当前位置:网站首页>MySQL advanced part 2: SQL optimization
MySQL advanced part 2: SQL optimization
2022-07-05 06:13:00 【Dawnlighttt】
List of articles
Mass insert data
Environmental preparation :
CREATE TABLE `tb_user_2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
`birthday` datetime DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`email` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`qq` varchar(32) DEFAULT NULL,
`status` varchar(32) NOT NULL COMMENT ' User state ',
`create_time` datetime NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_user_username` (`username`) -- Uniqueness constraint
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
When using load When the command imports data , Appropriate settings can improve the efficiency of import .
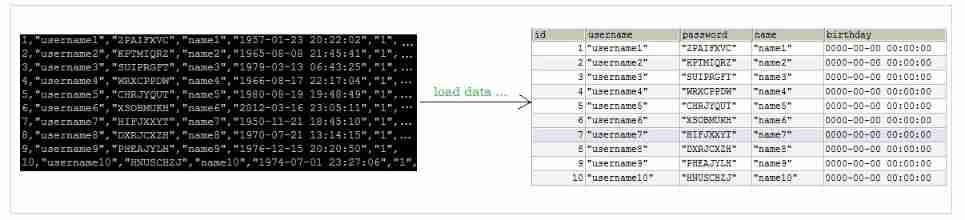
about InnoDB Type of watch , There are several ways to improve the efficiency of import :
1) Insert primary key in order
because InnoDB Tables of type are saved in the order of primary keys , So the imported data is arranged in the order of primary key , It can effectively improve the efficiency of importing data . If InnoDB Table has no primary key , Then the system will automatically create an internal column as the primary key by default , So if you can create a primary key for a table , Will be able to take advantage of this , To improve the efficiency of importing data .
Script file Introduction :
sql1.log ----> The primary key is ordered
sql2.log ----> The primary key is out of order
Insert ID Order the data :

Insert ID Sort the data out of order :

