当前位置:网站首页>2022-5-第四周日报
2022-5-第四周日报
2022-07-05 06:18:00 【mentalps】
0 2022/5/23
1 Provably Secure Federated Learning against Malicious Clients代码复现
1.1 aggregator.py
import numpy as np
class FedAvg:
def __init__(self, global_model, different_client_values, client_count):
global_weights = np.array(global_model.getWeights())
for i in range(len(different_client_values)):
global_weights -= different_client_values[i] / client_count
global_model.setWeights(global_weights)
1.2 model.py
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation,Flatten
from keras.models import model_from_json
import tensorflow as tf
class Model:
def __init__(self):
self.model = Sequential()
self.model.add(Flatten())
self.model.add(Dense(128, activation='relu'))
self.model.add(Dense(10, activation='softmax'))
self.model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
def saveModel(self, name):
model_json = self.model.to_json()
with open("model/model_%s.json" % name, "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
self.model.save_weights("model/model_%s.h5" % name)
print("Saved model to disk")
def loadModel(self, name):
json_file = open('model/model_%s.json' % name, 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights("model/model_%s.h5" % name)
print("Loaded model from disk")
loaded_model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
return loaded_model
def run(self, X, Y, load=True):
if (load):
self.model = self.loadModel('sever_model')
self.model.fit(X, Y, epochs=2)
def evaluate(self, X, Y, verbose=2):
return self.model.evaluate(X, Y, verbose=verbose)
def loss(self, X, Y):
return self.model.evaluate(X, Y)[0]
def predict(self, X):
return self.model.predict(X)
def getWeights(self):
return self.model.get_weights()
def setWeights(self, weight):
self.model.set_weights(weight)
1.3 data.py
from tensorflow.python.keras.datasets import cifar10, mnist, fashion_mnist
import numpy as np
def Mnist_data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 28 * 28) / 255
x_test = x_test.reshape(-1, 28 * 28) / 255
return x_train, y_train, x_test, y_test
def generate_client_data(num_clients=10):
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 28 * 28) / 255
x_test = x_test.reshape(-1, 28 * 28) / 255
data = list(zip(x_train, y_train))
size = len(data) // num_clients
shards = [data[i:i+size] for i in range(0, size * num_clients, size)]
return data, shards, x_test, y_test
def generate_malice_data(data):
x, y = zip(*data)
x = np.array(x)
y = np.array(y)
for i in range(len(y)):
if y[i] == 1:
y[i] = 2
return list(zip(x, y))
#
# if __name__ == '__main__':
# data, shards, x_test, y_test = generate_client_data(4)
# x_1, y_1 = zip(*shards[0])
#
# print(type(x_test))
1.4 main.py
import numpy as np
import data
import model
import aggregator
ClientNum = 5
EPOCH = 5
if __name__ == '__main__':
data1, shards, x_test, y_test = data.generate_client_data(ClientNum)
