当前位置:网站首页>Mongodb learning notes
Mongodb learning notes
2022-07-06 16:58:00 【Xiaoxiamo】
MongoDB Relevant concepts
Business application scenarios
Traditional relational database ( Such as MySQL), In data manipulation “ Three tenors ” Demand and response Web2.0 In front of the needs of the website , Seems to be out of his depth . explain :“ Three tenors ” demand :
- High performance - High concurrent read and write requirements for database .
- Huge Storage - The need for efficient storage and access of massive data .
- High Scalability && High Availability- The need for high scalability and high availability of databases .
and MongoDB Can cope with “ Three tenors ” demand .
Specific application scenarios such as :
- Social scene , Use MongoDB Store and store user information , As well as the user's published circle of friends information , By geolocation index to achieve people around 、 Location and other functions .
- Game scenario , Use MongoDB Store game user information , User's equipment 、 Integration and so on are directly stored in the form of embedded documents , Convenient query 、 Efficient storage and access .
- Logistics scenario , Use MongoDB Store order information , The order status will be updated during shipment , With MongoDB In the form of an embedded array to store , One query can read all the changes of the order .
- Internet of things scenario , Use MongoDB Store all the connected smart device information , And the log information reported by the equipment , And the multi-dimensional analysis of these information .
- Live video , Use MongoDB Store user information 、 Like interactive information, etc .
In these application scenarios , The common feature of data manipulation is
- Large amount of data
- Write operations are frequent ( Reading and writing are very frequent )
- Lower value data , It's not very transactional
For such data , We are better suited to use MongoDB To achieve data storage .
When to choose MongoDB
In terms of architecture selection , In addition to the above three features , If you're still hesitant to choose it ? Consider the following questions :
- Applications don't need transaction and complexity join Support
- New application , Demand will change. , The data model cannot be determined , Want to develop quickly and iteratively
- Applications need to be 2000-3000 The above reading and writing QPS( It can be higher )
- Applications need to be TB even to the extent that PB Level data storage
- Applications are developing rapidly , Need to be able to scale quickly and horizontally
- The application requires that the stored data is not lost
- Applications need to be 99.999% High availability
- Applications need a lot of location queries 、 Text query
If there is 1 A meet , You can consider MongoDB,2 More than one match , choice MongoDB Never regret .
MongoDB brief introduction
MongoDB It's open source 、 High performance 、 A modeless document database , It was designed to simplify development and facilitate expansion , yes NoSQL One of the database products . It is most like a relational database (MySQL) Non relational database .
The data structure it supports is very loose , It's something like JSON Of Format call BSON, So it can store complex data types , And quite flexible .
MongoDB The record in is a document , It is a pair of fields and values (field:value) Data structure of composition .MongoDB The document is similar to JSON object , That is, a document is considered an object . The data type of the field is character , Its value, in addition to using some basic types , Other documents can also be included 、 Normal array and document array .
Architecture
MySQL and MongoDB contrast
| SQL The term / Concept | MongoDB The term / Concept | explain / explain |
|---|---|---|
| database | database | database |
| table | collection | Database table / aggregate |
| row | document | Data record row / file |
| column | field | Data field / Domain |
| index | index | Indexes |
| table joins | Table joins ,MongoDB I won't support it | |
| The embedded document | MongoDB Replace multi table joins with embedded documents | |
| primary key | primary key | Primary key ,MongoDB Automatically put _id Field sets the primary key |
Data model
MongoDB The smallest unit of storage is the document (document) object . file (document) Object corresponds to a row in a relational database . The data is in MongoDB China and Israel BSON(Binary-JSON) The format of the document is stored on disk .
BSON(Binary Serialized Document Format) Is a kind json A storage format in binary form , abbreviation Binary JSON.BSON and JSON equally , Support embedded document objects and array objects , however BSON Yes JSON There are no data types , Such as Date and BinData type .
BSON Similar to C The name of the language structure 、 For the representation , Support embedded document objects and array objects , Lightweight 、 Ergodicity 、 Three characteristics of efficiency , It can effectively describe unstructured data and structured data . The advantage of this format is high flexibility , But its disadvantage is that the space utilization is not ideal .
Bson in , Except for the basic JSON type :string,integer,boolean,double,null,array and object,mongo Special data types are also used . These types include date,object id,binary data,regular expression and code. Each driver implements these types in a language specific way , Check the documentation of your driver for details .
BSON Data type reference list :
| data type | describe | give an example |
|---|---|---|
| character string | UTF-8 Strings can be represented as string type data | {“x” : “foobar”} |
| object id | object id It's a document 12 Byte unique ID | {“X” :ObjectId() } |
| Boolean value | True or false :true perhaps false | {“x”:true}+ |
| Array | A set or list of values can be represented as an array | {“x” : [“a”, “b”, “c”]} |
| 32 An integer | Type not available .JavaScript Support only 64 Bit floating point , therefore 32 Bit integers are automatically converted . | shell This type is not supported ,shell By default, it will be converted to 64 Bit floating point |
| 64 An integer | This type is not supported .shell A special embedded document will be used to display 64 An integer | shell This type is not supported ,shell By default, it will be converted to 64 Bit floating point |
| 64 Bit floating point | shell The numbers in are of this type | {“x”:3.14159,“y”:3} |
| null | Represents a null value or an undefined object | {“x”:null} |
| undefined | Undefined types can also be used in documents | {“x”:undefined} |
| Symbol | shell I won't support it ,shell The symbol type data in the database will be automatically converted into a string | |
| Regular expressions | Regular expressions can be included in documents , use JavaScript The regular expression syntax of | {“x” : /foobar/i} |
| Code | Documents can also contain JavaScript Code | {“x” : function() { /* …… */ }} |
| binary data | Binary data can be made up of any string of bytes , however shell Not available in | |
| Maximum / minimum value | BSON Include a special type , Indicates the maximum possible .shell There is no such type in . |
Tips :
shell By default 64 Bit floating point values .{“x”:3.14} or {“x”:3}. For integer values , have access to NumberInt(4 Byte sign integer ) or NumberLong(8 Byte sign integer ),{“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)}
MongoDB Characteristics
MongoDB It mainly has the following characteristics :
- High performance :
MongoDB Provides high performance data persistence . especially ,
Support for embedded data model reduces the number of I/O Activities .
Indexes support faster queries , And it can contain keys from embedded documents and arrays .( Text indexing addresses the need for search 、TTL Indexing solves the need for automatic expiration of historical data 、 The geo location index can be used to build various O2O application )
mmapv1、wiredtiger、mongorocks(rocksdb)、in-memory Multi engine support to meet the needs of various scenarios .
