当前位置:网站首页>Many papers on ByteDance have been selected into CVPR 2021, and the selected dry goods are here
Many papers on ByteDance have been selected into CVPR 2021, and the selected dry goods are here
2022-07-06 16:55:00 【ByteDance Technology】
CVPR 2021, The curtain has just come to an end recently .
As one of the three top academic conferences in the field of computer vision ,CVPR It attracts major universities every year 、 Papers submitted by scientific research institutions and technology companies , Many important achievements of computer vision technology are in CVPR Publish from the top .
today , Selected for you 14 A technical team was selected for this year CVPR The paper of , It includes 2 piece Oral( Oral speeches and papers ), Share the core breakthrough , Learn the most advanced research in the field of computer vision .
besides , In this session CVPR All aspects of the competition , Byte beat technology team won 4 Champion of a competition .
Next , Let's read it together paper La .
HR-NAS: Use lightweight Transformer Efficient search of high resolution neural architecture
HR-NAS: Searching Efficient High-Resolution Neural Architectures with Lightweight Transformers
This paper is composed of two parts 、 The project was completed in cooperation with the College of artificial intelligence, Renmin University of China , It's this CVPR Of Oral One of the papers .
In this paper, we propose a new method for classification 、 Division 、 A unified approach to various visual perception tasks including detection supernet And the model structure search and compression method on top of it , A unified framework is proposed to solve the requirements of different visual perception tasks for different results .
The author of the paper has updated NAS Search space and search strategy , Designed lightweight Transformer, Its computational complexity can change dynamically with different objective functions and computational budgets . In order to maintain a high-resolution representation of the learning network ,HR-NAS Convolutional coding using multi branch architecture to provide multiple feature resolutions . The author also proposes a more effective search strategy to train HR-NAS To effectively explore the search space , Find the best architecture for specific tasks and computing resources .

Thesis link :
https://openaccess.thecvf.com/content/CVPR2021/papers/Ding_HR-NAS_Searching_Efficient_High-Resolution_Neural_Architectures_With_Lightweight_Transformers_CVPR_2021_paper.pdf
Code link :
https://github.com/dingmyu/HR-NAS
Intensive contrast learning for self supervised visual pre training
Dense Contrastive Learning for Self-Supervised Visual Pre-Training
This paper consists of byte beating and the University of Adelaide 、 Tongji University cooperated to complete , It's this CVPR A piece of Oral The paper .
This research can be achieved without expensive intensive manual labeling , Can achieve excellent pre training performance on downstream intensive prediction tasks .
The new approach proposed by the research team DenseCL(Dense Contrastive Learning) By considering the correspondence between local features , Pixels directly between the two views of the input image ( Or area ) Optimize pairwise contrast on features ( Dissimilarity ) Loss to achieve intensive self supervised learning .
The existing self-monitoring framework takes different data from the same image as a pair of positive samples , The data enhancement of the remaining image is used as its negative sample , Construct positive and negative sample pairs to realize global comparative learning , This often ignores the connection and difference of local features .
The method proposed in this study is based on this , Take the two most similar pixels in the same image ( Area ) Characteristics as a pair of positive samples , And all the remaining pixels ( Area ) Feature is used as its negative sample to realize intensive comparative learning . The global pooling layer in the existing self supervised learning framework is removed , The global mapping layer is replaced by dense mapping layer . In the choice of matching strategy , The researchers compared the effects of maximum similarity matching and random similarity matching on the final accuracy . And benchmark methods MoCo-v2 comparison ,DenseCL The introduction of negligible computational overhead ( Only less than 1%), But in moving downstream intensive tasks ( Such as target detection 、 Semantic segmentation ) when , It shows excellent performance .
The performance gain of this method when migrating to downstream intensive tasks :

Thesis link :
https://arxiv.org/abs/2011.09157
Code link :
https://github.com/WXinlong/DenseCL
Progressive temporal feature alignment network for video restoration
Progressive Temporal Feature Alignment Network for Video Inpainting
This paper was completed in cooperation with the University of California, Davis .
The author proposes a new video completion algorithm , It combines the previous optical flow based and 3D Convolution neural network method , A feature alignment method is proposed 3D Convolution method , be known as 「 Progressive time feature alignment network 」, Use optical flow to gradually enrich the features of the current frame from the features of adjacent frames , This method corrects the spatial dislocation in the phase of time feature propagation , Greatly improve the accuracy and visual effect of generated video .
at present , This new approach is DAVIS and FVI The two data sets have achieved the best results in academia .
This technology can be applied to video editing class App in , When the user is in the video P When you drop some parts , Can automatically generate better completion effect .


