当前位置:网站首页>第5章 NameNode和SecondaryNameNode
第5章 NameNode和SecondaryNameNode
2022-07-06 09:29:00 【留不住斜阳】
5.1.NameNode
NameNode 负责管理文件系统的命名空间以及客户端对文件的访问。当客户端请求数据时,从 NameNode 获取文件的元数据信息,具体的数据传输不经过 NameNode,而是直接与具体的 DataNode 进行交互。
文件的元数据信息记录了文件系统中的文件名和目录名,以及它们之间的层级关系,同时也记录了每个文件所属目录、所有者及其权限,甚至还记录每个文件由哪些块组成,这些元数据信息记录在 fsimage 中,当系统初次启动时,NameNode 将读取 fsimage 中的信息并保存到内存中。
文件块的位置信息是由 NameNode 启动后从每个 DataNode 获取并保存在内存当中的,这样既减少了 NameNode 的启动时间,又减少了读取数据的查询时间,提高了整个系统的效率。
内存中的元数据发生更新,磁盘中的fsimage也需要同时更新,才能保证数据的一致性。但是,如果内存中的元数据每更新一次,就同步到磁盘,效率会非常低下。
5.2.SecondaryNameNode
SecondaryNameNode 不是 NameNode 的备份
SecondaryNameNode 会定时定量的把集群中的 Edits 文件转化为 Fsimage 文件,来保证 NameNode 中数据的可靠性
5.3.NN和SNN工作机制
NameNode存储文件系统目录树的信息,而目录树的信息则存放在fsimage文件中,当NameNode启动的时候首先读取整个fsimage文件,将信息装载到内存
edits文件存储日志信息,在HDFS上所有更新操作,包括增加,删除,修改等都会保存到edits文件中,并不会同步到fsimage中,当NameNode关闭的时候,也不会将fsimage和edits进行合并。
注意:客户端的操作首先写入到edits文件中,然后操作内存中的数据所以当NameNode启动的时候,首先装载fsimage文件到内存中,然后按照edits中的记录执行一遍所有记录的操作,最后将内存中最新的fsimage保存到磁盘上,之后重新启用新的edits文件记录后续更新操作。
如果该合并过程只由NameNode去做,那么就会增加NameNode的压力,因为不仅需要处理合并还要处理客户端的请求
基于上述NameNode中fsimage和edits合并只在NameNode启动的时候才会进行,但是生产环境下,重启NameNode的时候edits往往非常大,而edits中保存的是操作,往往也存在许多重复性操作,意味着做无用功且损耗效率
Secondary NameNode的职责分担NameNode的压力,按一定规则合并NameNode的edits到fsimage文件中。并且合并过程不影响NameNode的操作
合并规则
- 定时时间到了,请求获取相关文件,然后进行合并
- edits文件的"数据满了",例如,达到一定的操作次数
问题一:启动读取edits文件的过程
当NameNode启动的时候,edits_inprogress文件会将文件中的信息刷到一个edits文件中(文件结尾为事务开始id-事务结束id,表示刷进去的事务操作范围),并生成一个最新的edits_inprogress开头的文件,文件结尾为最新的事务id。NameNode拿到这个edits文件以后,与最新的fsimage镜像文件进行合并,生成新的fsimage并存储到磁盘上。
问题二:启动时读取edits+fsimage文件,而不是只读取fsimage
磁盘中的fsimage是由secondary namenode定期合并生成的最新的镜像文件,但是secondary namenode将操作日志合并到fsimage中是有周期性,在周期内,如果集群停掉,最新的日志文件就没有合并到fsimage中。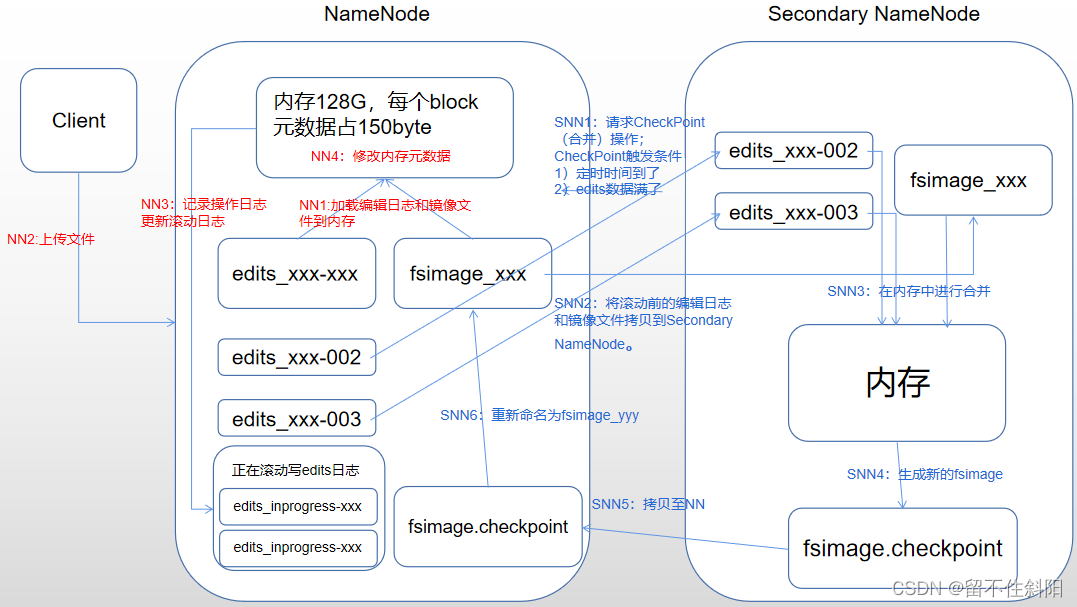
第一阶段:NameNode启动
① 在NameNode上通过bin/hdfs namenode -format命令格式化后,会在NameNode节点创建fsimage文件。通过sbin/start-dfs.sh第一次启动文件系统的时候,系统会把fsimage读取到内存中,而DataNode节点数据的相关变动,则保留在一系列的edits文件中,在下次(非第一次)文件系统重新启动的时候,先刷新edits_inprogress文件内容到edits文件,开启一个新的edits_inprogress文件记录后续操作,把目前的fsimage和所有的edits进行合并重新生成一个新的fsimage。