Gridfs Address the need for file storage . - High availability :
MongoDB Our replication tool is called replica set (replica set), It provides automatic failover and data redundancy . - High scalability :
MongoDB Provides horizontal scalability as part of its core functionality .
Fragmentation distributes data across a cluster of machines .( Mass data storage , Service capability level expansion )
from 3.4 Start ,MongoDB Support the creation of data areas based on slice keys . In a balanced cluster ,MongoDB Direct the reads and writes covered by an area only to those slices in the area . - Rich query support :
MongoDB Support rich query language , Supports read and write operations (CRUD), For example, data aggregation 、 Text search and geospatial query, etc . - Other features : Such as Modeless ( Dynamic mode )、 Flexible document model .
MongoDB Use
MongoDB install
There are many ways to install , Development can use docker run , Production can run according to actual needs
Shell Connect
Enter the following... At the command prompt shell Command to complete the login
mongo
or
mongo --host=127.0.0.1 --port=27017
View existing databases
>show databases
sign out mongodb
exit
More parameters can be viewed through the help :
mongo --help
Tips :
MongoDB javascript shell It's based on javascript Interpreter , So support js programmatic .
Basic common commands
Select and create databases
Select and create the syntax format of the database ( If the database does not exist, it will be created automatically ):
use Database name
View all database commands that have permission to view
show dbs
or
show databases
Be careful : stay MongoDB in , Collections are created only after content is inserted ! That is to say , Create set ( Data sheet ) Then insert another document ( Record ), The collection will actually create .
View the database commands currently in use
db
MongoDB The default database in is test, If you don't choose a database , The collection will be stored in test In the database .
in addition :
The database name can be any of the following conditions UTF-8 character string .
It cannot be an empty string ("").
Must not contain any ’ '( Space )、.、$、/、\ and \0 ( Null character ).
All lowercase .
most 64 byte .
Some database names are reserved , You can directly access these databases for special purposes .
admin: From a rights perspective , This is a "root" database . Add a user to the database , This user automatically inherits permissions for all databases . Some special
The specified server-side commands can only be run from this database , Such as listing all the databases or shutting down the server .
local: This data will never be copied , Can be used to store any collection limited to a single local server
config: When Mongo Used for sharding Settings ,config The database is used internally , Used to save information about sharding .
Database deletion
MongoDB The syntax format for deleting a database is as follows :
db.dropDatabase()
Tips : It is mainly used to delete persistent databases
Set operations
aggregate , Similar to tables in relational databases .
Can display the creation of , You can also implicitly create .
Explicit creation of collections
Basic grammar :
db.createCollection(name)
Naming conventions for collections :
- The collection name cannot be an empty string "".
- The collection name cannot contain \0 character ( Null character ), This character represents the end of the collection name .
- The set name cannot be "system." start , This is the reserved prefix for the system set .
- User-created collection names cannot contain reserved characters . Some drivers do support inclusion in the collection name , This is because some system-generated collections contain this character . Unless you want to access a collection created by this system , Otherwise, don't put it in your name $.
Implicit creation of collections
When inserting a document into a collection , If the set doesn't exist , The collection is automatically created .
See Document insertion chapter .
Tips : Usually we can create documents implicitly .
Delete of collection
Set delete syntax format is as follows :
db.collection.drop()
or
db. aggregate .drop()
Return value
Successfully deletes the selected collection , be drop() Method returns true, Otherwise return to false.
for example : To delete mycollection aggregate
db.mycollection.drop()
Basic document CRUD
file (document) Data structure and JSON Is essentially the same .
All data stored in the collection is BSON Format .
Document insertion
Insert a single document
Use insert() or save() Method to insert a document into the collection , The grammar is as follows :
db.collection.insert(
<document or array of documents>,
{
writeConcern: <document>,
ordered: <boolean>
}
)
Parameters :
| Parameter | Type | Description |
|---|---|---|
| document | document or array | The document or document array to insert into the collection .((json Format ) |
| writeConcern | document | Optional. A document expressing the write concern. Omit to use the default write concern.See Write Concern.Do not explicitly set the write concern for the operation if run in atransaction. To use write concern with transactions, see Transactions and Write Concern. |
| ordered | boolean | Optional . If it is true , Then insert the documents in the array in order , If an error occurs in one of the documents ,MongoDB Will return without processing the rest of the documents in the array . If it is false , Then perform unordered insertion , If an error occurs in one of the documents , Then continue to process the main document in the array . In version 2.6+ China and Murdoch think true |
Example
Want to comment Set ( surface ) Insert a piece of test data :
db.comment.insert({"articleid":"100000","content":" It's a beautiful day , The sun is shining ","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null})
Tips :
- comment If the set doesn't exist , Will implicitly create
- mongo Number in , By default double type , If you want to save integers , Function must be used NumberInt( integer ), Otherwise, there will be a problem taking it out
- Insert the current date using new Date()
- The inserted data does not specify _id , The primary key value is automatically generated
- If a field has no value , It can be assigned to null, Or do not write this field
Be careful :
- Key in document / The value pairs are ordered
- A value in a document can be more than just a string in double quotes , It can also be several other data types ( It can even be an entire embedded document )
- MongoDB Case and type sensitive
- MongoDB The document cannot have duplicate keys
- The key of the document is a string . With a few exceptions , Keys can be arbitrary UTF-8 character
Document key naming conventions :
- The bond cannot contain \0 ( Null character ). This character is used to indicate the end of the key
- . and $ It has a special meaning , It can only be used in certain environments
- The following line "_" The opening key is reserved ( Not strictly required )
Batch insert
grammar :
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
Parameters :
| Parameter | Type | Description |
|---|---|---|
| document | document | The document or document array to insert into the collection .((json Format ) |
| writeConcern | document | Optional. A document expressing the write concern. Omit to use the default write concern.Do not explicitly set the write concern for the operation if run in a transaction. To use write concern with transactions, see Transactions and Write Concern. |
| ordered | boolean | Optional . A Boolean value , Appoint Mongod Should the instance be inserted in order or out of order . The default is true. |
Example :
db.comment.insertMany([
{"_id":"1","articleid":"100001","content":" We shouldn't waste the morning on cell phones , Health is very important , A cup of warm water happiness you, me and him .","userid":"1002","nickname":" Forget about the Jianghu ","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},
{"_id":"2","articleid":"100001","content":" I drink cold boiled water on an empty stomach in summer , Drink warm water in winter ","userid":"1005","nickname":" Yi people are haggard ","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},
{"_id":"3","articleid":"100001","content":" I drink cold water all the time , Drink in winter and summer .","userid":"1004","nickname":" Captain Jack ","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},
{"_id":"4","articleid":"100001","content":" Experts say you can't eat on an empty stomach , Affect health .","userid":"1003","nickname":" Caesar ","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},
{"_id":"5","articleid":"100001","content":" Studies have shown that , Just boiled water must not be drunk , Because it burns your mouth .","userid":"1003","nickname":" Caesar ","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}
]);
Tips :
When inserting _id , Then the primary key is the value .
