当前位置:网站首页>Chapter 6 datanode
Chapter 6 datanode
2022-07-06 16:35:00 【Can't keep the setting sun】
6.1.DataNode Working mechanism
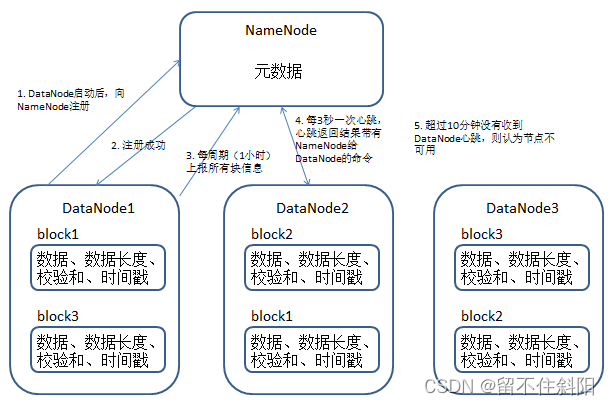
- A data block in DataNode Is stored as a file on disk , There are two files , One is the data itself , One is that the metadata includes the length of the data block , Checksums of data blocks , And time stamps .
- DataNode Starts to NameNode register , After successful registration , Periodically NameNode Report all block information .
- The heartbeat is every 3 Seconds at a time , Heartbeat returns results with NameNode To the DataNode The order of , For example, copy block data to another machine , Or delete a block of data . If exceeded 10 Minutes did not receive a certain DataNode The heart of , The node is considered unavailable .
- You can safely join and exit some machines while the cluster is running .
6.2. Data integrity
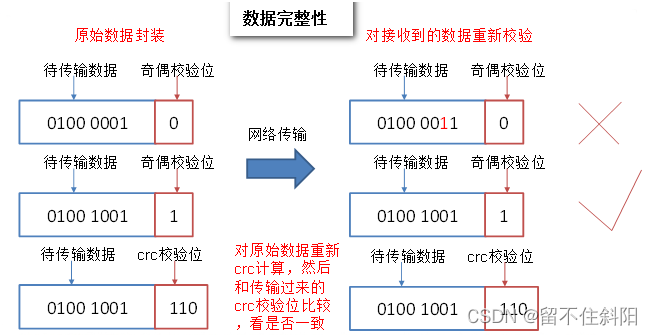
- When DataNode Read block When , It will also have a checksum.
- If you calculate the checksum, And block The values are different when created , explain block Has been damaged .
- client Read other DataNode Upper block.
- DataNode Verify periodically after the file is created checksum.
6.3. Drop time parameter Settings
DataNode Process death or network failure DataNode Can't be with NameNode signal communication ,NameNode The node is not immediately judged dead , It's going to take a while , This period of time is temporarily called overtime .HDFS The default timeout is 10 minute +30 second . If the timeout is defined as timeout, The formula for calculating the overtime is :timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
explain : default dfs.namenode.heartbeat.recheck-interval The size is 5 minute ,dfs.heartbeat.interval The default is 3 second . stay hdfs-site.xml In profile dfs.namenode.heartbeat.recheck-interval In milliseconds ,dfs.heartbeat.interval In seconds .
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
6.4. Add new data nodes
demand : As the company's business grows , More and more data , The capacity of the original data nodes can no longer meet the needs of data storage , You need to dynamically add new data nodes on the basis of the original cluster .
Environmental preparation
- Clone a virtual machine (NameNode)
- modify ip Address and host name
- Add new nodes ssh Password free login configuration
- Delete the new node data and logs Files in directory ( Because cloned NameNode host )
Operation steps
- stay namenode Of /opt/module/hadoop-2.7.2/etc/hadoop Create under directory dfs.hosts file
touch dfs.hosts
vi dfs.hosts
Add the following host name ( all DataNode node , Include new nodes hadoop105)
hadoop102
hadoop103
hadoop104
hadoop105
Be careful : among dfs.hosts Lists the connections NameNode The node of , If it is empty , Then all of them DataNode Can be connected to NameNode. If it's not empty , Then... Exists in the file DataNode Can be connected to .dfs.hosts.exclude List the forbidden connections NameNode The node of . If a node exists at the same time dfs.hosts and dfs.hosts.exclude, It is forbidden to connect to .
