当前位置:网站首页>Doing SQL performance optimization is really eye-catching
Doing SQL performance optimization is really eye-catching
2022-07-05 06:07:00 【Unknown architect】
Many big data calculations use SQL Realized , When you run slowly, you have to optimize SQL, But we often encounter situations that make people stare .
such as , There are three statements in the stored procedure that are roughly like this, which execute very slowly :
select a,b,sum(x) from T group by a,b where …;
select c,d,max(y) from T group by c,d where …;
select a,c,avg(y),min(z) from T group by a,c where …;
there T It's a huge watch with hundreds of millions of lines , To group in three ways , The result set of grouping is not large .
The grouping operation needs to traverse the data table , These three sentences SQL You have to traverse this big table three times , It takes a long time to traverse hundreds of millions of rows of data , Not to mention three times .
In this grouping operation , Relative to the time of traversing the hard disk ,CPU The calculation time is almost negligible . If you can calculate the summary of multiple groups in one traversal , although CPU The amount of calculation has not decreased , But it can greatly reduce the amount of data read from the hard disk , You can double the speed .
If SQL Support syntax like this :
from T -- The data come from T surface
select a,b,sum(x) group by a,b where … -- The first grouping in traversal
select c,d,max(y) group by c,d where … -- The second group in traversal
select a,c,avg(y),min(z) group by a,c where …; -- The third group in traversal
Can return multiple result sets at a time , Then you can greatly improve the performance .
unfortunately , SQL There is no such grammar , Can't write such a statement , Only one alternative , Just use group a,b,c,d First calculate a more detailed grouping result set , But first save it as a temporary table , To further use SQL Calculate the target result .SQL As follows :
create table T\_temp as select a,b,c,d,
sum(case when … then x else 0 end) sumx,
max(case when … then y else null end) maxy,
sum(case when … then y else 0 end) sumy,
count(case when … then 1 else null end) county,
min(case when … then z else null end) minz
group by a,b,c,d;
select a,b,sum(sumx) from T\_temp group by a,b where …;
select c,d,max(maxy) from T\_temp group by c,d where …;
select a,c,sum(sumy)/sum(county),min(minz) from T\_temp group by a,c where …;
So just traverse once , But take different WHERE The condition goes to the previous case when in , The code is much more complex , It will also increase the amount of calculation . and , When calculating the temporary table, the number of grouping fields becomes large , The result set can be very large , Finally, the temporary table is traversed many times , Computing performance is not fast . Large result set grouping calculation also needs hard disk cache , Its performance is also very poor .
You can also use the database cursor of the stored procedure to put data one by one fetch Come out and calculate , But it has to be done all by yourself WHERE and GROUP The action of , It's too cumbersome to write , The performance of database cursor traversing data will only be worse !
Just stare !
TopN Operation will also encounter this helplessness . for instance , use Oracle Of SQL Write top5 It looks something like this :
select \* from (select x from T order by x desc) where rownum<=5
surface T Yes 10 Billion data , from SQL Look at the sentences , Is to sort all the data before taking it out 5 name , The rest of the sorting results are useless ! Large sorting costs a lot , The amount of data is too large to fit in memory , There will be multiple hard disk data switching , Computing performance will be very poor !
It's not hard to avoid big sorting , Keep a... In memory 5 A small collection of records , When traversing data , Before the calculated data 5 Names are preserved in this small set , If the new data obtained is more than the current second 5 Famous , Then insert it and throw away the present 5 name , If it's better than the current 5 The name should be small , Do not act . To do so , As long as the 10 100 million pieces of data can be traversed once , And the memory consumption is very small , Computing performance will be greatly improved .
The essence of this algorithm is to TopN It is also regarded as the sum of 、 Count the same aggregation operation , It just returns a collection, not a single value .SQL If it could be written like this , You can avoid big sorting :
select top(x,5) from T
Unfortunately ,SQL There is no explicit set data type , Aggregate functions can only return single values , Can't write such a statement !
