当前位置:网站首页>Story of [Kun Jintong]: talk about Chinese character coding and common character sets
Story of [Kun Jintong]: talk about Chinese character coding and common character sets
2022-07-06 16:36:00 【Ruo Miaoshen】
List of articles
Before N All the articles mentioned Chinese characters garbled , It's really a problem that has plagued us for a long time .
Regardless of the development language , Disk files , database , Coding problems may occur in network transmission .
( One ) code
The computer has no code , They only recognize 0101 Binary system ( We often write formats for convenience 0xFF Of 16 Base number ).
So to display any text, you need to encode , Even English letters . So it was human beings who created the code .
Keep the nonsense short :
PS: The content and pictures come from Baidu and other websites ( Those who can find links are given ).
1.1 ASCII code
ASCII= American Standard Code for Information Interchange= American Standard Code for information exchange
A single byte represents a character , The highest bit is 0, The combination of other bits represents various English letters and symbols , such as :
most : 0111 1111,7F
HEX:41 42 43 44 2C 31 32 33 34 —— ABCD,1234
In English , use 128 A symbol code can represent all letters and symbols , But it is not enough to express other languages .
1.2 ASCII Code extension
Use the highest bit , For example, in French é The code of is 130( Binary system 10000010).
thus , The coding system used by these European countries , Can mean at most 256 Symbols .
most : 1111 1111,FF
But different countries have different letters , therefore , Even if they all use 256 The encoding of symbols , The letters are different . such as :
byte (130) In French coding, it stands for é,
In Hebrew code, it stands for the letters Gimel (ג),
In Russian code, it will represent another symbol .
But anyway , Of all these coding methods ,0–127 The symbols are the same , It's just that 128–255 This part of .
PS: In order to know the specific characters represented by the same code , We must know the meaning of this passage Character set .
1.3 Chinese characters ( Including other words ) Multi byte encoding of
Because we have the national standard code (GB) There are also international standard codes (Unicode), So Chinese is relatively complicated .
- GB2312 code :1981 year 5 month 1 The national standard for simplified Chinese character coding issued on May .GB2312 Use of Chinese characters Double byte code , Included 7445 Graphic characters , These include 6763 The Chinese characters .
- BIG5 code : Taiwan Traditional Chinese standard character set , Double byte encoding is adopted , Collects 13053 Chinese characters ,1984 Year of implementation .
- GBK code :1995 year 12 The national standard for Chinese character coding issued in May , It's right GB2312 Expansion of coding , Use of Chinese characters Double byte code .GBK The character set contains 21003 The Chinese characters , Including national standards GB13000-1 All the Chinese, Japanese and Korean characters in , and BIG5 All Chinese characters in the code .
- GB18030 code :2000 year 3 month 17 National standard of Chinese character coding issued by Japan , It's right GBK Expansion of coding , Cover Chinese 、 Japanese 、 Korean and Chinese minority languages , It includes 27484 The Chinese characters .GB18030 Character set uses Single byte 、 Double byte and Four bytes Three ways to encode characters . compatible GBK and GB2312 Character set .
- Unicode code : International standard character set , It defines a unique code for each character in various languages in the world , To meet cross language needs 、 Cross platform text information conversion .Unicode use Four bytes Code for each character .
- UTF-8 and UTF-16 code :Unicode Encoding conversion format , Variable length encoding , be relative to Unicode More space saving .UTF-16 The byte order of has a big tail (big-endian) And small tail sequence (little-endian) The difference .PS:UTF-8 The Chinese character of is usually Three bytes .
