当前位置:网站首页>【Rust 笔记】15-字符串与文本(下)
【Rust 笔记】15-字符串与文本(下)
2022-07-05 05:50:00 【phial03】
15.4 - 格式化值
格式化宏:总是借用对其参数的共享引用,不会取得所有权,也不会修改它们。
只要实现了
std::fmt模块的格式化特型,就可以扩展下述宏,以支持自定义类型:
format!:使用模板来构建String。println!和print!:将格式化后的文本写入标准输出流。writeln!和write!:将格式化后的文本写入指定输出流。panic!:使用模板构建一个终止诧异的表达式,可以包含自定义的信息。format_args!宏和std::fmt::Arguments类型:可以写出自定义的支持格式化语言的函数和宏。
模板中的每个
{},都会被后面某个参数的格式化形式取代。模板字符串必须是常量。模板的
{}部分称为格式化形参,形式为
{which:how}。
which和how是可选的。which部分用于选择使用模板后面的哪个参数来填补当前位置。可以通过索引或名称来选择参数。没有which部分的形参会简单地从左往右应用参数。how部分用于指定如何格式化参数:加多少空白、精度和基数多少。如果有how参数,那么前面的冒号是必须的。
| 模板字符串 | 参数列表 | 结果 |
|---|---|---|
"number of {}: {}" | "elephants", 19 | "number of elephants: 19" |
"from {1} to {0}" | "the grave", "the cradle" | "from the cradle to the grave" |
"v = {:?}" | vec![0, 1, 2, 5, 12, 29] | "v = [0, 1, 2, 5, 12, 29]" |
"name = {:?}" | "Nemo" | "name = \"Nemo\"" |
{: 8.2} km/s"" | "11.186" | " 11.19 km/s" |
"{: 20} {: 02x} {: 02x}" | "adc #42", 105, 42 | "adc #42 69 2a" |
"{1:02x} {2:02x} {0}" | "adc #42", 105, 42 | "69 2a adc #42" |
"{lsb:02x} {msb:02x} {insn}" | insn="adc #42", lsb = 105, msb = 42 | "69 2a adc #42" |
15.4.1 - 格式化文本值
格式化 &str 或 String(char 等同于只有一个字符的字符串)文本类型时,格式化形参 how 部分可以包含如下可选内容:
| 使用的特性 | 模板字符串 | 结果 |
|---|---|---|
| 默认 | "{}" | "bookends" |
| 最小字段宽度 | "{: 4}" | "bookends" |
"{: 12}" | "bookends " | |
| 文本长度限制 | "{:. 4}" | "book" |
"{:. 12}" | "bookends" | |
| 字段宽度及长度限制 | "{: 12.20}" | "bookends " |
"{: 4.20}" | "bookends" | |
"{: 4.6}" | "booken" | |
"{: 6.4}" | "book " | |
| 左对齐,字段宽度 | "{: <12}" | "bookends " |
| 居中对齐,字段宽度 | "{: ^12}" | " bookends " |
| 右对齐,字段宽度 | "{: >12}" | " bookends" |
填充 =,居中对齐,字段宽度 | "{: =^12}" | "==bookends==" |
填充 *,右对齐,字段宽度,长度限制 | "{: *>12.4}" | "********book" |
除
&str和String之外,也可以给格式化宏传入引用目标为文本的智能指针类型,比如Rc<String>或Cow<'a, str>。不能直接把文件名路径
std::path::Path传给格式化宏,但可以使用Path的dispaly方法返回的值进行格式化。println!("processing file: {}", path.display());
15.4.2 - 格式化数值
当格式化参数具有 usize 或 f64 数值类型时,形参 how 的值必须包含,有以下可选组成部分。
- 格式化数值
| 使用的特性 | 模板字符串 | 结果 |
|---|---|---|
| 默认 | "{}" | "1234" |
| 强制符号 | "{: +}" | "+1234" |
| 最小字段宽度 | "{: 12}" | " 1234" |
"{: 2}" | "1234" | |
| 符号,宽度 | "{: +12}" | " +1234" |
| 前置零,宽度 | "{: 012}" | "000000001234" |
| 符号,前置零,宽度 | "{: +012}" | "+00000001234" |
