当前位置:网站首页>第6章 Rebalance详解
第6章 Rebalance详解
2022-07-06 09:29:00 【留不住斜阳】
rebalance本质是一种协议,规定了一个consumer group下的所有consumer如何达成一致来分配订阅的topic的每个分区。比如某个group下有20个consumer,它订阅了一个具有100个分区的topic。正常情况下,Kafka平均会为每个consumer分配5个分区。这个分配的过程就叫rebalance。
6.1 触发rebalance的条件
rebalance的触发条件有三种:
- 组成员发生变更(新consumer加入组、已有consumer主动离开组或已有consumer崩溃)
- 订阅主题数发生变更——这当然是可能的,如果你使用了正则表达式的方式进行订阅,那么新建的匹配正则表达式的topic就会触发rebalance
- 订阅主题的分区数发生变更
6.2 rebalance分配机制
Kafka新版本consumer默认提供了两种分配策略:range和round-robin。当然Kafka采用了可插拔式的分配策略,可以自定义分配器以实现不同的分配策略。实际上,由于目前range和round-robin两种分配器都有一些弊端,Kafka社区已经提出第三种分配器来实现更加公平的分配策略,目前还在开发中。
简单举个例子,假设目前某个consumer group下有两个consumer:A和B,当第三个成员加入时,kafka会触发rebalance并根据默认的分配策略重新为A、B和C分配分区,如下图所示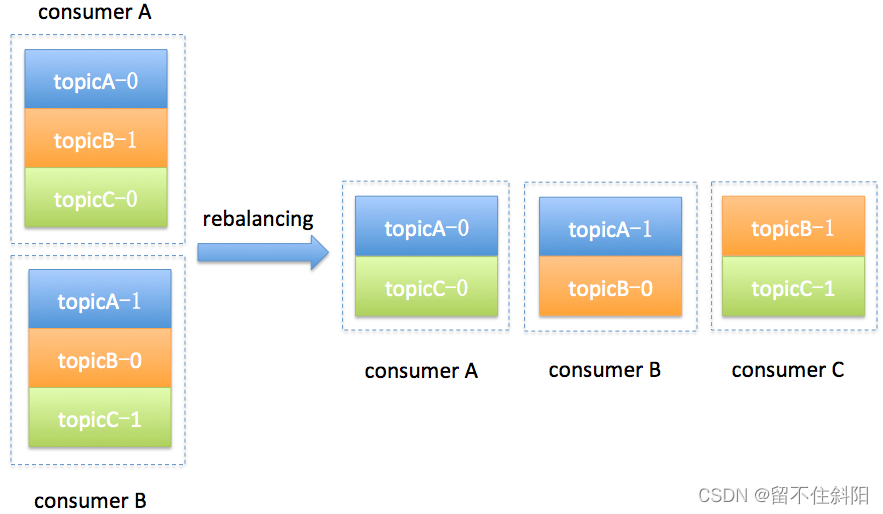
6.3 执行rebalance和consumer group管理
Kafka由Coordinator执行Rebalance和consumer group管理;
首先是0.8版本的coordinator,那时候coordinator是依赖zookeeper来实现对consumer group进行管理。Coordinator监听zookeeper的/consumers/<group>/ids的子节点变化以及/brokers/topics/<topic>数据变化来判断是否需要进行rebalance。group下的每个consumer都自己决定要消费哪些分区,并把自己的决定抢先在zookeeper中的/consumers/<group>/owners/<topic>/<partition>下注册。很明显,这种方案要依赖于zookeeper的帮助,而且每个consumer是单独做决定的,没有那种“大家属于一个组,要协商做事情”的精神。
基于这些潜在的弊端,0.9版本的kafka改进了coordinator的设计,提出了group coordinator——每个consumer group都会被分配一个这样的coordinator用于组管理和位移管理。这个group coordinator比原来承担了更多的责任,比如组成员管理、位移提交保护机制等。当新版本consumer group的第一个consumer启动的时候,它会和kafka server确定谁是它们组的coordinator。之后该group内的所有成员都会和该coordinator进行协调通信。显而易见,这种coordinator设计不再需要zookeeper了,性能上可以得到很大的提升。
