当前位置:网站首页>MIT-6874-Deep Learning in the Life Sciences Week 7
MIT-6874-Deep Learning in the Life Sciences Week 7
2022-07-05 05:51:00 【木姑娘】
Lecture 05 Interpretable Deep Learning
- 可解释性深度学习
- 一、Intro to Interpretability
- 1a. Interpretability definition: Convert implicit NN information to human-interpretable information
- 1b. Motivation: Verify model works as intended; debug classifier; make discoveries; Right to explanation
- 1c. Ante-hoc (train interpretable model) vs. Post-hoc (interpret complex model; degree of “locality”)
- 2. Interpreting Deep Neural Networks
- Evaluating Attribution Methods
- 3a. Qualitative: Coherence: Attributions should highlight discriminative features / objects of interest
- 3b. Qualitative: Class Sensitivity: Attributions should be sensitive to class labels
- 3c. Quantitative: Sensitivity: Removing feature with high attribution --> large decrease in class probability
- 3d. Quantitative: ROAR & KAR. Low class prob cuz image unseen --> remove pixels, retrain, measure acc. drop
可解释性深度学习
本节讨论的是深度学习的可解释性。模型本身意味着知识,可解释性对于如深度学习这样的“黑盒模型”而言,是解释其为何做出如此判断的原因和方法的根本所在,能够帮助模型朝着人类预期的方向工作。在许多场景,如推荐、医疗等场景有很大的应用前景。
以下是本节课的提纲
一、Intro to Interpretability
1a. Interpretability definition: Convert implicit NN information to human-interpretable information
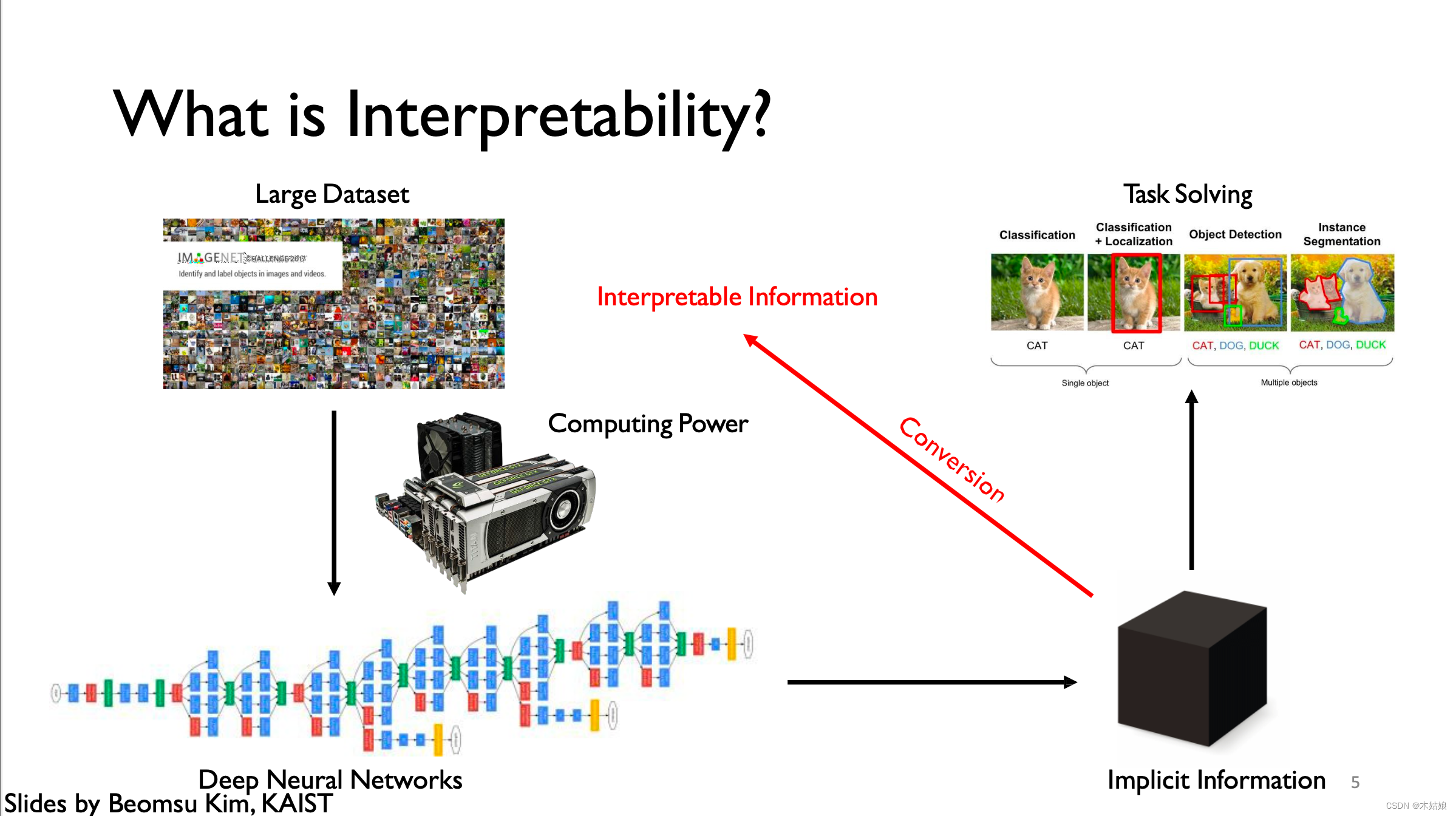
1b. Motivation: Verify model works as intended; debug classifier; make discoveries; Right to explanation
Why Interpretability?