| 左对齐,宽度 | "{: <12}" | "1234 " |
| 居中对齐,宽度 | "{: ^12}" | " 1234 " |
| 右对齐,宽度 | "{: >12}" | " 1234" |
| 左对齐,符号,宽度 | "{: <+12}" | "+1234 " |
| 居中对齐,符号,宽度 | "{: ^+12}" | " +1234 " |
| 右对齐,符号,宽度 | "{: >+12}" | " +1234" |
| 填充 =,居中对齐,宽度 | "{: =^12}" | "====1234====" |
| 二进制计数法 | "{: b}" | "100110100010" |
| 宽度,八进制计数法 | "{: 12o}" | " 2322" |
| 符号,宽度,十六进制计数法 | "{: +12x}" | " +4d2" |
| 符号,宽度,大写十六进制计数法 | "{: +12X}" | " +4D2" |
| 符号,基数前缀,宽度,十六进制 | "{: +#12x}" | " +0x4d2" |
| 符号,基数,补零,宽度,十六进制 | "{: +#012x}" | "+0x0000004d2" |
"{: +#06x}" | "+0x4d2" |
- 格式化浮点数
| 使用的特性 | 模板字符串 | 结果 |
|---|---|---|
| 默认 | "{}" | "1234.5678" |
| 精度 | "{:. 2}" | "1234.57" |
"{:. 6}" | "1234.567800" | |
| 最小字段宽度 | "{: 12}" | " 1234.5678" |
| 宽度,精度 | "{: 12.2}" | " 1234.57" |
"{: 12.6}" | " 1234.567800" | |
| 前置零,宽度,精度 | "{: 012.6}" | "01234.567800" |
| 科学计数法 | "{: e}" | "1.234578e3" |
| 科学计数法,精度 | "{: 3e}" | "1.235e3" |
| 科学计数法,宽度,精度 | "{: 12.3e}" | " 1.235e3" |
"{: 12.3E}" | " 1.235E3" |
15.4.3 - 格式化其他类型
- 每种错误类型都应该实现
std::error::Error特型,该特型扩展支持了默认的格式化特型std::fmt::Display。任何实现Error的类型都是可以格式化的。 std::net::IpAddr和std::net::SocketAddr类型:可以格式化互联网协议地址。true和false布尔值:可以直接格式化。
15.4.4 - 为调试格式化值
{:?}格式:可以调试和输出日志,也支持格式化任意 Rust 标准库中的公共类型。可以用来检查向量、切片、元组、散列表、线程等数百种类型。
使用
#[derive(Debug)]语法,可以让自定义类型支持{:?}。#[derive(Copy, Clone, Debug)] struct Complex { r: f64, i: f64 } let third = Complex { r: -0.5, i: f64::sqrt(0.75) }; println!("{:?}", third); // 输出结果 Complex { r: -0.5, i: 0.8660254037544386 }
#字符:在格式化形参中添加,用来美化打印输出结果。use std::collections::HashMap; let mut map = HashMap::new(); map.insert("Portland", (45.5237606, -122.6819273)); map.insert("Shanghai", (25.0375167, 121.5637)); println!("{:?}", map); // 输出结果 { "Shanghai": (25.0375167, 121.5637), "Portland": (45.5237606, -122.6819273)} println!("{: #?}", map); // 输出结果 { "Shanghai": ( 25.0375167, 121.5637 ), "Portland": ( 45.5237606, -122.6819273 ) }
15.4.5 - 为调试格式化指针
{: p} 符号:用于将引用、Box 和其他指针类型格式化为地址:
use std::rc::Rc;
let original = Rc::new("mazurka".to_string());
let cloned = original.clone();
let impostor = Rc::new("mazurka".to_string());
println!("text: {}, {}, {}", original, cloned, impostor);
println!("pointers: {: p}, {: p}, {: p}", original, cloned, impostor);
// 输出结果