Notice that :【LOAD DATA Syntax upload data 】
See... For the specific solution Last 【Mysql note ERROR】
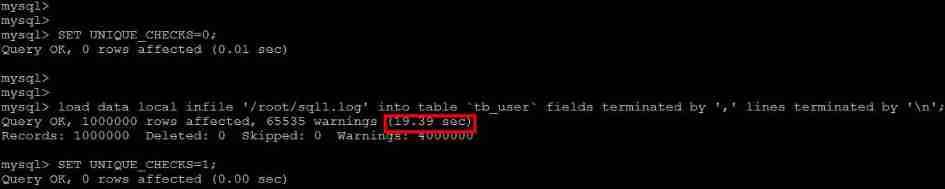
2) Turn off uniqueness check
Execute... Before importing data SET UNIQUE_CHECKS=0, Turn off uniqueness check , Execute... After import SET UNIQUE_CHECKS=1, Restore uniqueness check , Can improve the efficiency of import .
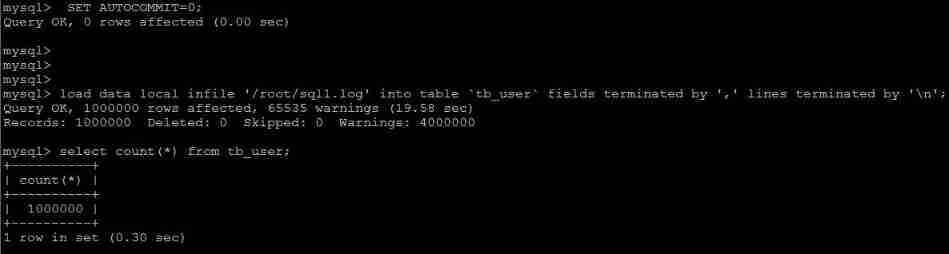
3) Commit transactions manually
If the app uses auto submit , It is recommended to execute before importing SET AUTOCOMMIT=0, Turn off auto submit , After the import, execute SET AUTOCOMMIT=1, Turn on auto submit , It can also improve the efficiency of import .
Optimize insert sentence
When it comes to data insert During operation , The following optimization schemes can be considered .
If you need to insert many rows of data into a table at the same time , You should try to use more than one value table insert sentence , This way will greatly reduce the connection between the client and the database 、 Turn off consumption, etc . Make the efficiency ratio separate from the single execution insert Fast sentence .Example , The original way is :
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry');The optimized scheme is :
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');Data insertion in transactions .start transaction; insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); commit;Data is inserted in orderinsert into tb_test values(4,'Tim'); insert into tb_test values(1,'Tom'); insert into tb_test values(3,'Jerry'); insert into tb_test values(5,'Rose'); insert into tb_test values(2,'Cat');After optimization
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); insert into tb_test values(4,'Tim'); insert into tb_test values(5,'Rose');
Optimize order by sentence
Environmental preparation
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(3) NOT NULL,
`salary` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100');
insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');
create index idx_emp_age_salary on emp(age,salary);
Two ways of sorting
1). The first is to sort the returned data , That is to say filesort Sort , All sorts that do not return sorting results directly through index are called FileSort Sort . Low efficiency
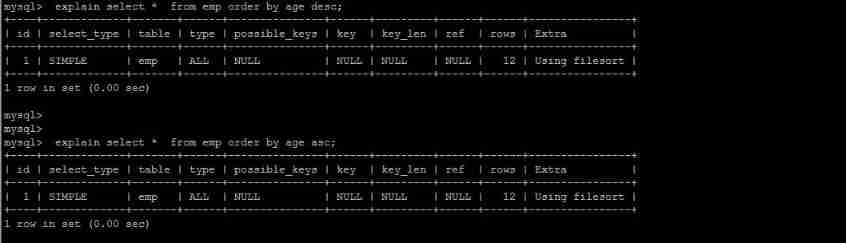
2). The second way is to return ordered data directly through ordered index scanning , This is the case using index, No need for extra sorting , High operating efficiency .
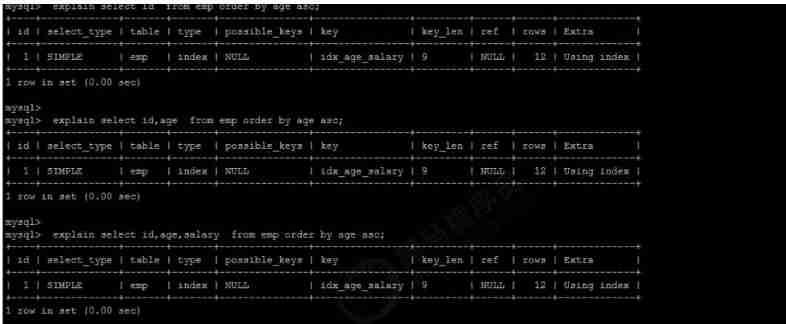
Multi field sorting
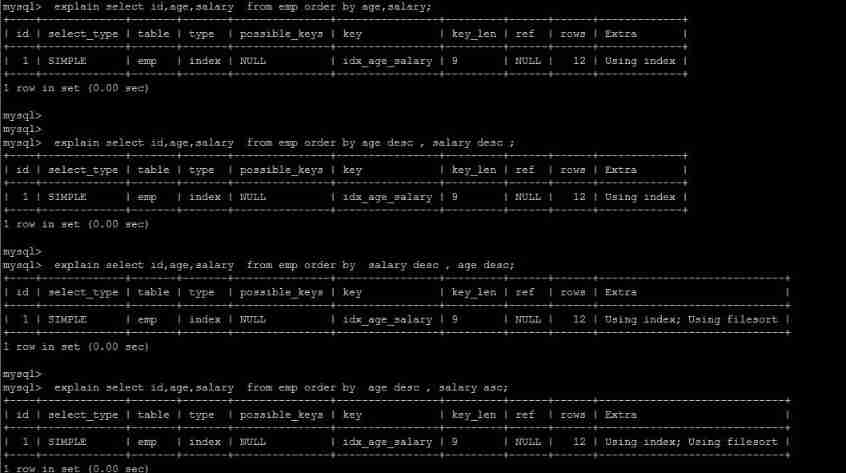
I understand MySQL Sort by , The goal of optimization is clear : Try to minimize the extra ordering , Return ordered data directly through index (using index).where Conditions and Order by Use the same index , also Order By In the same order as the index , also Order by The fields of are all in ascending order , Or in descending order . Otherwise, extra operation is necessary , And then there will be FileSort.
Filesort The optimization of the
By creating the appropriate index , Can reduce the Filesort Appearance , But in some cases , Conditionality cannot allow Filesort disappear , Then we need to speed up Filesort The sorting operation of . about Filesort , MySQL There are two sort algorithms :
1) Two scan algorithm :MySQL4.1 Before , Use this method to sort . First, take out the sorting field and row pointer information according to the conditions , Then in the sorting area sort buffer Middle order , If sort buffer Not enough , On the temporary watch temporary table The sorting result is stored in . After sorting , Then read the record according to the row pointer back to the table , This operation may result in a large number of random I/O operation .
2) One scan algorithm : Take out all the fields that meet the conditions at once , Then in the sorting area sort buffer After sorting, output the result set directly . When sorting, memory overhead is large , But the efficiency of sorting is higher than that of twice scanning algorithm .
MySQL By comparing system variables max_length_for_sort_data The size and Query The total size of the field taken out by the statement , To determine the sort algorithm , If max_length_for_sort_data Bigger , Then use the second optimized algorithm ; Otherwise use the first .
Can be improved properly sort_buffer_size and max_length_for_sort_data System variables , To increase the size of the sorting area , Improve the efficiency of sorting .