② 客户端发出对数据增删改的请求。
③ NameNode记录操作日志,更新滚动日志。
④ NameNode修改内存元数据。
注意:客户端的操作首先是写入到edits文件中,然后再操作内存中的数据
Namenode启动成功后,启动datanode
(1) datanode向namenode注册;
(2) datanode向namenode发送blockreport。
(3) datanode启动成功后,client可以对HDFS进行目录创建、文件上传、下载、查看、重命名等操作,更改namespace的操作将被记录在edit log文件中。
第二阶段:Secondary NameNode工作
① Secondary NameNode请求执行CheckPoint操作。
② Secondary NameNode通知NameNode准备提交edits文件,假设此时的编辑日志文件是edits_inprogress_001,所有的客户端的操作首先追加到该日志中,当NameNode提交edits日志文件的时候该日志名称为edits_001-005,并将它提交给Secondary NameNode,滚动产生edits_inprogress_006,新的操作信息存到新的日志文件中。
③ SecondaryNameNode通过http get方式获取NameNode的fsimage与edits文件
④ 在SNN内存中对编辑日志和镜像文件进行合并。
⑤ 生成新的镜像文件fsimage.chkpoint
⑥ 拷贝fsimage.chkpoint到NameNode。
⑦ NameNode将fsimage.chkpoint重新命名成 fsimage_txid 的形式,后面txid表示此fsimage文件记录的已合并的最新操作的txid。
磁盘上的元数据文件
记录在edit Log文件中的每个操作都是一个独立的事务,每个事务有相应的操作码,唯一的事务ID以及操作对应的数据信息等。事务ID是由NameNode统一管理的,采用递增的方式,为每个操作赋予唯一的事务ID。最后一次操作的事务ID还会被写入到文件(seen_txid),namenode重启后会读取这些信息,并在最后一次事务ID上继续递增。
每个edit Log文件的文件名都有固定的格式,其中当前正在写的文件名格式为edits_inprogress_TXID,TXID为该文件中记录的第一个操作的事务ID;已经写完成的edit log文件名为 edts_StartTXID_EndTXID,StartTXID为该文件中记录的第一个操作的事务ID,EndTXID为该文件中记录的最后一个操作的事务ID,如下所示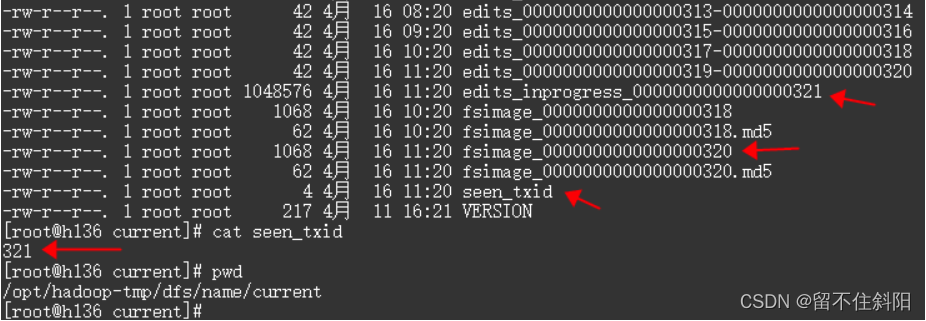
说明:上图存在两个版本的fsimage分别为后缀318和320,318为上一次合并的fsimage文件,320表示当前的fsimage文件,当前日志是edits_inprogress_0000000000000000321,seen_txid记录着最新的编辑日志文件编号321
每次NameNode启动的时候都会将fsimage文件读入内存,从seen_txid文件中找到应该执行的Edits文件里的编号,执行所有Edits文件名末尾数字比seen_txid文件数字大的文件。如果seen_txid文件存储的是528,那么就意味着。重新启动NameNode时,NameNode会自动执行 edits_0000000000000000528文件及其之后的文件:如edits_0000000000000000529、edits_0000000000000000530等,直到最后一个,假设最后一个是531。然后生成一个edits_inprogress_0000000000000000532文件,用于记录启动之后的操作,然后,seen_txid文件里的数字就会变成532。
edits.new:又称edits_inprogress,正在写入的edits文件,用于存储最新的操作日志。每次checkponit,fsimage更新完成之后,重命名edits文件。
5.4.Fsimage和Edits解析
5.4.1.基本概念