- 1.Verify that model works as expected: Wrong decisions can be costly and dangerous
- 2. Improve / Debug classifier
- 3. Make new discoveries
- 4.Right to explanation
“Right to be given an explanation for an output of the algorithm”
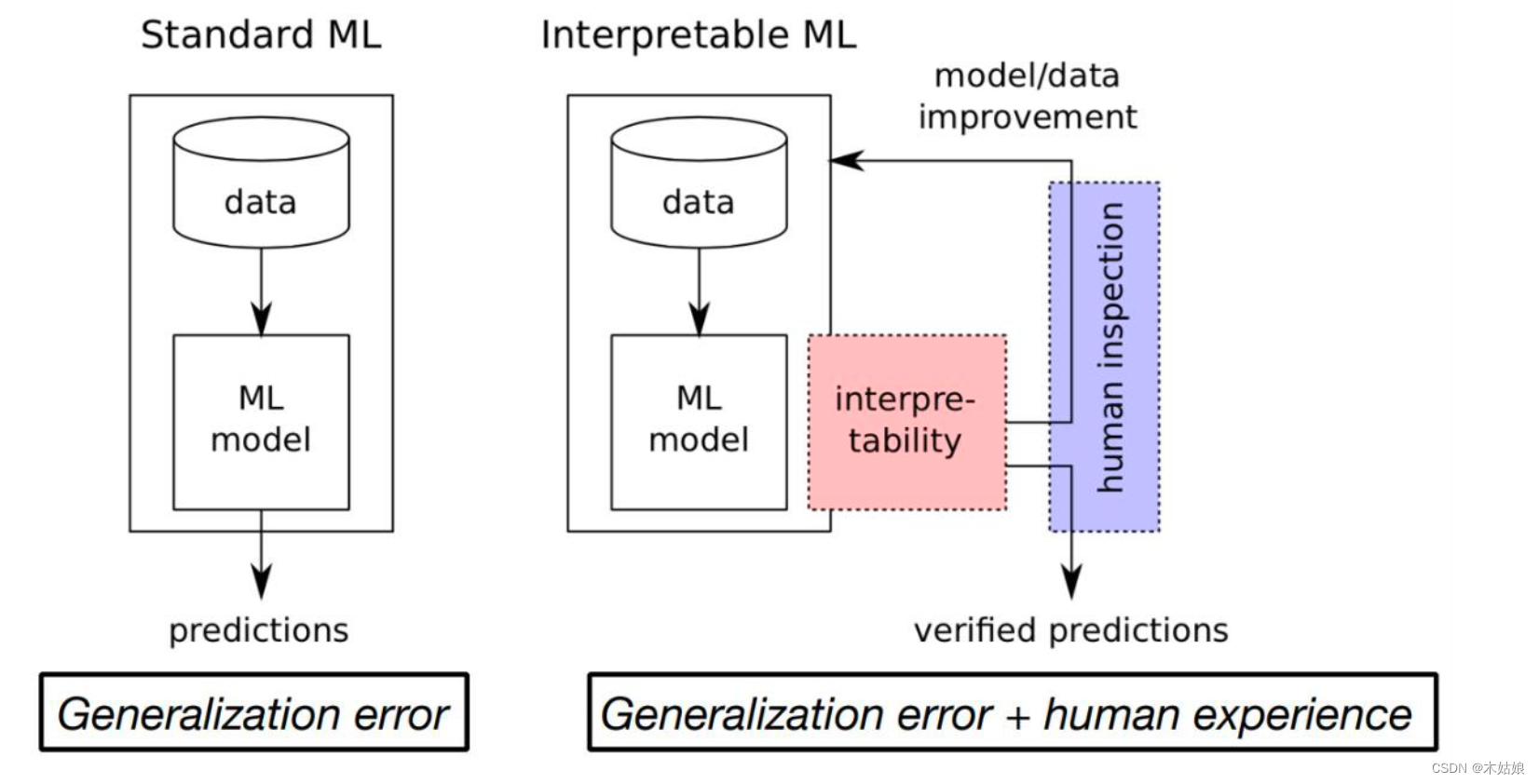
1c. Ante-hoc (train interpretable model) vs. Post-hoc (interpret complex model; degree of “locality”)
获得模型可解释性的两种方法(即可解释性的分类)
- Ante-hoc & Post-hoc
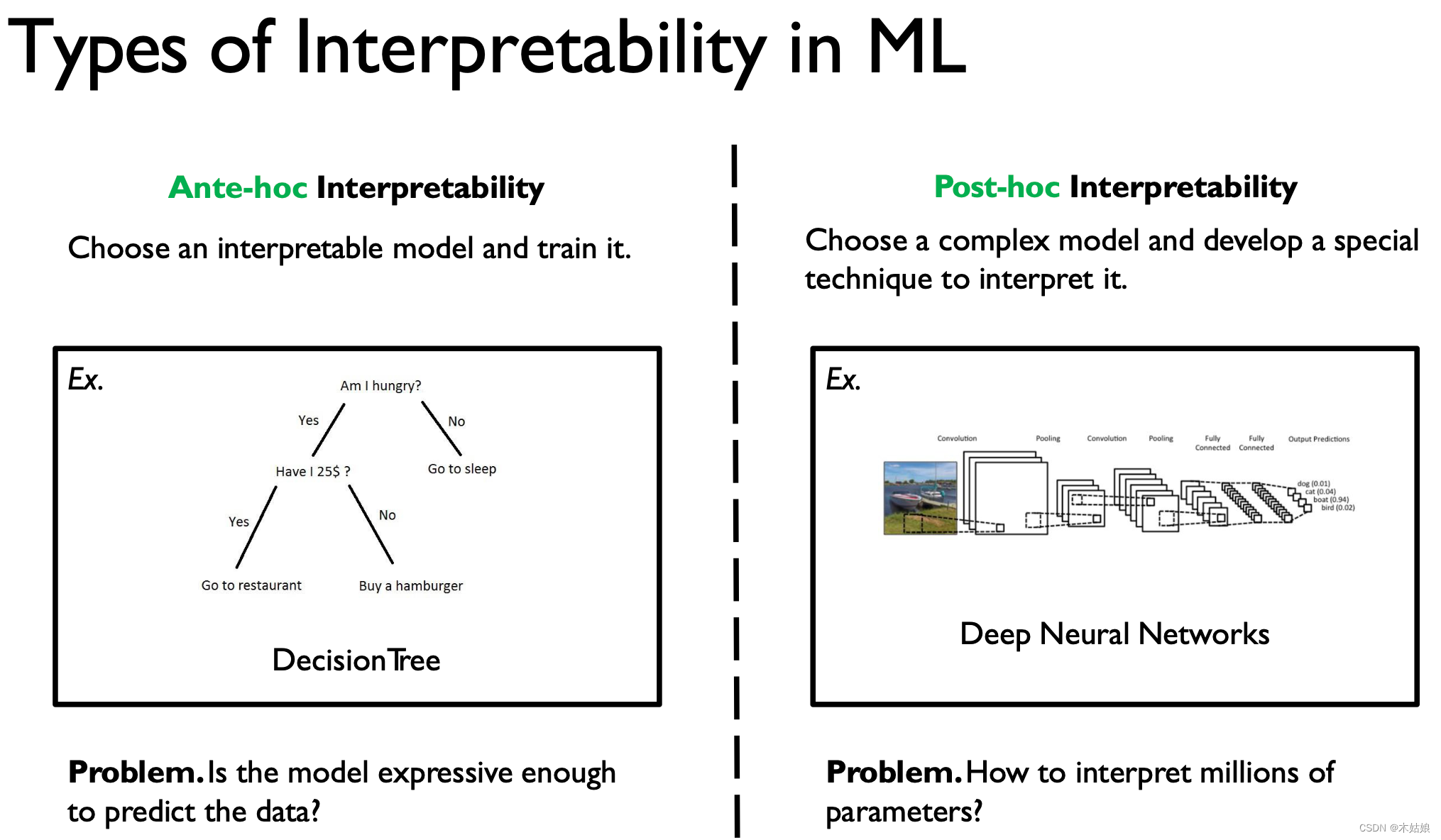