text: mazurka, mazurka, mazurka
pointers: 0x7f99af80e000, 0x7f99af80e000, 0x7f99af80e030
15.4.6 - 通过索引或名字引用参数
格式化形参可以使用索引显示选择它使用的参数。
assert_eq!(format!("{1}, {0}, {2}", "zeroth", "first", "second"), "first, zeroth, second");冒号后面可以再跟其他格式化形参。
assert_eq!(format!("{2:#06x}, {1:b}, {0:=>10}", "first", 10, 100), "0x0064, 1010, =====first");处理通过索引选择参数,还可以使用变量名称。
assert_eq!(format!("{descirption:. <25} {quantity: 2} @ {price: 5.2}", price = 3.25, quantity = 3, description = "Maple Turnmeric Latte" ), "Maple Turnmeric Latte..... 3 @ 3.25" );还可以在一个格式化宏中混用索引、名字和位置参数。位置参数从左往右匹配,不考虑已有的索引和命名参数。
assert_eq!(format!("{mode} {2} {} {}", "people", "eater", "purple", mode = "flying"), "flying purple people eater" );混合使用时,命名参数必须放在列表末尾。
15.4.7 - 动态宽度与精度
1$作为最小字段宽度:告诉format!使用第二个参数的值作为宽度format!("{: >1$}", content, get_width());引用的参数必须是
usize。还可以通过名字来引用参数:format!("{: >width$}", content, width=get_width());同样也支持文本长度限制。
format!("{: >width$.limit$}", content, width=get_width(), limit=get_limit());*符号:表示取得下一个位置上的参数作为精度。format!("{:. *}", get_limit(), content);作为精度的参数必须是
usize。字段宽度没有对应的语法。
15.4.8 - 格式化自定义类型
格式化宏使用
std::fmt模块中定义的一组特型,将值转换为文本。
- 如果自定义其中的一个或多个特型,就可以让自定义类型实现格式化宏的格式。
- 格式形参的记号表示其参数类型必须实现哪个特型。
| 记号 | 示例 | 特型 | 用途 |
|---|---|---|---|
| 无 | {} | std::fmt::Display | 文本、数值、错误: 兜底的特型 |
b | {: #b} | std::fmt::Binary | 二进制中的数值 |
o | {: #5o} | std::fmt::Octal | 八进制中的数值 |
x | {: 4x} | std::fmt::LowerHex | 十六进制中的数值,小写数字 |
X | {: 016X} | std::fmt::UpperHex | 十六进制中的数值,大写数字 |
e | {:. 3e} | std::fmt::LowerExp | 科学计数法中的浮点数值 |
E | {:. 3E} | std::fmt::UpperExp | 同上,E 大写显示 |
? | {: #?} | std::fmt::Debug | 调试视图,适合开发者 |
p | {: p} | std::fmt::Pointer | 指针地址,适合开发者 |
如果把
#[derive(Debug)]属性放在类型定义上,那么就可以直接使用{:?}格式化形参。Rust 会自动为这个类型实现
std::fmt::Debug特型。格式化特型的结构都一样,只是名字不同,如下的
std::fmt::Display特型:trait Display { fn fmt(&self, dest: &mut std::fmt::Formatter) -> std::fmt::Result; }对
Display实现Complex。use std::fmt; impl fmt::Display for Complex { fn fmt(&self, dest: &mut std::fmt::Formatter) -> fmt::Result { let i_sign = if self.i < 0.0 { '-' } else { '+' }; write!(dest, "{} {} {} i", self.r, i_sign, f64::abs(self.i)) } }
15.4.9 - 在代码中使用格式化语言
使用 format_args! 宏和 std::fmt::Arguments 类型,在示例代码中,编写接收格式化模板和参数的函数和宏。
fn logging_enabled() -> bool {
...