Thesis link :
https://arxiv.org/abs/2104.03507
Code link :
https://github.com/MaureenZOU/TSAM
Characters to cover up : Character occlusion perception and restoration
Human De-occlusion: Invisible Perception and Recovery for Humans
This paper is completed by the cooperation with school of electronic information and communication, Huazhong University of science and technology .
Aiming at the problem that the person part in the image is blocked by other objects , The author proposes a two-stage framework to estimate the invisible part of the portrait , And restore the contents .
The first is the mask completion stage , With the help of an example segmentation model , The author designs a stacked network structure , To perfect the whole mask ; After that, the content is restored in the mask , A new analytic directed attention model is used , To distinguish different parts of the body , Add more information .
This technology can be applied in the process of character image editing , Realize the replacement of portrait group photo sequence 、 Repair and other functions .

Besides , In the task of covering the characters , The author contributed Amodal Human perception (AHP) Data sets , The dataset labels the scene of each picture , And there are plenty of characters . The method proposed in this paper is also in AHP The best results in the current academic circles have been obtained on the data set .
Thesis link :
https://arxiv.org/abs/2103.11597
Data sets :
https://sydney0zq.github.io/ahp/
First locate... Then split : A high performance benchmark method for referential image segmentation
Locate then Segment: A Strong Pipeline for Referring Image Segmentation
This paper is completed by the cooperation between the Institute of automation of Chinese Academy of Sciences and the Institute of automation of Chinese Academy of Sciences .
Referential object segmentation (Referring Image Segmentation), Target objects in the scene are located and segmented by natural language , For example, language instruction 「 Cut out the man in the white shirt 」, The system will complete this task automatically .
This study adopts the scheme of location first and then segmentation (LTS,Locate then Segment), The referential image segmentation task is decomposed into two subsequence tasks :
Positioning module : Position prediction of the referred object , The object that the language refers to can be obtained explicitly through location modeling ;
Segmentation module : Generation of object segmentation results , The subsequent segmentation network can get the accurate contour according to the visual environment information .

The positioning module aims to find the visual area referred by language expression . Firstly, convolution kernel is generated based on language description , Then, the multi-modal features extracted by the convolution check are filtered to obtain the position information , The response score of the region of the referred object should be higher than that of the irrelevant visual region , This is also a rough segmentation result .
In order to get fine segmentation results , The segmentation module stitches the original multi-modal features and location priors , Then a segmentation network is used to refine the coarse segmentation results , Its main structure is ASPP, Capture information around objects on multiple scales by using multiple sampling rates . In order to get more accurate segmentation results , In this paper, we use deconvolution to upsampling the feature graph .
The method proposed in this study has the best performance than the previous method CGAN Higher performance , Especially in RefCOCO + and RefCOCOg It can improve about 3%IoU.
Thesis link :
https://arxiv.org/abs/2103.16284
Multi scale automatic data enhancement method for target detection
Scale-aware Automatic Augmentation for Object Detection
This paper is written in collaboration with the Chinese University of Hong Kong .
This paper proposes an automatic method for target change detection , The research team designed a new search space and an estimation index in the search process (Pareto Scale Balance).
This new method only costs 8 block GPUs,2.5 It can be done in a few days , Search efficiency is relatively improved 40 times . The data enhancement strategy obtained from the search can improve the performance of all kinds of detectors and different data sets , And beyond the traditional method .
Besides , There is a certain rule in the search strategy , These rules may provide some help for artificial data enhancement design in the future .