1. Ante-hoc 可解释性——事先可解释性(模型内置可解释性)
通过训练一个自认具有可解释的模型,以获得对结果的解释。
常见的可解释模型:
- 朴素贝叶斯
- 线性回归
- 决策树
- 基于规则的模型
但是这类模型可达的复杂程度有限,从而导致其根本上的性能受限
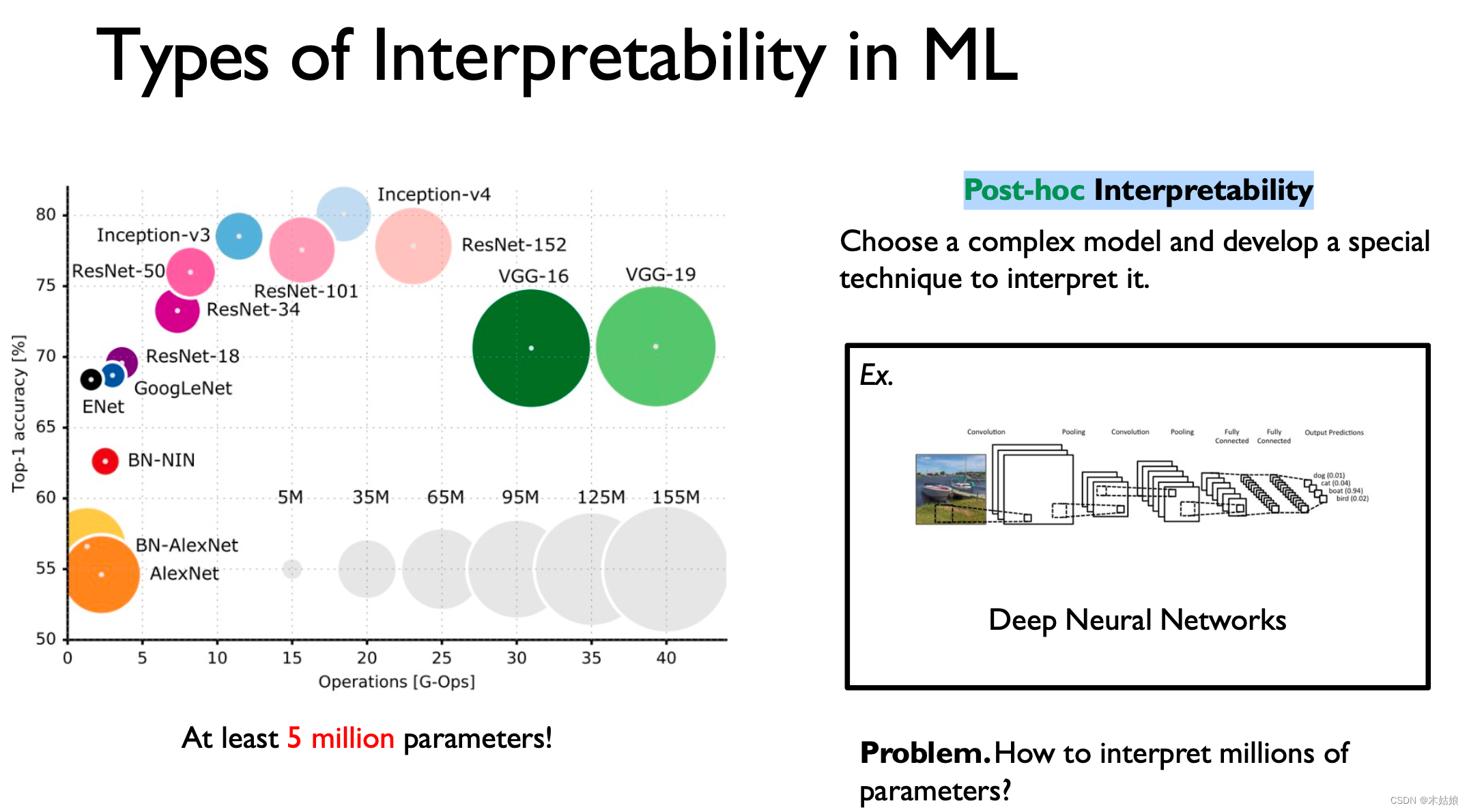
2. Post-hoc Interpretability——事后可解释性
指对于黑盒模型,通过某些方法,体现出他的决策逻辑
