当前位置:网站首页>Introduction to LVS [unfinished (semi-finished products)]
Introduction to LVS [unfinished (semi-finished products)]
2022-07-05 06:01:00 【Johnny. G】
1、LVS brief introduction
LVS yes Linux Virtual Server For short , That is to say Linux Virtual server , Is a free software project initiated by Dr. Zhang wensong , Its official website is www.linuxvirtualserver.org. Now? LVS It's already Linux Part of the standard kernel , stay Linux2.4 Before kernel , Use LVS Must recompile the kernel to support LVS Function module , But from Linux2.4 After kernel , It's completely built in LVS Each function module , There is no need to patch the kernel , You can use it directly LVS Various functions provided .
Use LVS The goal of technology is : adopt LVS Load balancing technology and Linux The operating system achieves a high performance 、 Cluster of highly available servers , It has good reliability 、 Scalability and operability . Thus, the optimal service performance can be achieved at low cost .
LVS since 1998 Year begins , Now it is a mature technology project . You can use LVS Technology to achieve highly scalable 、 Highly available network services , for example WWW service 、Cache service 、DNS service 、FTP service 、MAIL service 、 video / Audio on demand services, etc , There are many famous websites and organizations using LVS Cluster system erected , for example :Linux Portal for (www.linux.com)、 towards RealPlayer Famous for providing audio and video services Real company (www.real.com)、 The world's largest open source website (sourceforge.net) etc. .
2、LVS Architecture
Use LVS The server cluster system has three parts : The front-end load balancing layer , use Load Balancer Express , The middle server group layer , use Server Array Express , Data sharing storage layer at the bottom , use Shared Storage Express .
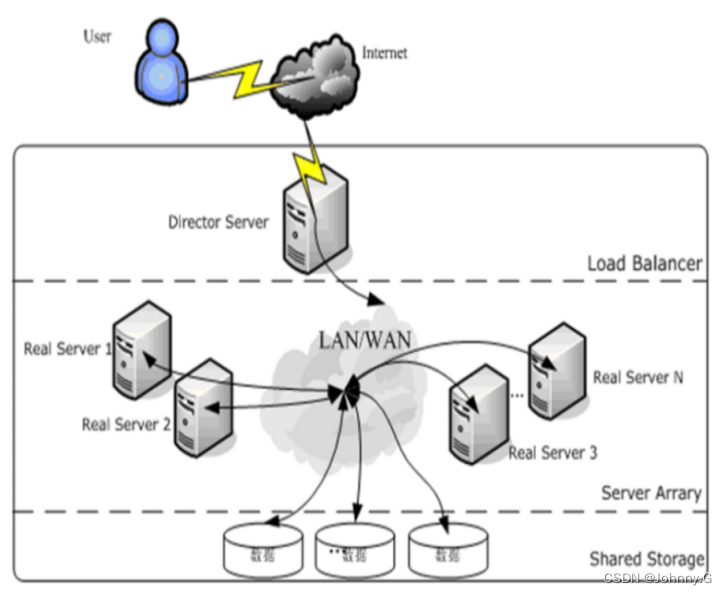
Load Balancer layer : At the front end of the whole cluster system , There are one or more load schedulers (Director Server) form ,LVS The module is installed in Director Server On , and Director Its main function is similar to that of a router , It contains completion LVS The routing table set by the function , Users' requests are distributed to Server Array Application server of layer (Real Server) On . meanwhile , stay Director Server And install the right one Real Server Service monitoring module Ldirectord, This module is used to monitor each Real Server The health of the service . stay Real Server When not available, remove it from LVS Remove... From the routing table , Rejoin on recovery .
Server Array layer : Consists of a set of machines that actually run application services ,Real Server It can be WEB The server 、MAIL The server 、FTP The server 、DNS The server 、 One or more video servers , Every Real Server Through high speed LAN Or distributed all over the world WAN Connect . In practical applications ,Director Server They may also hold concurrent posts Real Server Role .
Shared Storage layer : Is for all Real Server A storage area that provides Shared storage space and content consistency , In Physics , It generally consists of disk array devices , To provide content consistency , In general, you can go through NFS Network file systems share data , however NFS In a busy business system , The performance is not very good , Cluster file system can be adopted at this time , for example Red hat Of GFS file system ,oracle Provided OCFS2 File system, etc .