6.4 如何确定Coordinator
那么consumer group如何确定自己的coordinator是谁呢? 简单来说分为两步
- 确定consumer group消费位移信息写入__consumer_offsets的哪个分区。具体计算公式:
__consumer_offsets_partitionId = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)
注意:groupMetadataTopicPartitionCount由参数offsets.topic.num.partitions指定,默认是50个分区。
- 该分区leader所在的broker就是被选定的coordinator
6.5 Rebalance generation
Rebalance generation它表示rebalance之后的新一届成员,主要是用于保护consumer group,防止无效offset提交。例如,上一届的consumer成员是无法提交位移到新一届的consumer group中。否则报ILLEGAL_GENERATION错误。每次group进行rebalance之后,generation号都会加1,表示group进入到了一个新的版本,如下图所示,Generation 1时group有3个成员,随后成员2退出组,coordinator触发rebalance,consumer group进入Generation 2,之后成员4加入,再次触发rebalance,group进入Generation 3。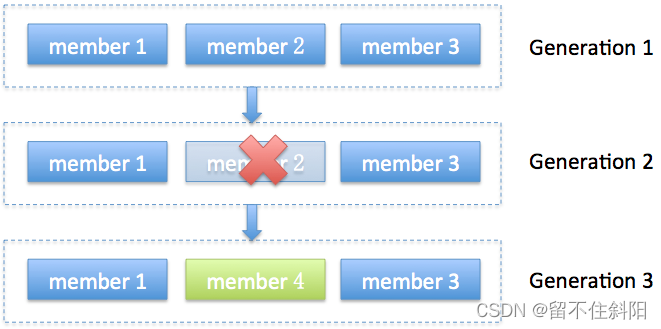
6.6 协议(protocol)
rebalance本质是一组协议。group与coordinator共同使用它来完成group的rebalance。目前kafka提供了5个协议处理与consumer group coordination相关的问题
- Heartbeat请求:consumer需要定期给coordinator发送心跳来表明自己还活着
- LeaveGroup请求:主动告诉coordinator我要离开consumer group
- SyncGroup请求:group leader把分配方案告诉组内所有成员
- JoinGroup请求:成员请求加入组
- DescribeGroup请求:显示组的所有信息,包括成员信息、协议名称、分配方案、订阅信息等。通常该请求是给管理员使用
Coordinator在rebalance的时候主要用到了前面4种请求。
6.7 Liveness
consumer如何向coordinator证明自己还活着?通过定时向coordinator发送Heartbeat请求。如果超过了设定的超时时间,那么coordinator就认为这个consumer已经挂了。一旦coordinator认为某个consumer挂了,那么它就会开启新一轮rebalance,并且在当前其他consumer的心跳response中添加“REBALANCE_IN_PROGRESS”,告诉其他consumer:不好意思各位,你们重新申请加入组吧!