Optimize group by sentence
because GROUP BY In fact, the sorting operation will also be carried out , And with the ORDER BY comparison ,GROUP BY It's mainly about the grouping operation after sorting . Of course , If some other aggregate functions are used when grouping , So we need to calculate some aggregate functions . therefore , stay GROUP BY During the implementation of , And ORDER BY You can also use the index .
If the query contains group by But users want to avoid the consumption of sorting results , Then you can execute order by null No sorting . as follows :
drop index idx_emp_age_salary on emp;
explain select age,count(*) from emp group by age;

After optimization
explain select age,count(*) from emp group by age order by null;

As can be seen from the above example , first SQL The statement needs to be "filesort", And the second one. SQL because order by null There is no need for “filesort”, As mentioned above Filesort It's very time consuming .
Create index :
create index idx_emp_age_salary on emp(age,salary);

Optimize nested queries
Mysql4.1 After the version , Start supporting SQL Subquery of . This technology can be used SELECT Statement to create a single column query result , Then use this result as a filter in another query . Using subquery can complete many logical steps at once SQL operation , At the same time, transaction or table lock can be avoided , And it's easy to write . however , In some cases , Subqueries can be joined more efficiently (JOIN) replace .
Example , Find all user information with roles :
explain select * from t_user where id in (select user_id from user_role );
The execution plan is :

After optimization :
explain select * from t_user u , user_role ur where u.id = ur.user_id;

Connect (Join) The reason why queries are more efficient , Because MySQL There is no need to create a temporary table in memory to complete this logically two-step query .
Optimize OR Conditions
To contain OR Query clause for , If you want to use indexes , be OR Each condition column between must use an index , And you can't use composite indexes ; If there is no index , You should consider adding indexes .
obtain emp All indexes in the table :