Thesis link :
https://arxiv.org/abs/2103.17220
Code link :
https://github.com/Jia-Research-Lab/SA-AutoAug
Plug and play , More efficient : A method of motion recognition based on hybrid attention mechanism ACTION modular
ACTION-Net: Multipath Excitation for Action Recognition
This paper is written in collaboration with Trinity University Dublin .
This study focuses on 3D Convolution of the depth of neural network to complete the task of video action recognition , It mainly focuses on sequential action recognition, such as human-computer interaction and VR/AR Gesture recognition in .
Compared with traditional motion recognition, such as Kinetics( Pay attention to video classification ), There are two main differences in such application scenarios :
1. It is generally deployed on edge devices, such as mobile phones ,VR/AR On the device . Therefore, there are certain requirements for model calculation and reasoning speed ;
2. This kind of action ("Rotate fists counterclockwise" vs "Rotate fists clockwise") And traditional action recognition ("Walking" vs "Running") It has a strong timing compared with . For the above two points , We are based on 2D CNN( Light ) A hybrid attention mechanism is proposed ACTION modular ( For temporal action modeling ).
The main contribution is :
1. For sequential action recognition ( Like gestures ) A hybrid attention mechanism is proposed ACTION modular , The module takes into account three important information in the sequential action : (a) Spatiotemporal information is the relationship between action in time and space ; (b) A weight of the timing information of an action between different channels ;(c) The trajectory of motion between every two adjacent frames .
2. The module is similar to the classic TSM The modules are the same , Plug and play . be based on 2D CNN, Very light . We show in the article ACTION The modules are in three different stages backbone: ResNet-50,MobileNet V2 and BNInception Compared with TSM The result is improved and the amount of calculation is increased . In three sequential action data sets, namely Something-to-Something V2,Jester and EgoGesture It's been tested on the Internet ACTION The practicality of the module .

Thesis link :
https://arxiv.org/pdf/2103.07372.pdf
Code link :
https://github.com/V-Sense/ACTION-Net
Non iterative and incremental learning method is used for super pixel segmentation
Learning the Superpixel in a Non-iterative and Lifelong Manner
This paper consists of two parts 、 Beijing University of Posts and Telecommunications cooperated to complete .
The purpose of super-pixel segmentation is to efficiently segment the image into super-pixel blocks far exceeding the number of targets , To achieve the purpose of preserving the edge information of all objects in the image as much as possible . However , Currently based on CNN Super pixel segmentation method of , In the training process, it depends on semantic segmentation and annotation , As a result, the generated super pixels usually contain a lot of redundant high-level semantic information , Therefore, it not only limits the generalization of super-pixel segmentation methods 、 flexibility 、 It also restricts its application prospect in the visual task of lacking segmentation and annotation , Such as target tracking 、 Weakly supervised image segmentation, etc .
To solve this problem , This paper looks at the problem of super-pixel segmentation from the perspective of continuous learning , And a new super pixel segmentation model is proposed, which can better support the unsupervised online training mode .
Considering that super-pixel segmentation as a generalized segmentation problem needs to pay more attention to the details of the image , This model abandons the deep and complex convolutional neural network structure used in other super-pixel segmentation networks , The feature extraction module is light weight (FEM), A non iterative clustering module is proposed (NCM) By automatically selecting seed nodes , It avoids the iterative update of clustering center in the super-pixel segmentation method , It greatly reduces the space complexity and time complexity of super pixel segmentation .
Last , To solve the catastrophic forgetting problem brought by online learning , This model uses gradient adjustment module (GRM), By training the effect of the weight in the feature reconstruction and the prior of the spatial position of the pixel , Adjust the gradient of each weight in back propagation , To enhance the memory and generalization of the model .

Thesis link :
https://arxiv.org/abs/2103.10681
Code link :
https://github.com/zh460045050/LNSNet
Involution: Reverse the inherent properties of convolution for visual recognition
Involution: Inverting the Inherence of Convolution for Visual Recognition
This paper is written by the author and the Hong Kong University of science and technology 、 Peking University cooperated to complete .
This paper rethinks the inherent characteristics of convolution kernel in space and channel dimensions , That is, spatial invariance and channel specificity .
By reversing the above two design criteria , A novel neural network operator is proposed , be called Involution, The recently widely used self attention operation is classified as a complex special case involution The category of .Involution Operator can replace ordinary convolution to build a new generation of visual neural network , Support a variety of deep learning models in different visual tasks , Include ImageNet Image classification ,COCO Object detection and instance segmentation ,Cityscapes Semantic segmentation .
be based on Involution Compared with convolution neural network model , In the above tasks, the computational cost can be significantly reduced and the recognition performance can be improved .

Thesis link :
https://arxiv.org/abs/2103.06255
Code link :
https://github.com/d-li14/involution
One for vision - The best pooling strategy for automatic learning of semantic embedding
Learning the Best Pooling Strategy for Visual Semantic Embedding
This paper is jointly completed by the University of California and the University of Southern California .