可解释性的几个级别:
- 模型级别的可解释:DNN模型为什么要如此决定决策边界
- 特征的可解释性:哪一部分特征能最大化的激活当前的模型
- 走向单个个体的可解释:解释为何这个输入会被如此分类

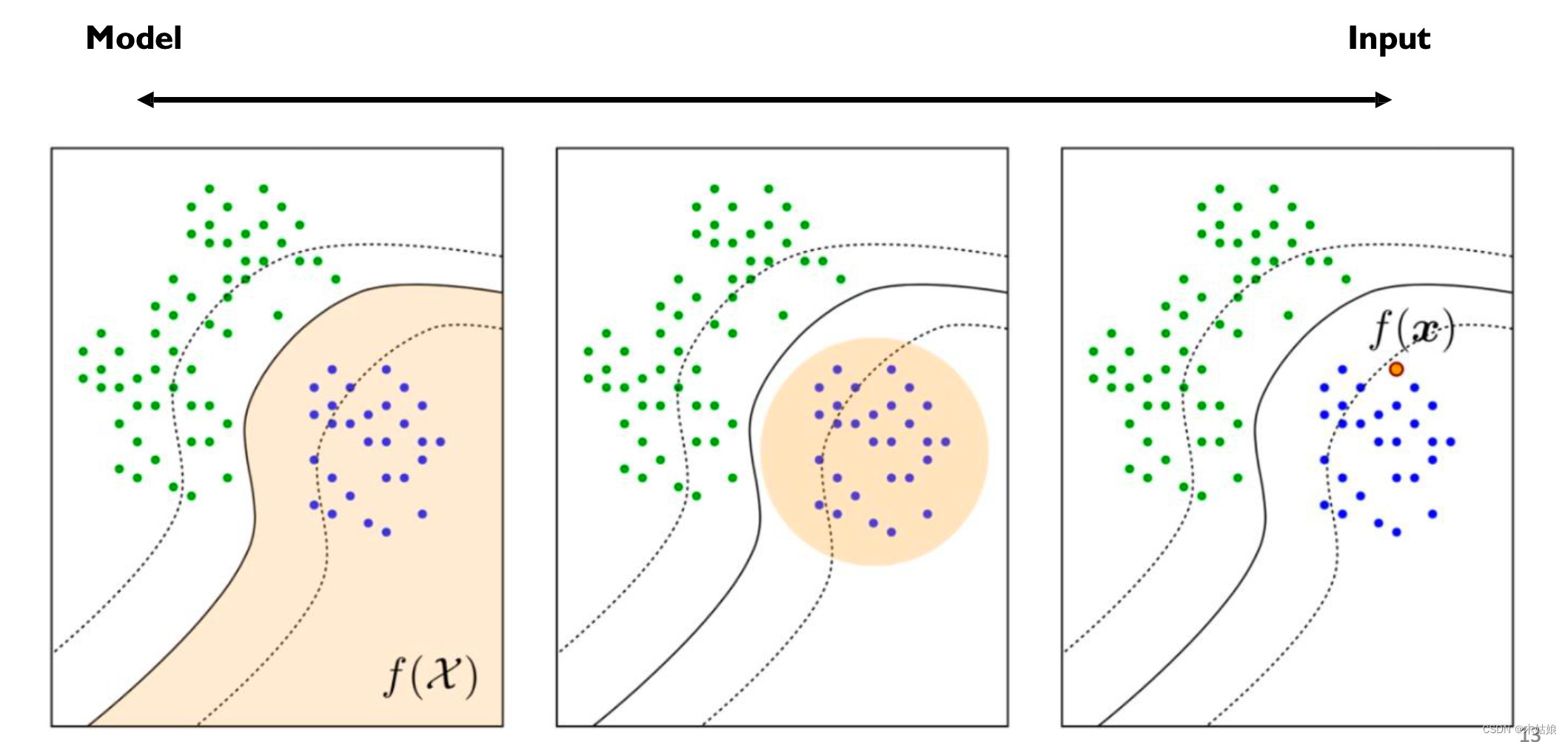
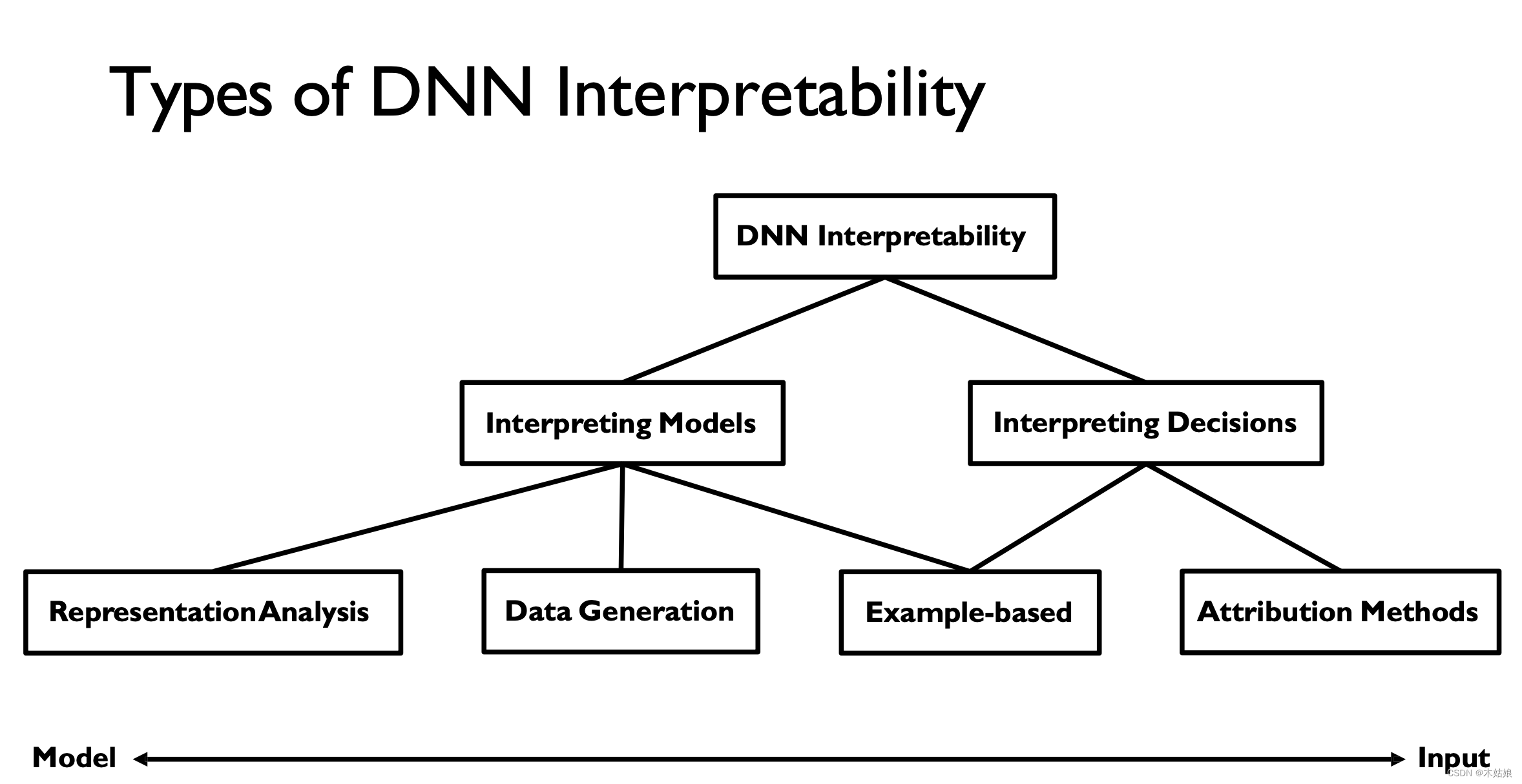
2. Interpreting Deep Neural Networks