Our national standard code ( Character set ) It developed like this :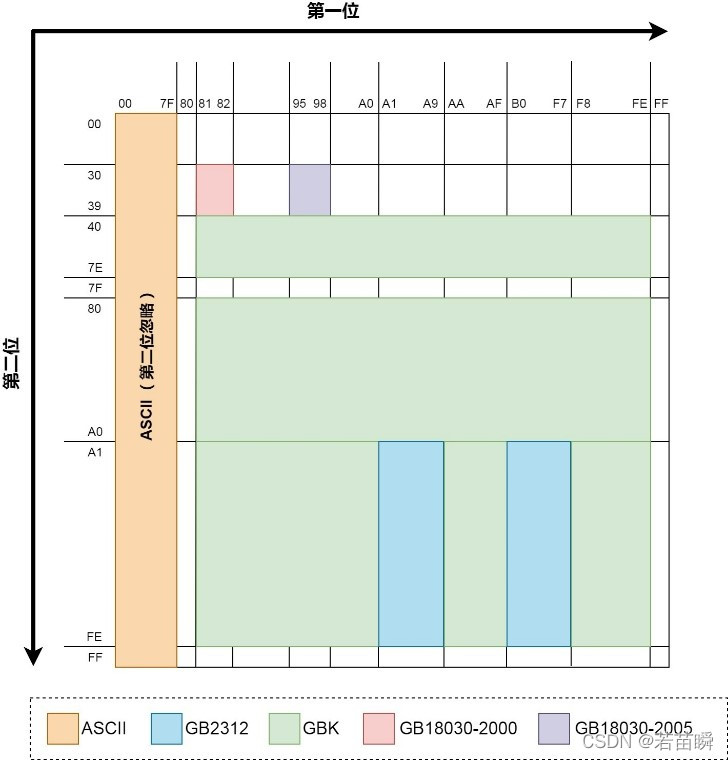
1.4 Coding examples and tests
for instance , Four Chinese characters ( Reference resources Website )
【 I 〇 䶵 𬌗 】
- I : frequently-used character , There are all kinds of character set codes .
- 〇: In the early GB2312 Not included .
- 䶵: Japanese Kanji ? Reference link ,GBK Not included ,GB18030 It's four bytes ,UTF-8 It's three bytes
- 𬌗: Occlusal surface of teeth , Reference link ,GBK Not included ,GB18030 It's four bytes ,UTF-8 It's four bytes .
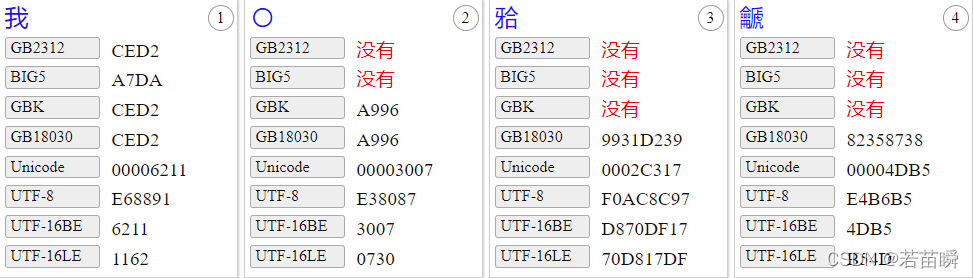
use Java Test it , The code is as follows :
String aTestStr=" Chinese I 〇䶵𬌗abc";
{
System.out.print("UTF-8 :");
byte[] gb = aTestStr.getBytes(StandardCharsets.UTF_8);
for (byte b : gb)
System.out.printf("%#02x,", b);
System.out.println("\n"+new String(gb, StandardCharsets.UTF_8)+"\n");
}
{
System.out.print("GB18030:");
byte[] gb = aTestStr.getBytes("GB18030");
for (byte b : gb)
System.out.printf("%#02x,", b);
System.out.println("\n"+new String(gb, "GB18030")+"\n");
}
{
System.out.print("GBK :");
byte[] gb = aTestStr.getBytes("GBK");
for (byte b : gb)
System.out.printf("%#02x,", b);
System.out.println("\n"+new String(gb, "GBK")+"\n");
}
{
System.out.print("GB2312 :");
byte[] gb = aTestStr.getBytes("GB2312");
for (byte b : gb)
System.out.printf("%#02x,", b);
System.out.println("\n"+new String(gb, "GB2312")+"\n");
}
The output is as follows , Consistent with the above table :
Uh , Take a closer look , Or remove irrelevant words ...