Example :
explain select * from emp where id = 1 or age = 30;
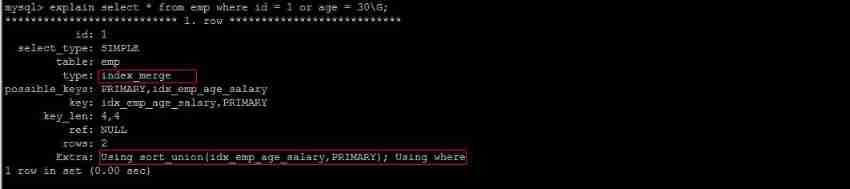
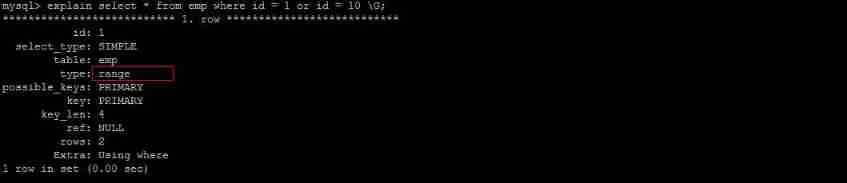
It is recommended to use union Replace or:

Let's compare the important indicators , The main difference was found to be type and ref These two
type It shows the type of access , Is a more important indicator , The result value is from good to bad :
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
UNION Of the statement type The value is ref,OR Of the statement type The value is range, You can see that this is a very clear gap
UNION Of the statement ref The value is const,OR Of the statement type The value is null,const Represents a constant value reference , Very fast
The difference between the two shows that UNION Is better than OR .
Optimize paging queries
General paging query , Better performance can be achieved by creating indexes . A common and very troublesome problem is limit 2000000,10 , At this time need MySQL Sort front 2000010 Record , Just go back to 2000000 - 2000010 The record of , Other records discarded , The cost of query sorting is very high .

Optimization idea 1
Complete sort paging operation on Index , Finally, according to the primary key Association, return to the original table to query other column contents .

Optimization idea II
This scheme is applicable to tables with self increasing primary key , You can put Limit The query is converted to a query in a certain location .( limitations : Primary keys cannot be broken )