If a piece of data fails to insert , Will terminate insertion , But the data that has been inserted successfully will not be rolled back .
Basic query of documents
The syntax format of the query data is as follows :
db.collection.find(<query>, [projection])
Parameters :
| Parameter | Type | Description |
|---|---|---|
| query | document | Optional . Use the query operator to specify the selection filter . To return all documents in the collection , Please omit this parameter or pass an empty document ( {} ). |
| projection | document | Optional . Specify the fields to be returned in the document that matches the query filter ( Projection ). To return all fields in the matching document , Please omit this parameter . |
Example :
- Query all
If we want to check spit All documents in the collection , Let's enter the following command
db.comment.find()
or
db.comment.find({})
- Look up a
For example, to check userid by 1003 The record of
db.comment.find({userid:'1003'})
or
db.comment.findOne({userid:'1003'})
- Projection query (Projection Query):
If you want the query result to return some fields , Then you need to use projection query ( Don't show all fields , Display only the specified fields ). Such as : The query results only show _id、userid、nickname :
>db.comment.find({userid:"1003"},{userid:1,nickname:1})
{ "_id" : "4", "userid" : "1003", "nickname" : " Caesar " }
{ "_id" : "5", "userid" : "1003", "nickname" : " Caesar " }
- Default _id Will be displayed , If you need the query results, only 、userid、nickname , No display _id :
>db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})
{ "userid" : "1003", "nickname" : " Caesar " }
{ "userid" : "1003", "nickname" : " Caesar " }
Document updates
Update the syntax of the document :
db.collection.update(query, update, options)
// or
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // Available starting in MongoDB 4.2
}
)
Parameters :
| Parameter | Type | Description |
|---|---|---|
| query | document | Updated selection criteria . Can be used with find() Method , similar sql update In the query where hinder .. stay 3.0 Changes have been made in : When using upsert:true perform update() when , If the query uses point notation, it is in _id Field , be MongoDB Insert of new document will be rejected |
| update | document or pipeline | Changes to apply . The value can be : Documents containing update operator expressions , Or just : Replacement document for , Or in the MongoDB 4.2 Start the polymerization pipeline in . Pipelines can consist of the following stages : Its other name set Its other name unset Its other name replaceWith. |
| upsert | boolean | Optional . If set to true, Create a new document when there is no document matching the query criteria . The default value is false, If no match is found , No new document will be inserted . |
| multi | boolean | Optional . If set to true, Update multiple documents that meet the query criteria . If set to false, Then update a document . The default value is false. |
| writeConcern | document | Optional . It means to write the document of the problem . The level at which an exception is thrown |
| collation | document | Optional . Specify the proofing rules to use for the operation |
| arrayFilters | array | Optional . An array of filtered documents , Used to determine which array elements to modify for the update operation on the array field . |
| hint | Document or string | Optional . Specifies the document or string used to support the index of the query predicate . This option can take the index specification document or the index name string . If the specified index does not exist , It means that the operation is wrong . for example , See version 4 Medium “ Specify a prompt for the update operation . |
Tips :
Focus on the first four parameters .
- Changes to overlay
If we want to modify _id by 1 The record of , The number of likes is 1001, Enter the following statement :
db.comment.update({_id:"1"},{likenum:NumberInt(1001)})
After execution , We will find that , This document is in addition to likenum The other fields are missing ,
- Partial modification
To solve this problem , We need to use modifiers $set To achieve , We want to modify _id by 2 The record of , The number of views is 889, Enter the following statement :
db.comment.update({_id:"2"},{$set:{likenum:NumberInt(889)}})
- Batch modification
Update all users to 1003 The user's nickname is Caesar the great
// By default, only the first data is modified
db.comment.update({userid:"1003"},{$set:{nickname:" Caesar 2"}})
// Modify all eligible data
db.comment.update({userid:"1003"},{$set:{nickname:" Caesar the great "}},{multi:true})
Tips : If you don't add the following parameters , Only the first record that meets the conditions is updated
- Modification of column value growth
If we want to increase or decrease the value of a column based on the original value , have access to $inc Operator to implement .
demand : Yes 3 The number of likes of the data No , Each increment 1
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})
Delete the document
Delete the syntax structure of the document :
db. Collection name .remove( Conditions )
The following statement can delete all the data , Please use with caution
db.comment.remove({})
If you remove _id=1 The record of , Enter the following statement
db.comment.remove({_id:"1"})
Paging query of documents
Statistics query
Statistical queries use count() Method , The grammar is as follows :
db.collection.count(query, options)
Parameters :
| Parameter | Type | Description |
|---|---|---|
| query | document | Query selection criteria . |
| options | document | Optional . Additional options for modifying the count . |
Tips :
Optional temporarily not used
Example :
- Count all records :
Statistics comment The number of all records in the set :
db.comment.count()
- Count the number of records by condition :
for example : Statistics userid by 1003 The number of records
db.comment.count({userid:"1003"})
Tips :
By default count() Method returns the number of all qualified records .
Pagination list query
have access to limit() Method to read a specified amount of data , Use skip() Method to skip a specified amount of data .
The basic syntax is as follows :
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
If you want to return a specified number of records , Can be in find After the method is called limit To return results (TopN), The default value is 20, for example :
db.comment.find().limit(3)
skip Method also accepts a numeric parameter as the number of records to skip .( front N No one ), The default value is 0
db.comment.find().skip(3)
Paging query : demand : each page 2 individual , The second page begins : Skip the first two data , Then the value shows 3 and 4 Data
// first page
db.comment.find().skip(0).limit(2)
// The second page
db.comment.find().skip(2).limit(2)
// The third page
db.comment.find().skip(4).limit(2)
Sort query
sort() Method to sort the data ,sort() Method can be used to specify the sorting field by parameter , And use 1 and -1 To specify how to sort , among 1 Arrange... In ascending order , and -1 It's for descending order .
The syntax is shown below :
db.COLLECTION_NAME.find().sort({KEY:1})
or
db. Collection name .find().sort( sort order )
for example :
Yes userid Descending order , And sort the traffic in ascending order
db.comment.find().sort({userid:-1,likenum:1})
Tips :
skip(), limilt(), sort() When the three are put together , The order of execution is first sort(), And then there was skip(), Finally, it shows limit(), It has nothing to do with the order of command writing .