}
use std::fs::OpenOptions;
use std::io::Write;
fn write_log_entry(entry: std::fmt::Arguments) {
if logging_enabled() {
let mut log_file = OpenOptions::new()
.append(true)
.create(true)
.open("log-file-name")
.expect("failed to open log fie");
log_file.write_fmt(entry)
.expect("failed to write to log");
}
}
// 实现一个调用write_log_entry的宏
macro_rules! log {
($format: tt, $($arg: expr), *) => (
write_log_entry(format_args!($format, ${
$arg}, *))
)
}
fn main() {
write_log_entry(format_args!("Hard! {:?}\n", mysterious_value)); // 直接调用
log!("O day and night, but this is wondrous strange! {:?}\n", mysterious_value);
}
- 编译时,
format_args!宏会解析模板字符串,并按照参数类型对其进行检查,并在发现问题时报错。 - 运行时,
format_args!宏会求值参数,并构建一个带有所有格式化文本必需信息的Arguments值,包括模板的预解析形式,以及对参数值的共享引用。 File类型实现了std::io::Write特型,其write_fmt方法接收Argument参数,并进行格式化,之后再把结果写入底层流。
15.5 - 正则表达式
regex包是 Rust 官方的正则表达式库,提供了常用的搜索和匹配功能。要使用
regex,需要在Cargo.toml文件的[dependencies]部分添加如下代码:regex = "1"然后在包的底层加一个
extern crate特性项extern crate regex;
15.5.1 - 基本用法
Regex值表示解析之后的正则表达式。Regex::new构造函数:将传入的&str作为正则表达式解析,返回Result。use regex::Regex; // 使用r"..."原始字符串语法,可以避免多反斜杠的转义 let semver = Regex::new(r"(\d+)\.(\d+)\.(\d+) (-[-.[: alnum:]] *)?")?; // 简单搜索,返回布尔值结果 let haystack = r#"regex = "0.2.5""#; assert!(semver.is_match(haystack));Regex::captures方法:从字符串中搜索第一个匹配,返回的
regex::Captures值,包含正则表达式中每一组对应的匹配信息。let captures = semver.captures(haystack) .ok_or("semver regex should have matched")?; assert_eq!(&captures[0], "0.2.5"); assert_eq!(&captures[1], "0"); assert_eq!(&captures[2], "2"); assert_eq!(&captures[3], "5");要测试某个特定组是否有匹配结果,可以调用
Captures::get,会返回Option<regex::Match>。Match值记录一个捕获组的匹配信息。assert_eq!(captures.get(4), None); assert_eq!(captures.get(3).unwrap().start(), 13); assert_eq!(captures.get(3).unwrap().end(), 14); assert_eq!(captures.get(3).unwrap().as_str(), "5");
可以遍历一个字符串中的所有匹配:
let haystack = "In the beginning there was 1.0.0. \ For a while, we used 1.0.1-beta, \ but in the end, we settled on 1.2.4."; let matches: Vec<&str> = semver.find_iter(haystack) .map(|match_| match_.as_str()) .collect(); assert_eq!(matches, vec!["1.0.0", "1.0.1-beta", "1.2.4"]);find_iter迭代器:为表达式的每个不重叠匹配,分别生成一个Match值,从字符串开头到末尾。captures_iter方法也能实现上述功能,但是生成的记录是所有捕获组的Captures值。记录捕获组会导致搜索变慢。
15.5.2 - 构建 Regex 值
Regex::new构造函数的性能较差,最好不要在大计算量的循环中构建Regex,建议只构建一次,然后重用。lazy_static包提供了首次使用时,懒构建静态值的方法。要使用这个包,需要在Cargo.toml中加上:[dependencies] lazy_static = "1.4.0"lazy_static包提供了声明变量用的宏:#[marcro_use] extern crate lazy_static; lazy_static! { static ref SEMVER: Regex = Regex::new(r"(\d+)\.(\d+)\.(\d+) (-[-.[: alnum:]] *)?") .expect("error parsing regex"); }调用
SEMVER:正则表达式只会在程序运行时编译一次。use std::io::BufRead; let stdin = std::io::stdin(); for line in stdin.locak().lines() { let line = line?; if let Some(match_) = SEMVER.find(&line) { println!("{}", match_.as_str()); } }
