当前位置:网站首页>Volcano resource reservation feature
Volcano resource reservation feature
2022-07-05 06:44:00 【Dream of finding flowers~~】
List of articles
Volcano It's based on Kubernetes Cloud native batch computing platform , It's also CNCF The first batch computing project of .

Volcano It is mainly used for AI、 big data 、 gene 、 Rendering and many other high-performance computing scenarios , It has good support for the mainstream general computing framework . It provides high-performance computing task scheduling , Heterogeneous device management , Ability of task runtime management . This article will analyze in depth Volcano One of the important characteristics —— Reserve resources .
official github Address : https://github.com/volcano-sh/volcano
brief introduction
Reserve resources (Reservation) It is a common requirement of batch processing system , It's also fair scheduling (Fair Scheduling) A supplement to . From different dimensions , Resource reservation can be divided into preemptive reservation and non preemptive reservation 、 Job resource reservation and queue resource reservation 、 Immediate reservation and predictive reservation, etc .
since v1.1.0 Start ,Volcano Start iterating to support resource reservation features . According to the community Roadmap,v1.1.0( The published ) Give priority to supporting job resource reservation ,v1.2.0 It will support specifying queue resource reservation .
This feature v1.2 Version has been deprecated since .

Scene analysis
in application , There are two common scenarios :
(1) In the case of insufficient cluster resources , Suppose a job is in the state of being scheduled A and B,A The number of resource applications is less than B or A Priority over B. Based on the default scheduling policy ,A Will take precedence over B To schedule . In the worst case , If jobs with high priority or less resources are added to the waiting queue ,B Will be hungry for a long time and wait forever .
(2) In the case of insufficient cluster resources , Suppose there are jobs to be scheduled A and B.A Lower in priority B But the number of resource applications is less than B. Under the core scheduling strategy based on cluster throughput and resource utilization ,A Will be scheduled first . In the worst case ,B Will continue to starve .
The root cause of the above two scenarios is the lack of a fair scheduling mechanism : To ensure that the jobs in the state of starvation for a long time are scheduled first after reaching a critical condition . There are many reasons for persistent hunger , Including resource applications can not be met for a long time 、 The priority continues to be low 、 The frequency of preemption is too high 、 Affinity cannot be satisfied (v1.1.0 This scenario is not supported ) etc. , It is most common that the amount of resource application cannot be met .
Feature design
In order to ensure that jobs in a long-term blocking state can have fair scheduling opportunities , Two main problems need to be addressed :
- How to identify the target job ?
- How to reserve resources for target jobs ?
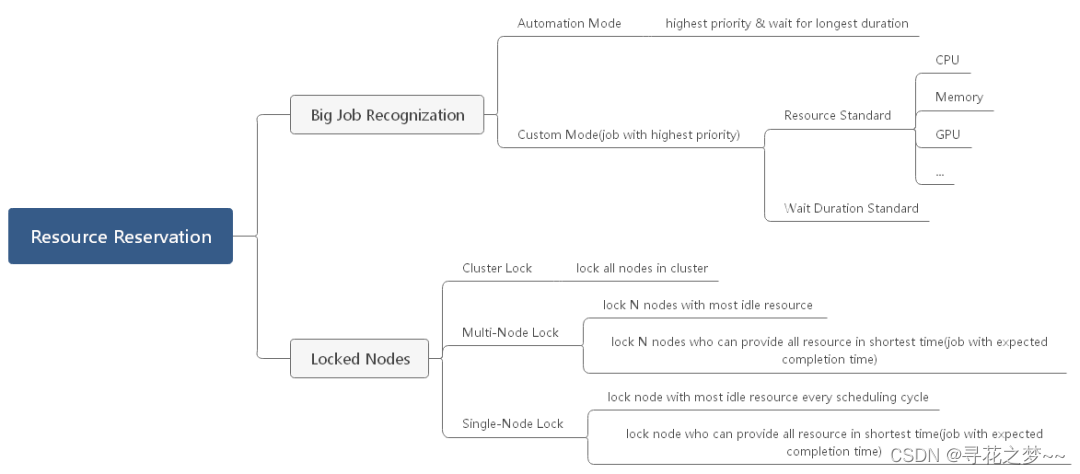
Target job identification
- Working conditions
The selection of operation conditions can be based on the waiting time 、 Single dimension or combination of multiple dimensions such as resource application amount . Comprehensive consideration ,v1.1.0 The implementation version selects the job with the highest priority and the longest waiting time as the target job . This not only ensures that urgent tasks are scheduled first , Considering the length of waiting time, the jobs with more resource requirements are selected by default . - Number of assignments
Objective to , There is usually more than one job that meets the criteria , Resources can be reserved for a target job group or a single target job . Considering that resource reservation will inevitably affect the performance of scheduler in terms of throughput and delay ,v1.1.0 A single target operation is adopted . - Recognition mode