model_client = []
for i in range(ClientNum):
model_client.append(model.Model())
global_model = model.Model()
shards[0] = data.generate_malice_data(shards[0])
shards[1] = data.generate_malice_data(shards[1])
x_all = []
y_all = []
for i in range(ClientNum):
xx, yy = zip(*shards[i])
xx = np.array(xx)
yy = np.array(yy)
x_all.append(xx)
y_all.append(yy)
a_0 = np.argmax(global_model.predict(x_all[0][0:784]))
global_model.saveModel('sever_model')
for i in range(ClientNum):
np.argmax(model_client[i].predict(x_all[0][0:784]))
for i in range(EPOCH):
client_difference_value = []
for j in range(ClientNum):
model_client[j].setWeights(global_model.getWeights())
for j in range(ClientNum):
model_client[j].run(x_all[j], y_all[j])
for j in range(ClientNum):
client_difference_value.append(np.array(global_model.getWeights()) - np.array(model_client[j].getWeights()))
fedavg = aggregator.FedAvg(global_model, client_difference_value, 3)
global_model.saveModel('sever_model')
x = []
y = []
for i in range(len(x_test)):
if y_test[i] == 1:
x.append(x_test[i])
y.append(y_test[i])
test_loss, test_acc = global_model.evaluate(x_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)
0 2022/5/24
1 组会讨论
1.1 Provably Secure Federated Learning against Malicious Clients
- 加入了集成学习;
- 1000个客户端,20个被攻击;
- 从1000个客户端随机选择5个进行聚合,选择10次,就有10个这样的聚合模型;
- 预测:一个未知样本被这10个模型分别打标签,根据投票决定该样本的标签;
- 给每个预测样本一个安全等级;
- 通过变化被攻击客户端的数量,然后对同样的样本进行预测,得到样本被预测为不同标签值的概率,使得标签值反转的被攻击客户端的临界数量作为该样本的安全等级。
1.2 我们的想法
- 对100个客户端进行聚类,聚类个数作为超参数,假设聚了10类;
- 每一类有不同个数的客户端,客户端个数作为后面集成模型的权重;
- 10类训练出10个聚合模型;
- 每个虚拟中心都与上一次更新进行对比,如果超过某个阈值,则仍为这些客户端受到了攻击,将其抛弃。
- 预测一个未知样本的标签 = 权重 * 每个良性的聚合模型的预测结果。
0 2022/5/25
1 想法改进
1.计算所有客户端更新之间相似性,将相似性高于一定阈值的客户端聚合成一个模型;
2.每个模型包含的客户端个数作为后面集合时的权重;
3.同时取该模型更新中的中位数;
4.之后每一轮的聚合之前,都将更新与上一轮的更新中位数做比较,超过阈值则抛弃;
5.预测一个未知样本的标签 = 权重 * 每个聚合模型的预测结果。
2 对比方案
- Krum
- Trimmed mean
- Median
0 2022/5/26
1 krum
算法步骤:
- 服务器s把全局模型的参数 W W W分发给所有客户端;
- 每个客户端 c i c_{i} ci利用本地数据训练模型得到梯度 d i d_{i} di,然后发送给服务器;
- 服务器收到客户端的梯度后,两两计算梯度之间的距离 d i , j d_{i,j} di,j;
- 对于每个梯度 g i g_{i} gi,选择与他最近的 n − f − 1 n-f-1 n−f−1个距离,将其累加得到该梯度 d i d_{i} di的得分;
- 计算所有的梯度得分后,求出得分最小的梯度 g i ∗ g_{i^{*}} gi∗;
- 更新 W = W − l r ⋅ g i ∗ W=W-lr\sdot g_{i^{*}} W=W−lr⋅gi∗;
- 重复1-6,直到模型收敛。
2 Trimmed mean
算法步骤:
- 服务器s把全局模型的参数 W W W分发给所有客户端;
- 每个客户端 c i c_{i} ci利用本地数据训练模型得到梯度 W i W_{i} Wi,然后发送给服务器;
- 服务器收到客户端的参数后,开始聚合;
w j ′ = m β ( w j 1 , w j 2 , . . . , w j n ) . w_{j}^{'}=m_{\beta}(w_{j}^{1},w_{j}^{2},...,w_{j}^{n}). wj′=mβ(wj1,wj2,...,wjn). - 聚合后的权重为 W ′ = ( w 1 ′ , w 2 ′ , . . . , w p ′ ) W^{'}=(w_{1}^{'},w_{2}^{'},...,w_{p}^{'}) W′=(w1′,w2′,...,wp′),服务器把新的参数发送给客户端;
- 重复1-4,直到模型收敛。
3 Median
算法步骤:
- 服务器s把全局模型的参数 W W W分发给所有客户端;
- 每个客户端 c i c_{i} ci利用本地数据训练模型得到梯度 W i W_{i} Wi,然后发送给服务器;
- 服务器收到客户端的参数后,开始聚合;
w j ′ = m e d ( w j 1 , w j 2 , . . . , w j n ) . w_{j}^{'}=med(w_{j}^{1},w_{j}^{2},...,w_{j}^{n}). wj′=med(wj1,wj2,...,wjn).
