当前位置:网站首页>12 MySQL interview questions that you must chew through to enter Alibaba
12 MySQL interview questions that you must chew through to enter Alibaba
2022-07-05 14:49:00 【InfoQ】
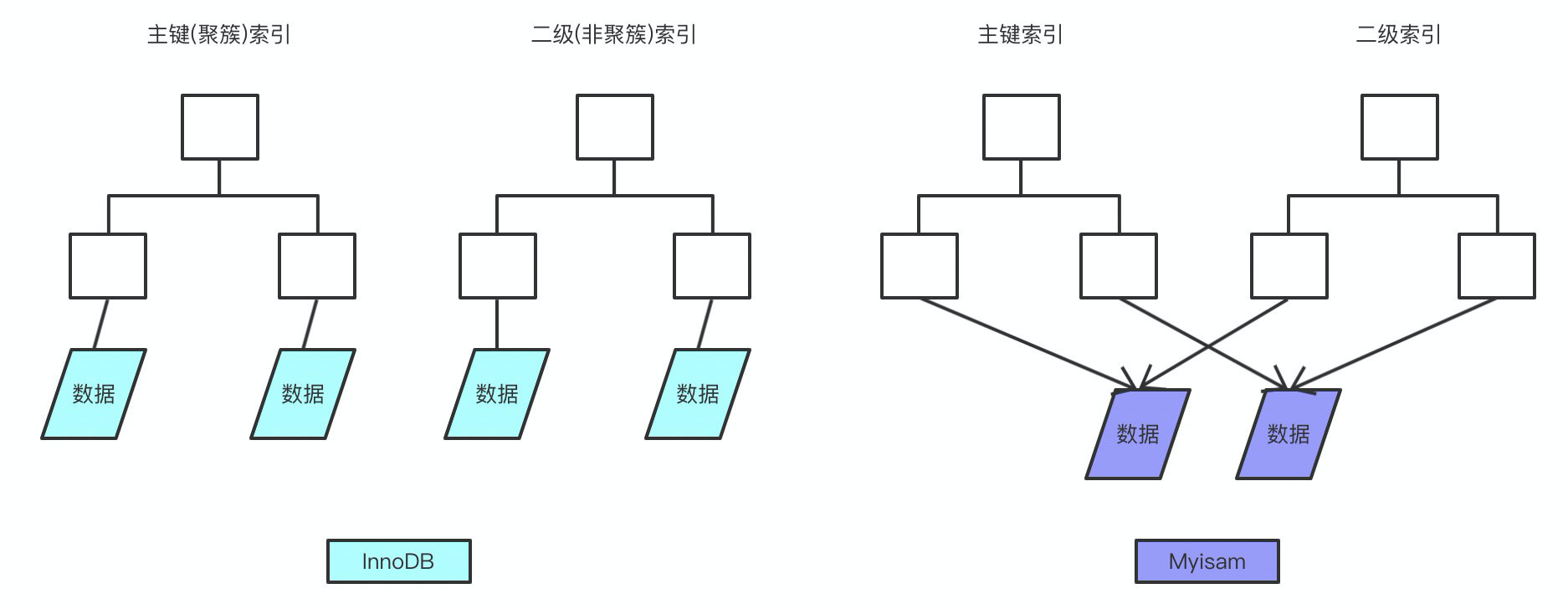
1. Can you say myisam and innodb The difference between ?
2. Under the said mysql What's the index of , What are clustered and nonclustered indexes ?
create table user(