- stay namenode Of hdfs-site.xml Added in configuration file dfs.hosts attribute
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
- Refresh namenode
hdfs dfsadmin -refreshNodes
The results are shown below
Refresh nodes successful
- Refresh resourcemanager node
yarn rmadmin -refreshNodes
The results are shown below
INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
- stay NameNode and DataNode Of slaves Add a new host name to the file
hadoop102
hadoop103
hadoop104
hadoop105
- Start the data node and node manager on the new node
sbin/hadoop-daemon.sh start datanode
The results are shown below
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-lubin-datanode-hadoop105.out
sbin/yarn-daemon.sh start nodemanager
The results are shown below
starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-lubin-nodemanager-hadoop105.out
stay web Check the browser for ok
If the data is unbalanced , Cluster rebalancing can be achieved by command ( stay sbin Execute the following command in the directory )
./start-balancer.sh
As shown below
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-lubin-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
6.5. Retire the old data node
(1) stay namenode $HADOOP_HOME/etc/hadoop Create under directory dfs.hosts.exclude file
touch dfs.hosts.exclude
Add the retirement node hostname
hadoop105
(2) stay namenode Of hdfs-site.xml Added in configuration file dfs.hosts.exclude attribute
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
(3) stay namenode Refresh the node namenode、 stay resourcemanager Refresh the node resourcemanager
$ hdfs dfsadmin -refreshNodes
The following message appears , Indicates that the refresh was successful
Refresh nodes successful
$ yarn rmadmin -refreshNodes
The following message appears , Indicates that the refresh was successful
INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
(4) Check web browser , The state of the decommissioned node is decommission in progress( The retired ), Indicates that the data node is copying blocks to other nodes .
(5) Wait for the status of the decommissioned node to be decommissioned( All the blocks have been copied ), Stop the node and the node explorer . Be careful : If the copy number is 3, The nodes in service are less than or equal to 3, You can't retire successfully , You need to modify the number of copies before you can retire .
(6) On the retirement node , Stop the node process
sbin/hadoop-daemon.sh stop datanode
stopping datanode
sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
(7) from namenode Of dfs.hosts Delete retired node from file hadoop105
hadoop102
hadoop103
hadoop104
Refresh namenode, Refresh resourcemanager
$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
$ yarn rmadmin -refreshNodes
INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
(8) from NameNode and DataNode Of slave Delete retired node from file hadoop105
hadoop102
hadoop103
hadoop104
(9) If the data is unbalanced , Cluster rebalancing can be achieved by command
$ sbin/start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-lubin-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
6.6.Datanode Multi-directory configuration
- datanode It can also be configured as multiple directories , Each directory stores different data . namely : Data is not a copy .
- Modify the configuration file
hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///hd2/dfs/data2</value>
</property>
Be careful : The default value is file:///${hadoop.tmp.dir}/dfs/data, If the server has multiple disks, this parameter must be modified ( Pay attention to the access rights of the attached disk );
The disk condition of each server node is different , So after modifying the configuration , No need to distribute ;
6.7. Data equalization
6.7.1.Hadoop Data balance between nodes
(1) Enable data balancing
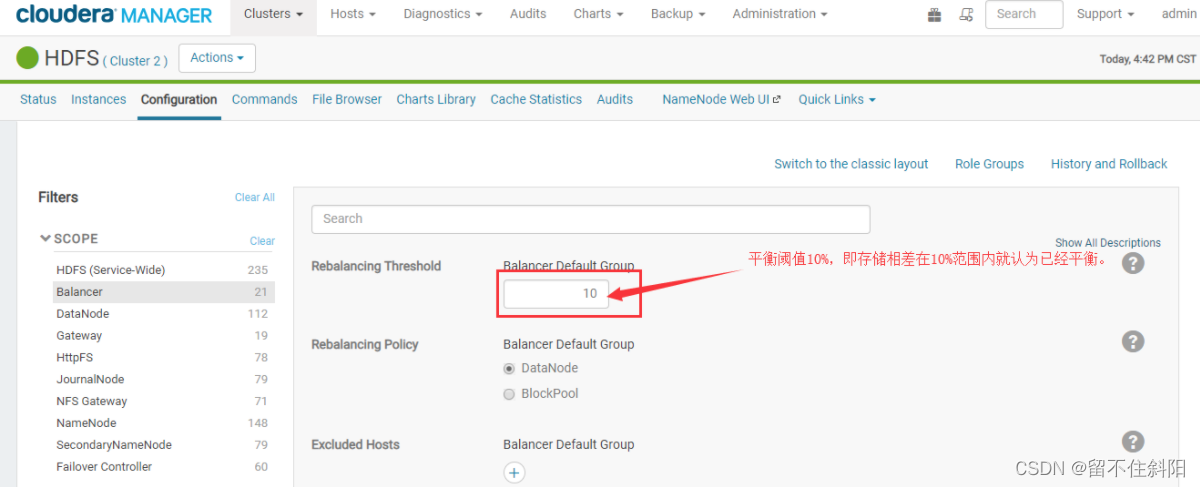
sbin/start-balancer.sh -threshold 10
Parameters :10 Indicates that the difference in disk space utilization of each node in the cluster does not exceed 10%, It can be adjusted according to the actual situation
(2) Stop data balancing
sbin/stop-balancer.sh
Be careful : because HDFS You need to start a separate Rebalance Server To execute Rebalance operation , So try not to be in NameNode On the implementation start-balancer.sh.