Use SQL Tips
SQL Tips , Is an important means to optimize the database , Simple Come on , Is in the SQL Add some human prompts in the statement to optimize the operation .
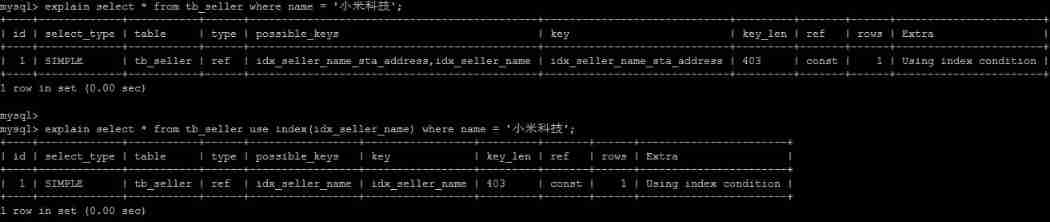
USE INDEX
After the table name in the query statement , add to use index To provide hope MySQL To refer to the index list , You can make MySQL No longer consider other available indexes .
create index idx_seller_name on tb_seller(name);
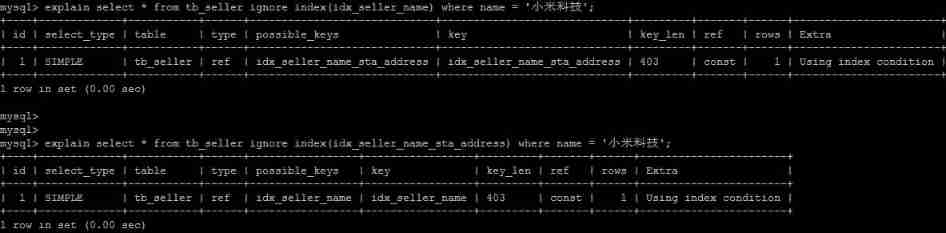
IGNORE INDEX
If the user just wants to let MySQL Ignore one or more indexes , You can use ignore index As hint .
explain select * from tb_seller ignore index(idx_seller_name) where name = ' Xiaomi Tech ';
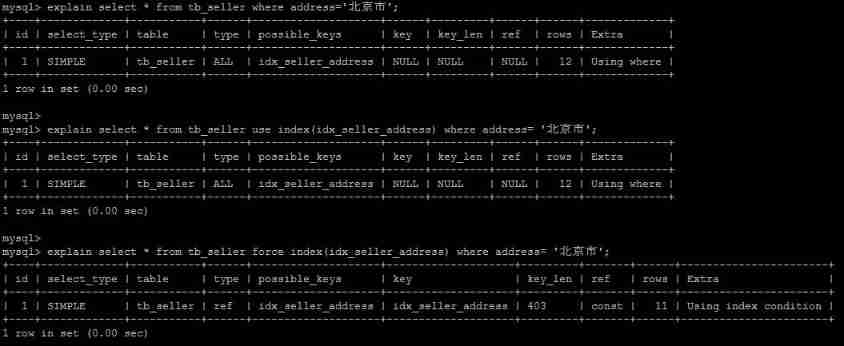
FORCE INDEX
Is mandatory MySQL Use a specific index , It can be used in query force index As hint .
create index idx_seller_address on tb_seller(address);
边栏推荐
- One question per day 1447 Simplest fraction
- Leetcode stack related
- Matrixdb V4.5.0 was launched with a new mars2 storage engine!
- 数据可视化图表总结(二)
- LaMDA 不可能觉醒吗?
- leetcode-556:下一个更大元素 III
- Leetcode-3: Longest substring without repeated characters
- LeetCode 0107. Sequence traversal of binary tree II - another method
- LVS简介【暂未完成(半成品)】
- 中职网络安全技能竞赛——广西区赛中间件渗透测试教程文章
猜你喜欢
Leetcode stack related
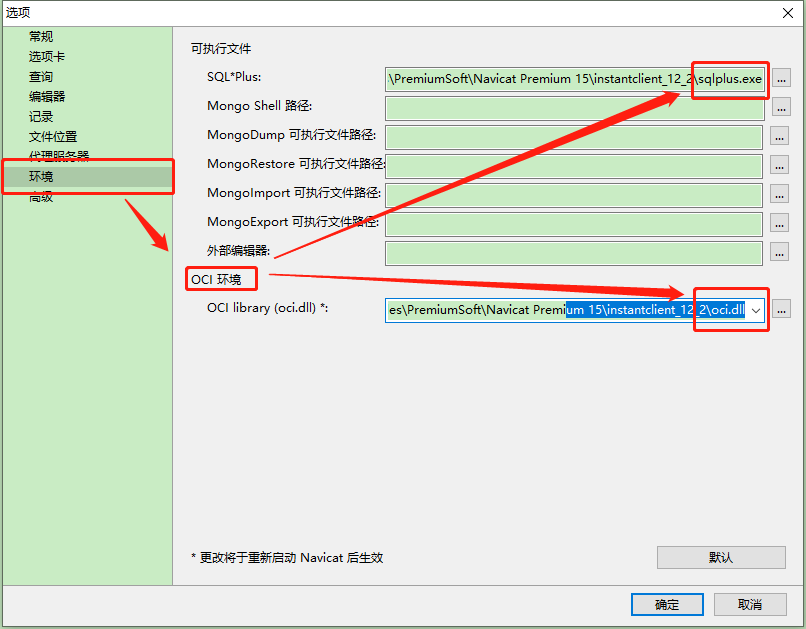
Error ora-28547 or ora-03135 when Navicat connects to Oracle Database
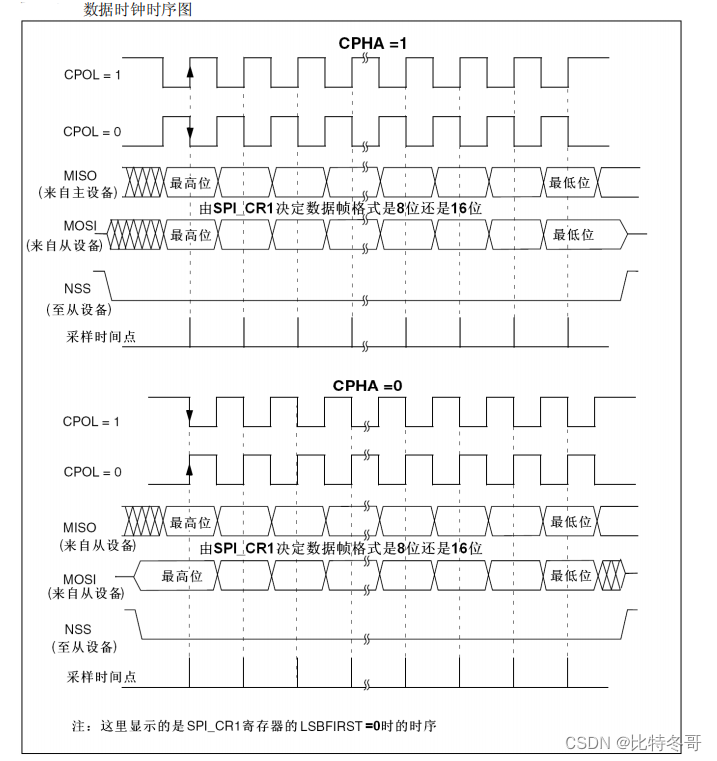
SPI 详解
SPI details