- 如果每次对 HDFS 的操作都实时的把内存中的元数据信息往磁盘上传输,这样显然效率不够高,也不稳定,这时就出现了 Edits 文件,用来记录每次对 HDFS 的操作,这样在磁盘上每次就只用做很小改动(只进行追加操作),当 Edits 文件达到了一定大小或过了一定的时间,就需要把 Edits 文件转化 Fsimage 文件,然后重新生成一个edits_inprogress文件,这样的 Fsimage 文件不会和内存中的元数据实时同步,需要加上 Edits 文件才相等。
- namenode被格式化之后,在NameNode服务器的dfs.namenode.name.dir目录中(一般为/data/dfs/name/current)产生如下文件
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
- Fsimage文件:HDFS文件系统元数据的一个永久性检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
- Edits文件:编辑日志,存放着对HDFS文件系统的所有更新操作,文件系统客户端执行的所有增删改操作首先会被记录到edits文件中。
- seen_txid文件保存的是一个数字,就是最后一个edits_inprogress的数字
- 每次NameNode启动的时候都会将fsimage文件读入内存,并执行所有Edits文件名末尾数字比seen_txid中记录的数字大的文件,保证内存中的元数据信息是最新的、同步的。
5.4.2.fsimage文件基本操作
查看oiv和oev命令
hdfs --help
Usage: hdfs [--config confdir] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
dfsadmin run a DFS admin client
diskbalancer Distributes data evenly among disks on a given node
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
mover run a utility to move block replicas across
storage types
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to an legacy fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version 3 gateway
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
storagepolicies list/get/set block storage policies
version print the version
hdfs oiv --help
Usage: bin/hdfs oiv [OPTIONS] -i INPUTFILE -o OUTPUTFILE
Offline Image Viewer
View a Hadoop fsimage INPUTFILE using the specified PROCESSOR,
saving the results in OUTPUTFILE.
The oiv utility will attempt to parse correctly formed image files
and will abort fail with mal-formed image files.
The tool works offline and does not require a running cluster in
order to process an image file.
The following image processors are available:
* XML: This processor creates an XML document with all elements of
the fsimage enumerated, suitable for further analysis by XML
tools.
* reverseXML: This processor takes an XML file and creates a
binary fsimage containing the same elements.
* FileDistribution: This processor analyzes the file size
distribution in the image.