But the good thing is that the whole episode TopN Relatively simple , although SQL Write like that , The database is usually optimized in Engineering , Use the above method to avoid large sorting . therefore Oracle Count that SQL Not slow .
however , If TopN The situation is complicated , Used in subqueries or with JOIN When we get together , Optimization engines usually don't work . For example, after grouping, calculate the of each group TopN, use SQL It's a little difficult to write .Oracle Of SQL It's written like this :
select \* from (select y,x,row\_number() over (partition by y order by x desc) rn from T) where rn<=5
Now , The database optimization engine is dizzy , We will not use the above method to TopN Understand the method of aggregation operation . I have to sort , As a result, the operation speed drops sharply !
If SQL The grouping TopN Can write like this :
select y,top(x,5) from T group by y
hold top As and sum The same aggregate function , It's not only easier to read , And it's easy to calculate at high speed .
unfortunately , no way .
Still stare !
Correlation calculation is also very common . Take the filtering calculation after an order is associated with multiple tables as an example ,SQL It's roughly like this :
select o.oid,o.orderdate,o.amount
from orders o
left join city ci on o.cityid = ci.cityid
left join shipper sh on o.shid=sh.shid
left join employee e on o.eid=e.eid
left join supplier su on o.suid=su.suid
where ci.state='New York'
and e.title='manager'
and ...
The order form has tens of millions of data , City 、 Shippers 、 Employee 、 The data of suppliers and other tables are not large . The filter criteria fields may come from these tables , And the front end transmits parameters to the background , It's dynamic .
SQL It is generally used HASH JOIN The algorithm implements these associations , To calculate HASH Value and compare . Only one... Can be parsed at a time JOIN, Yes N individual JOIN To execute N Pass action , After each association, you need to keep the intermediate results for the next round , The calculation process is complex , The data will also be traversed many times , Poor computing performance .
Usually , These associated code tables are small , You can read it into memory first . If each associated field in the order table is serialized in advance , For example, convert the employee number field value to the serial number of the corresponding employee table record . So when calculating , You can use the employee number field value ( That is, the employee table serial number ), Directly get the record of the corresponding position of the employee table in memory , Performance ratio HASH JOIN Much faster , And you only need to traverse the order table once , The speed increase will be very obvious !
That is, you can put SQL Write it as follows :
select o.oid,o.orderdate,o.amount
from orders o
left join city c on o.cid = c.# -- The city number of the order form is through the serial number # Associated city table
left join shipper sh on o.shid=sh.# -- Order form shipper number through serial number # Associated shippers table
left join employee e on o.eid=e.# -- The employee number of the order form is by serial number # Associated employee table
left join supplier su on o.suid=su.#-- The supplier number of the order form is passed through the serial number # Associated supplier table
where ci.state='New York'
and e.title='manager'
and ...
It is a pity ,SQL The concept of unordered set is used , Even if these numbers have been numbered , Databases can't take advantage of this feature , The mechanism of rapid sequence number positioning cannot be used on these unordered sets of corresponding association tables , Only the index can be used to find , And the database doesn't know that the number is serialized , Still calculate HASH Value and comparison , The performance is still very poor !
There are good methods that can't be implemented , Can only stare again !
And highly concurrent account queries , This operation is very simple :
select id,amt,tdate,… from T
where id='10100'
and tdate>= to\_date('2021-01-10','yyyy-MM-dd')
and tdate<to_date('2021-01-25','yyyy-mm-dd')
and="" …="" <p="">
stay T In the hundreds of millions of historical data in the table , Quickly find several to thousands of details of an account ,SQL It's not complicated to write , The difficulty is that the response speed should reach the second level or even faster in case of large concurrency . In order to improve query response speed , It's usually about T Tabular id Field indexing :
create index index_T_1 on T(id)
In the database , It's fast to find a single account with an index , But when there is a lot of concurrency, it will obviously slow down . The reason is mentioned above SQL Theoretical basis of disorder , The total amount of data is very large , Unable to read all into memory , The database cannot guarantee that the data of the same account is physically stored continuously . The hard disk has the smallest reading unit , When reading discontinuous data , Will take out a lot of irrelevant content , Queries will slow down . Each query with high concurrent access is slower , The overall performance will be very poor . At a time when experience is very important , Who dares to let users wait more than ten seconds ?!