Redis publish subscribe command line implementation
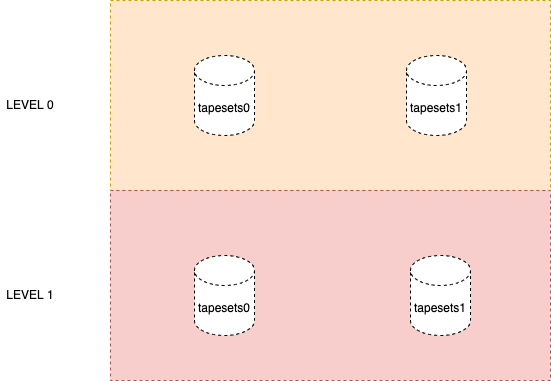
Matrixdb V4.5.0 was launched with a new mars2 storage engine!
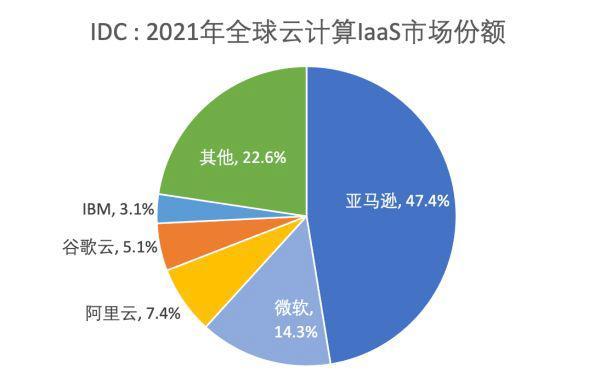
Quickly use Amazon memorydb and build your own redis memory database

1.15 - input and output system

做 SQL 性能优化真是让人干瞪眼
可变电阻器概述——结构、工作和不同应用
随机推荐
Leetcode-1200: minimum absolute difference
Arduino 控制的 RGB LED 无限镜
Sqlmap tutorial (1)
LeetCode 0108. Convert an ordered array into a binary search tree - the median of the array is the root, and the left and right of the median are the left and right subtrees respectively
1040 Longest Symmetric String
Wazuh開源主機安全解决方案的簡介與使用體驗
Matrixdb V4.5.0 was launched with a new mars2 storage engine!
927. 三等分 模拟
Currently clicked button and current mouse coordinates in QT judgment interface
Golang uses context gracefully
The sum of the unique elements of the daily question
SPI details
QT判断界面当前点击的按钮和当前鼠标坐标
A reason that is easy to be ignored when the printer is offline
【Rust 笔记】14-集合(下)
leetcode-6111:螺旋矩阵 IV
Basic explanation of typescript
[practical skills] how to do a good job in technical training?
leetcode-3:无重复字符的最长子串
On the characteristics of technology entrepreneurs from Dijkstra's Turing Award speech