6.8 Rebalance过程
rebalance的前提是coordinator已经确定了。总体而言,rebalance分为2步:Join和Sync
- Join:顾名思义就是加入组。所有成员都向coordinator发送JoinGroup请求,请求入组。一旦所有成员都发送了JoinGroup请求,coordinator会从中选择一个consumer担任leader的角色,并把组成员信息以及订阅信息发给leader——注意leader和coordinator不是一个概念。leader负责消费分配方案的制定。
- Sync:leader开始分配消费方案,即哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个consumer。这样组内的所有成员就都知道自己应该消费哪些分区了。
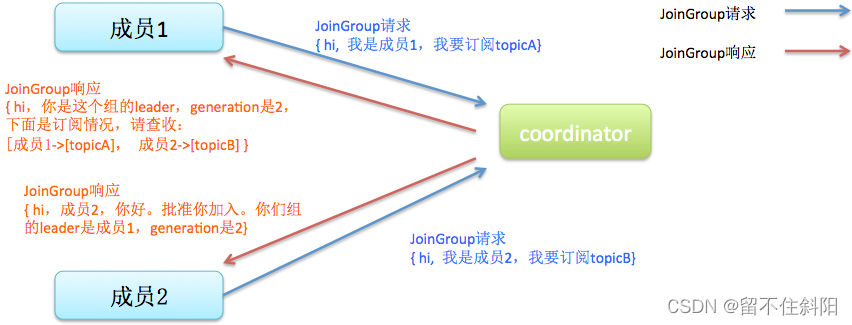
注意:在coordinator收集到所有成员请求前,它会把已收到请求放入一个叫purgatory(炼狱)的地方。
然后是分发分配方案的过程,即SyncGroup请求: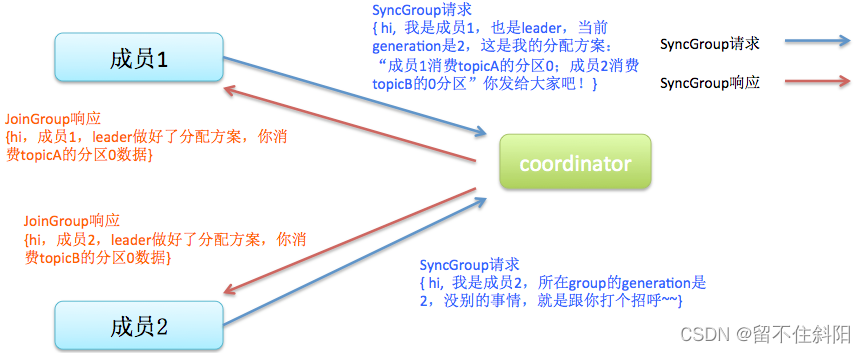
注意:consumer group的分区分配方案是在客户端执行的!Kafka将这个权利下放给客户端主要是因为这样做可以有更好的灵活性。比如这种机制下可以实现类似于Hadoop那样的机架感知(rack-aware)分配方案,即为consumer挑选同一个机架下的分区数据,减少网络传输的开销。可以覆盖consumer的参数partition.assignment.strategy来实现自己分配策略。
6.9 Consumer group状态机
consumer group也做了个状态机来表明组状态的流转。coordinator根据这个状态机会对consumer group做不同的处理,如下图所示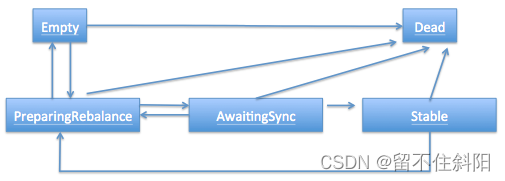