id int(11) not null,
age int(11) not null,
primary key(id),
key(age)
);
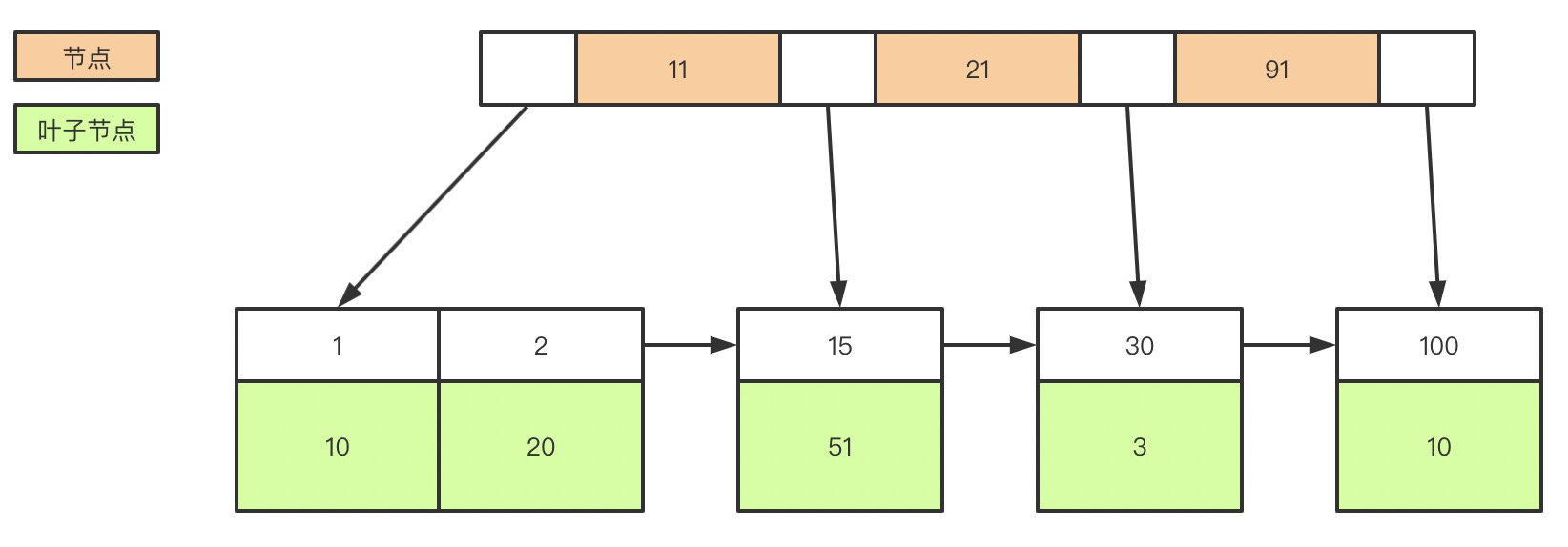
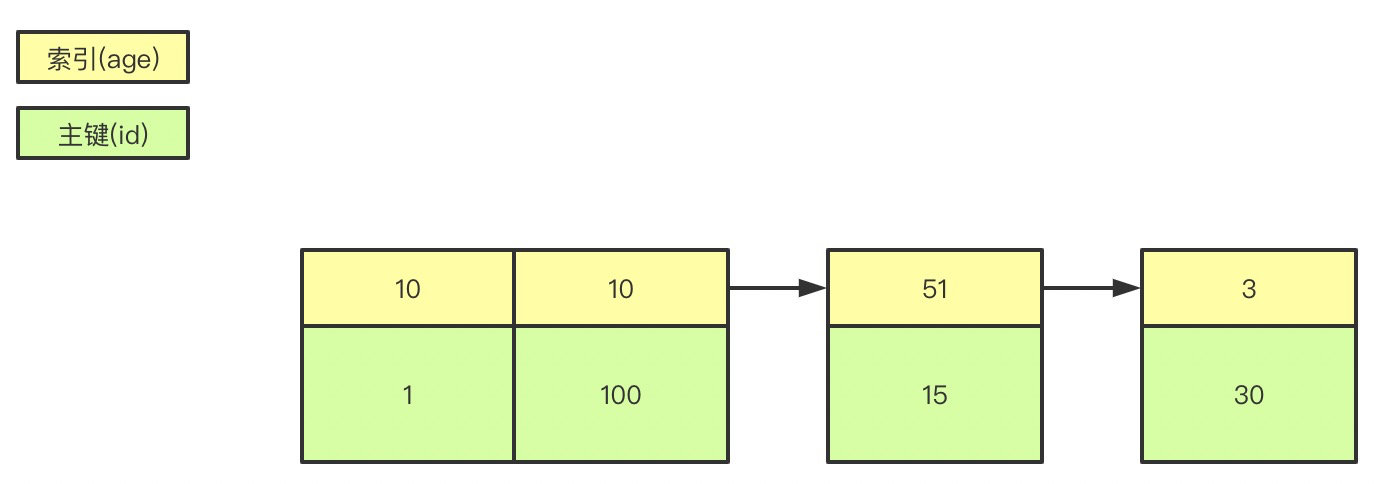
3. Do you know what is overlay index and return table ?
explain select * from user where age=1; // Of the query name Cannot get from index data
explain select id,age from user where age=1; // You can get it directly from the index