More queries for documents
Regular complex conditional queries
MongoDB The fuzzy query is realized by regular expression . The format is :
db.collection.find({field:/ Regular expressions /})
or
db. aggregate .find({ Field :/ Regular expressions /})
Tips : The regular expression is js The grammar of , Direct quantity writing .
for example , I want to check the comments, which contain “ Boiled water ” All documents of , The code is as follows :
db.comment.find({content:/ Boiled water /})
If you want to query the content of comments with “ Experts ” At the beginning , The code is as follows :
db.comment.find({content:/^ Experts /})
Comparison query
<, <=, >, >= This operator is also very common , The format is as follows :
db. Collection name .find({ "field" : { $gt: value }}) // Greater than : field > value
db. Collection name .find({ "field" : { $lt: value }}) // Less than : field < value
db. Collection name .find({ "field" : { $gte: value }}) // Greater than or equal to : field >= value
db. Collection name .find({ "field" : { $lte: value }}) // Less than or equal to : field <= value
db. Collection name .find({ "field" : { $ne: value }}) // It's not equal to : field != value
Example : The number of comments and likes is greater than 700 The record of
db.comment.find({likenum:{$gt:NumberInt(700)}})
Contains the query
Include use $in The operator . Example : Query a collection of comments userid Field contains 1003 or 1004 Documents
db.comment.find({userid:{$in:["1003","1004"]}})
Does not include the use of $nin The operator . Example : Query the comments collection userid Field does not contain 1003 and 1004 Documents
db.comment.find({userid:{$nin:["1003","1004"]}})
Conditional join query
If we need to satisfy the above two conditions at the same time , Need to use $and Operator to associate conditions .( phase When SQL Of and) The format is :
$and:[ { },{ },{ } ]
Example : Query the comments collection likenum Greater than or equal to 700 And less than 2000 Documents :
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})
If the relationship between two or more conditions is or , We use Operators , With the front and It's the same way The format is :
$or:[ { },{ },{ } ]
Example : Query the comments collection userid by 1003, Or the number of likes is less than 1000 Documentation of
db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})
Summary of common commands
Select switch database :use articledb
insert data :db.comment.insert({bson data })
Query all the data :db.comment.find();
Condition query data :db.comment.find({ Conditions })
Query the first record that meets the criteria :db.comment.findOne({ Conditions })
Query the first few records that meet the criteria :db.comment.find({ Conditions }).limit( Number of pieces )
Query qualified skipped records :db.comment.find({ Conditions }).skip( Number of pieces )
Modifying data :db.comment.update({ Conditions },{ Revised data }) or db.comment.update({ Conditions },{$set:{ To modify the field of the part : data })
Modify the data and add a field value automatically :db.comment.update({ Conditions },{$inc:{ Self increasing field : Step value }})
Delete data :db.comment.remove({ Conditions })
Statistics query :db.comment.count({ Conditions })
Fuzzy query :db.comment.find({ Field name :/ Regular expressions /})
Conditional comparison operations :db.comment.find({ Field name :{$gt: value }})
Contains the query :db.comment.find({ Field name :{$in:[ value 1, value 2]}}) or db.comment.find({ Field name :{$nin:[ value 1, value 2]}})
Conditional join query :db.comment.find({$and:[{ Conditions 1},{ Conditions 2}]}) or db.comment.find({$or:[{ Conditions 1},{ Conditions 2}]})
Indexes -Index
summary
Index support in MongoDB Efficiently execute queries in . If there is no index ,MongoDB A full set scan must be performed , That is, scanning every document in the collection , To select the document that matches the query statement . The query efficiency of scanning the whole collection is very low , Especially when dealing with large amounts of data , Queries can take tens of seconds or even minutes , This can be deadly to the performance of your site .
If the query has an appropriate index ,MongoDB You can use this index to limit the number of documents that must be checked .
An index is a special data structure , It stores a small portion of the collection dataset in an easy to traverse form . An index stores the values of a particular field or group of fields , Sort by field value . The sorting of index entries supports efficient equality matching and range based query operations . Besides ,MongoDB You can also use the sort in the index to return the sort result .
MongoDB Index usage B Tree data structure ( Exactly B-Tree,MySQL yes B+Tree)
Type of index
Single field index
MongoDB Supports the creation of user-defined ascending order on a single field of a document / descending index , It's called a single field index (Single Field Index). For single field indexing and sorting operations , Sort order of index keys ( In ascending or descending order ) Not important , because MongoDB The index can be traversed in any direction .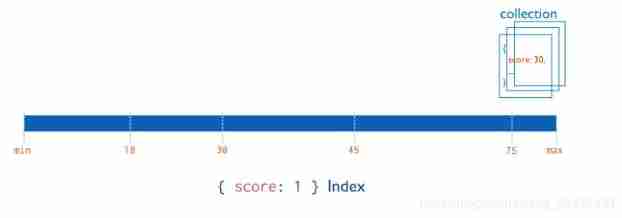
Composite index
MongoDB It also supports user-defined indexes for multiple fields , Composite index (Compound Index).
The order of the fields listed in a composite index is significant . for example , If the composite index is from { userid: 1, score: -1 } form , Then the index first presses userid Positive sequence sort , And then in each userid Within the value of , Press... Again score Reverse sort .
Other indexes
Geospatial index (Geospatial Index)、 Text index (Text Indexes)、 Hash index (Hashed Indexes).
Geospatial index (Geospatial Index):
In order to support the effective query of geospatial coordinate data ,MongoDB Two special indexes are provided : Use the two-dimensional index of plane geometry when returning the result and the two-dimensional spherical index of spherical geometry when returning the result .
Text index (Text Indexes):
MongoDB Provides a type of text index , Support searching string content in the collection . These text indexes don't store language specific stop words ( for example “the”、“a”、“or”), And the words in the set are used as stems , Store only the root word .
Hash index (Hashed Indexes):
To support hash based fragmentation ,MongoDB Provides a hash index type , It indexes a hash of field values . These indexes have a more random distribution of values within their ranges , But only equal matching is supported , Range based queries are not supported .
Index management operations
View index
explain :
Returns an array of all indexes in a collection .
grammar :
db.collection.getIndexes()
Tips : The syntax command is required to run MongoDB 3.0+
Example :
see comment All indexes in the set
> db.comment.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "articledb.comment"
}
]
The result shows the default _id Indexes .
Default _id Indexes :
MongoDB In the process of creating a collection , stay _id Create a unique index on the field , The default name is id , This index prevents the client from inserting two documents with the same value , You can't be in _id Delete this index from the field .
Be careful : The index is unique , So the value cannot be repeated , namely _id The value cannot be repeated . In a shard cluster , Usually use _id As a slice key .