There are two ways to identify : Custom configuration and automatic identification .v1.1.0 For the time being, only automatic recognition is supported , In other words, the scheduler automatically identifies the target jobs that meet the conditions and quantity in each scheduling cycle , And reserve resources for it . Subsequent versions will be considered in the global and Queue Granularity supports custom configuration .
Resource reservation algorithm
Resource reservation algorithm is the core of the whole feature .v1.1.0 The node group locking method is used to reserve resources for the target job , That is, select a group of nodes that meet some constraints to be included in the node group , The nodes in the node group will no longer accept new job delivery from the time of inclusion , The sum of node specifications meets the requirements of target operation . It's important to note that , The target jobs will be able to be scheduled throughout the cluster , Non target jobs can only be scheduled using nodes outside the node group .
- Node selection
In the feature design phase , The community has considered the following node selection algorithms : Specification first 、 Spare time first .
【 Specification first 】 It means that all nodes in the cluster follow the main specifications ( Target assignment request resource specification ) Sort in descending order , Before selection N Nodes are included in the node group , this N The total amount of resources of each node meets the application amount . The advantage of this method is that it is easy to realize 、 Minimize the number of locked nodes 、 Scheduling friendly to target jobs ( The total amount of resources locked in this way is often larger than the total amount of applications , And in the work each Pod Easy to aggregate and schedule on locked nodes , advantageous to Pod And so on ); The disadvantage is that the probability of locking the total amount of resources is not the optimal solution 、 Comprehensive scheduling performance loss ( throughput 、 Scheduling time )、 It is easy to produce large resource fragments .v1.1.0 This algorithm is used in the implementation of .
【 Spare time first 】 It refers to all nodes in the cluster according to the main resource type ( Target job request resource type ) The amount of idle resources is sorted in descending order , Before selection N Nodes are included in the node group , this N The total amount of resources of each node meets the application amount . The advantage of this method is that it has a high probability of releasing the total resources that meet the requirements as soon as possible ; The disadvantage is that the node group is not the optimal solution due to the dynamic distribution of idle resources , The stability of the solution is poor .
- Number of nodes
In order to minimize the impact of lock operation on the overall performance of the scheduler , On the premise of meeting the amount of reserved resources , No matter which node selection algorithm is used , Ensure that the number of selected nodes is at least .
- Lock mode
There are two core considerations in the way of locking : Number of parallel locks 、 Lock node has load handling means .
There are three options for the number of parallel locks : Single node locking 、 Multi node locking 、 Cluster locking .
【 Single node locking 】 In each scheduling cycle, a node that meets the requirements is selected to be included in the node group based on the current cluster resource distribution . This method can minimize the impact of resource distribution fluctuation on the stability of the solution , The disadvantage is that it takes more scheduling cycles to complete the locking process .v1.1.0 This is the way to realize .