-maxSize specifies the range [0, maxSize] of file sizes to be
analyzed (128GB by default).
-step defines the granularity of the distribution. (2MB by default)
* Web: Run a viewer to expose read-only WebHDFS API.
-addr specifies the address to listen. (localhost:5978 by default)
* Delimited (experimental): Generate a text file with all of the elements common
to both inodes and inodes-under-construction, separated by a
delimiter. The default delimiter is \t, though this may be
changed via the -delimiter argument.
Required command line arguments:
-i,--inputFile <arg> FSImage or XML file to process.
Optional command line arguments:
-o,--outputFile <arg> Name of output file. If the specified
file exists, it will be overwritten.
(output to stdout by default)
If the input file was an XML file, we
will also create an <outputFile>.md5 file.
-p,--processor <arg> Select which type of processor to apply
against image file. (XML|FileDistribution|
ReverseXML|Web|Delimited)
The default is Web.
-delimiter <arg> Delimiting string to use with Delimited processor.
-t,--temp <arg> Use temporary dir to cache intermediate result to generate
Delimited outputs. If not set, Delimited processor constructs
the namespace in memory before outputting text.
-h,--help Display usage information and exit
基本语法
hdfs oiv -p 输出文件类型 -i 镜像文件 -o 转换后文件输出路径
案例实操
$ hdfs oiv -p XML -i fsimage_0000000000005894269 -o /tmp/fsimage.xml
$ cat /tmp/fsimage.xml
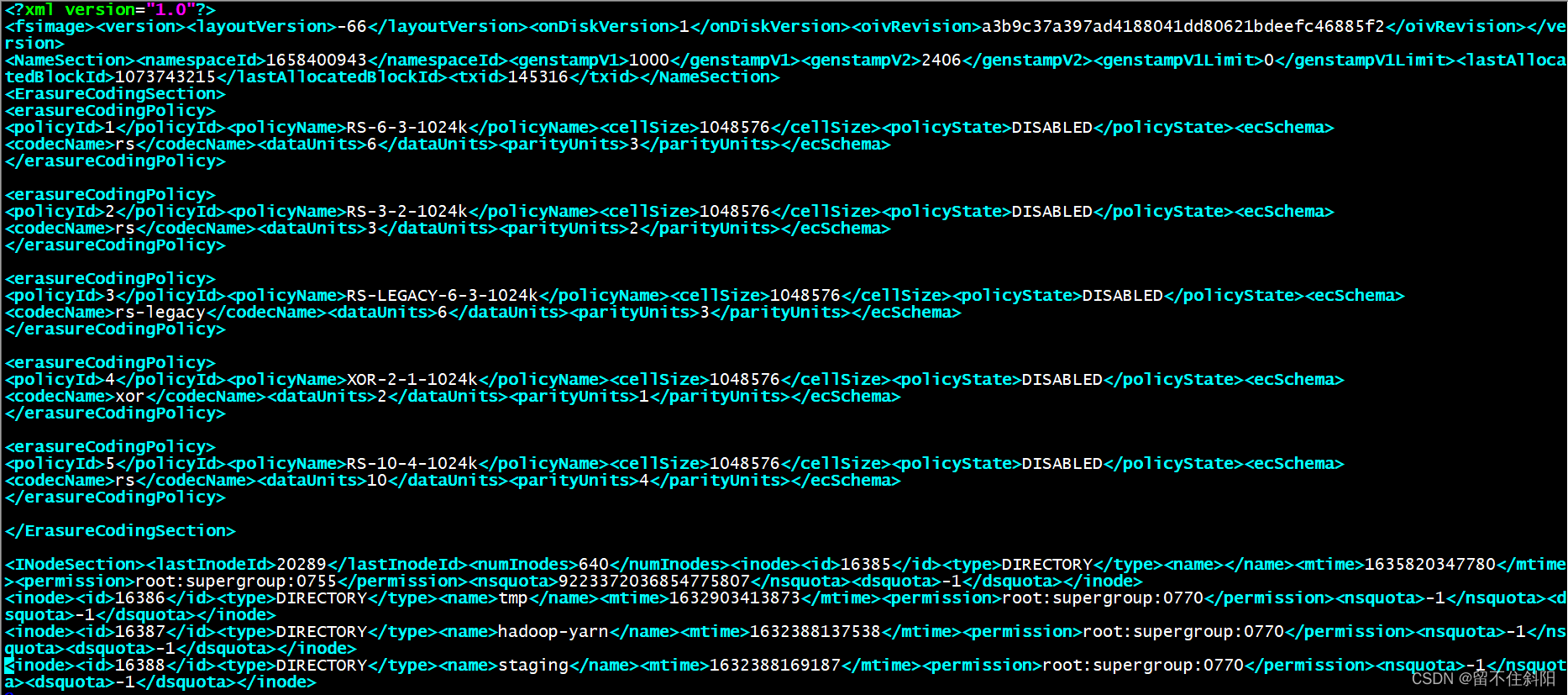
如上图中,每一个inode表示一个文件的元数据信息,包括inode的id以及类型,类型是由上述的type标签进行指定以及通过name标签指定它的名称,block指定它的块以及修改时间等信息。
inode是单个文件或目录的元数据信息,它的层次关系是通过id进行实现的,也就是哪个目录下存在什么文件
<directory><parent>16386</parent><child>16387</child><child>16388</child></directory>
parent表示是父节点的id,child表示子节点的id,这样表示一个层次的关系。
该数据结构中存储块的id信息,但是不能确定块是存储在哪个DataNode上的,当设置的副本数小于服务器节点数,会按一定策略进行选择副本去存储。这个数据块及其存储的服务器信息,是在NameNode启动的时候由DataNode进行提交到NameNode的内存中的。
oev查看edits文件
- 基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
案例实操
$ hdfs oev -p XML -i edits_0000000000005900756-0000000000005901164 -o /tmp/edits.xml
$ cat /tmp/edits.xml
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-60</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>5900756</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD</OPCODE>
<DATA>
<TXID>5900757</TXID>
<LENGTH>0</LENGTH>
<INODEID>1164250</INODEID>
<PATH>/tmp/.cloudera_health_monitoring_canary_files/.canary_file_2019_08_14-08_15_58</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1565741758249</MTIME>
<ATIME>1565741758249</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-599989334_69</CLIENT_NAME>
<CLIENT_MACHINE>10.13.11.22</CLIENT_MACHINE>
<OVERWRITE>true</OVERWRITE>