The easy way to think of is , Sort hundreds of millions of data in advance according to accounts , Ensure the continuous storage of data in the same account , Almost all the data blocks read out from the hard disk during query are target values , Performance will be greatly improved .
however , use SQL The relational database of the system does not have this awareness , The physical order of data storage is not enforced ! The problem is not SQL Caused by grammar , But also with SQL The theoretical basis of , There is still no way to implement these algorithms in relational databases .
To do that ? Can only stare ?
No more SQL And relational databases , To use another computing engine .
Open source concentrator SPL Based on the theoretical basis of innovation , Support more data types and operations , Be able to describe the new algorithm in the above scenario . Use simple and convenient SPL Write code , It can greatly improve the computing performance in a short time !
The above questions use SPL The code example written is as follows :
- Multiple groups are calculated in one traversal
| A | B | |
|---|---|---|
| 1 | =file(“T.ctx”).open().cursor(a,b,c,d,x,y,z | |
| 2 | cursor A1 | =A2.select(…).groups(a,b;sum(x)) |
| 3 | // Define the first filter in traversal 、 grouping | |
| 4 | cursor | =A4.select(…).groups(c,d;max(y)) |
| 5 | // Define the second filter in traversal 、 grouping | |
| 6 | cursor | =A6.select(…).groupx(a,c;avg(y),min(z)) |
| 7 | // Define the third filter in traversal 、 grouping | |
| 8 | … | // End of definition , Start to calculate the three ways of filtering 、 grouping |
- Calculate by aggregation Top5
The complete Top5( Multithreaded parallel computing )
| A | |
|---|---|
| 1 | =file(“T.ctx”).open() |
| 2 | [email protected](x).total(top(-5,x),top(5,x)) |
| 3 | //top(-5,x) To calculate the x The biggest front 5 name ,top(5,x) yes x The smallest front 5 name . |
grouping Top5( Multithreaded parallel computing )
| A | |
|---|---|
| 1 | =file(“T.ctx”).open() |
| 2 | [email protected](x,y).groups(y;top(-5,x),top(5,x)) |
- Use the serial number as the associated SPL Code :
System initialization
| A | |
|---|---|
| 1 | >env(city,file(“city.btx”)[email protected]()),env(employee,file(“employee.btx”)[email protected]()),… |
| 2 | // When the system is initialized , Several small tables are read into memory |
Inquire about
| A | |
|---|---|
| 1 | =file(“orders.ctx”).open().cursor(cid,eid,…).switch(cid,city:#;eid,employee:#;…) |
| 2 | =A1.select(cid.state==“New York” && eid.title==“manager”…) |
| 3 | // First, the serial number is associated , Then reference the associated table fields to write the filter criteria |
- High concurrency of account queries SPL Code :
Data preprocessing , Orderly storage
| A | B | |
|---|---|---|
| 1 | =file(“T-original.ctx”).open().cursor(id,tdate,amt,…) | |
| 2 | =A1.sortx(id) | =file(“T.ctx”) |
| 3 | [email protected](#id,tdate,amt,…)[email protected](A2) | |
| 4 | =B2.open().index(index_id;id) | |
| 5 | // Sort the original data , Save as new table , And index the account number |
Account query
| A | |
|---|---|
| 1 | =T.icursor(;id==10100 && tdate>=date(“2021-01-10”) && tdate<date(“2021-01-25”) && …,index_id).fetch() |
| 2 | // The query code is very simple |
Apart from these simple examples ,SPL More high-performance algorithms can be implemented , For example, orderly merging realizes the association between orders and details 、 Pre association technology realizes multi-layer dimension table Association in multi-dimensional analysis 、 Bit storage technology to achieve thousands of tag statistics 、 Boolean set technology can speed up the query of multiple enumeration value filter conditions 、 Timing grouping technology realizes complex funnel analysis and so on .