UTF-8 :0xe4,0xb8,0xad,0xe6,0x96,0x87,0xe6,0x88,0x91,0xe3,0x80,0x87,0xe4,0xb6,0xb5,0xf0,0xac,0x8c,0x97,0x61,0x62,0x63,
Chinese I 〇䶵𬌗abc
GB18030:0xd6,0xd0,0xce,0xc4,0xce,0xd2,0xa9,0x96,0x82,0x35,0x87,0x38,0x99,0x31,0xd2,0x39,0x61,0x62,0x63,
Chinese I 〇䶵𬌗abc
GBK :0xd6,0xd0,0xce,0xc4,0xce,0xd2,0xa9,0x96,0x3f,0x3f,0x61,0x62,0x63,
Chinese I 〇??abc
GB2312 :0xd6,0xd0,0xce,0xc4,0xce,0xd2,0x3f,0x3f,0x3f,0x61,0x62,0x63,
Chinese I ???abc
( Two ) Show the reason for the garbled code
2.1 Out of coding range
As in the above example ,GBK,GB2312 There are random codes , Rare words appear ? question mark .
If the bytecode of a string stores the encoded content that is not in the character set used ,
The display will produce confused symbols and strange characters that you can't understand , Generally we call it garbled .
PS: Encountered before :《Python When writing to a text file ‘GBK’ The encoder cannot encode characters ‘\uXXYY‘》 It's the coding range .
The article is not written correctly , I'm too lazy to change , The results of the above test ,Java It's not a designation GBK Just relax , have to GB18030 ah !
2.2 code UTF8 Of BOM
stay Windows Maybe some UTF8 The coding , front 3 Is it Bit Order Mark( I made a mistake ), But in fact UTF8 There is no need to identify bits in byte order , So the only function is to show that this is a UTF8 The file of .
This is not a very general , We all accept the setting ( Please find out for yourself BOM), such as Linux I don't recognize BOM Of .
If you ignore BOM It will cause a little bit of garbled code in front of it when reading .
The best way is not to use BOM, chinese UTF8 code ( Yes BOM) The data example of is as follows :
EF BB BF 41 42 43 31 32 33 2C E4 B8 AD E6 96 87 E6 B1 89 E5 AD 97
“ABC123, Chinese characters ”
2.3 No Chinese support
For example, the operating system does not support , Chinese fonts are not installed .
Even if the content encoding is correct , But the system doesn't know what is GB18030, Nothing can show GB18030 The font of . It can only be displayed as garbled .
In fact, this situation cannot be called garbled , The code is right , But it can't be displayed ( It's usually a box ?).
2.4 Wrong code
Bingo!
Compared with the previous few less common reasons , Wrong coding when programming , Is the main cause of garbled code .
The so-called wrong use , Is to use a kind of code , Read the bytecode content of another encoding .
The most common : use GB Serial encoding mode read UTF8, use UTF8 read GB series .
PS: Encountered before :《 upgrade HBase2 Character encoding and Chinese display 》 It belongs to the wrong code ,
But I didn't write it wrong on my own initiative , It is String.getBytes No character set parameters were passed , The problem of using the system default character set .
Windows/Linux The default is different , and Java In subsequent operations (HBASE Take out the data ) For unspecified text , Have adopted UTF8 Handle .