<PERMISSION_STATUS>
<USERNAME>hdfs</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>438</MODE>
</PERMISSION_STATUS>
<RPC_CLIENTID>c38f5acc-9324-48a2-be95-98c393a68de8</RPC_CLIENTID>
<RPC_CALLID>443299</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<DATA>
<TXID>5900758</TXID>
<BLOCK_ID>1074468491</BLOCK_ID>
</DATA>
</RECORD>
</EDITS>
5.5.checkpoint时间设置
Secondary NameNode可以定时或者到达一定的数据量(操作次数)就会去进行合并fsimage和edits文件,可以在hdfs-site.xml文件进行配置。
通常情况下,SecondaryNameNode每隔一小时执行一次。hdfs-default.xml配置文件中默认配置
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>单位:秒,两个周期文件系统检查点时间间隔</description>
</property>
10分钟检查一次操作次数,当操作次数达到事物数后,SecondaryNameNode执行一次,创建一个检查点,无论检查点周期是否到期。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>事物数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>600</value>
<description>每间隔10分钟检查一次操作次数是否到达</description>
</property>
5.6.NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
5.6.1 方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
- kill -9 NameNode进程
- 删除NameNode存储的数据(dfs.namenode.name.dir)
$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
- 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
$ scp -r [email protected]:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/
- 重新启动namenode
$ sbin/hadoop-daemon.sh start namenode
5.6.2 方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
- 修改hdfs-site.xml配置
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
<description>秒数</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
- kill -9 namenode进程
- 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
- 如果SecondaryNameNode和NameNode不在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件。
$ scp -r [email protected]:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./
$ rm -rf in_use.lock
$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
$ ls
data name namesecondary
- 导入检查点数据(等待一会ctrl+c结束掉)
$ bin/hdfs namenode -importCheckpoint
- 启动namenode
$ sbin/hadoop-daemon.sh start namenode
Secondary NameNode可以恢复绝大部分数据,跟NameNode主要差异就是Secondary NameNode中没有NameNode最新的编辑日志,因为编辑日志是按一定规则进行提交合并的,不符合条件的edits文件就存在于NameNode中,所以如果服务器出现问题需要进行NameNode的恢复,那么通过Secondary NameNode不一定可以完全恢复所有的数据。
上述故障恢复做一个了解,目前使用的是HA的架构,会创建多个NameNode,当发生故障会自动切换到其他可用的NameNode
5.7.集群安全模式
5.7.1.基本概述
- NameNode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。但是此刻,NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
- 系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
- 如果满足“最小副本条件”,NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
集群进入安全模式的时候,不能正常操作,例如不能正常修改HDFS上的文件。
上述可以在Web端可以看到该字段,Safemode为off表示关闭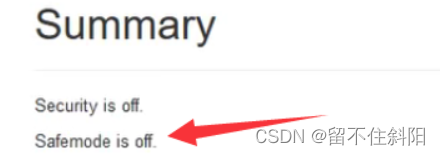
5.7.2.基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
