被拷贝到多个滑动窗口中,就如我们在 Window Assigners 中描述的那样。 因此,设置一个大小为一天、滑动距离为一秒的滑动窗口可能不是个好想法。
ReduceFunction和AggregateFunction可以极大地减少储存需求,因为他们会就地聚合到达的元素, 且每个窗口仅储存一个值。而使用ProcessWindowFunction需要累积窗口中所有的元素。使用
Evictor可以避免预聚合, 因为窗口中的所有数据必须先经过 evictor 才能进行计算。
参考
边栏推荐
- ~86m rabbit practice
- 字节跳动春招攻略:学长学姐笔经面经,还有出题人「锦囊」
- Only learning C can live up to expectations Top1 environment configuration
- 唯有学C不负众望 TOP3 Demo练习
- Basic knowledge of assembly language
- 冯诺依曼体系结构
- Activit零零碎碎要人命的坑
- The 116 students spent three days reproducing the ByteDance internal real technology project
- Data config problem: the reference to entity 'useunicode' must end with ';' delimiter.
- Introduction to microservices
猜你喜欢
算数运算指令
arithmetic operation
Resume of a microservice architecture teacher with 10 years of work experience

字节跳动技术面试官现身说法:我最想pick什么样的候选人
![Saw local status change event StatusChangeEvent [timestamp=1644048792587, current=DOWN, previous=UP]](/img/e6/c53ad67ead1793a2acb93c26e8d377.jpg)
Saw local status change event StatusChangeEvent [timestamp=1644048792587, current=DOWN, previous=UP]

was unable to send heartbeat
Mongodb learning notes
原型链继承

Activiti目录(四)查询代办/已办、审核
服务器端渲染(SSR)和客户端渲染(CSR)的区别
随机推荐
Activiti directory (III) deployment process and initiation process
8086 segmentation technology
Activiti directory (V) reject, restart and cancel process
字节跳动多篇论文入选 CVPR 2021,精选干货都在这里了
js垃圾回收机制和内存泄漏
我走過最迷的路,是字節跳動程序員的腦回路
汇编课后作业
~79 Movie card exercise
字节跳动2022校招研发提前批宣讲会,同学们最关心的10个问题
How to configure hosts when setting up Eureka
「博士毕业一年,我拿下 ACL Best Paper」
Full record of ByteDance technology newcomer training: a guide to the new growth of school recruitment
Set up the flutter environment pit collection
DOS function call
Assembly language addressing mode
Shell_ 07_ Functions and regular expressions
Erlang installation
Logical operation instruction
汇编语言段定义
Error occurred during initialization of VM Could not reserve enough space for object heap