简单说明下图中的各个状态
- Dead:组内已经没有任何成员的最终状态,组的元数据也已经被coordinator移除了。这种状态响应各种请求都是一个response: UNKNOWN_MEMBER_ID
- Empty:组内无成员,但是位移信息还没有过期。这种状态只能响应JoinGroup请求
- PreparingRebalance:组准备开启新的rebalance,等待成员加入
- AwaitingSync:正在等待leader consumer将分配方案传给各个成员
- Stable:rebalance完成!可以开始消费了~
6.10 Rebalance场景剖析
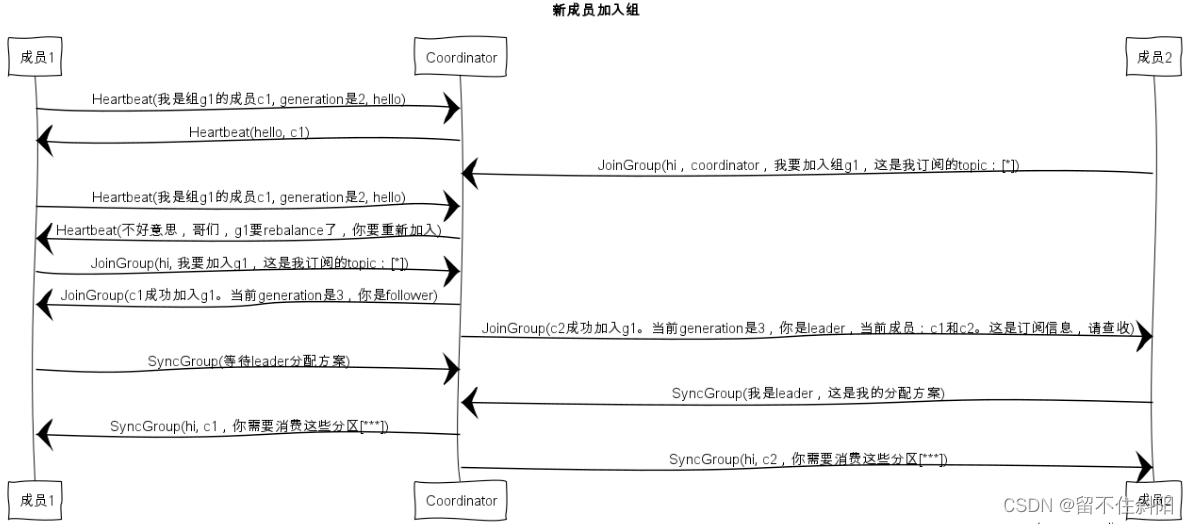
6.10.1 新成员入组
6.10.2 组成员崩溃
组成员崩溃和组成员主动离开是两个不同的场景。因为在崩溃时成员并不会主动地告知coordinator此事,coordinator有可能需要一个完整的session.timeout周期才能检测到这种崩溃,这必然会造成consumer的滞后。可以说离开组是主动地发起rebalance;而崩溃则是被动地发起rebalance。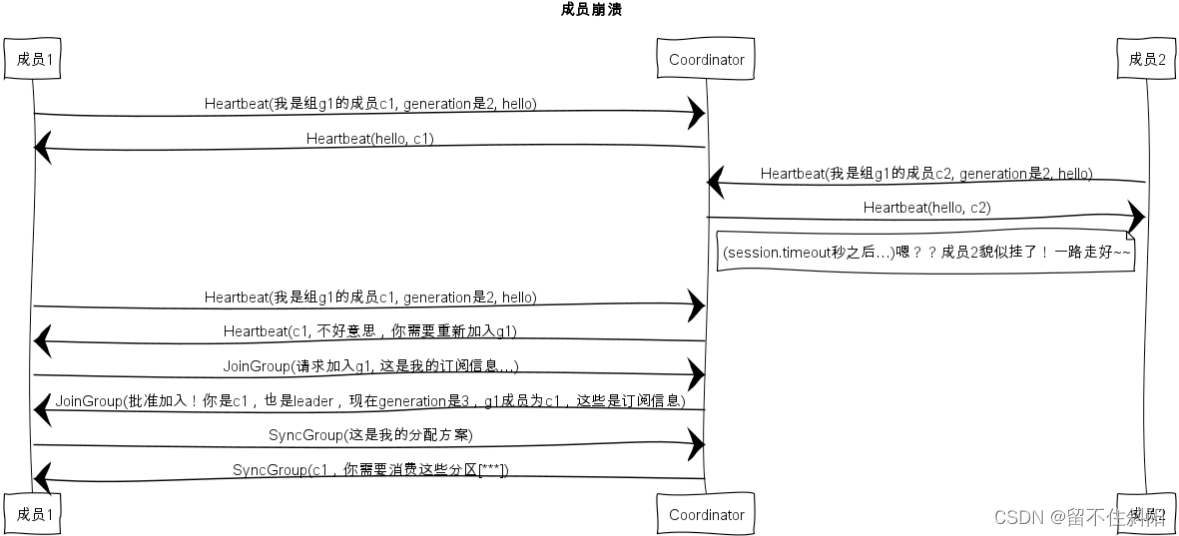
6.10.3组成员主动离组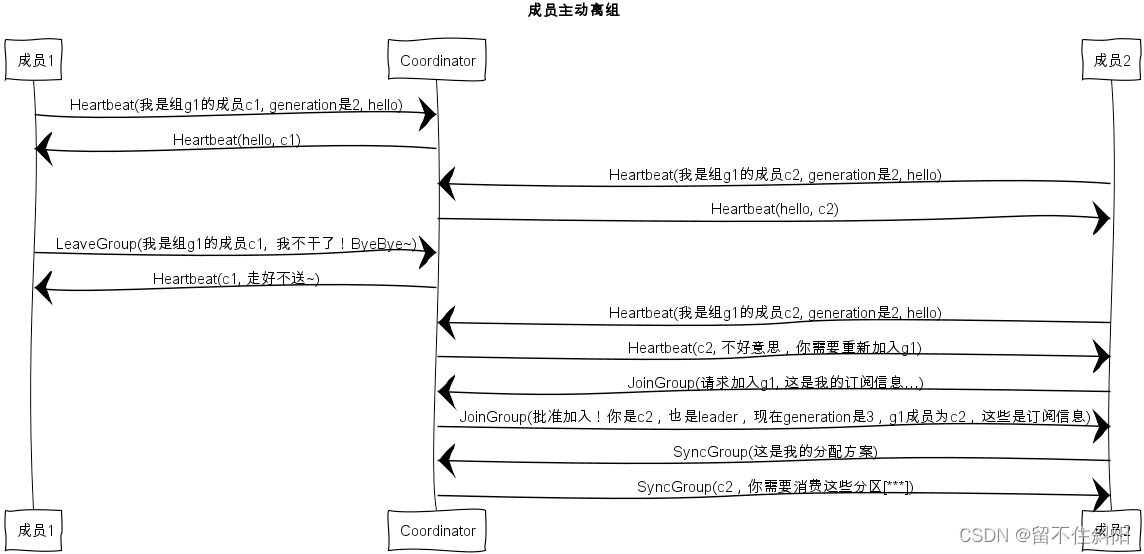
6.10.4提交位移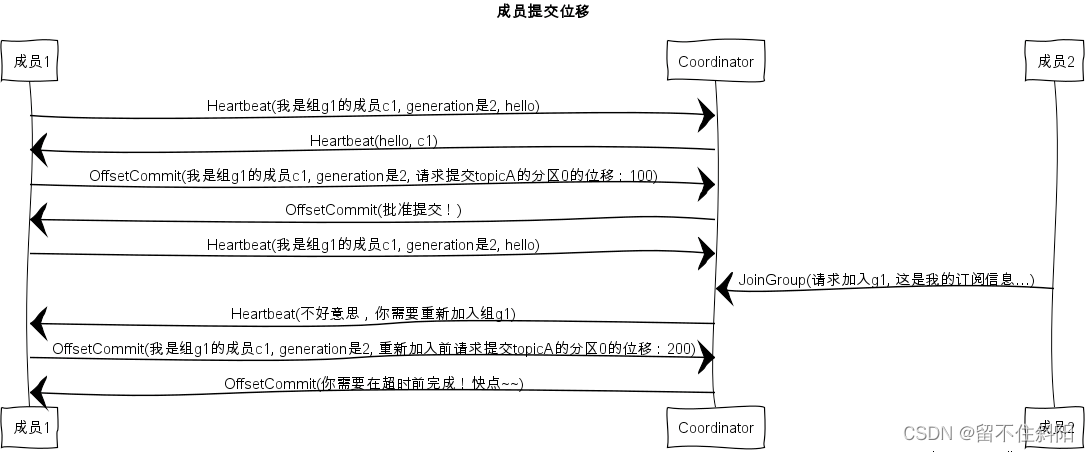
边栏推荐
- 顺丰科技智慧物流校园技术挑战赛(无t4)
- 指定格式时间,月份天数前补零
- js封装数组反转的方法--冯浩的博客
- 解决Intel12代酷睿CPU单线程调度问题(二)
- Pytorch extract skeleton (differentiable)