(2) Hadoop2.X Support data balance between nodes
hdfs balancer -help
Usage: java Balancer
[-policy <policy>] the balancing policy: datanode or blockpool
[-threshold <threshold>] Percentage of disk capacity
[-exclude [-f <hosts-file> | comma-sperated list of hosts]] Excludes the specified datanodes.
[-include [-f <hosts-file> | comma-sperated list of hosts]] Includes only the specified datanodes.
For more efficient implementation balancer operation , Recommendations are as follows :
-threshold 10 Parameter meaning : The target parameter to determine whether the cluster is balanced , every last datanode The difference between the storage utilization and the total storage utilization of the cluster should be less than this threshold , Theoretically , The smaller the parameter is set , The more balanced the whole cluster is , But in an online environment ,hadoop The cluster is in progress balance when , Also write and delete data concurrently , So it may not reach the set balance parameter value .
-include Parameter meaning : Be balanced datanode list
-exclude Parameter meaning : Don't want to balance datanode list
hdfs dfsadmin -setBalancerBandwidth xxx Parameter meaning : Set up balance The bandwidth that the tool can occupy during operation , Setting too large may cause mapred slow .
CDH Balancer Is very simple to use , Just set the above parameters , Click again Actions→Rebalance A menu item , It will automatically start balancing . If it has been running before , Need to stop first , If you can't get up , need kill fall 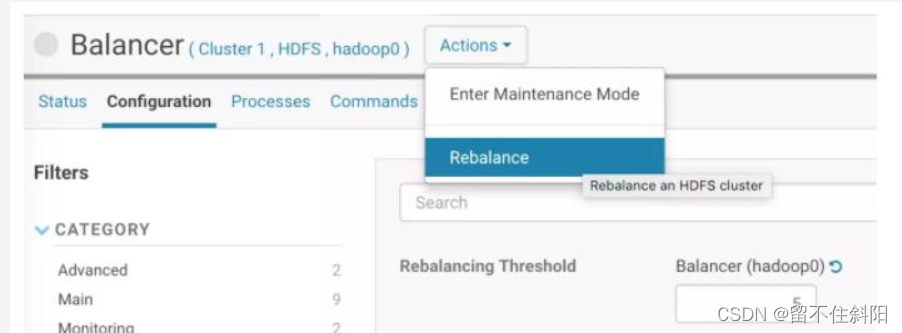
6.7.2. Data balancing between disks
(1) Turn on disk balancer
stay CDH 5.8.2+ In the version , It can be done by CM Middle configuration . If used Hadoop The version is 3.0+(hadoop2.X Data balancing between disks is not supported ), It's right there hdfs-site.xml Add relevant items in . Set up dfs.disk.balancer.enabled by true
(2) Generate a balanced plan
hdfs diskbalancer -plan cdh4
Be careful :cdh4 For hosts that need to be balanced 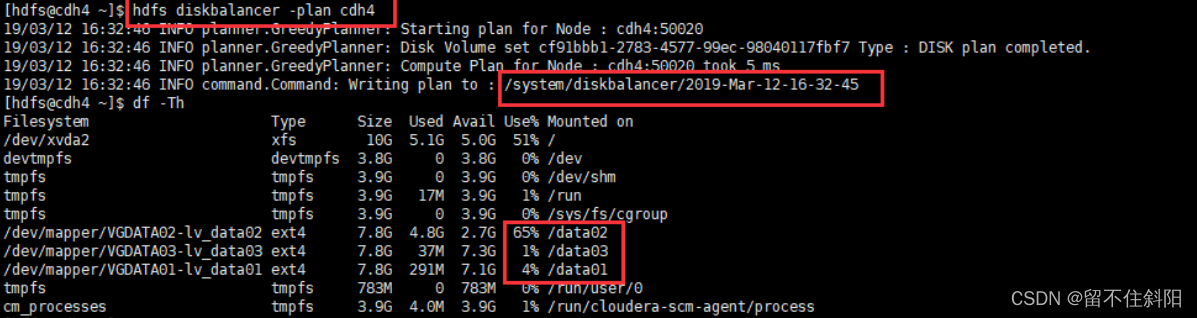
(3) Execute a balanced plan
hdfs diskbalancer -execute {
/system/diskbalancer/XXXXX/{
Host name }.plan.json}

(4) View execution status hdfs diskbalancer -query { Host name }
(5) Completion and inspection 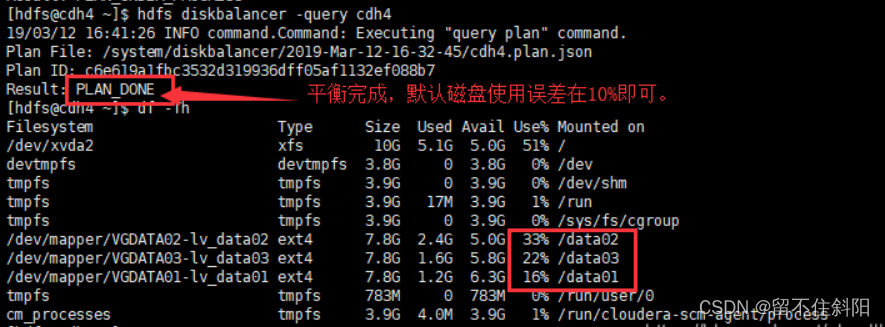
hadoop2.x Cannot automatically balance disks , At the node hdfs-site.xml Several parameters are added to change the data storage strategy to achieve the purpose of balance , Restart this node after adding parameters datanode that will do .
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold</name>