3、LVS Related terms
For the convenience of discussion LVS technology ,LVS The community provides a naming convention , The contents are as follows
| name | abbreviation | explain |
|---|---|---|
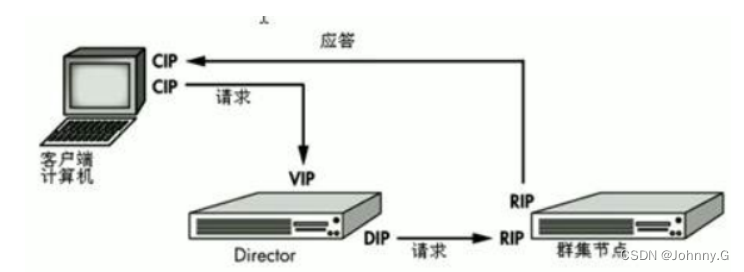
| fictitious IP Address (Virtual IP Address) | VIP | Director Used to provide services to client computers IP Address |
| real IP Address (Real Server IP Address) | RIP | Used on the nodes below the cluster IP Address |
| Director Of IP Address (Director IP Address) | DIP | Director Used to connect internal and external networks IP Address |
| Client host IP Address (Client IP Address) | CIP | The client user computer requests the cluster server IP Address , This address is used as the source of the request sent to the cluster IP Address |
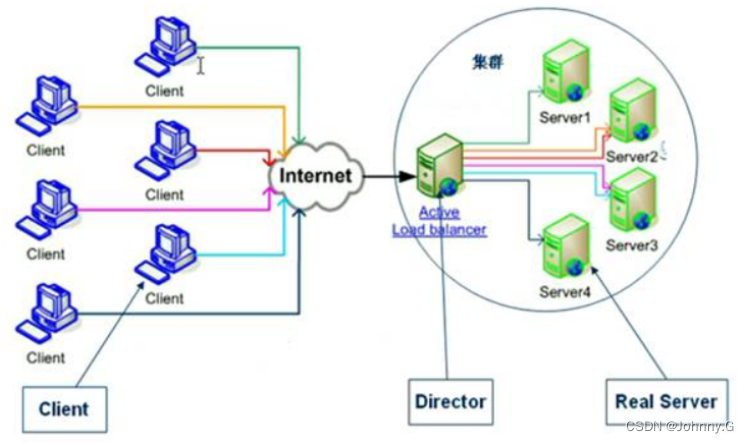
LVS The nodes inside the cluster are called real servers (Real Serve), Also called cluster node . The computer requesting the cluster service is called the client computer . The same way that computers usually exchange data packets on the Internet , Client computers 、Director And real servers IP Addresses communicate with each other . The naming of different architecture roles is shown in the following figure :
4、LVS Working mode
LVS Of IP Load balancing technology is achieved by IPVS Module to achieve ,IPVS yes LVS The core software of cluster system , Its main function is : Installed in the Director Server On , At the same time Director Server Make a virtual IP Address , Users have to go through this virtual IP Address access service . This virtual IP Commonly referred to as LVS Of VIP, namely Virtual IP. Requests for access first go through VIP Arriving at the load scheduler , The load scheduler then starts from Real Server Select a service node from the list to respond to the user's request
When the user's request reaches the load scheduler , How the scheduler sends the request to the provider Real Server node , and Real Server How the node returns data to the user , yes IPVS The key technology to realize ,IPVS There are three load balancing mechanisms , Namely NAT、TUN and DR.
VS/NAT: namely (Virtual Server via Network Address Translation)
That is, the network address translation technology realizes the virtual server , When a user request arrives at the scheduler , The scheduler will request the destination address of the message ( It's virtual IP Address ) Rewrite to the selected Real Server Address , At the same time, the target port of the message is also changed to the selected Real Server The corresponding port of , Finally, the message request is sent to the selected Real Server. After getting the data on the server side ,Real Server When returning data to the user , The source address and source port of the message need to be changed to virtual through the load scheduler again IP Address and corresponding port , And then send the data to the user , Complete the whole load scheduling process .