- Raspberry pie 4b64 bit system installation miniconda (it took a few days to finally solve it)
- Market trend report, technical innovation and market forecast of tabletop dishwashers in China
- Bidirectional linked list - all operations
- window11 conda安装pytorch过程中遇到的一些问题
- Browser print margin, default / borderless, full 1 page A4
猜你喜欢

Openwrt build Hello ipk
顺丰科技智慧物流校园技术挑战赛(无t4)
分享一个在树莓派运行dash应用的实例。
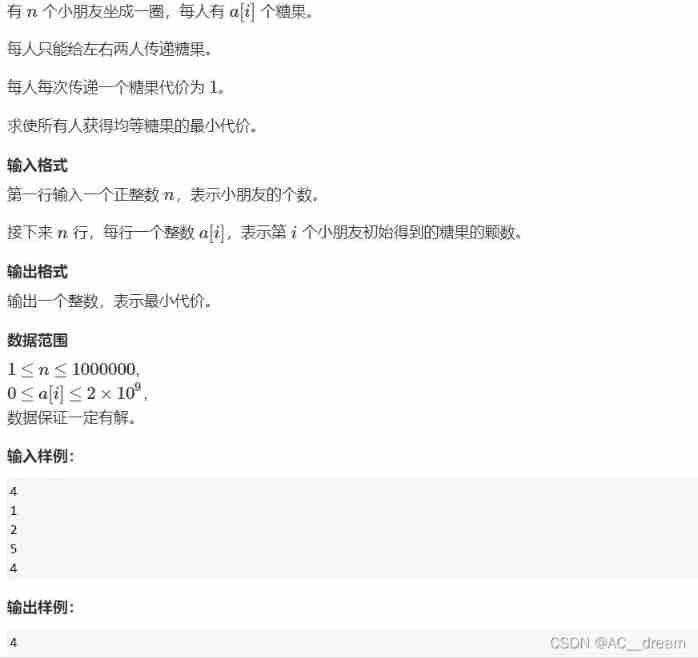
Candy delivery (Mathematics)
300th weekly match - leetcode
第 300 场周赛 - 力扣(LeetCode)

业务系统从Oracle迁移到openGauss数据库的简单记录

浏览器打印边距,默认/无边距,占满1页A4
QT simulates mouse events and realizes clicking, double clicking, moving and dragging

1529. Minimum number of suffix flips
随机推荐
Read and save zarr files
pytorch提取骨架(可微)
Generate random password / verification code
Market trend report, technical innovation and market forecast of China's desktop capacitance meter
Problem - 1646C. Factorials and Powers of Two - Codeforces
useEffect,函数组件挂载和卸载时触发
QT有关QCobobox控件的样式设置(圆角、下拉框,向上展开、可编辑、内部布局等)
Spark的RDD(弹性分布式数据集)返回大结果集
875. Leetcode, a banana lover
useEffect,函數組件掛載和卸載時觸發
Raspberry pie 4b64 bit system installation miniconda (it took a few days to finally solve it)
Codeforces Round #797 (Div. 3)无F
Bisphenol based CE Resin Industry Research Report - market status analysis and development prospect forecast
Summary of FTP function implemented by qnetworkaccessmanager
计算时间差
Codeforces Round #799 (Div. 4)A~H
Classic application of stack -- bracket matching problem
1689. Ten - the minimum number of binary numbers
Pull branch failed, fatal: 'origin/xxx' is not a commit and a branch 'xxx' cannot be created from it
Codeforces - 1526C1&&C2 - Potions