4. What are the types of locks
5. Can you talk about the basic characteristics and isolation level of transactions ?
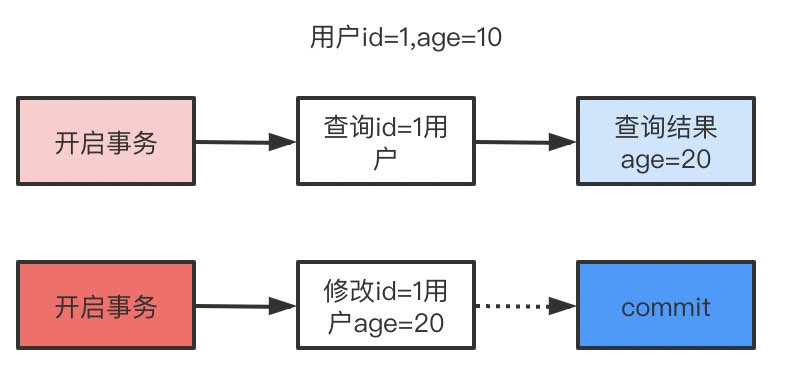
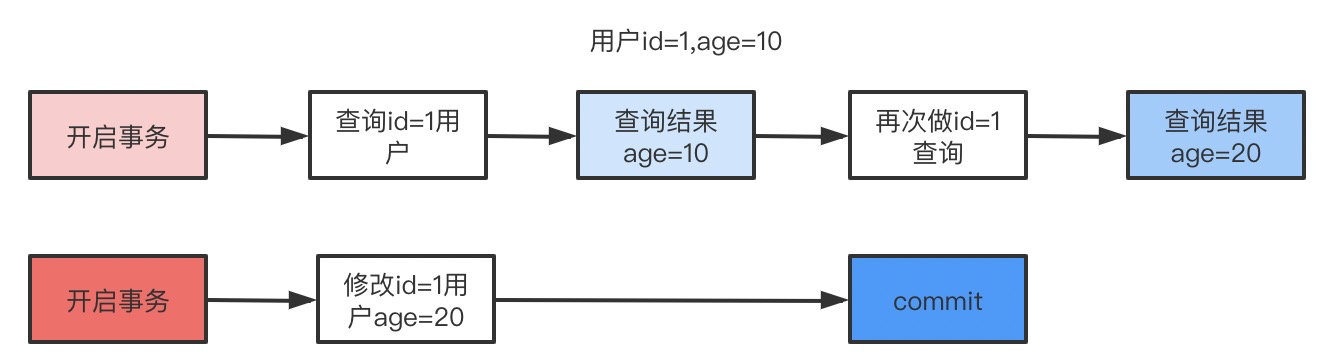
6. So what do you mean by phantom reading , What is? MVCC?

select * from user where id<=3;
update user set name=' Zhang Sansan ' where id=1;

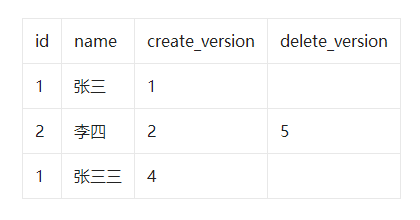
select * from user where id<=3 and create_version<=3 and (delete_version>3 or delete_version is null);
- Xiao Ming opens up business current_version=6 The query name is ' Wang Wu ' The record of , Discover that there is no .
- Xiaohong opens the business current_version=7 Insert a piece of data , So it turns out :

- Xiao Ming executes insert name ' Wang Wu ' The record of , Unique index conflict found , Can't insert , This is unreal reading .
7. that ACID By what guarantee ?