VS/TUN : namely (Virtual Server via IP Tunneling)
That is to say IP Tunnel technology realizes virtual server . Its connection scheduling and management with VS/NAT The same way , It's just that its message forwarding method is different ,VS/TUN In the way , The scheduler uses IP Tunneling technology forwards user requests to a certain Real Server, And this Real Server Will respond directly to the user's request , No more front-end scheduler , Besides , Yes Real Server There is no requirement for the geographical location of , You can talk to Director Server In the same network segment , It can also be an independent network . therefore , stay TUN In the way , The scheduler will only process the user's message requests , The throughput of cluster system is greatly improved .
VS/DR: namely (Virtual Server via Direct Routing)
That is to use direct routing technology to realize virtual server . Its connection scheduling and management with VS/NAT and VS/TUN The same as in China , But its message forwarding method is different ,VS/DR By rewriting the MAC Address , Send the request to Real Server, and Real Server Return the response directly to the customer , Save it. VS/TUN Medium IP Tunnel costs . This method has the highest and best performance among the three load scheduling mechanisms , But you have to ask Director Server And Real Server There is a network card connected to the same physical network segment .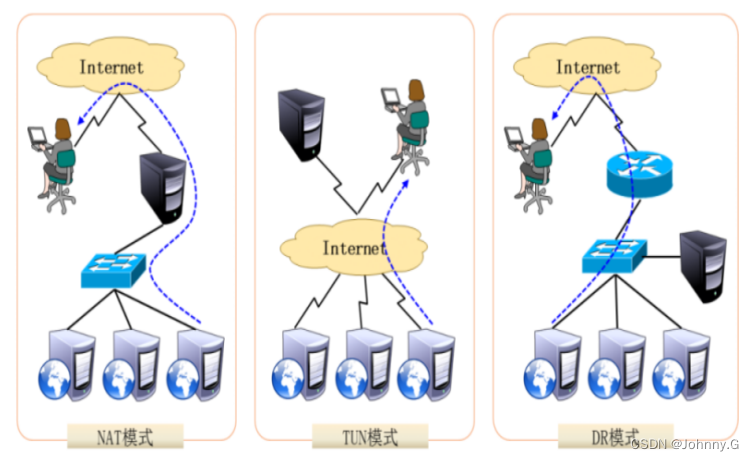
hot tip :(VS/DR) Mode is the most widely used mode on the Internet , stay LVS-DR Configuration in progress ,Director Forward all inbound requests to the internal nodes of the cluster , But the nodes inside the cluster directly send their replies to the client computers ( Don't pass Director Come back ). As shown in the figure below
5、LVS Scheduling algorithm
The scheduling method determines how to distribute the workload among these cluster nodes .
When Director Received access to her from the client computer VIP When the inbound request of the cluster service on ,Director You must decide which cluster node should get the request .Director The scheduling methods that can be used to make this decision fall into two basic categories :
Fixed scheduling algorithm :rr,wrr,dh,sh
Dynamic scheduling algorithm :wlc,lblc,lblcr,SED,NQ( The last two official sites do not mention )
10 The three scheduling algorithms are shown in the following table :
| Algorithm | explain |
|---|---|
| rr | Round robin scheduling (Round-Robin), It allocates different requests in turn RS, That is to say RS Average share request . It's a simple algorithm , But it is only suitable for cases with little difference in processing performance |
| wrr | Weighted round robin scheduling (Weighted Round-Robin) It's going to vary RS To assign tasks . Higher weight RS Get the tasks first , And the number of connections allocated will be less than the one with lower weight RS more . The same weight RS You get the same number of connections . |
| dh | Destination hash scheduling (Destination Hashing) Find a static for the keyword with the destination address hash To get what you need RS. |
| sh | Source address hash scheduling (source hashing) Find a static keyword with the source address hash To get what you need RS. |
| wlc | Weighted minimum connection number scheduling (weighted leastconnection) Assuming that the machine RS The weight of wi(i=1…n), Current TCP The number of connections is Ti(i=1…n), Select... In turn Ti/Wi For the smallest RS As the next assignment RS. |
| lc | Minimum connection number scheduling (Least-Connection),IPVS The table stores all the active connections . Send the connection request of the heart to the one with the smallest number of connections RS. |