I don't know which God sorted out the form below , When encountering garbled code, you can have a look .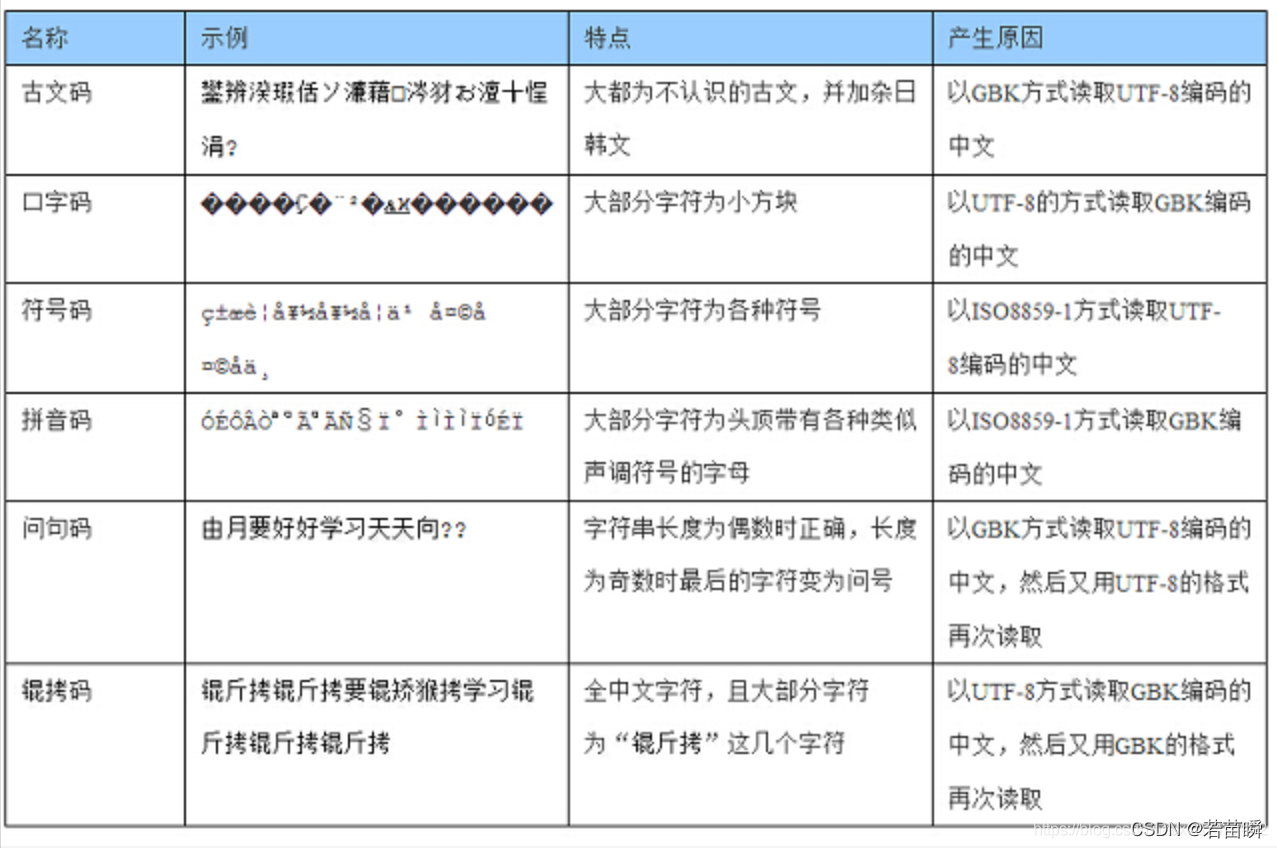
2.5 Original bytecode error
If it's like the one mentioned above : After reading incorrectly, the content is written into a new text file , Then the new text file is encoded incorrectly .
The original bytecode of the text has been wrong , No matter how you read it later , The display is all wrong .
especially 【 Kunjin copy 】 such , Is an unrecoverable error .
( 3、 ... and ) Avoid reading and writing garbled files
3.1 Note the default encoding
- Java By default UTF8 code .
- Linux The default is UTF8 code .
- Windows The default is GB18030 code ( Everybody says GBK, however GBK Smaller range , Ah )
- Even if Windows Next ,IntelliJ IDEA The default unit test for is UTF8 code ( How to test is different from the formal runtime ?).
3.2 Specified encoding
- open , When writing to a text file , To specify an encoding , You need to specify the correct .
- Correct encoding requires no conversion , The code to be converted must be wrong .
3.3 Don't rely too much on automatic judgment
Two cases :
- The content is too short , Both coding ranges are included .
- The file is too large , Only English in front , Do you need to finish reading 10GB Text to judge the coding ?
