当前位置:网站首页>Paper reading report
Paper reading report
2022-07-05 06:23:00 【mentalps】
0 2022/6/23-2022/6/25
1. FLAME: Taming Backdoors in Federated Learning
1.1 The contribution of this article
- We proposed FLAME, It's a way of targeting FL Defense framework of middle and back door attack , It can eliminate backdoors without affecting the benign performance of the aggregation model . Contrary to the early backdoor defense ,FLAME Applicable to general opponent model , That is, it does not rely on the powerful assumption of the opponent's attack strategy , Nor does it depend on the underlying data distribution of benign and hostile data sets .
- We show that , The required Gaussian noise can be fundamentally reduced by the following methods :a) Apply our clustering method to delete potential malicious model updates ,b) Cut the weight of the local model to an appropriate level , To limit single ( Especially malice ) The impact of models on aggregation models .
- We inject noise ( suffer DP inspire ) The required amount of Gaussian noise provides a proof of the noise boundary , To eliminate the contribution of the back door .
- We have extensively evaluated the defense framework of real-world data sets from three very different application areas . We show that ,FLAME Reduce the amount of noise required , Therefore, the benign performance of the aggregation model will not be significantly reduced , And direct injection is based on DP Compared with the most advanced defense against noise , It has important advantages .
1.2 Problem setting and goals
Rear door feature description :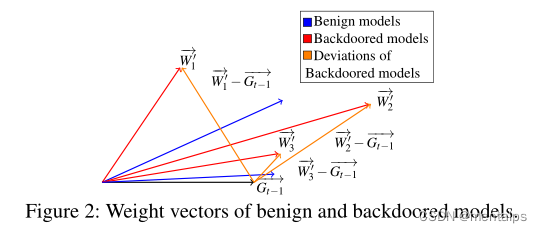
Benign models: Benign model ;
Backdoored models: Backdoor attack model ;
Deviations of Backdoored models: The deviation of the back door model ;
G t − 1 G_{t-1} Gt−1: The deviation between the local model and the global model in the last round ;
W 1 , , W 2 , , W 3 , , W_{1}^{,},W_{2}^{,},W_{3}^{,}, W1,,W2,,W3,,: They represent three different backdoor attacks ;
Defensive target :
stay FL In the environment , General defense that can effectively mitigate backdoor attacks needs to achieve the following goals :(i) effectiveness : In order to prevent the opponent from achieving his attack target , The influence of backdoor model update must be eliminated , So that the aggregated global model does not show backdoor behavior .(ii) performance : The benign performance of the global model must be maintained , To maintain its effectiveness .(iii) Independent of data distribution and attack strategy : The defense method must be applicable to the general opponent model , That is, it is not required to know the backdoor attack method in advance , Or make assumptions about the specific data distribution of local clients , for example , The data is iid Or not iid.
1.2 FLAME Overview and design
motivation :
Early work used the difference privacy heuristic noise elimination backdoor of aggregation model . They identify a sufficient amount of noise to be used empirically . However , stay FL Setting up , This is a challenge , Because it is usually impossible to assume that aggregators can access training data , Especially toxic data sets . therefore , A general method is needed to determine how much noise is sufficient to effectively remove the back door . On the other hand , The more noise is injected into the model , The greater the impact on its benign performance .
FLAME summary :
FLAME Estimated at FL The noise level required for the removal of the rear door in the environment , There is no need for extensive empirical evaluation , There is no need to obtain training data . Besides , In order to effectively limit the amount of noise required ,FLAME A new method based on clustering is used to identify and delete the update of opponent model with great influence , And the dynamic weight clipping method is applied to limit the influence of the model expanded by the opponent to improve performance . Such as §3 Described , We cannot guarantee that all backdoor models can be detected , Because the opponent can completely control the angle and amplitude deviation , Make the model arbitrary and difficult to detect . therefore , Our clustering method aims to remove high attack impact ( The angle deviation is large ) Model of , Not all malicious models . chart 3 It explains the FLAME High level concept of : Filter 、 Clipping and noise . However , We emphasize , Each of these components needs to be applied very carefully , Because the naive combination of noise and clustering and clipping will lead to bad results , Because it's easy not to ease the back door and / Or worsen the benign performance of the model .
FLAME Design :
FLAME The paired cosine distance is used to measure the angular difference between all model updates , And Application HDBSCAN clustering algorithm . The advantage here is , Even if the opponent enlarges the model update to enhance its influence , Cosine distance will not be affected , Because this does not change the angle between update weight vectors . because HDBSCAN The algorithm clusters the model according to the density of cosine distance distribution , And dynamically determine the required number of clusters .
step :
1. Server acquisition n User model .
2. Calculation n n n Cosine similarity between two models .
3. Use dynamic clustering algorithm HDBSCAN Cluster the cosine similarity between two pairs , exceed 50 % The class of is benign update . Other classes are considered outliers , Remove it , Get the rest L L L A benign model .
4. Yes n n n Each of the models calculates the Euclidean distance from the current global model ( e 1 , e 2 , . . . , e n ) (e_{1},e_{2},...,e_{n}) (e1,e2,...,en), And let the value be S t S_{t} St.
5. For each round L L L A model screened by clustering algorithm , The dynamic adaptive clipping threshold is γ = S t / e l \gamma=S_{t}/e_{l} γ=St/el.
6. Calculate the trimmed local model W l = G t − 1 + ( W l − G t − 1 ) ∗ M I N ( 1 , γ ) W_{l}=G_{t-1}+(W_{l}-G_{t-1})*MIN(1,\gamma) Wl=Gt−1+(Wl−Gt−1)∗MIN(1,γ).
7. Give the same weight to the trimmed local model and aggregate to get the global model G t G_{t} Gt.
8. Based on the differences between local models ( distance ) Get the dynamic adaptive noise σ = λ ∗ S t \sigma=\lambda*S_{t} σ=λ∗St, Where the super parameter λ \lambda λ Is the noise level factor set according to experience .
9. Get the global model after noise G t = G t + N ( 0 , σ 2 ) G_{t}=G_{t}+N(0,\sigma^{2}) Gt=Gt+N(0,σ2).
0 2022/6/27
1 The Limitations of Federated Learning in Sybil Settings
The main idea:
1. For each client i i i, The server saves its historical update vector as H i = ∑ t Δ i , t H_{i}=\sum_{t}\Delta_{i,t} Hi=∑tΔi,t.
2. Look for indicative features .
3. Calculate the cosine similarity between two indicative features in the client history update c s i , j cs_{i,j} csi,j, And order v i v_{i} vi For the client i i i The maximum value of cosine similarity with all other clients .
4. After the cosine similarity between two is calculated , For each client i i i, If there is another client j j j Satisfy v j > v i v_{j}>v_{i} vj>vi , Then the client i i i Of c s i , j cs_{i,j} csi,j Amend to read c s i , j ∗ v i / v j cs_{i,j}*v_{i}/v_{j} csi,j∗vi/vj. By re measuring cosine similarity , It can further reduce the similarity between honest clients and malicious clients , The similarity between malicious clients and malicious clients is basically unchanged , Thus reducing false positives .
5. Calculate each client i i i Learning rate of a i = 1 − m a x j ( c s i ) a_{i}=1-max_{j}(cs_{i}) ai=1−maxj(csi) Is and divided by a i a_{i} ai Maximum of , Standardize and reduce it to 0 To 1 Between .
6. Learning rate for each client a i a_{i} ai, Use to 0.5 Centered logit function , Make close to 0 and 1 The learning rate becomes more divergent .
7. Multiply the final learning rate by the corresponding model update , Get the aggregated model update , And use it to update the global model
0 2022/7/1
1 Defending Against Backdoors in Federated Learning with Robust Learning Rate
The main idea:
- Server acquisition n n n Partial update of users .
- For each dimension j j j, Server pair n n n The number of models j j j Find the symbolic function with three parameters , Then sum the operation results of the symbolic function , The o ∑ k = s g n ( Δ j k ) \sum_{k}=sgn(\Delta_{j}^{k}) ∑k=sgn(Δjk).
- Set a super parameter of learning threshold θ \theta θ, if ∣ ∑ k s g n ( Δ j k ) ∣ |\sum_{k}sgn(\Delta_{j}^{k})| ∣∑ksgn(Δjk)∣, be η j = − η \eta_{j}=-\eta ηj=−η.
- Select an aggregation function to aggregate local updates , The only difference is , The learning rate of each parameter is not fixed η \eta η, It's what we got before η j \eta_{j} ηj.
边栏推荐
- JS quickly converts JSON data into URL parameters
- Usage scenarios of golang context
- AE tutorial - path growth animation
- 4. Object mapping Mapster
- 中国剩余定理 AcWing 204. 表达整数的奇怪方式
- Leetcode backtracking method
- Liunx starts redis
- [2021]GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
- [wustctf2020] plain_ WP
- NotImplementedError: Cannot convert a symbolic Tensor (yolo_boxes_0/meshgrid/Size_1:0) to a numpy ar
猜你喜欢