m e d med med表示取中位数。 - 聚合后的权重为 W ′ = ( w 1 ′ , w 2 ′ , . . . , w p ′ ) W^{'}=(w_{1}^{'},w_{2}^{'},...,w_{p}^{'}) W′=(w1′,w2′,...,wp′),服务器把新的参数发送给客户端;
- 重复1-4,直到模型收敛。
边栏推荐
- Chapter 6 relational database theory
- [rust notes] 16 input and output (Part 1)
- [rust notes] 14 set (Part 2)
- A reason that is easy to be ignored when the printer is offline
- 1041 Be Unique
- redis发布订阅命令行实现
- [rust notes] 16 input and output (Part 2)
- 做 SQL 性能优化真是让人干瞪眼
- What is socket? Basic introduction to socket
- LeetCode 1200. Minimum absolute difference
猜你喜欢
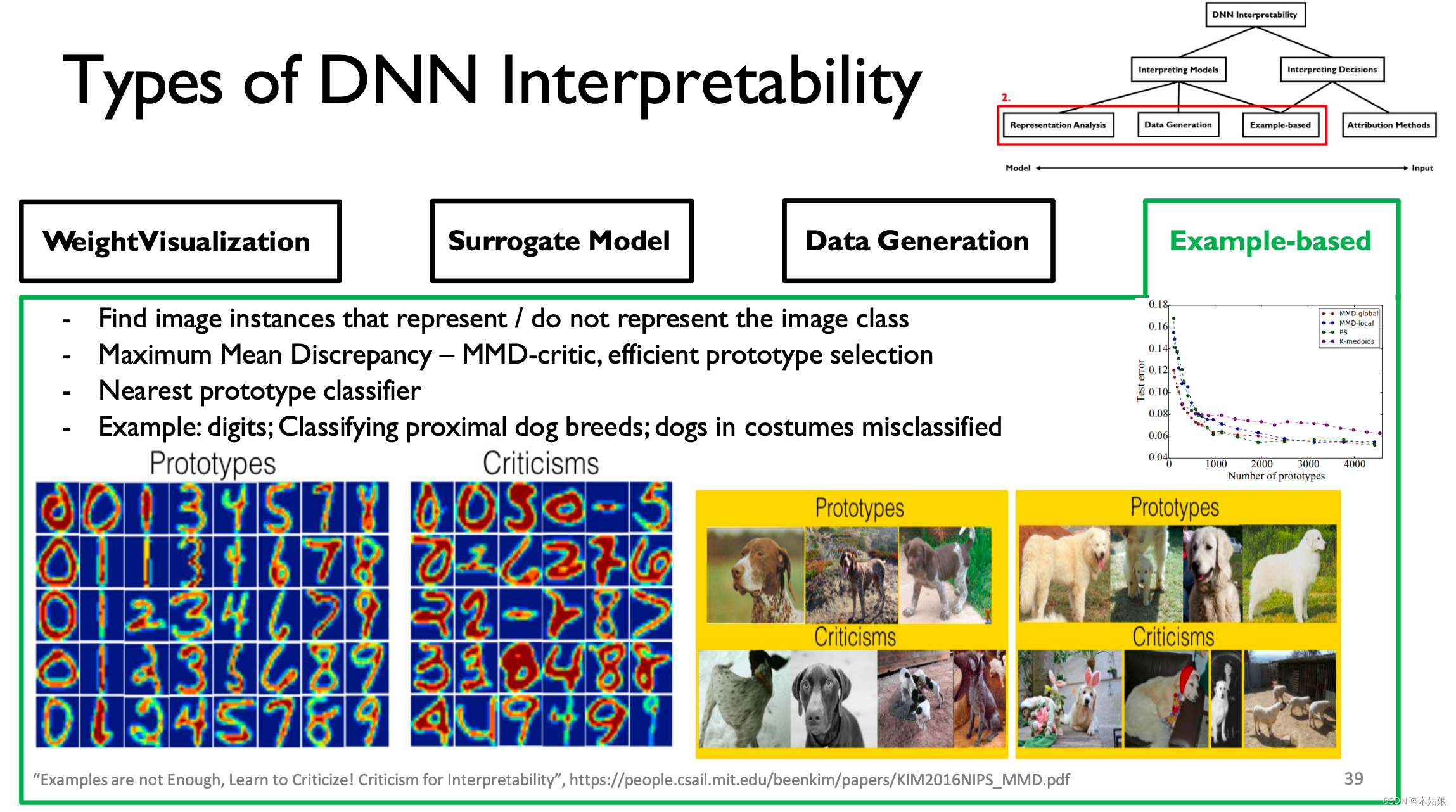
MIT-6874-Deep Learning in the Life Sciences Week 7

Simple selection sort of selection sort