15.6 - 规范化
- 规范化:如果两个字符串按照 Unicode 的规则应该判定为等价,那么它们规范化的形式应该每个字符都相同。
- 在以 UTF-8 编码的情况下,每个字节都相同。
- 可以使用
==来比较规范化的字符串。 - 可以将它们作为
HashMap或HashSet的键。
- 不进行规范化,会导致安全隐患。
15.6.1 - 规范化形式
- 分解表示形式:更适合显示文本或搜索,因为可以呈现更多细节。
- 对于越南语
Phô,把基本字符跟它的两个记号分开表示成 3 个独立的 Unicode 字符。 - 如
'o'、\u{31b}(COMBINING HORN,组合角号)和\u{309}(COMBINING HOOK ABOVE,组合上钩号)。 - 最终结果是
Pho\u{31b}\u{309}
- 对于越南语
- 组合表示形式:
format!宏之类的简单字符串格式化特型。 - 将文本规范化为兼容性等效形式,有可能丢失重要信息。比如
2^5,可能会忽略上标5的格式,而直接保存为25。 - 4 种规范化形式:
- Unicode NFC(Normalization From C,规范化形式 C):对每个字符串应用最大化组合。W3C 建议对所有内容使用 NFC。
- Unicode NFD(Normalization From D,规范化形式 D):对每个字符串应用最大化分解。
- Unicode NFKC:将所有兼容性等效序列规范化为组合形式。建议对编程语言的标识符使用。
- Unicode NFKD:将所有兼容性等效序列规范化为分解形式
15.6.2-unicode-normalization 包
unicode-normalization包的特型,可以给&str添加把文本转换为任意 4 中规范化形式的方法。[dependencies] unicode-normalization = "0.1.8"包的顶部文件,需要添加
extern crate声明:extern crate unicode_normalization;如此可以对
&str调用相应转化为不同规范化形式的迭代器的方法。use unicode_normalization::UnicodeNormalization; assert_eq!("Phô".nfd().collect::<String>(), "Pho\u{31b}\u{309}"); assert_eq!("Phô".nfc().collect::<String>(), "Pho\u{1edf}"); // "ffi"连字符 assert_eq!("① Di\u{fb03culty}".nfkc().collect::<String>(), "1 Difficulty");两个规范化的字符串拼接起来,未必是规范化的。
Unicode 规则:只要文本在规范化时没有使用未分配的码点,那其规范化形式在标准的未来版本中就不会改变。
规范化形式通常适合持久存储数据。
详见《Rust 程序设计》(吉姆 - 布兰迪、贾森 - 奥伦多夫著,李松峰译)第十七章
原文地址
边栏推荐
- The number of enclaves
- 每日一题-无重复字符的最长子串
- Detailed explanation of expression (csp-j 2021 expr) topic
- Hang wait lock vs spin lock (where both are used)
- Convolution neural network -- convolution layer
- Sword finger offer 53 - ii Missing numbers from 0 to n-1
- Palindrome (csp-s-2021-palin) solution
- Configuration and startup of kubedm series-02-kubelet
- Educational Codeforces Round 116 (Rated for Div. 2) E. Arena
- leetcode-31:下一个排列
猜你喜欢



随机推荐
Implement a fixed capacity stack
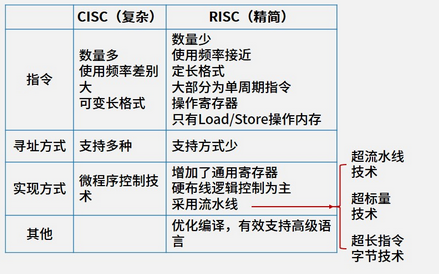
1.13 - RISC/CISC
读者写者模型
2022年貴州省職業院校技能大賽中職組網絡安全賽項規程
How to adjust bugs in general projects ----- take you through the whole process by hand
卷积神经网络——卷积层
Sword finger offer 05 Replace spaces
【云原生】微服务之Feign自定义配置的记录
Sword finger offer 04 Search in two-dimensional array
leetcode-3:无重复字符的最长子串
884. Uncommon words in two sentences
2022 极术通讯-Arm 虚拟硬件加速物联网软件开发
2020ccpc Qinhuangdao J - Kingdom's power
1.14 - 流水线
每日一题-无重复字符的最长子串
Configuration and startup of kubedm series-02-kubelet
On the characteristics of technology entrepreneurs from Dijkstra's Turing Award speech
Animation scoring data analysis and visualization and it industry recruitment data analysis and visualization
Full Permutation Code (recursive writing)
PC register