MySQL advanced part 2: the use of indexes

5.Oracle-表空间
Sqlmap tutorial (II) practical skills I

阿里巴巴成立企业数智服务公司“瓴羊”,聚焦企业数字化增长
MySQL怎么运行的系列(八)14张图说明白MySQL事务原子性和undo日志原理
There are three kinds of SQL connections: internal connection, external connection and cross connection
Series of how MySQL works (VIII) 14 figures explain the atomicity of MySQL transactions and the principle of undo logging
7.Oracle-表结构
SQLMAP使用教程(一)

International Open Source firmware Foundation (osff) organization
随机推荐
[BMZCTF-pwn] ectf-2014 seddit
New title of module a of "PanYun Cup" secondary vocational network security skills competition
Nested method, calculation attribute is not applicable, use methods
Redis-01.初识Redis
Basic explanation of typescript
There are three kinds of SQL connections: internal connection, external connection and cross connection
【LeetCode】Day94-重塑矩阵
MySQL advanced part 2: optimizing SQL steps
Gauss Cancellation acwing 884. Solution d'un système d'équations Xor linéaires par élimination gaussienne
[learning] database: several cases of index failure
Redis publish subscribe command line implementation
Modnet matting model reproduction
AE tutorial - path growth animation
LeetCode 0108. Convert an ordered array into a binary search tree - the median of the array is the root, and the left and right of the median are the left and right subtrees respectively
What's wrong with this paragraph that doesn't work? (unresolved)
P3265 [jloi2015] equipment purchase
Data visualization chart summary (I)
Leetcode-6108: decrypt messages
Liunx starts redis
博弈论 AcWing 893. 集合-Nim游戏