This paper focuses on vision - Semantic cross modal matching problem , A general pooling strategy is proposed .
Vision - Semantic embedding (Visual Semantic Embedding) Learning is vision - A common method of text retrieval , By mapping the embedding corresponding to visual and text modes to the same space , So that the matching vision is similar to the text embedding .
The author found that the set embedding of a single mode ( As shown in the picture grid-level features 、 Textual token-level features 、 The video frame-level features ) The pooling method of aggregation into global embedding has a great influence on the effect of the model , A simple and universal pooling module is proposed Generalized Pooling Operator(GPO), It is used to embed and aggregate the set of arbitrary modes into a global embedding .GPO The module can adaptively learn the optimal pooling strategy for each mode , So as to avoid complex combination attempts .
Thesis link :
https://arxiv.org/abs/2011.04305
Code link :
https://vse-infty.github.io
DeepI2P: Point cloud based on deep learning - Image registration
DeepI2P: Image-to-Point cloud registration via deep classification
This paper is written in collaboration with the National University of Singapore .
This paper presents a new method to realize cross modal point cloud - Image registration . Given a shot taken near the same location RGB picture , And 3D point clouds scanned by lidar , Can pass DeepI2P Estimate the relative position of the camera and lidar , Rotation matrix and translation vector .
In the past, the common method of cross modal matching is learning point cloud 、 The descriptor of the image . But learning and matching these two modal descriptors is very difficult , Because of the point cloud 、 The geometry of the image 、 Texture features are very different .
DeepI2P Skillfully bypasses the difficult cross modal descriptor learning , The cross modal registration problem is transformed into a classification problem plus a “ Inverse Projection ” problem . Through a classification network , Each point in the 3D point cloud can be classified as falling in or out of the camera plane . These marked points can be identified by “ Inverse Projection ” The optimizer works out the relative position of the camera and the lidar .
DeepI2P The algorithm is already in KITTI and Oxford RobotCar The validity is verified on the data set .

Thesis link :
https://arxiv.org/abs/2104.03501
Code link :
https://github.com/lijx10/DeepI2P
Sparse R-CNN: End to end sparse target detector based on learnable candidate frame
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
This paper is composed of two parts 、 Tongji University 、 University of California, Berkeley .
Traditional target detectors can be divided into two categories :
The first category is the dense detector which has been widely used since the era of non deep learning (dense detector), for example DPM,YOLO,RetinaNet. On a dense detector , A large number of candidate objects such as anchor frame and reference point are preset on the image grid or feature map grid in advance , Then, we can directly predict the deviation of these candidate boxes from the real value and the object category .
The second category is dense to sparse detectors (dense-to-sparse detector), for example ,Faster R-CNN series . The characteristic of this kind of method is to predict, regress and classify a group of sparse candidate boxes , This sparse set of candidate boxes comes from dense detectors .
Along the field of target detection Dense and Dense-to-Sparse Framework ,Sparse R-CNN A thorough sparse target detection framework is established , Out of the anchor box 、 Concepts such as reference points , No non maximum suppression is required (NMS) post-processing , In standard COCO benchmark It's the best performance at present .

Thesis link :
https://arxiv.org/pdf/2011.12450.pdf
Code link :
https://github.com/PeizeSun/SparseR-CNN
One stage human body grid estimation model
Body Meshes as Points
This paper is written in collaboration with the National University of Singapore .
Most of the existing human body mesh estimation algorithms are based on two stages , The first stage is used for character positioning , The second stage is used for body mesh estimation , This redundant computing framework leads to high computing cost and poor performance in complex scenarios .
In this work , The research team proposed a single-stage human mesh estimation model for the first time (BMP), To simplify the computing framework and improve efficiency and performance . To be specific , In this paper, several examples of characters are represented as 2D Flat and 1D Points in depth space , Each of these points is associated with a body mesh .BMP We can locate the instance points and estimate the corresponding body grid at the same time , So as to directly predict the body grid of multiple characters in a single stage . In order to better infer the depth ranking of all characters in the same scene ,BMP A simple and effective ordinal depth loss between instances is designed to obtain depth coherent mesh estimation of multi person body .BMP A novel data enhancement technique based on key points is introduced to enhance the robustness of the model to occluded and partially visible human instances .
This achievement is in Panoptic、MuPoTS-3D and 3DPW And other data sets have achieved the most advanced performance .

Thesis link :
https://arxiv.org/pdf/2105.02467.pdf
Code link :
https://github.com/jfzhang95/BMP
Learn how to remove fog in this video : A real world dataset and a new approach
Learning to Restore Hazy Video: A New Real-World Dataset and A New Method
This paper consists of byte beat and Tencent Youtu laboratory 、 Xi'an Jiaotong University 、 Nanjing University of science and technology cooperated to complete .
This paper designs a new video data collection system based on the repeatable positioning manipulator , Take pictures of the same scene with and without fog , To get a completely real data set (REal-world VIdeoDEhazing, REVIDE), It can be used to train the defogging model using supervised learning method .