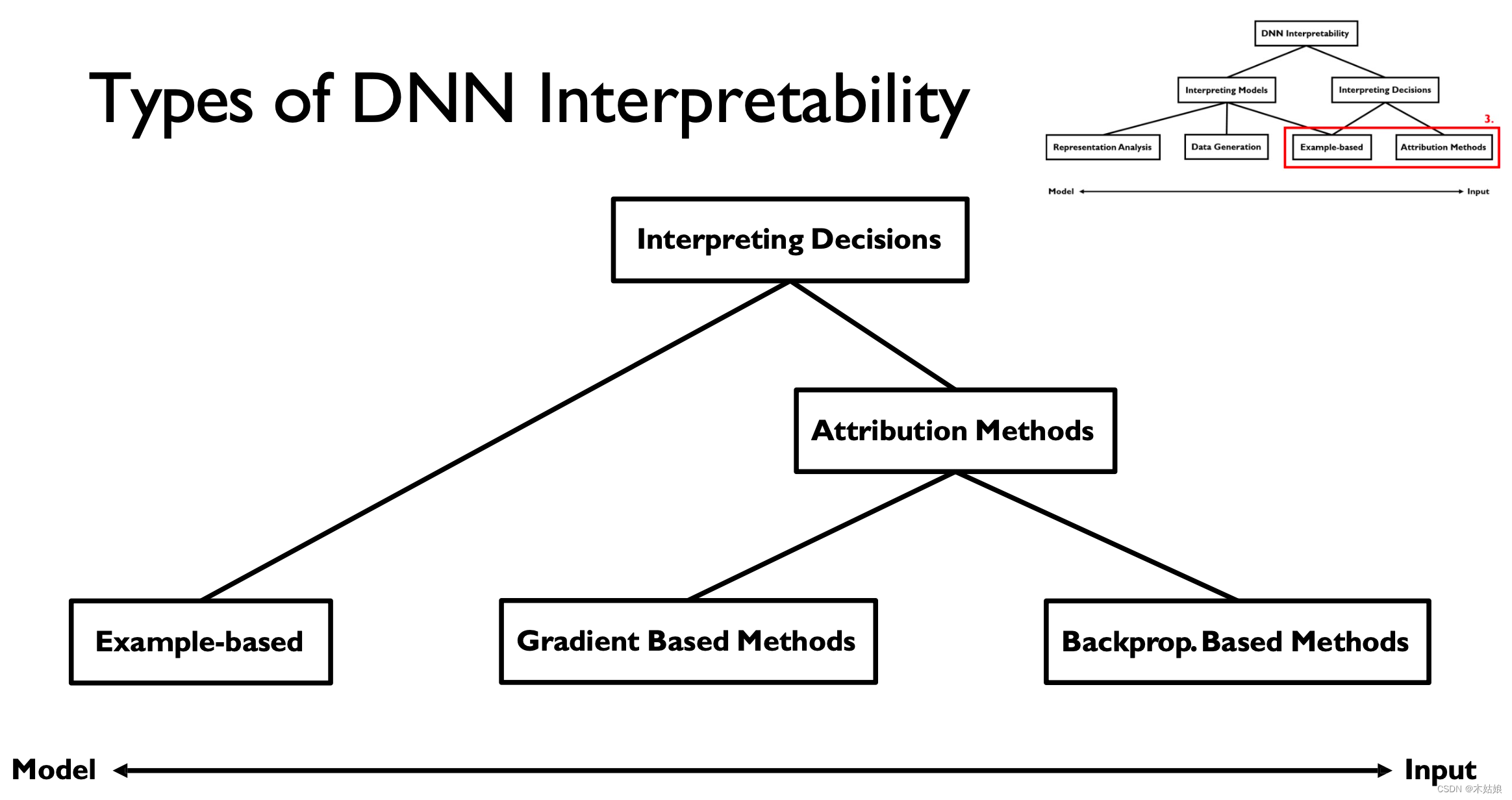
2a. Interpreting Models (macroscopic, understand internals) vs. decisions (microscopic, practical applications)
(课程走向)模型可解释性的几种分类
- Interpreting decisions:
- Attribution method: 什么属性决定了模型当前的输出