8. Do you know what a clearance lock is ?
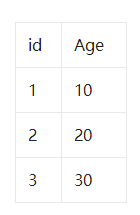
begin;
select * from user where age=20 for update;
begin;
insert into user(age) values(10); # success
insert into user(age) values(11); # Failure
insert into user(age) values(20); # Failure
insert into user(age) values(21); # Failure
insert into user(age) values(30); # Failure
(negative infinity,10],(10,20],(20,30],(30,positive infinity)
9. After the sub table ID How to guarantee uniqueness ?
- Set the step size , such as 1-1024 Let's set up a table 1024 The basic step size of , In this way, the primary keys will not conflict when they fall into different tables .
- Distributed ID, Realize a set of distributed ID Generate algorithms or use open source ones like snowflake
- After table splitting, the primary key is not used as the query basis , Instead, a field is added to each form as a unique primary key , For example, the order number is unique , No matter which table it ends up in, it is based on the order number , It's the same with updates .
10. What's the magnitude of your data ? How to do sub database and sub table ?

11. After the table is divided, it is not sharding_key How to handle the query of ?
- You can make one mapping surface , For example, what should businesses do when they want to query the order list ? No user_id You can't scan the whole table if you want to inquire ? So we can make a mapping table , Keep the relationship between the merchant and the user , When querying, first query the user list through the merchant , Re pass user_id Go to query .
- Wide watch , generally speaking , The real-time data requirement of the merchant is not very high , For example, to query the order list , You can synchronize the order table to offline ( real time ) Several positions , Then make a wide table based on the data warehouse , Based on other things like es Provide inquiry service .
- If the amount of data is not large , For example, some queries in the background , You can also scan the table through multithreading , And then aggregate the results to do . Or asynchronous form is OK .
List<Callable<List<User>>> taskList = Lists.newArrayList();
for (int shardingIndex = 0; shardingIndex < 1024; shardingIndex++) {
taskList.add(() -> (userMapper.getProcessingAccountList(shardingIndex)));
}
List<ThirdAccountInfo> list = null;
try {
list = taskExecutor.executeTask(taskList);
} catch (Exception e) {
//do something
}
public class TaskExecutor {
public <T> List<T> executeTask(Collection<? extends Callable<T>> tasks) throws Exception {
List<T> result = Lists.newArrayList();
List<Future<T>> futures = ExecutorUtil.invokeAll(tasks);
for (Future<T> future : futures) {
result.add(future.get());
}
return result;
}
}
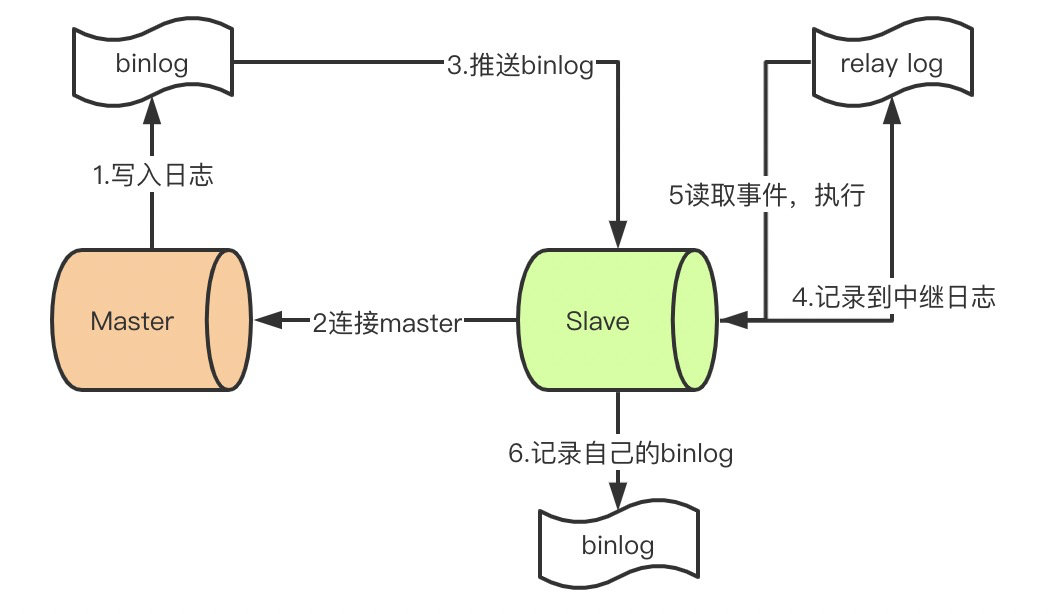
12. say something mysql Master slave synchronization how to do it ?