| lblc | Minimum number of connections based on address scheduling (locality-Based Least-Connection) Assign requests from the same destination address to the same station RS If this server is not full , Otherwise, it is assigned to the one with the smallest number of connections RS, And take it as the first consideration for the next allocation . |
| lblcr | Scheduling based on minimum number of repeated connections of address band (Locality-Based Least-Connection with Replication) For a destination address , There is a corresponding RS A subset of . Request for this address , It has the smallest number of connections in the gamete set RS; If all subsets in the server are full , Select a server with a small number of connections from the cluster , Add it to this subset and assign connections ; If within a certain period of time , No changes have been made , The node with the largest load in the subset is removed from the subset . |
| SED | The shortest expected delay (shortest expected delay scheduling SED)(SED) be based on wlc Algorithm . This has to be exemplified ABC Three machines are weighted separately 123, The number of connections is also 123. So if you use wlc Algorithm, when a new request enters, it may be distributed to ABC Any one of . Use sed Such an operation will be carried out after the algorithm A(1+1)/1 B(1+2)/2 C(1+3)/3 According to the result of the operation , Give the connection to C. |
| NQ | Minimum queue scheduling (Never Queue Scheduling NQ)(NQ) There is no need for queues . If there is one realserver Connection number =0 Just distribute the past , There's no need to be sed operation |
Describe in detail the four most commonly used scheduling algorithms :
Polling scheduling (Round Robin)
“ polling ” Dispatch is also called 1:1 Dispatch , The scheduler passes “ polling ” The scheduling algorithm places external user requests in order 1:1 Is assigned to each of the clusters Real Server On , The algorithm treats each computer equally Real Server, Regardless of the actual load and connection status on the server .
Weighted polling scheduling (Weighted Round Robin)
“ Weighted polling ” The scheduling algorithm is based on Real Server Different processing capabilities to schedule access requests . You can do it for each Real Server Set different scheduling weights , For relatively good performance Real Server You can set higher weights , And for the less capable Real Server, You can set a lower weight , This ensures that the server with strong processing power can handle more access traffic . Make full use of the server resources . meanwhile , The scheduler can also automatically query Real Server The load of , And dynamically adjust its weight .
Least link scheduling (Least Connections) “ The minimum connection ” The scheduling algorithm dynamically schedules network requests to the server with the least number of established links . If the real server of the cluster system has similar system performance , use “ The minimum connection ” The scheduling algorithm can balance the load well .
Weighted least link scheduling (Weighted Least Connections) “ Weighted least link scheduling ” yes “ Least Connection Scheduling ” Superset , Each service node can use the corresponding weight to represent its processing capacity , And the system administrator can set the corresponding weight dynamically , The default weight is 1, When allocating new connection requests, the weighted minimum connection scheduling makes the number of established connections of the service node proportional to its weight as far as possible .
边栏推荐
- The connection and solution between the shortest Hamilton path and the traveling salesman problem
- leetcode-22:括号生成
- QQ电脑版取消转义符输入表情
- 【Jailhouse 文章】Jailhouse Hypervisor
- Pointnet++ learning
- R语言【数据集的导入导出】
- Dichotomy, discretization, etc
- Arduino 控制的 RGB LED 无限镜
- [practical skills] how to do a good job in technical training?