<value>10737418240</value>
</property>
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction</name>
<value>0.85f</value>
</property>
Parameter interpretation dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold The difference between the capacity of the disk with the largest remaining capacity and that of the smallest disk (10G The default value is )
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction If the size of the current copy is greater than lowAvailableVolumes The maximum free space of all disks inside , Then it will be stored in highAvailableVolumes Inside , In addition, the situation will be 85% The probability is stored in highAvailableVolumes,15% The probability is stored in lowAvailableVolumes.
Be careful :
This is invalid for the data that has been stored on the disk , Only valid for subsequent stored data , Use balance to transfer the stored data .
边栏推荐
- 875. Leetcode, a banana lover
- China tetrabutyl urea (TBU) market trend report, technical dynamic innovation and market forecast
- 简单尝试DeepFaceLab(DeepFake)的新AMP模型
- Problem - 1646C. Factorials and Powers of Two - Codeforces
- Codeforces Round #801 (Div. 2)A~C
- (lightoj - 1369) answering queries (thinking)
- 原生js实现全选和反选的功能 --冯浩的博客
- Installation and use of VMware Tools and open VM tools: solve the problems of incomplete screen and unable to transfer files of virtual machines
- 读取和保存zarr文件
- AcWing:第58场周赛
猜你喜欢

Pytorch extract skeleton (differentiable)
第五章 Yarn资源调度器
软通乐学-js求字符串中字符串当中那个字符出现的次数多 -冯浩的博客
第7章 __consumer_offsets topic
Raspberry pie 4b64 bit system installation miniconda (it took a few days to finally solve it)

< li> dot style list style type
Discussion on QWidget code setting style sheet
提交Spark应用的若干问题记录(sparklauncher with cluster deploy mode)
QT implementation fillet window
Chapter 2 shell operation of hfds
随机推荐
新手必会的静态站点生成器——Gridsome
解决Intel12代酷睿CPU单线程调度问题(二)
Codeforces Round #802(Div. 2)A~D
How to insert mathematical formulas in CSDN blog
Summary of FTP function implemented by qnetworkaccessmanager
Summary of game theory
MariaDB的安装与配置
(lightoj - 1323) billiard balls (thinking)
QT implementation fillet window
(lightoj - 1236) pairs forming LCM (prime unique decomposition theorem)
树莓派4B64位系统安装miniconda(折腾了几天终于解决)
读取和保存zarr文件
QT实现窗口置顶、置顶状态切换、多窗口置顶优先关系
Problem - 1646C. Factorials and Powers of Two - Codeforces
Codeforces Round #798 (Div. 2)A~D
生成随机密码/验证码
解决Intel12代酷睿CPU【小核载满,大核围观】的问题(WIN11)
Install Jupiter notebook under Anaconda
Tree of life (tree DP)
The "sneaky" new asteroid will pass the earth safely this week: how to watch it