- master After committing the transaction , write in binlog
- slave Connect to master, obtain binlog
- master establish dump Threads , push binglog To slave
- slave Start a IO Thread reads synchronized master Of binlog, It was recorded that relay log In the relay log
- slave Open one more sql Thread reads relay log Events and slave perform , Complete synchronization
- slave Record your own binglog
13. How to solve the delay of master-slave ?
- For specific business scenarios , Read and write requests are forced to go to the main library
- Read request from library , If there is no data , Go to the main database for secondary query
边栏推荐
- Chow Tai Fook fulfills the "centenary commitment" and sincerely serves to promote green environmental protection
- Total amount analysis accounting method and potential method - allocation analysis
- Microframe technology won the "cloud tripod Award" at the global Cloud Computing Conference!
- 通过npm 或者 yarn安装依赖时 报错 出现乱码解决方式
- webRTC SDP mslabel lable
- World Environment Day | Chow Tai Fook serves wholeheartedly to promote carbon reduction and environmental protection
- I want to inquire about how to ensure data consistency when a MySQL transaction updates multiple tables?
- Photoshop插件-动作相关概念-非加载执行动作文件中动作-PS插件开发
- 申请代码签名证书时如何选择合适的证书品牌?
- I collect multiple Oracle tables at the same time. After collecting for a while, I will report that Oracle's OGA memory is exceeded. Have you encountered it?
猜你喜欢
Talking about how dataset and dataloader call when loading data__ getitem__ () function