And so on ,
【 Multi node locking 】 It means to select... In each scheduling cycle X(X>1) A node that meets the conditions is locked . This method can make up for the problem of long locking time introduced by single node locking to a certain extent , The disadvantage is that X It's not easy to find the optimal value , High implementation complexity .
【 Cluster locking 】 Lock all nodes in the cluster at one time , Until the target job is scheduled . It's the easiest way to do that , The target job has the shortest waiting time , Very suitable for resource reservation of super large target jobs .
【 Lock the node 】 There are two ways to deal with the existing load : Preemptive reservation 、 Non preemptive reservation . seeing the name of a thing one thinks of its function , Preemptive reservation will force the expulsion of the existing load on the locked node . This way can ensure the fastest release of the required amount of resource applications , But it will have a significant impact on existing businesses , Therefore, it is only applicable to resource reservation for urgent tasks . Non preemptive reservation will not be processed after the node is locked , Waiting for the load running on it to end itself .v1.1.0 Non preemptive reservation is adopted .
Best practices
be based on v1.1.0 The implementation of the , At present, the community only supports automatic identification and resource reservation of target jobs . So , New introduction 2 individual action and 1 individual plugin.elect action Used to select the target job ;reserve action Used to perform resource reservation actions ;reservation plugin The specific target selection and resource reservation logic are realized in .
To turn on the resource reservation feature , Will be more than action and plugin Configuration to volcano In the configuration file .
Recommended configuration example :
actions: "enqueue, elect, allocate, backfill, reserve"
tiers:
- plugins:
- name: priority
- name: gang
- name: conformance
- name: reservation
- plugins:
- name: drf
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
When you configure yourself , Please pay attention to the following :
elect action Must be configured in enqueue action and allocate action Between
reserve action Must be configured in allocate action after
Because of the identification of the target job 、 selection 、 Resource reservation is done automatically , The whole process is completely transparent on the user side , It can be done by scheduler Log view to the whole process .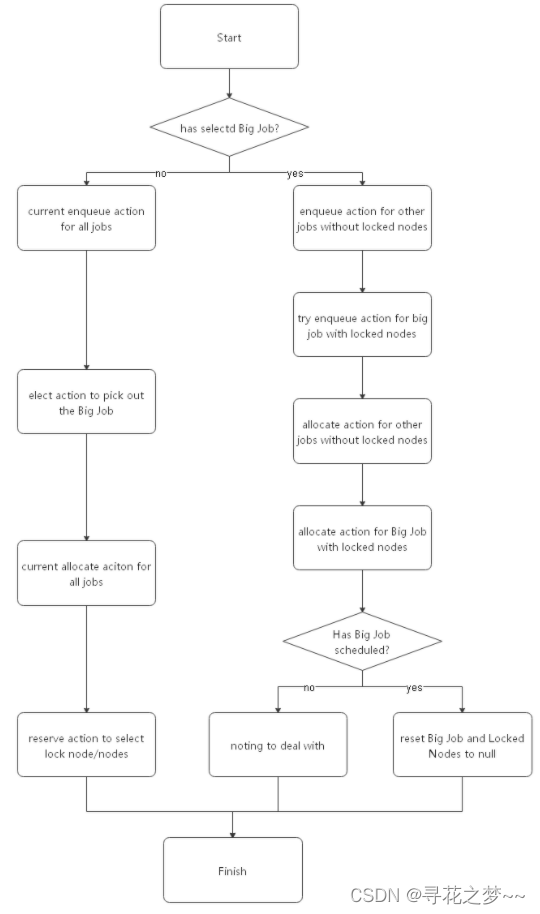
Sample production configuration attached :
actions: "enqueue, reserve, allocate, backfill, preempt"
tiers:
- plugins:
- name: reserveresource
arguments:
reserve.cpu: 1
reserve.memory: 2Gi
- plugins:
- name: priority
- name: gang
- name: conformance
- plugins:
- name: predicates
- name: nodeorder
arguments:
nodeaffinity.weight: 20
podaffinity.weight: 20
bizaffinity.weight: 100
resourcefit.weight: 20
leastrequested.weight: 0
balancedresource.weight: 1
imagelocality.weight: 1
similaraffinity.weight: 1
- name: preemptnodeorder
- name: binpack
arguments:
binpack.weight: 10
binpack.cpu: 1
binpack.memory: 1
binpack.resources: nvidia.com/gpu,tencent.com/vcuda-core
binpack.resources.nvidia.com/gpu: 5
binpack.resources.tencent.com/vcuda-core: 5
Reference material :https://mp.weixin.qq.com/s/_KYdmJq_qpuaYx7ZwJ3Z2Q
边栏推荐
猜你喜欢

5. Oracle tablespace
Skywalking全部
'mongoexport 'is not an internal or external command, nor is it a runnable program or batch file.