The second situation is easy to understand ,
And the first case , There are only a few Chinese characters in the content , Such as UTF8 Coded 【 Jump jump 】,【 tinkling of jade pendants 】:
jump (UTF8) = E8 B7 83
Sam (UTF8) = E7 8F 8A
So the lovely reduplication is :
Jump jump (UTF8) = E8 B7 83,E8 B7 83
tinkling of jade pendants (UTF8) = E7 8F 8A,E7 8F 8A
If we 2 Look at bytes in groups :
Jump jump (UTF8) = E8 B7 83,E8 B7 83 = E8 B7,83 E8,B7 83 = Pathetic (GB18030)
tinkling of jade pendants (UTF8) = E7 8F 8A,E7 8F 8A = E7 8F,8A E7,8F 8A = Strong (GB18030)
Although not a common word , But it can be concluded that GB18030 Is it wrong ?
Maybe Yue Yue and Shan Shan look too normal ,
Let's take another example 【 趃 珋 】 and 【 Zan mi 】 Who on earth is right ?
( Four ) Extend the discussion :Oracle Character set for
Be careful Oracle It looks something like this :
- Oracle Even the English character set of the server, such as ISO8859p1 You can also store Chinese .
- It only needs Oracle The character set settings of client and server are consistent .
- Except for one kind of coding : Server side AL32UTF8, The client can set Jianzhong ZHS16GBK / In complexity ZHT16BIG5.
- Be a server AL32UTF8 when , The client should not be set to AL32UTF8.
The principle is as follows , But be careful of pits :
- Various client software tools handle character sets differently .
- Java8 Don't use Oracle Client character set ( clam ???).
For example, I have tried the following client tools ( Does not mean all versions !):
- TOAD: Not according to NLS_LANG environment variable , Unable to set character set , Only support ZHS16GBK.
- PL/SQL: according to NLS_LANG environment variable , Unable to set character set , But import data to AL32UTF8 Time is actually ZHS16GBK code , The query can be displayed correctly at the same time AL32UTF8 and ZHS16GBK Chinese for .
- Navicat: Import and query according to the set character set , But Chinese characters often make mistakes when importing .
Java With Alibaba's Druids, I managed to solve , You can refer to the problems encountered before .
This :《Oracle The database character set is WE8ISO8859P1 Store Chinese and Java Reading and writing display 》
as well as :《Oracle The database character set is WE8ISO8859P1 Store Chinese and client programs to show Chinese problems 》
( Four ) Extend the discussion :FTP Character encoding of
We develop FTP It is also easy to encounter garbled code , But mature FTP Tools generally do not .
That's because others judge carefully , Will ask in detail FTP Supported instructions , Including command coding method .
- Simply put, if FTP The service side with UTF8, Then no conversion is required .
- If the server is not UTF-8, Then we need to put our GBK Bytecode , Forcibly convert to the code of the server ( Include 8859-1 A class ).
Name related instructions ,list,put,get, Usually there is a directory name , Call everywhere in the file name .
Why? GBK turn 8859-1, No UTF8 turn 8859-1 Well , Because if it is UTF8 It already supports Chinese !!!
Um. , It's a matter of logic ……
Part of the code is as follows :
public String FromServerEncodingString(String aOriString) throws Exception {
if (ftp.getControlEncoding().equalsIgnoreCase("UTF-8")) return aOriString.trim();
else return new String(aOriString.getBytes(ftp.getControlEncoding()), "GBK").trim();
}
public String ToServerEncodingString(String aOriString) throws Exception {
if (ftp.getControlEncoding().equalsIgnoreCase("UTF-8")) return aOriString.trim();
else return new String(aOriString.getBytes("GBK"), ftp.getControlEncoding());
}
But fortunately, SFTP That is to say SSH agreement , It seems to be unified UTF8 code .
Make complaints about it FTP What a loose agreement !!!
For the time being , We'll talk about it in the future when we encounter new situations .