Is for SQL Performance optimization headache partners , Can discuss with us :
http://www.raqsoft.com.cn/wx/Query-run-batch-ad.html
SPL Information

边栏推荐
- CF1634 F. Fibonacci Additions
- Over fitting and regularization
- MIT-6874-Deep Learning in the Life Sciences Week 7
- wordpress切换页面,域名变回了IP地址
- Appium基础 — 使用Appium的第一个Demo
- Common optimization methods
- 927. Trisection simulation
- One question per day 2047 Number of valid words in the sentence
- 【Rust 笔记】13-迭代器(下)
- Bit mask of bit operation
猜你喜欢

中职网络安全技能竞赛——广西区赛中间件渗透测试教程文章
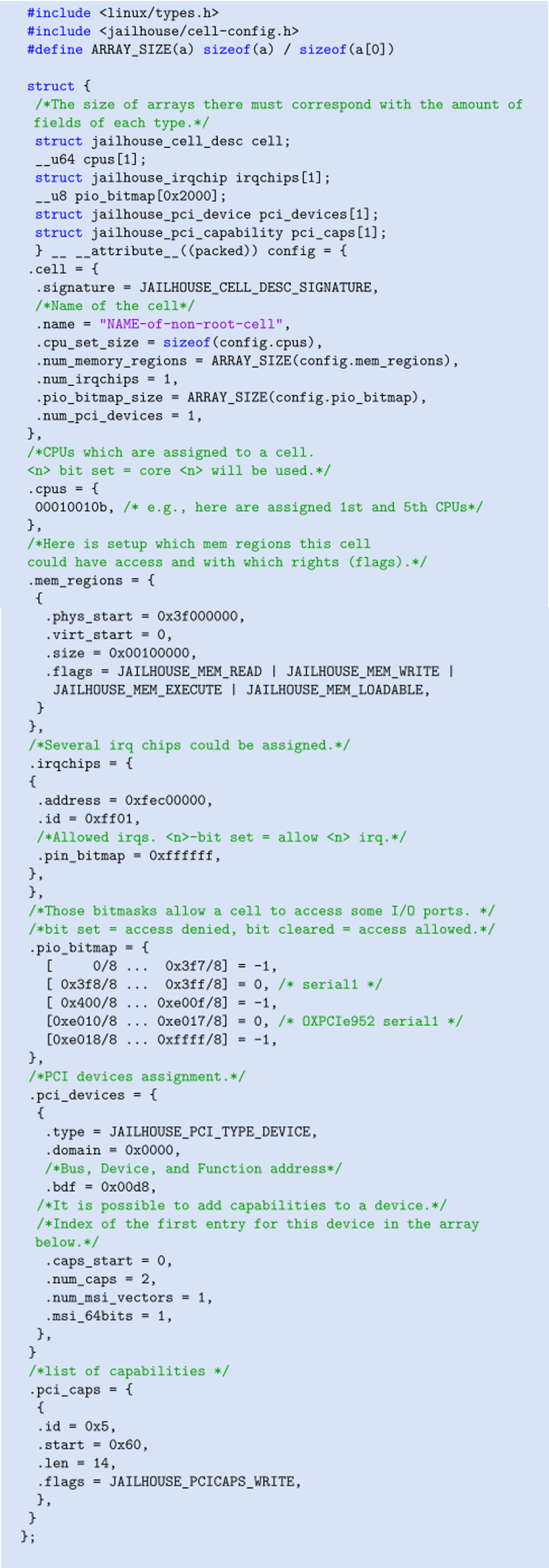