This dataset is more realistic than synthetic data , It can train better defogging algorithm .
Thesis link :
https://openaccess.thecvf.com/content/CVPR2021/papers/Zhang_Learning_To_Restore_Hazy_Video_A_New_Real-World_Dataset_and_CVPR_2021_paper.pdf
Data sets :
http://xinyizhang.tech/revide/

4 term CVPR The champion of the competition
In addition to publishing papers , In this session CVPR All aspects of the competition , Our technical team also achieved excellent results .
stay CVPR Mobile AI Workshop Real time mobile terminal detection scene competition , Bytes to beat ByteScene The team with 163.08 Won the championship with an absolute advantage of points .

The competition requires real-time judgment of the camera input image on the mobile hardware , Predict that the current scene contains portraits 、 The beach 、 sky 、 cat 、 Dogs, etc 30 Which of the three categories , This kind of algorithm can help video creators edit more conveniently , More intelligent help creators match template materials .
CVPR Fine grained visual classification challenge , The two teams won the first and second place .

The competition requires identification up to 10000 There are different kinds of animals and plants , The difference between similar species is very small , And can not be disturbed by the background pattern . This kind of algorithm can be used in various object recognition scenarios .
In the semi supervised fine-grained visual classification challenge , The team also won the first place .

Different from the above game , The competition focuses on semi supervised learning , That is, there is no need to label the training set in advance , The training of visual classification model can be realized .
Kinetics-700 Video classification competition supervision learning track , Byte runout and CMU( Carnegie Mellon university ) The cooperative team won the first place .

Kinetics-700 It's a video data set , Contains about 65 Ten thousand video clips , It shows 700 It's a different human movement , Contestants need training models to classify different videos .
Where does the thesis come from ? Business starts & Forward looking judgment
See so many results , So in real business , How did these achievements land ? Byte beating researchers , How to meet the real business needs , Who created these leading achievements ?
A researcher Leader Introduce , In the company , R & D students have enough freedom to make decisions , Be able to promote the research of technologies of interest from the bottom up , While supporting the business, you can refine your own innovative ideas , Self driving drives research , Become an academic achievement . in addition , The company provides rich training resources to , Not only to support the business , It also supports scientific research .
The results of these academic studies , It is also used in real business .
for instance , Computer vision technology is widely used in content security 、 Video understanding 、 Video copyright and other issues .“ And the data distribution on the actual business line is constantly changing , We need to make sure that the machine learning model changes with the data distribution on the adapter line , We can also make full use of the vast amount of knowledge we have learned , It's a continuous learning in academia (continual learning) The problem of , It's both a business issue , It is also an important topic in academic circles . We will explore these issues in depth , It can not only solve academic and business problems , We should also consider how to save computing resources in specific business implementation 、 Reduce model operation and maintenance costs .”
“ Another example , In robot visual perception , Robot object detection is a very important content , How to improve accuracy 、 How to improve the calculation efficiency while ensuring the accuracy , Both are important goals , It's going to force us to try and explore a lot .”
Besides , Relevant research results of computer vision have also been used in image cutting 、 Watermelon video and other products , Help creators create and edit videos more easily .
In the process of solving these business problems , When the R & D team will make new breakthroughs , Further study of , It will even be the world's leading level , It can be used as scientific research achievements to share with the academic community .
In addition to business driven R & D projects , Our R & D team will also make forward-looking judgment on Technology , At a time when the business has not yet developed to meet the needs of relevant technologies , Do enough technology research and development and reserve , In response to future technology needs and challenges .
边栏推荐
- Simple records of business system migration from Oracle to opengauss database
- Chapter 5 namenode and secondarynamenode
- 字节跳动多篇论文入选 CVPR 2021,精选干货都在这里了
- Jedis
- LeetCode 1584. Minimum cost of connecting all points
- Use JQ to realize the reverse selection of all and no selection at all - Feng Hao's blog
- 面试集锦库
- Which is more important for programming, practice or theory [there are some things recently, I don't have time to write an article, so I'll post an article on hydrology, and I'll fill in later]
- string. How to choose h and string and CString
- Fdog series (III): use Tencent cloud SMS interface to send SMS, write database, deploy to server, web finale.
猜你喜欢
~74 JD top navigation bar exercise