- Example-based: 什么特殊的案例导致模型当前的输出
- Interpreting models:
- Representation analysis: 模型表示本身
- Data generation:如何使用模型生成数据
- Example-based:相关案例
DNN interpretability 可以分为宏观和微观两个层面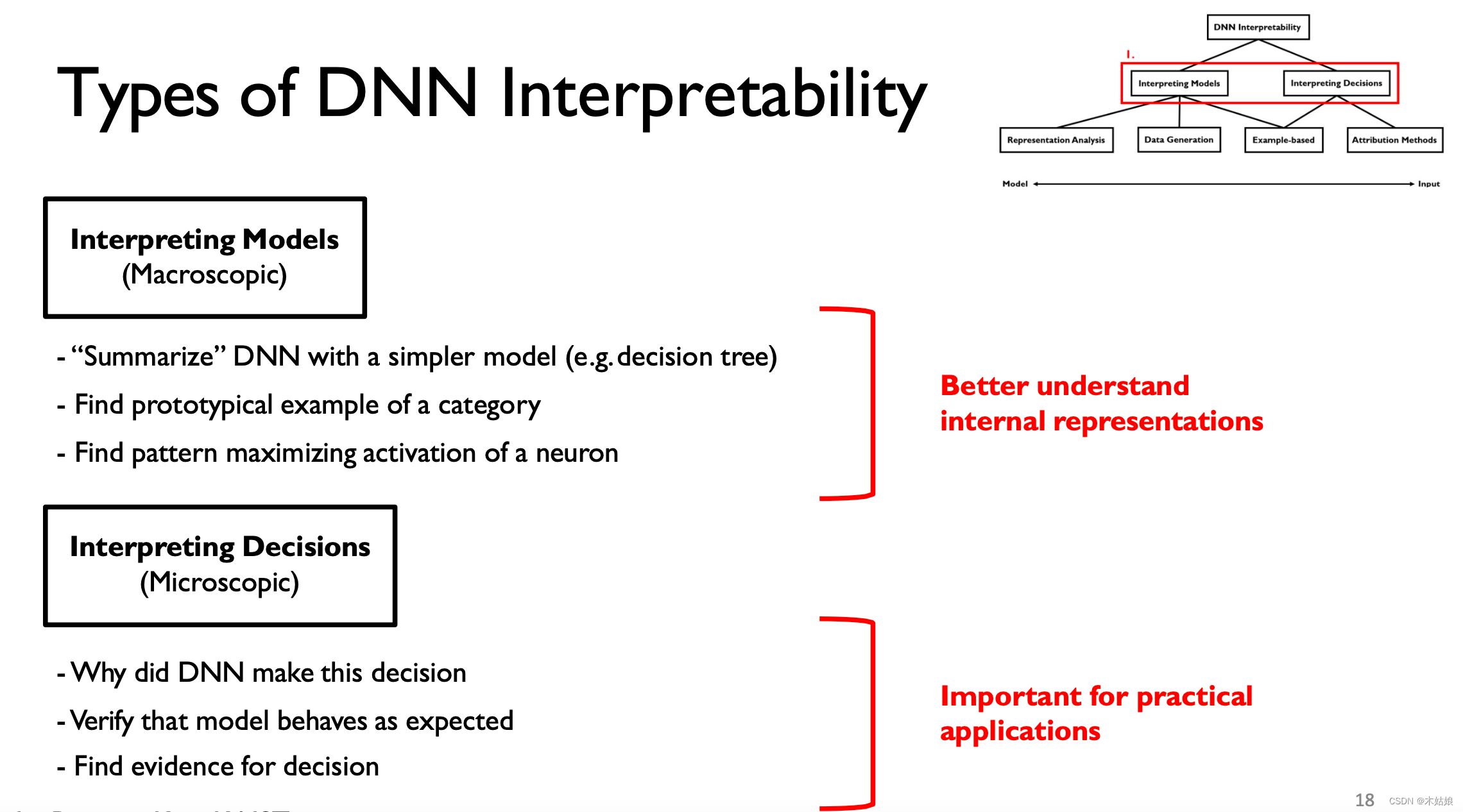
Interpreting models 又可以分为以下四个方面,其中 对于表示的分析可以分为权重可视化和代理模型