Index creation
explain :
Create an index on a collection .
grammar :
db.collection.createIndex(keys, options)
| Parameter | Type | Description |
|---|---|---|
| keys | document | Documents that contain field and value pairs , Where the field is the index key , Value describes the index type of the field . For ascending indexes on fields , Please specify a value 1; For a descending index , Please specify a value -1. such as : { Field :1 or -1} , among 1 Creates an index in ascending order for the specified , If you want to create the index in descending order specify as -1 that will do . in addition ,MongoDB Supports several different index types , Including text 、 Geospatial and Hashi index . |
| options | document | Optional . A document containing a set of options that control index creation . For more information , See the list of options for details . |
options( More options ) list :
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | The indexing process blocks other database operations ,background You can specify backchannel mode to create indexes , That is, increase "background" Optional parameters . “background” The default value is false. |
| unique | Boolean | Is the index created unique . Designated as true Create unique index . The default value is false. |
| name | string | Name of index . If not specified ,MongoDB Generates an index name by concatenating the field name of the index and the sort order . |
| dropDups | Boolean | 3.0+ Version obsolete . Whether to delete duplicate records when establishing a unique index , Appoint true Create unique index . The default value is false. |
| sparse | Boolean | Indexes are not enabled for field data that does not exist in the document ; This parameter requires special attention , If set to true Words , Documents that do not contain corresponding fields are not queried in index fields .. The default value is false. |
| expireAfterSeconds i | integer | Specifies a value in seconds , complete TTL Set up , Sets the lifetime of the collection . |
| v | index version | The version number of the index . The default index version depends on mongod The version that runs when the index is created . |
| weights | document | Index weight , Values in 1 To 99,999 Between , Represents the score weight of the index relative to other index fields . |
| default_language | string | For text index , This parameter determines the list of stop words and the rules for the word stem and lexicon . Default to English |
| language_override | string | For text index , This parameter specifies the name of the field to be included in the document , The language overrides the default language, The default value is language. |
Tips :
Pay attention to 3.0.0 The index method created before version is db.collection.ensureIndex() , Later versions were used db.collection.createIndex() Method ,ensureIndex() Can also be used , But only createIndex() Another name for .
Example :
- Single field index example : Yes userid Field indexing :
> db.comment.createIndex({userid:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
- Composite index : Yes userid and nickname At the same time, build composite (Compound) Indexes :
> db.comment.createIndex({userid:1,nickname:-1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
Index removal
explain : You can remove the specified index , Or remove all indexes
One 、 Specifies the removal of the index
grammar :
db.collection.dropIndex(index)
| Parameter | Type | Description |
|---|---|---|
| index | string or document | Specify the index to delete . The index can be specified by index name or index specification document . To delete the text index , Please specify the index name . |
Example :
Delete comment Collection userid The ascending index on the field :
> db.comment.dropIndex({userid:1})
{ "nIndexesWas" : 3, "ok" : 1 }
Two 、 Removal of all indexes
grammar :
db.collection.dropIndexes()
Example :
Delete spit All indexes in the collection .
> db.comment.dropIndexes()
{
"nIndexesWas" : 2,
"msg" : "non-_id indexes dropped for collection",
"ok" : 1
}
Tips : _id The index of the field cannot be deleted , Only non can be deleted _id Index of field .
Use of index
Implementation plan
Analyze query performance (Analyze Query Performance) Execution plans are usually used ( Explain the plan 、Explain Plan) To check the status of the query , Such as the time consumed by the query 、 Whether it is based on index query, etc .
that , Usually , We want to know , Whether the index established is valid , What's the effect , All need to be checked through the execution plan .
grammar :
db.collection.find(query,options).explain(options)
Covered queries
When the query condition and query projection contain only index fields ,MongoDB Return results directly from the index , Without scanning any documents or bringing them into memory . These covered queries can be very efficient .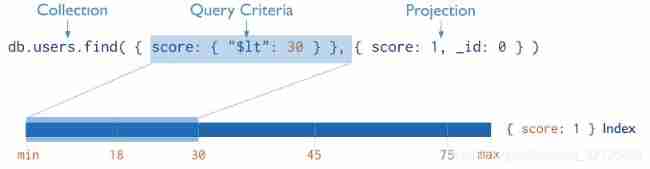
Replica set -Replica Sets
Introduction to replica set
MongoDB Replica sets in (Replica Set) It's a set of... That maintain the same dataset mongod service . Replica sets provide redundancy and high availability , Is the basis of all production deployment .
It can also be said that , Replica sets are similar to master-slave clusters with automatic fault recovery . Generally speaking, asynchronous synchronization of the same data with multiple machines , So that multiple machines have multiple copies of the same data , And when the primary database is down, it will automatically switch other backup servers as the primary database without user intervention . You can also use the replica server as a read-only server , Read and write separation , Increase load .
(1) Redundancy and data availability
Replication provides redundancy and improves data availability . By providing multiple copies of data on different database servers , Replication provides a level of fault tolerance , To prevent the loss of a single database server .
In some cases , Replication can provide increased read performance , Because the client can send the read operation to different services , Maintaining data copies in different data centers can increase the data location and availability of distributed applications . You can also maintain other copies for dedicated purposes , For example, disaster recovery , Report or backup .
(2)MongoDB Copy in
A replica set is a set of mongod example . The replica set contains multiple data hosting nodes and an optional quorum node . In the node that hosts the data , One and only one member is considered the master node , Other nodes are considered secondary ( from ) node .
The master node receives all writes . A replica set can only have one primary that can confirm that it has {w:“most”} Write attention to write ; Although in some cases , the other one mongod Examples may temporarily think that they are also major . It mainly records all changes of the dataset in its operation log , namely oplog.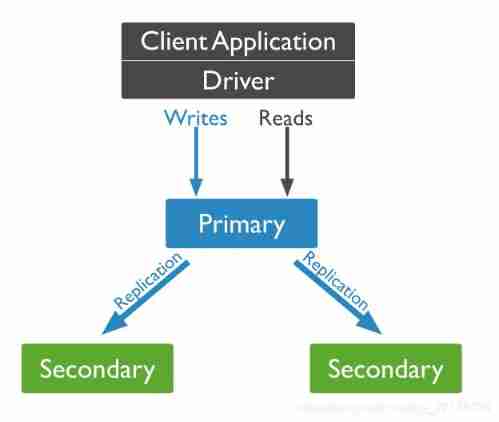
auxiliary ( copy ) Node copies the name of the master node oplog And apply the operation to its dataset , So that the data set of the secondary node reflects the data set of the primary node . If the key personnel are not present , Then eligible secondary schools will hold elections to elect new key personnel .
