当前位置:网站首页>读取和保存zarr文件
读取和保存zarr文件
2022-07-06 09:28:00 【深山里的小白羊】
前言
zarr一种数据格式,和hdf文件有点类似,即一个文件里面可以包含很多不同的dataset
与hdf文件不同,直观上看hdf是一个单一的文件,而zarr是一个文件夹,里面还包含不同的子文件夹(相当于hdf中的dataset),子文件夹下面保存着数据
另一点,zarr分块保存数据,直白来讲,就是将一整块的数据划分成相同大小的子块,每个子块保存成一个文件,命名为*.*.*,这样处理的好处是对于大规模的医学图像非常友好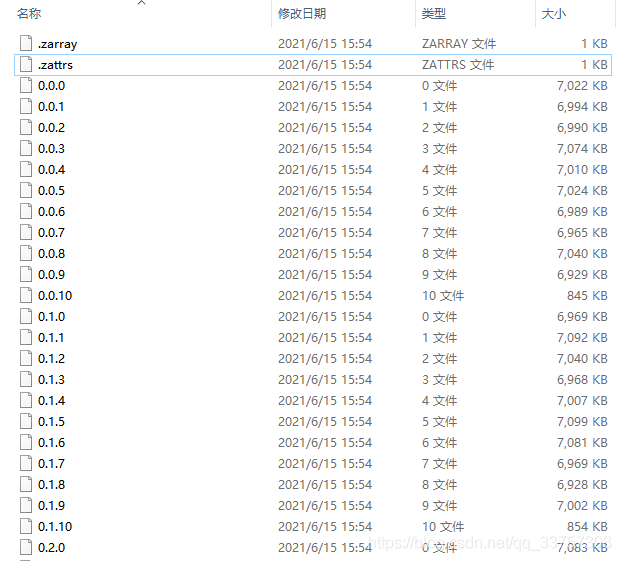
还有两个特殊的文件是.zarray和.zattrs,里面分别保存着数据特性和大小信息等等,例如
.zarray
.zattrs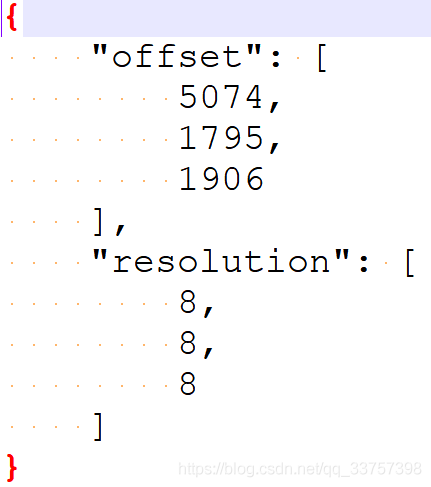
读取
import zarr
import numpy as np
input_name = 'data.zarr'
dataset_name = 'volumes/raw'
f = zarr.open(input_name)
raw = f[dataset_name ]
print(raw.shape)
raw_data = raw[:]
保存
import zarr
import numpy as np
output_name = 'data.zarr'
dataset_name = 'volumes/raw'
root = zarr.open(output_name , mode='a')
shape = [1000, 1000, 1000] # 整个数据的大小,3D
chunk_size = [128, 128, 128] # 分块的大小
dtype = np.uint8 # 数据类型
compressor = {
'id': 'gzip', 'level': 5}
compressor = zarr.get_codec(compressor) # 压缩方式
dataset_name = dataset_name.lstrip('/')
ds = root.create_dataset(
dataset_name,
shape=shape,
chunks=chunk_size,
dtype=dtype,
compressor=compressor)
ds.attrs['resolution'] = [8, 8, 8]
ds.attrs['offset'] = [0, 0, 0]
ds[:] = np.ones(tuple(shape), dtype=dtype)
边栏推荐
- 【练习-2】(Uva 712) S-Trees (S树)
- Common configuration files of SSM framework
- [exercise-7] (UVA 10976) fractions again?! (fraction split)
- Differential (one-dimensional, two-dimensional, three-dimensional) Blue Bridge Cup three body attack
- 信息安全-威胁检测-flink广播流BroadcastState双流合并应用在过滤安全日志
- 1855. Maximum distance of subscript alignment
- 【练习-9】Zombie’s Treasure Chest
- [exercise-6] (UVA 725) division = = violence
- Penetration test 2 --- XSS, CSRF, file upload, file inclusion, deserialization vulnerability
- Opencv learning log 13 corrosion, expansion, opening and closing operations
猜你喜欢

Information security - threat detection engine - common rule engine base performance comparison
![[exercise-7] crossover answers](/img/66/3dcba2e70a4cd899fbd78ce4d5bea2.png)
[exercise-7] crossover answers

1903. Maximum odd number in string
PySide6 信号、槽
605. Planting flowers
Penetration test (1) -- necessary tools, navigation
【高老师UML软件建模基础】20级云班课习题答案合集
【练习-7】Crossword Answers
Borg Maze (BFS+最小生成树)(解题报告)

渗透测试 ( 5 ) --- 扫描之王 nmap、渗透测试工具实战技巧合集
随机推荐
【练习-9】Zombie’s Treasure Chest
Quick to typescript Guide
【练习-6】(PTA)分而治之
Analysis of protobuf format of real-time barrage and historical barrage at station B
Truck History
Data storage in memory & loading into memory to make the program run
树莓派4B安装opencv3.4.0
【高老师UML软件建模基础】20级云班课习题答案合集
HDU - 6024 building shops (girls' competition)
对iptables进行常规操作
Truck History
[exercise -11] 4 values why sum is 0 (and 4 values of 0)
Ball Dropping
Auto.js入门
MySQL grants the user the operation permission of the specified content
想应聘程序员,您的简历就该这样写【精华总结】
Research Report of peripheral venous catheter (pivc) industry - market status analysis and development prospect prediction
【练习-6】(Uva 725)Division(除法)== 暴力
Essai de pénétration (1) - - outils nécessaires, navigation
PySide6 信号、槽