查看安全模式状态
bin/hdfs dfsadmin -safemode get
进入安全模式状态
bin/hdfs dfsadmin -safemode enter
离开安全模式状态
bin/hdfs dfsadmin -safemode leave
等待安全模式状态
bin/hdfs dfsadmin -safemode wait
5.7.3.案例
需求:模拟等待安全模式
- 先进入安全模式
bin/hdfs dfsadmin -safemode enter
- 执行下面的脚本
#!/bin/bash
bin/hdfs dfsadmin -safemode wait
bin/hdfs dfs -put ~/hello.txt /root/hello.txt
- 再打开一个窗口,执行
bin/hdfs dfsadmin -safemode leave
5.8.NameNode多目录配置
NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
具体配置步骤
- 在hdfs-site.xml文件中增加如下内容
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///dfs/name1,file:///dfs/name2</value>
</property>
- 停止集群,删除data和logs中所有数据。
rm -rf data/ logs/
- 格式化集群并启动。
bin/hdfs namenode –format
sbin/start-dfs.sh
- 查看结果
ll
总用量 12
drwx------. 3 lubin lubin 4096 12月 11 08:03 data
drwxrwxr-x. 3 lubin lubin 4096 12月 11 08:03 name1
drwxrwxr-x. 3 lubin lubin 4096 12月 11 08:03 name2
边栏推荐
- QT按钮点击切换QLineEdit焦点(含代码)
- (POJ - 3258) River hopper (two points)
- Tree of life (tree DP)
- (POJ - 1458) common subsequence (longest common subsequence)
- Openwrt source code generation image
- Generate random password / verification code
- Li Kou: the 81st biweekly match
- Market trend report, technological innovation and market forecast of double door and multi door refrigerators in China
- Date plus 1 day
- AcWing:第56场周赛
猜你喜欢

Codeforces Round #799 (Div. 4)A~H
顺丰科技智慧物流校园技术挑战赛(无t4)
Share an example of running dash application in raspberry pie.

2027. Minimum number of operations to convert strings

Summary of game theory
Kubernetes集群部署
Hbuilder X格式化快捷键设置
本地可视化工具连接阿里云centOS服务器的redis
Installation and use of VMware Tools and open VM tools: solve the problems of incomplete screen and unable to transfer files of virtual machines
Codeforces Round #801 (Div. 2)A~C
随机推荐
Tree of life (tree DP)
浏览器打印边距,默认/无边距,占满1页A4
QT按钮点击切换QLineEdit焦点(含代码)
Raspberry pie 4B installation opencv3.4.0
QT simulates mouse events and realizes clicking, double clicking, moving and dragging
Acwing - game 55 of the week
1529. Minimum number of suffix flips
875. 爱吃香蕉的珂珂 - 力扣(LeetCode)
Pull branch failed, fatal: 'origin/xxx' is not a commit and a branch 'xxx' cannot be created from it
1689. Ten - the minimum number of binary numbers
QT style settings of qcobobox controls (rounded corners, drop-down boxes, up expansion, editable, internal layout, etc.)
QT实现窗口置顶、置顶状态切换、多窗口置顶优先关系
(lightoj - 1370) Bi shoe and phi shoe (Euler function tabulation)
Discussion on QWidget code setting style sheet
Li Kou - 298th weekly match
Sanic异步框架真的这么强吗?实践中找真理
Problem - 922D、Robot Vacuum Cleaner - Codeforces
Suffix expression (greed + thinking)
useEffect,函数组件挂载和卸载时触发
QT实现窗口渐变消失QPropertyAnimation+进度条