边栏推荐
- Codeforces Round #801 (Div. 2)A~C
- < li> dot style list style type
- (lightoj - 1354) IP checking (Analog)
- Log statistics (double pointer)
- QT implementation fillet window
- 第5章 NameNode和SecondaryNameNode
- (POJ - 3186) treatments for the cows (interval DP)
- 两个礼拜速成软考中级软件设计师经验
- 拉取分支失败,fatal: ‘origin/xxx‘ is not a commit and a branch ‘xxx‘ cannot be created from it
- Kubernetes集群部署
猜你喜欢
Codeforces Round #801 (Div. 2)A~C
Oneforall installation and use
QT realizes window topping, topping state switching, and multi window topping priority relationship
QWidget代码设置样式表探讨
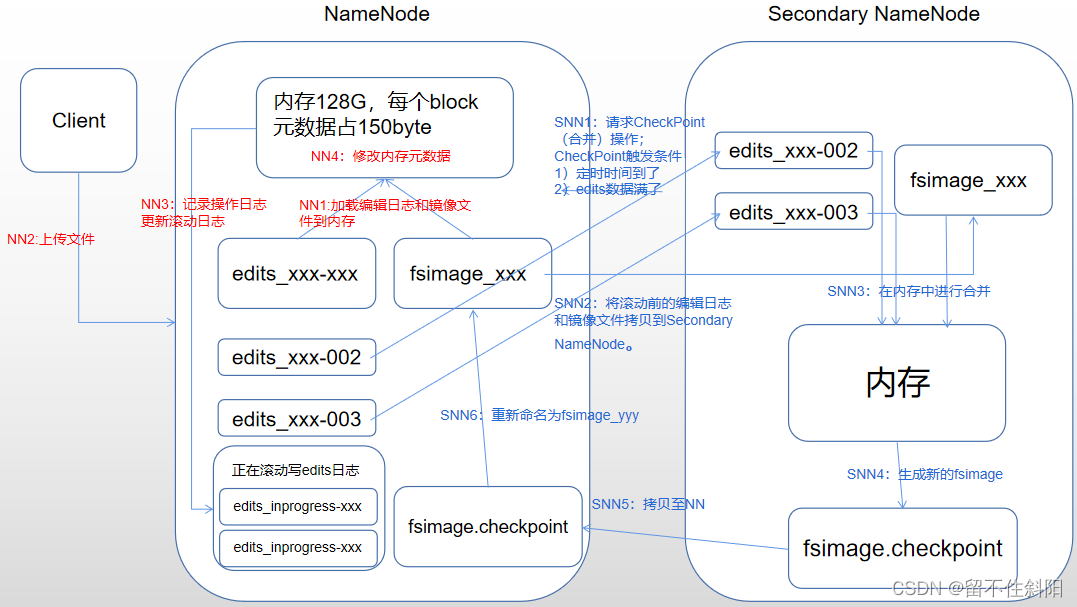
第5章 NameNode和SecondaryNameNode
Spark独立集群Worker和Executor的概念
Raspberry pie 4B installation opencv3.4.0

去掉input聚焦时的边框

pytorch提取骨架(可微)

业务系统从Oracle迁移到openGauss数据库的简单记录
随机推荐
Local visualization tools are connected to redis of Alibaba cloud CentOS server
Tert butyl hydroquinone (TBHQ) Industry Research Report - market status analysis and development prospect forecast
Raspberry pie 4b64 bit system installation miniconda (it took a few days to finally solve it)
Research Report of desktop clinical chemical analyzer industry - market status analysis and development prospect prediction
Problem - 1646C. Factorials and Powers of Two - Codeforces
Acwing: Game 58 of the week
AcWing——第55场周赛
MariaDB的安装与配置
Research Report on market supply and demand and strategy of China's four seasons tent industry
(lightoj - 1236) pairs forming LCM (prime unique decomposition theorem)
本地可视化工具连接阿里云centOS服务器的redis
QT实现窗口置顶、置顶状态切换、多窗口置顶优先关系
原生js实现全选和反选的功能 --冯浩的博客
pytorch提取骨架(可微)
(lightoj - 1349) Aladdin and the optimal invitation (greed)
sublime text 代码格式化操作
Investigation report of bench type Brinell hardness tester industry - market status analysis and development prospect prediction
Li Kou: the 81st biweekly match
VMware Tools和open-vm-tools的安装与使用:解决虚拟机不全屏和无法传输文件的问题
顺丰科技智慧物流校园技术挑战赛(无t4)