求组合数 AcWing 887. 求组合数 III
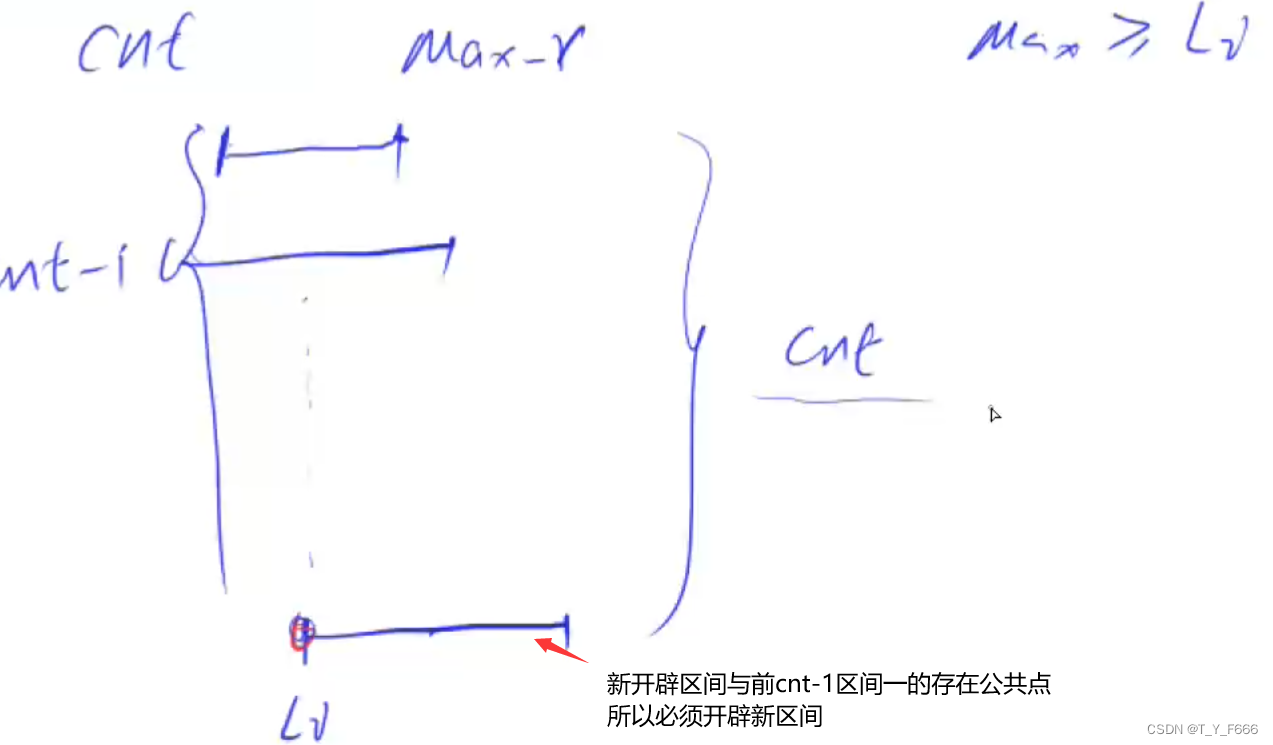
Interval problem acwing 906 Interval grouping
5.Oracle-錶空間
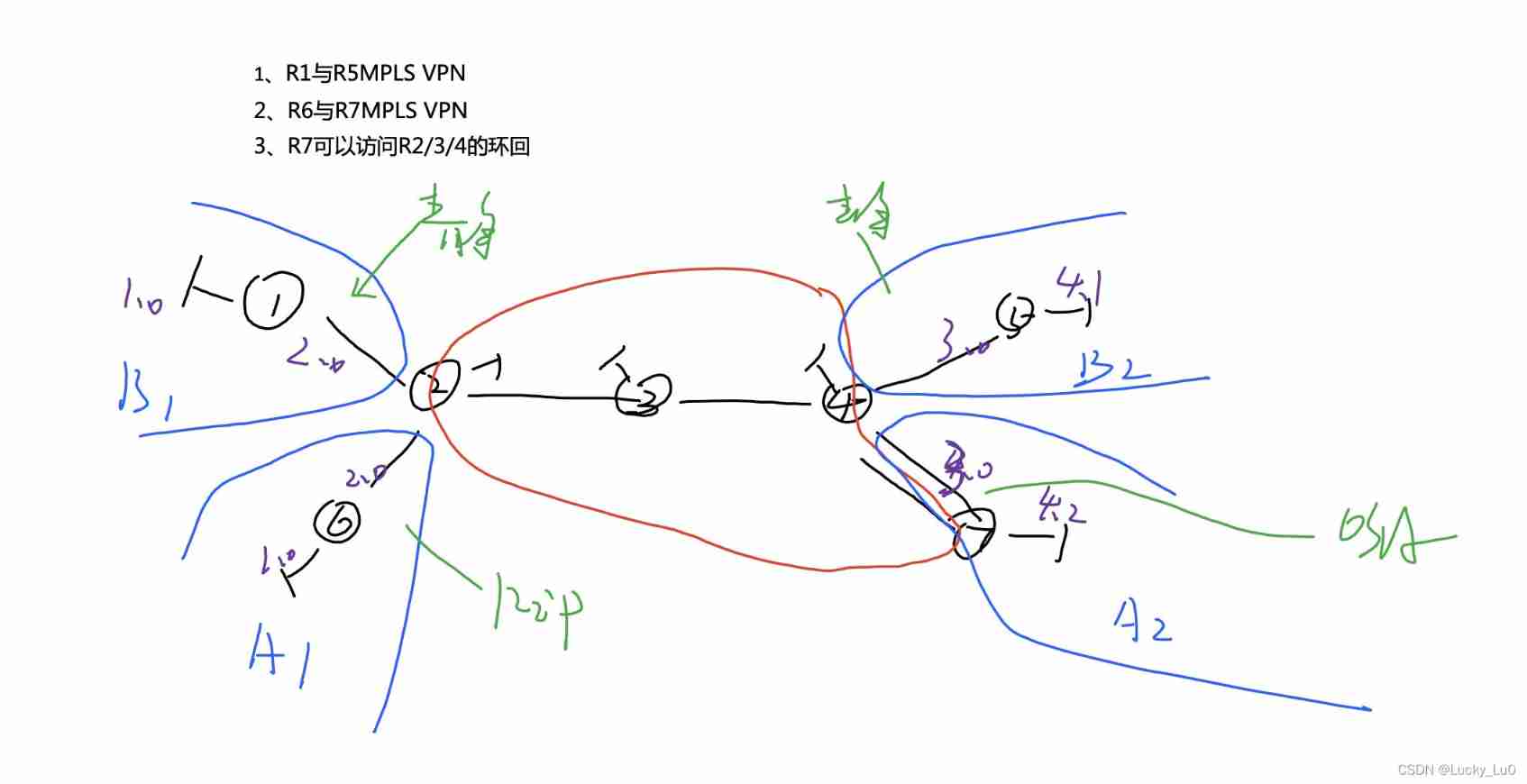
MPLS experiment
Rehabilitation type force deduction brush question notes D2
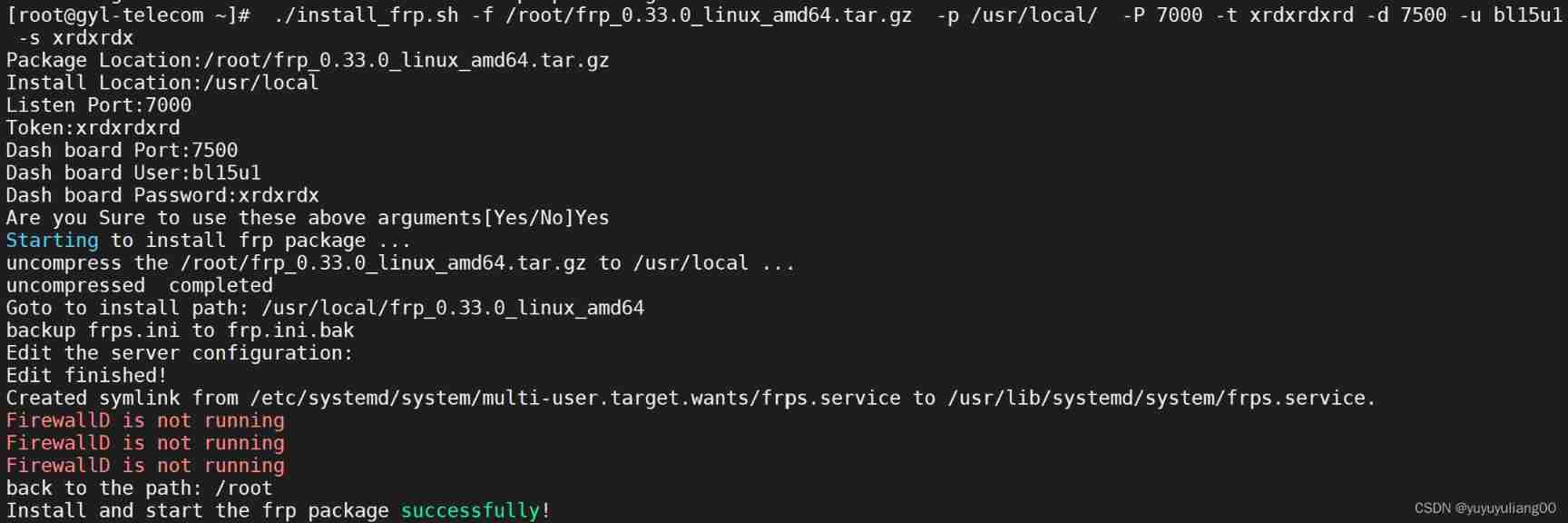
Bash exercise 17 writing scripts to install the server side of FRP reverse proxy software
1.手动创建Oracle数据库
随机推荐
Using handler in a new thread
Vant Weapp SwipeCell设置多个按钮
Dataframe (1): introduction and creation of dataframe
Page type
Positive height system
.net core踩坑实践
AE tutorial - path growth animation
求组合数 AcWing 888. 求组合数 IV
[learning] database: several cases of index failure
5.Oracle-錶空間
Getting started with typescript
FFmpeg build下载(包含old version)
Redis-02.Redis命令
The route of wechat applet jumps again without triggering onload
Client use of Argo CD installation
Rehabilitation type force deduction brush question notes D1
3.Oracle-控制文件的管理
Integer to 8-bit binary explanation (including positive and negative numbers) scope of application -127~+127
Time is fast, please do more meaningful things
how to understand the “model independent.“