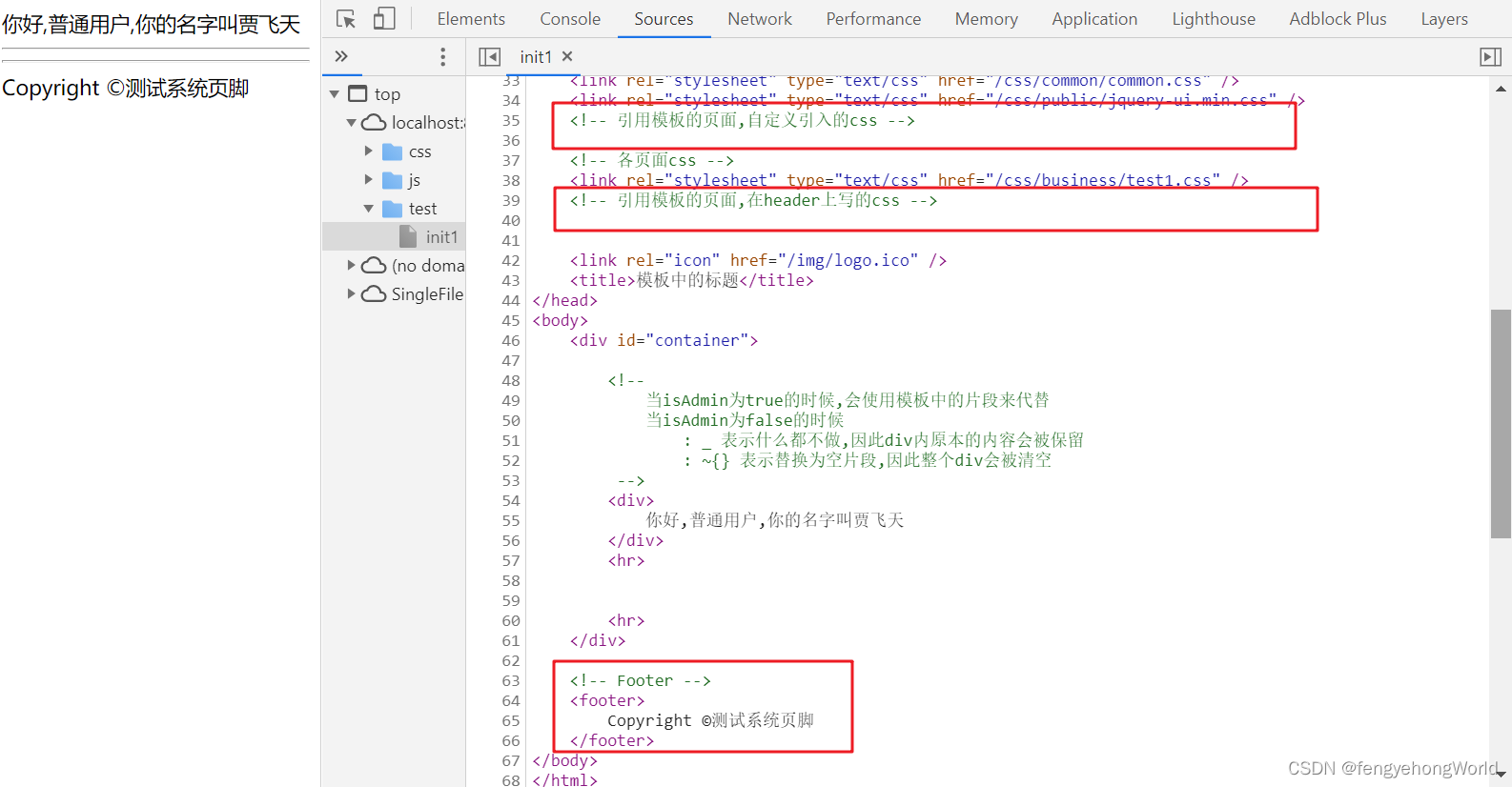
Thymeleaf 模板的创建与使用

【NVMe2.0b 14-9】NVMe SR-IOV
【leetcode周赛总结】LeetCode第 81 场双周赛(6.25)
Photoshop plug-in action related concepts actionlist actiondescriptor actionlist action execution load call delete PS plug-in development

Run faster with go: use golang to serve machine learning
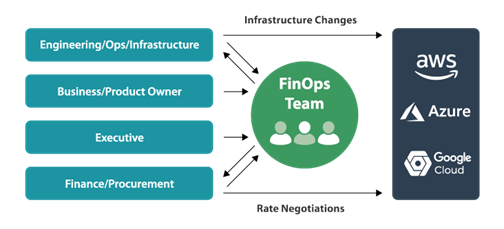
How can non-technical departments participate in Devops?
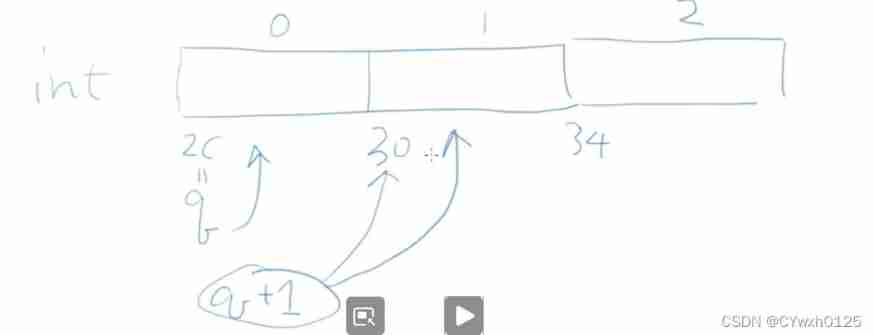
Pointer operation - C language
安装配置Jenkins
浅谈Dataset和Dataloader在加载数据时如何调用到__getitem__()函数
随机推荐
Install and configure Jenkins
Drive brushless DC motor based on Ti drv10970
easyOCR 字符識別
Under the crisis of enterprise development, is digital transformation the future savior of enterprises
Niuke: intercepting missiles
TS所有dom元素的类型声明
【C 题集】of Ⅷ
webRTC SDP mslabel lable
Structure - C language
anaconda使用中科大源
Catch all asynchronous artifact completable future
我想咨询一下,mysql一个事务对于多张表的更新,怎么保证数据一致性的?
Opengauss database source code analysis series articles -- detailed explanation of dense equivalent query technology (Part 2)
Handwriting promise and async await
CPU设计相关笔记
Fonctions communes de thymeleaf
PostgreSQL 13 installation
Solution of commercial supply chain collaboration platform in household appliance industry: lean supply chain system management, boosting enterprise intelligent manufacturing upgrading
webRTC SDP mslabel lable
There is a powerful and good-looking language bird editor, which is better than typora and developed by Alibaba