(3) The difference between master-slave replication and replica set
The biggest difference between master-slave cluster and replica set is that replica set is not fixed “ Master node ”; The whole cluster will choose one “ Master node ”, When it goes down , Select other nodes from the remaining nodes as “ Master node ”, There is always an active point in the replica set ( Lord 、primary) And one or more backup nodes ( from 、secondary).
The three roles of the replica set
There are two types of replica sets, three roles
Two types of :
- Master node (Primary) type : The main connection point for data operations , read-write .
- secondary ( auxiliary 、 from ) node (Secondaries) type : Data redundancy backup node , You can read or vote for .
Three roles :
leading member (Primary): All write operations are mainly received . It's the master node .
Replica member (Replicate): Maintain the same data set by copying from the master node , Backup data , Not writable , But you can read it ( But configuration is required ). Is a default slave node type .
arbiter (Arbiter): Do not keep a copy of any data , It only has the function of voting . Of course, you can also maintain the quorum server as part of the replica set , That is, copy members can also be arbitrators . It's also a slave node type .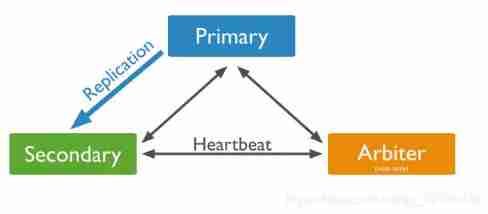
Additional instructions on the arbitrator :
You can add additional mongod Add instance to replica set as arbiter . The arbiter does not maintain the dataset . The purpose of the arbitrator is to maintain the arbitration in the replica set by responding to the heartbeat and election requests of other replica set members . Because they don't store datasets , So arbiter can be a good way to provide replica set Arbitration , Its resource cost is cheaper than full-featured replica set members with datasets .
If your replica set has even members , Please add an arbitrator to get... In the main election “ majority ” vote . The arbiter does not need dedicated hardware .
The arbiter will always be the arbiter , The primary personnel may quit and become secondary personnel , The minor personnel may become the main personnel during the election .
If your copy + The number of primary nodes is even , Suggest adding an arbitrator , Form an odd number , Easy to satisfy the majority of votes .
If your copy + The number of primary nodes is odd , There can be no arbiter .
The election principle of the master node
MongoDB In the replica set , The primary node will be selected automatically , Trigger conditions for master node election :
1) Primary node failure
2) The primary node network is unreachable ( The default heartbeat information is 10 second )
3) Artificial intervention (rs.stepDown(600))
Once the election is triggered , It is necessary to select the master node according to certain rules .
The election rule is to decide who wins by the number of votes :
- The highest number of votes , And got “ majority ” The node supported by the member's vote wins .
“ majority ” For the definition of : Suppose the number of voting members in the replica set is N, Most of them are N/2 + 1. for example :3 Voting members , Then most of the values are 2. When the number of live members in the replica set is less than most , The entire replica set will not be able to elect Primary, The replica set will not be able to provide write Services , In read-only state . - If the votes are the same , And they all got “ majority ” The members voted for , The new data node wins .
The old and new data is through the operation log oplog To compare .
When you get the votes , priority (priority) Parameters have a significant impact .
By setting the priority (priority) To set the number of additional votes . Priority is weight , The value is 0-1000, Equivalent to additional 0-1000 The number of votes , The higher the priority value , The more likely you are to get a majority vote (votes) Count . Specifying a higher value makes members more eligible to be primary members , Lower values make members more ineligible .
By default , The value of priority is 1 - The priority of the election node must be 0, It can't be any other value . That is, they do not have the right to vote , But have the right to vote
Fault test
Suppose there are three hosts as shown in Figure :node1、node2、node3 Set up a cluster , The following uses this cluster for fault testing 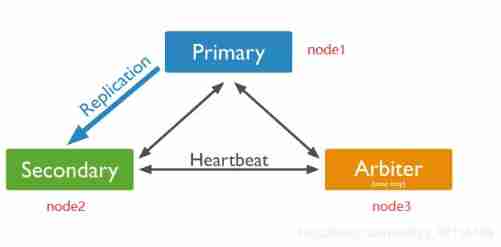
Replica node failure test
close node2 Replica node : Find out , Master node and arbitration node pair node2 My heart failed . Because the master node is still , therefore , There was no trigger to vote .
If at this time , Write data to the master node . Restart the slave node , Will find , Data written by the master node , It will be automatically synchronized to the slave node .
2 Master node fault test
close node1 node , Find out , Slave node and quorum node pair node1 My heart failed , When failure exceeds 10 second , At this time, because there is no master node , Will automatically initiate a vote . The replica node has only node2, therefore , There is only one candidate node2, Start voting .node3 towards node2 Voted for ,node2 Bring your own vote , So there are two votes , More than the “ majority ” ,node3 It's the arbitration node , There is no right to vote ,node2 Don't vote for it , The number of votes is 0. final result ,node2 Become the master node . It has the function of reading and writing .
Restart node1 node , Find out node1 Becomes a slave node ,node2 Keep master node . Sign in node1 node , It is found that it is from the node , Data automatically from node2 Sync . So high availability is realized .
The arbitration node and the master node fail
First turn off the current arbitration node node3, Turn off the current master node node2, Sign in node1 after , Find out ,node1 Still from the node , There is no master node in the replica set , In this time , The replica set is read-only , Unable to write .
Why not vote ? because node1 The number of votes , Didn't get the majority , That is, there is no greater than or equal to 2, It has only the default vote ( Priority is 1) If you want to trigger an election , Just join any member .
- If only node3 Quorum node members , Then the primary node must be node1, Because there's no choice , The arbitration node does not participate in the election , But vote .
- If only node2 node , There will be elections . because node1 and node2 Both are two votes , According to the new data , Who is the master node .
The arbitration node and the slave node fail
Turn off the arbitration node first node3, Turn off the current replica node node2 10 Seconds later ,node1 The master node is automatically demoted to the replica node .( service degradation ) Replica set is not writable , It has broken down .
Fragmentation cluster -Sharded Cluster
The concept of fragmentation
Fragmentation (sharding) Is a method of distributing data across multiple machines ,MongoDB Use fragmentation to support deployment with very large data sets and high throughput operations . let me put it another way : Fragmentation (sharding) It's splitting data , The process of dispersing it on different machines . Sometimes I use Partition (partitioning) To express the concept .
Spread data across different machines , More data can be stored without a powerful mainframe computer , Handle more load . Database systems with large datasets or high-throughput applications can challenge the capacity of a single server . for example , High query rate will deplete the server CPU Capacity . The size of the working set is larger than that of the system RAM Will emphasize the of disk drives I / O Capacity .
There are two solutions to system growth : Vertical expansion and Horizontal expansion .