【Jailhouse 文章】Jailhouse Hypervisor

1.15 - 输入输出系统

【实战技能】非技术背景经理的技术管理
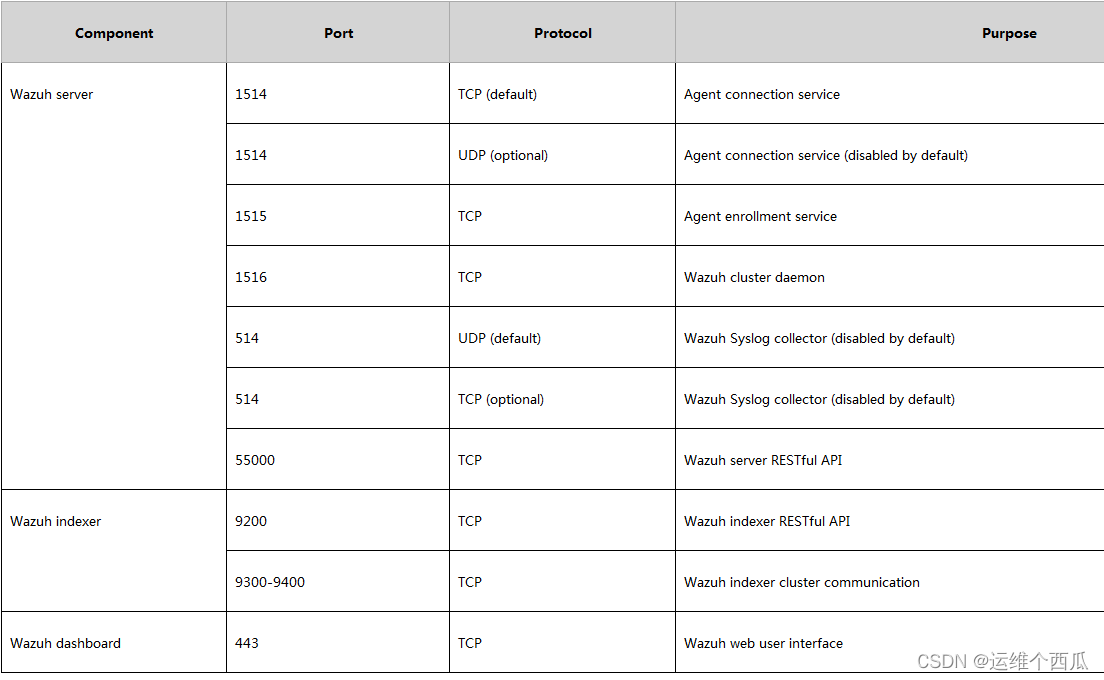
Wazuh开源主机安全解决方案的简介与使用体验
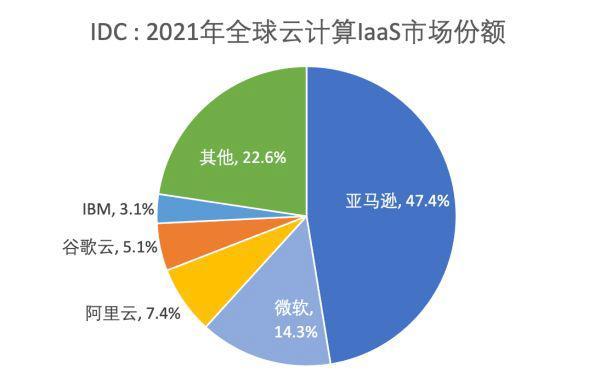
快速使用Amazon MemoryDB并构建你专属的Redis内存数据库
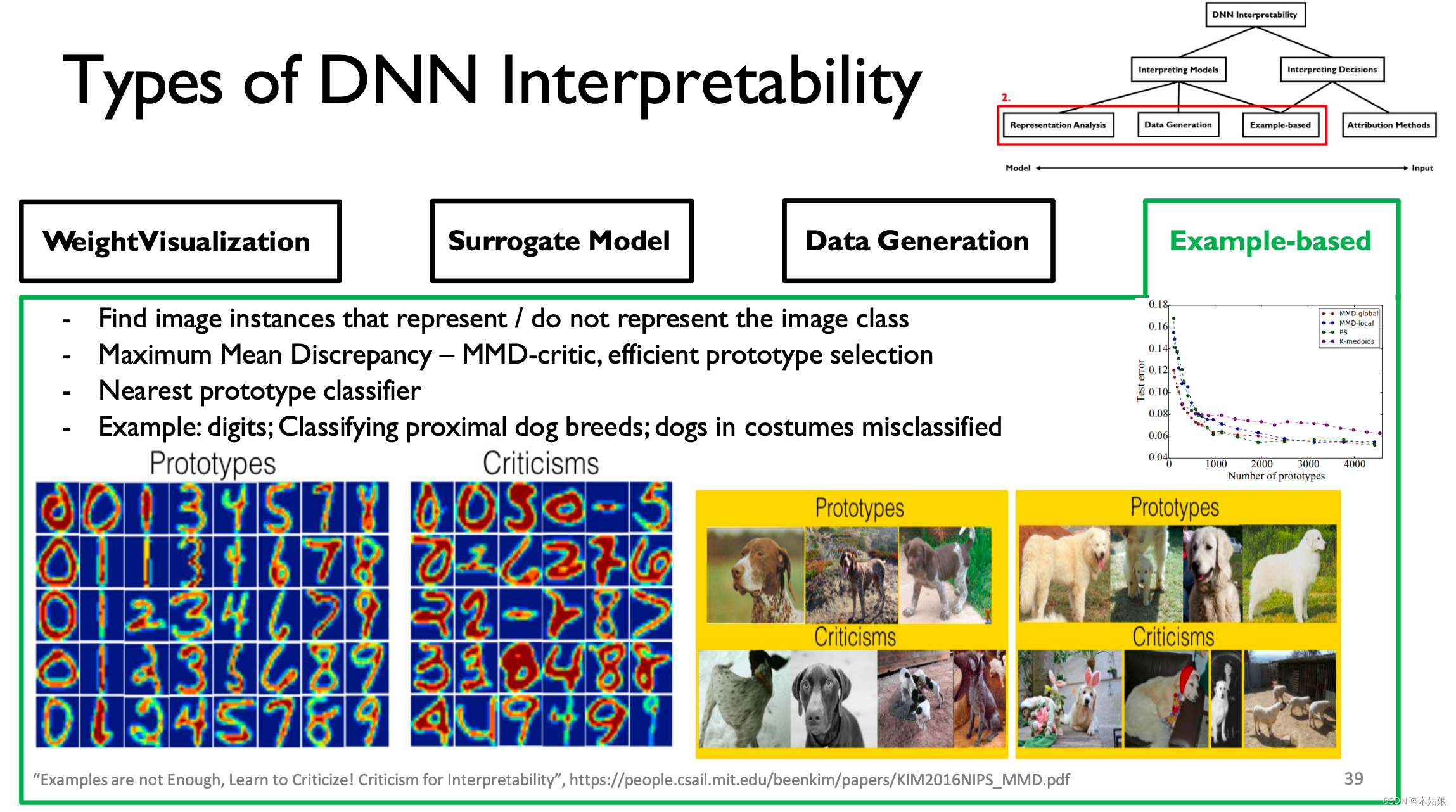
MIT-6874-Deep Learning in the Life Sciences Week 7

【云原生】微服务之Feign自定义配置的记录
Typical use cases for knapsacks, queues, and stacks
The connection and solution between the shortest Hamilton path and the traveling salesman problem
随机推荐
redis发布订阅命令行实现
【Rust 笔记】16-输入与输出(下)
[rust notes] 13 iterator (Part 2)
数据可视化图表总结(一)
CF1634E Fair Share
【Rust 笔记】14-集合(上)
LeetCode 1200.最小绝对差
Flutter Web 硬件键盘监听
Educational Codeforces Round 116 (Rated for Div. 2) E. Arena
Spark中groupByKey() 和 reduceByKey() 和combineByKey()
Sword finger offer 35 Replication of complex linked list
Kubedm series-00-overview
LaMDA 不可能觉醒吗?
Brief introduction to tcp/ip protocol stack
leetcode-556:下一个更大元素 III
1039 Course List for Student
Daily question 2006 Number of pairs whose absolute value of difference is k
One question per day 1447 Simplest fraction
CF1637E Best Pair
The sum of the unique elements of the daily question