这群程序员中的「广告狂人」,把抖音广告做成了AR游戏

图像处理一百题(1-10)

谢邀,人在工区,刚交代码,在下字节跳动实习生
One hundred questions of image processing (1-10)

图像处理一百题(11-20)

was unable to send heartbeat
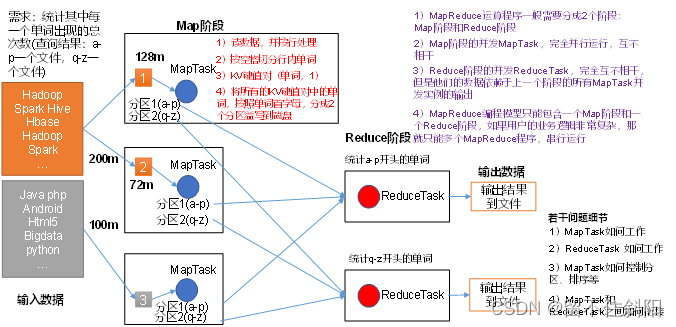
Chapter 1 overview of MapReduce
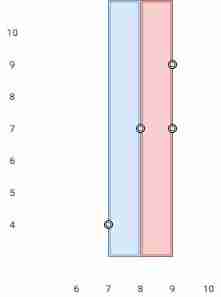
LeetCode 1637. The widest vertical area between two points without any point
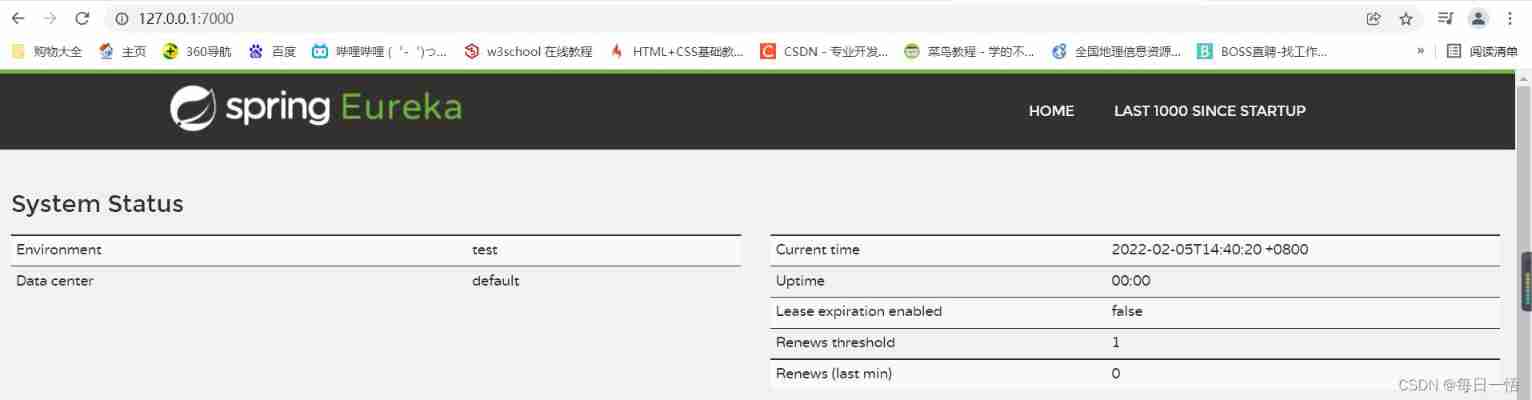
Eureka single machine construction
随机推荐
The most lost road I have ever walked through is the brain circuit of ByteDance programmers
~70 row high
~81 long table
Which is more important for programming, practice or theory [there are some things recently, I don't have time to write an article, so I'll post an article on hydrology, and I'll fill in later]
Saw local status change event StatusChangeEvent [timestamp=1644048792587, current=DOWN, previous=UP]
亮相Google I/O,字节跳动是这样应用Flutter的
CMake Error: Could not create named generator Visual Studio 16 2019解决方法
字节跳动技术新人培训全记录:校招萌新成长指南
LeetCode1556. Thousand separated number
Business system compatible database oracle/postgresql (opengauss) /mysql Trivia
LeetCode 1545. Find the k-th bit in the nth binary string
Shell_ 03_ environment variable
~Introduction to form 80
SQL快速入门
字节跳动海外技术团队再夺冠:高清视频编码已获17项第一
Detailed explanation of FLV format
~87 animation
Solr standalone installation
LeetCode 1566. Repeat the pattern with length m at least k times
TypeScript基本操作