- leetcode-1200:最小绝对差
猜你喜欢
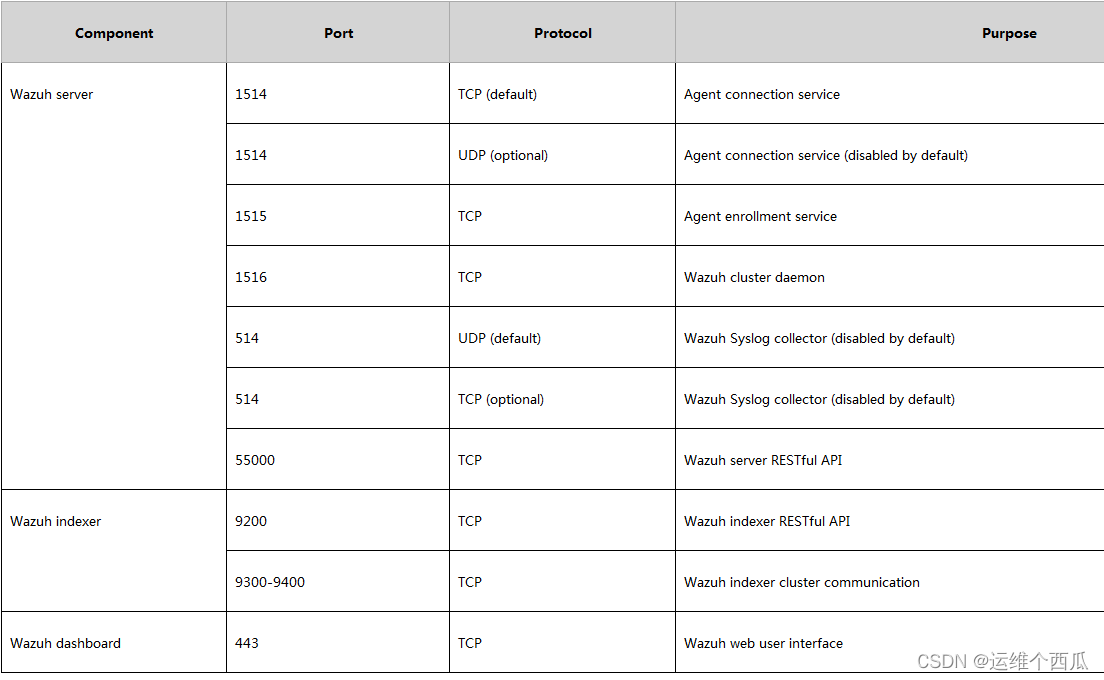
Wazuh開源主機安全解决方案的簡介與使用體驗
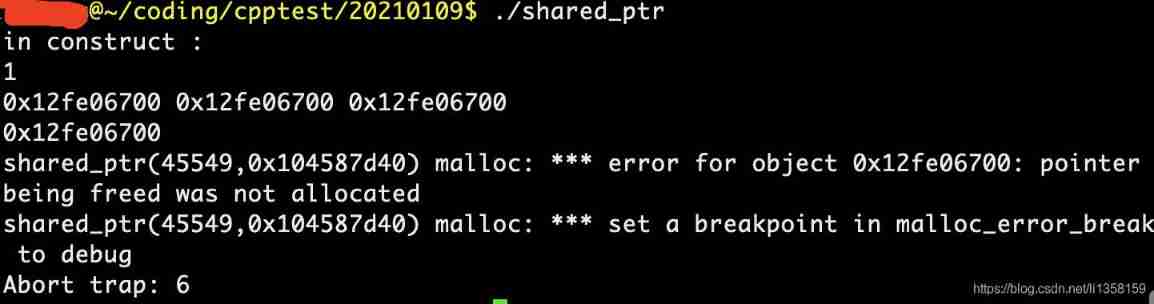
shared_ Repeated release heap object of PTR hidden danger
leetcode-6110:网格图中递增路径的数目
On the characteristics of technology entrepreneurs from Dijkstra's Turing Award speech

CF1634 F. Fibonacci Additions
![[article de jailhouse] jailhouse hypervisor](/img/f4/4809b236067d3007fa5835bbfe5f48.png)
[article de jailhouse] jailhouse hypervisor

Smart construction site "hydropower energy consumption online monitoring system"
网络工程师考核的一些常见的问题:WLAN、BGP、交换机

Full Permutation Code (recursive writing)
全排列的代码 (递归写法)
随机推荐
Règlement sur la sécurité des réseaux dans les écoles professionnelles secondaires du concours de compétences des écoles professionnelles de la province de Guizhou en 2022
CF1637E Best Pair
剑指 Offer 05. 替换空格
1041 Be Unique
Introduction to convolutional neural network
[jailhouse article] jailhouse hypervisor
The sum of the unique elements of the daily question
Introduction and experience of wazuh open source host security solution
Over fitting and regularization
【Rust 笔记】13-迭代器(下)
Little known skills of Task Manager
每日一题-搜索二维矩阵ps二维数组的查找
常见的最优化方法
Introduction et expérience de wazuh open source host Security Solution
CCPC Weihai 2021m eight hundred and ten thousand nine hundred and seventy-five
leetcode-556:下一个更大元素 III
1.15 - 输入输出系统
[jailhouse article] performance measurements for hypervisors on embedded ARM processors
Smart construction site "hydropower energy consumption online monitoring system"
Bit mask of bit operation