做 SQL 性能优化真是让人干瞪眼
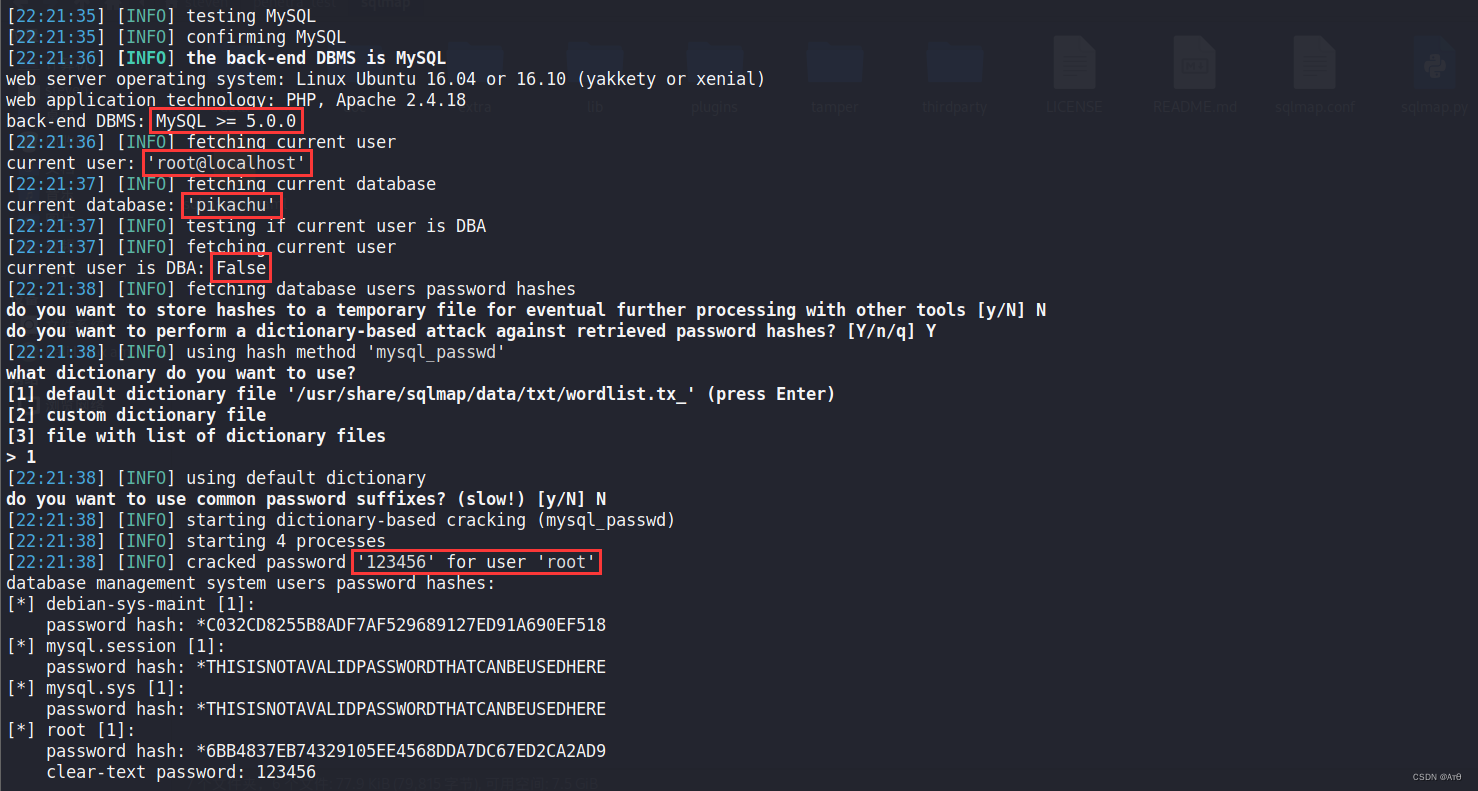
Sqlmap tutorial (II) practical skills I
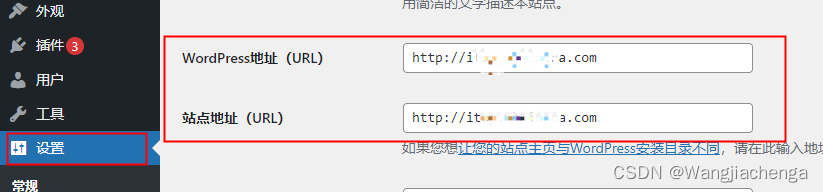
WordPress switches the page, and the domain name changes back to the IP address

求组合数 AcWing 887. 求组合数 III
![[2021]IBRNet: Learning Multi-View Image-Based Rendering Qianqian](/img/f1/e7a8a1a31bc5712d9f32d91305a2b0.jpg)
[2021]IBRNet: Learning Multi-View Image-Based Rendering Qianqian
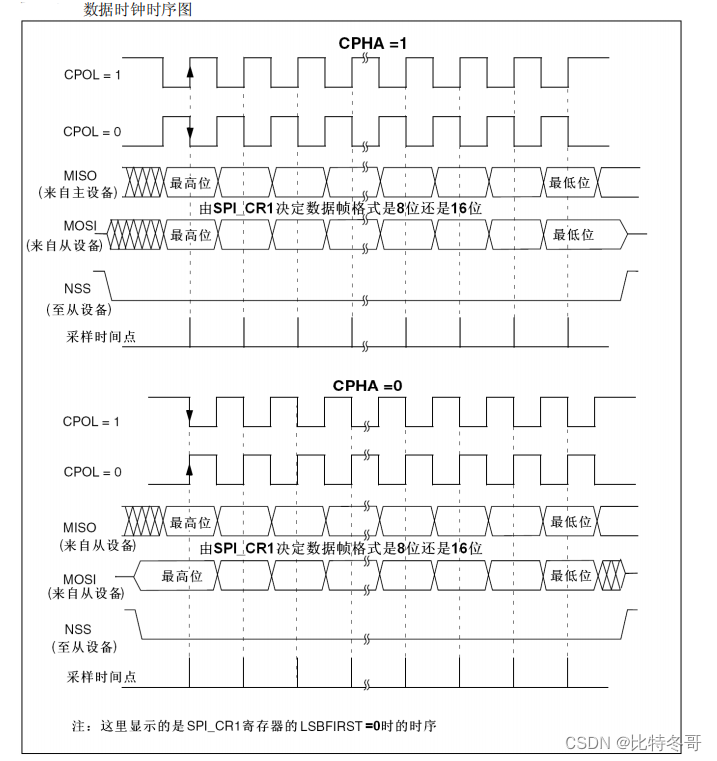
SPI details

Day 2 document

1.15 - input and output system
随机推荐
背包问题 AcWing 9. 分组背包问题
SQL三种连接:内连接、外连接、交叉连接
4. Object mapping Mapster
[BMZCTF-pwn] ectf-2014 seddit
Presentation of attribute value of an item
高斯消元 AcWing 884. 高斯消元解异或線性方程組
1.14 - assembly line
Is it impossible for lamda to wake up?
JS quickly converts JSON data into URL parameters
Arduino 控制的 RGB LED 无限镜
Groupbykey() and reducebykey() and combinebykey() in spark
Sum of three terms (construction)
MySQL怎么运行的系列(八)14张图说明白MySQL事务原子性和undo日志原理
求组合数 AcWing 887. 求组合数 III
Leetcode-3: Longest substring without repeated characters
MySQL advanced part 2: optimizing SQL steps
[2021]GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
P3265 [jloi2015] equipment purchase
Chart. JS - Format Y axis - chart js - Formatting Y axis
Gaussian elimination acwing 884 Gauss elimination for solving XOR linear equations