Vertical expansion It means increasing the capacity of a single server , For example, use the more powerful CPU, Add more RAM Or increase the amount of storage space . The limitations of available technologies may limit the ability of a single machine to be powerful enough for a given workload . Besides , Cloud based providers have a hard cap based on the available hardware configurations . result , Vertical scaling has an actual maximum value .
Horizontal expansion It means dividing the system data set and loading multiple servers , Add additional servers to increase capacity as needed . Although the overall speed or capacity of a single machine may not be high , But each machine handles a subset of the entire workload , It may provide higher efficiency than a single high-speed high-capacity server . To expand the deployment capacity, you only need to add additional servers as needed , This may be lower than the overall cost of high-end hardware for a single machine . The tradeoff is the increased complexity of infrastructure and deployment maintenance .MongoDB Support horizontal expansion through fragmentation .
The components contained in the partitioned cluster
MongoDB A sharded cluster consists of the following components :
- Fragmentation ( Storage ): Each shard contains a subset of shard data . Each shard can be deployed as a replica set .
- mongos( route ):mongos Acting as a query router , Provide interfaces between client applications and sharded clusters .
- config servers(“ Dispatch ” Configuration of ): Configure the metadata and configuration settings of the server storage cluster . from MongoDB 3.4 Start , The configuration server must be deployed as a replica set (CSRS).
The following figure describes the interaction of components in a fragmented cluster :
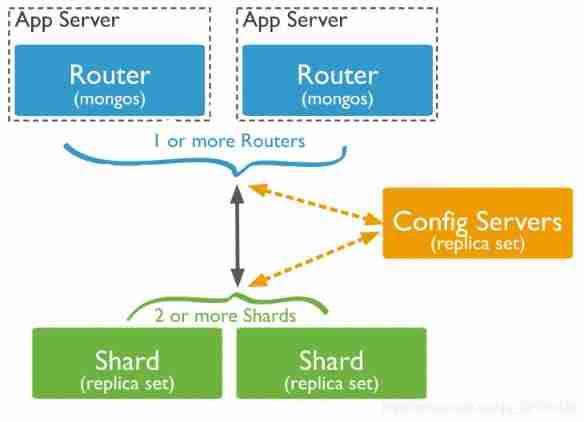
MongoDB Sharding data at the collection level , Distribute the set data on the slices in the cluster .
Safety certification
MongoDB User and role permissions for
By default ,MongoDB User access control is not enabled when the instance is started , in other words , On the local server of the instance, you can freely connect to the instance for various operations ,MongoDB There will be no user authentication for the connected client , This is very dangerous .
mongodb Said on the official website , In order to protect mongodb The following steps can be done for the safety of :
- Use the new port , default 27017 Once the port is known ip You can connect , Not very safe. .
- Set up mongodb Network environment , It is best to mongodb Deploy to the company server intranet , In this way, the Internet is inaccessible . Company internal access use vpn etc. .
- Turn on Safety Certification . The internal authentication mode between servers should be set at the same time , At the same time, set the account password authentication mode of the client connecting to the cluster .
To force user access control on ( User authentication ), You need to in MongoDB Use options when instance starts --auth Or add options... To the specified startup profile auth=true .
Basic concepts
- Enable access control :
MongoDB Using role-based access control (Role-Based Access Control,RBAC) To manage user access to instances . Control the user's access to database resources and database operations by granting one or more roles to the user , Before assigning roles to users , The user cannot access the instance .
Add options when the instance starts --auth Or specify options to add to the startup Profile auth=true . - role :
stay MongoDB The user is granted the operation authority of the corresponding database resource through the role , Permissions in each role can be explicitly specified , You can also do this by inheriting the permissions of other roles , Or both of them . - jurisdiction :
Permissions are assigned by the specified database resources (resource) And the operations allowed on the specified resources (action) form .
resources (resource) Include : database 、 aggregate 、 Partial collections and clusters ;
operation (action) Include : An increase in resources 、 Delete 、 Change 、 check (CRUD) operation .
One or more existing roles can be included in the role definition , The newly created role will inherit all the permissions of the included role . In the same database , The newly created role can inherit the permissions of other roles , stay admin The roles created in the database can inherit the permissions of roles in any other database .
Common built-in roles :
- Database user role :read、readWrite
- All database user roles :readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
- Database management role :dbAdmin、dbOwner、userAdmin
- The role of cluster management :clusterAdmin、clusterManager、clusterMonitor、hostManager
- Backup recovery role :backup、restore
- Super user role :root
- Internal roles :system
Role description :
| role | Permissions described |
|---|---|
| read | Can read any data in the specified database |
| readWrite | Can read and write any data in the specified database , Including the creation of 、 rename 、 Delete the collection |
| readAnyDatabase | Can read any data in all databases ( Besides databases config and local outside ) |
| readWriteAnyDatabase | Can read and write any data in all databases ( Besides databases config and local outside ) |
| userAdminAnyDatabase | Users can be created and modified in the specified database ( Besides databases config and local outside ) |
| dbAdminAnyDatabase | Can read any database and clean up the database 、 modify 、 Compress 、 Get statistics 、 Perform inspection, etc ( Besides databases config and local outside ) |
| dbAdmin | Can read the specified database and clean the database 、 modify 、 Compress 、 Get statistics 、 Perform inspection, etc |
| userAdmin | Users can be created and modified in the specified database |
| clusterAdmin | It can manage the whole cluster or database system |
| backup | Backup MongoDB Data minimum permissions |
| restore | Restore from backup file MongoDB data ( except system.profile aggregate ) Authority |
| root | Super account , Super authority |
边栏推荐
- Many papers on ByteDance have been selected into CVPR 2021, and the selected dry goods are here
- How to configure hosts when setting up Eureka
- Conception du système de thermomètre numérique DS18B20
- "One year after graduation, I won ACL best paper"
- Go language uses the thrift protocol to realize the client and service end reports not enough arguments in call to oprot Writemessagebegin error resolution
- Error occurred during initialization of VM Could not reserve enough space for object heap
- 7-8 likes (need to continue to improve)
- Shell_ 00_ First meeting shell
- Codeforces Round #771 (Div. 2)
- Shell_ 07_ Functions and regular expressions
猜你喜欢

ByteDance 2022 school recruitment R & D advance approval publicity meeting, students' top 10 issues

7-5 blessing arrived

Yao BanZhi and his team came together, and the competition experts gathered together. What fairy programming competition is this?

When it comes to Google i/o, this is how ByteDance is applied to flutter
~69 other ways to use icon fonts
TCP的三次握手和四次挥手
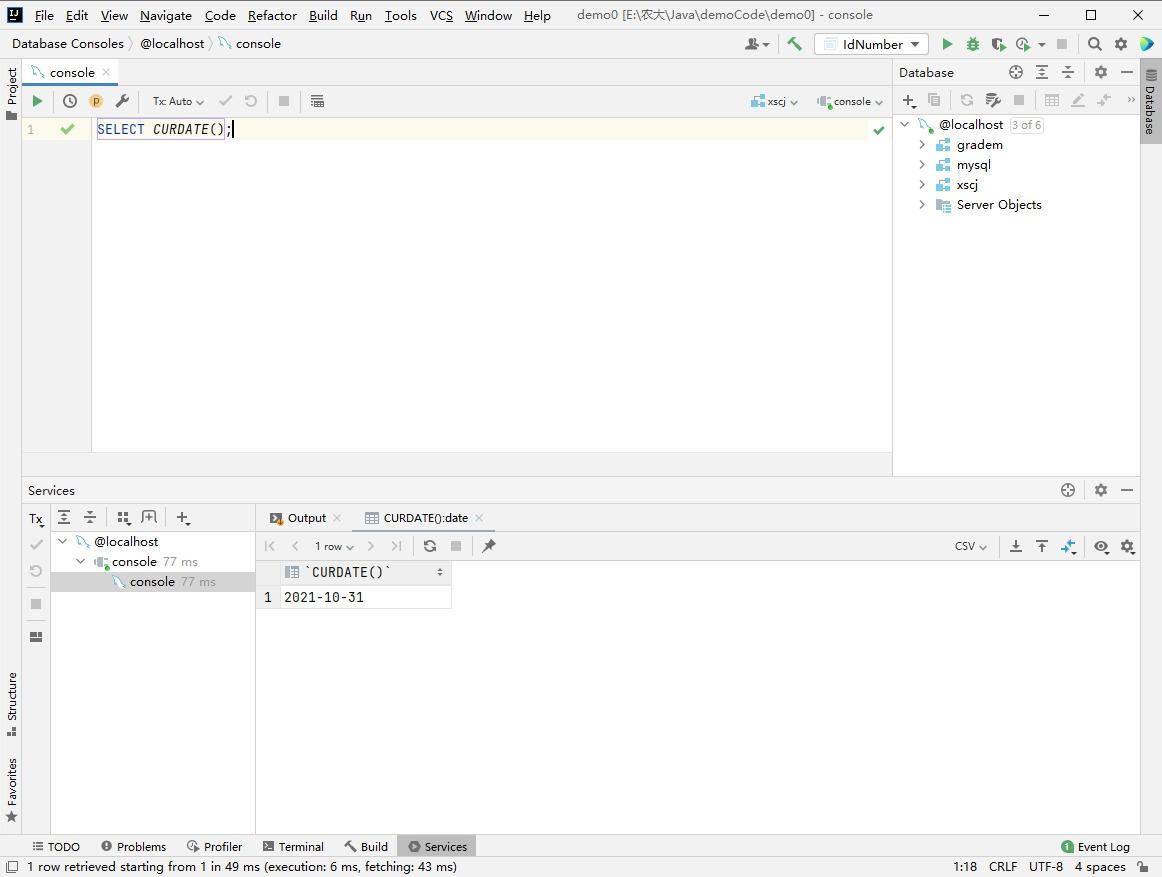
MySQL日期函数
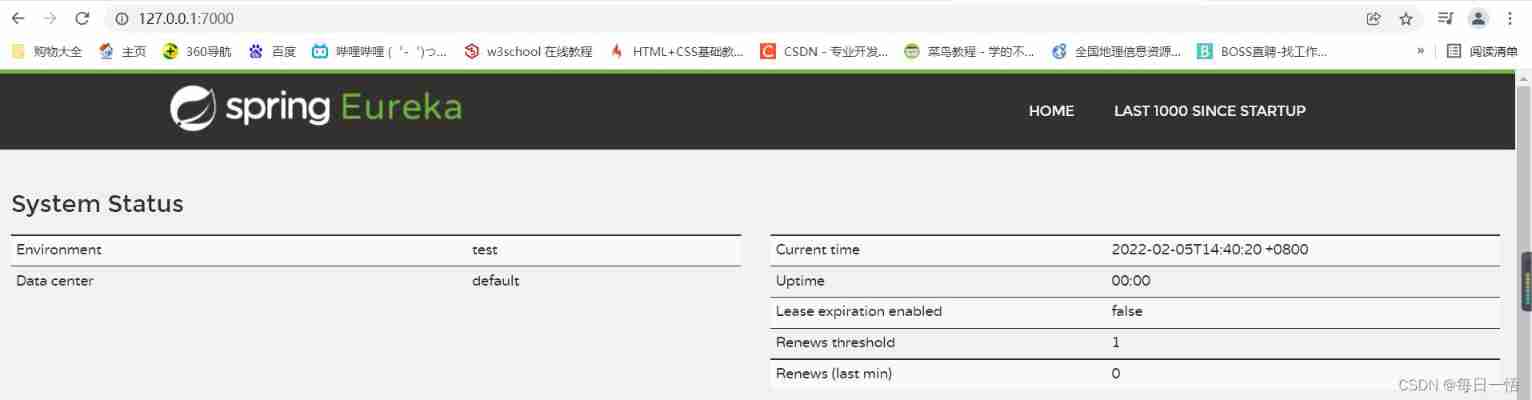
Eureka single machine construction
~81 long table

Many papers on ByteDance have been selected into CVPR 2021, and the selected dry goods are here
随机推荐
字节跳动技术新人培训全记录:校招萌新成长指南
「博士毕业一年,我拿下 ACL Best Paper」
Saw local status change event StatusChangeEvent [timestamp=1644048792587, current=DOWN, previous=UP]
QT system learning series: 1.2 style sheet sub control lookup
LeetCode 1551. Minimum operand to make all elements in the array equal
Codeforces Round #771 (Div. 2)
100张图训练1小时,照片风格随意变,文末有Demo试玩|SIGGRAPH 2021
Cmake error: could not create named generator visual studio 16 2019 solution
字节跳动海外技术团队再夺冠:高清视频编码已获17项第一
The QT program compiled on CentOS lacks a MySQL driven solution
Ruoyi-Cloud 踩坑的BUG
Fdog series (III): use Tencent cloud SMS interface to send SMS, write database, deploy to server, web finale.
Shell_ 02_ Text three swordsman
Shell_ 03_ environment variable
Shell_ 01_ data processing
服务器端渲染(SSR)和客户端渲染(CSR)的区别
"One year after graduation, I won ACL best paper"
~81 long table
Shell_ 00_ First meeting shell
7-6 sum of combinatorial numbers