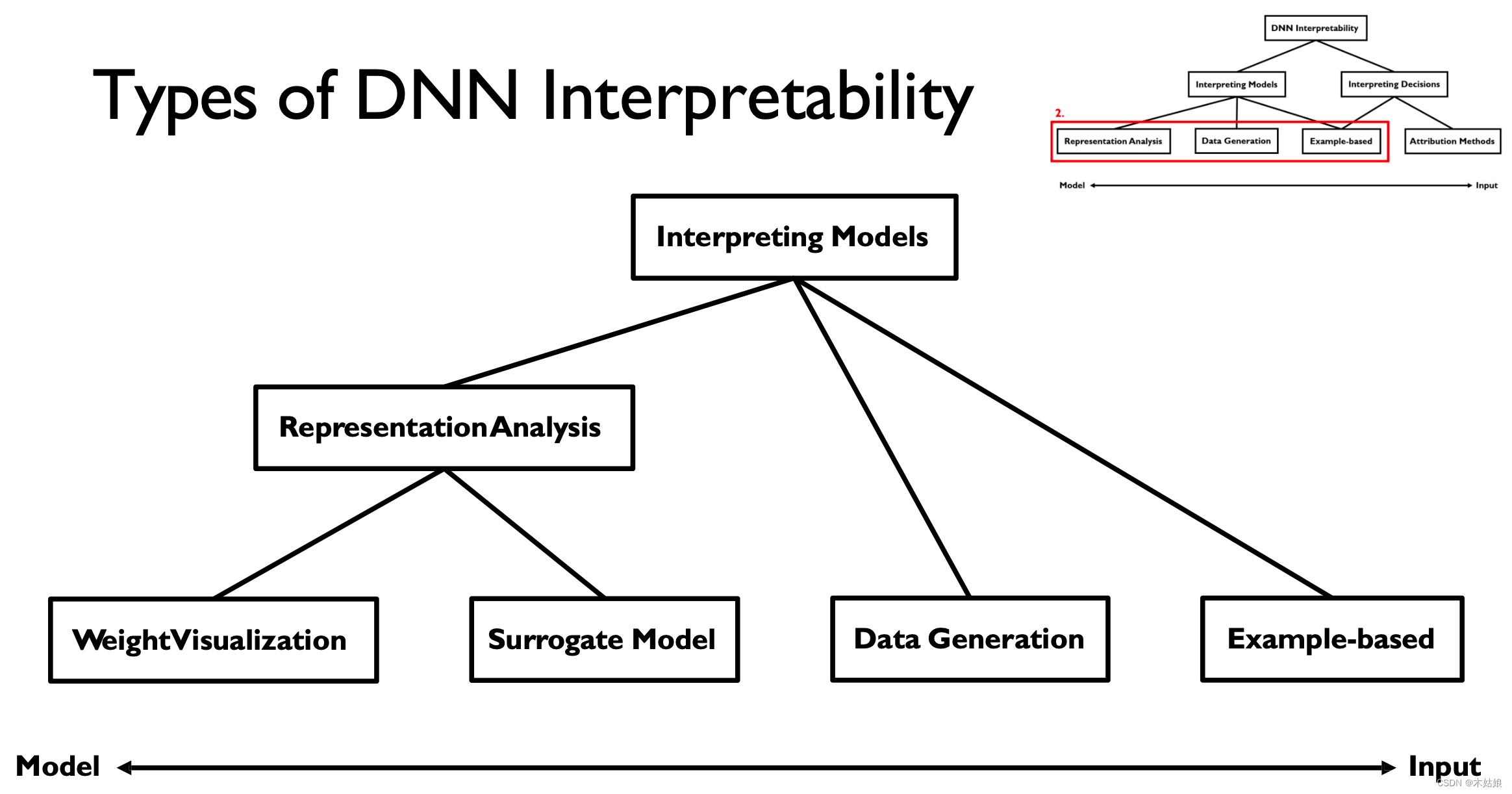
2b. Interpreting Models: Weight visualization, Surrogate model, Activation maximization, Example-based
1. Weight visualization 权重可视化
对CNN的每一层滤波器进行可视化,以理解模型在当前层在学习什么东西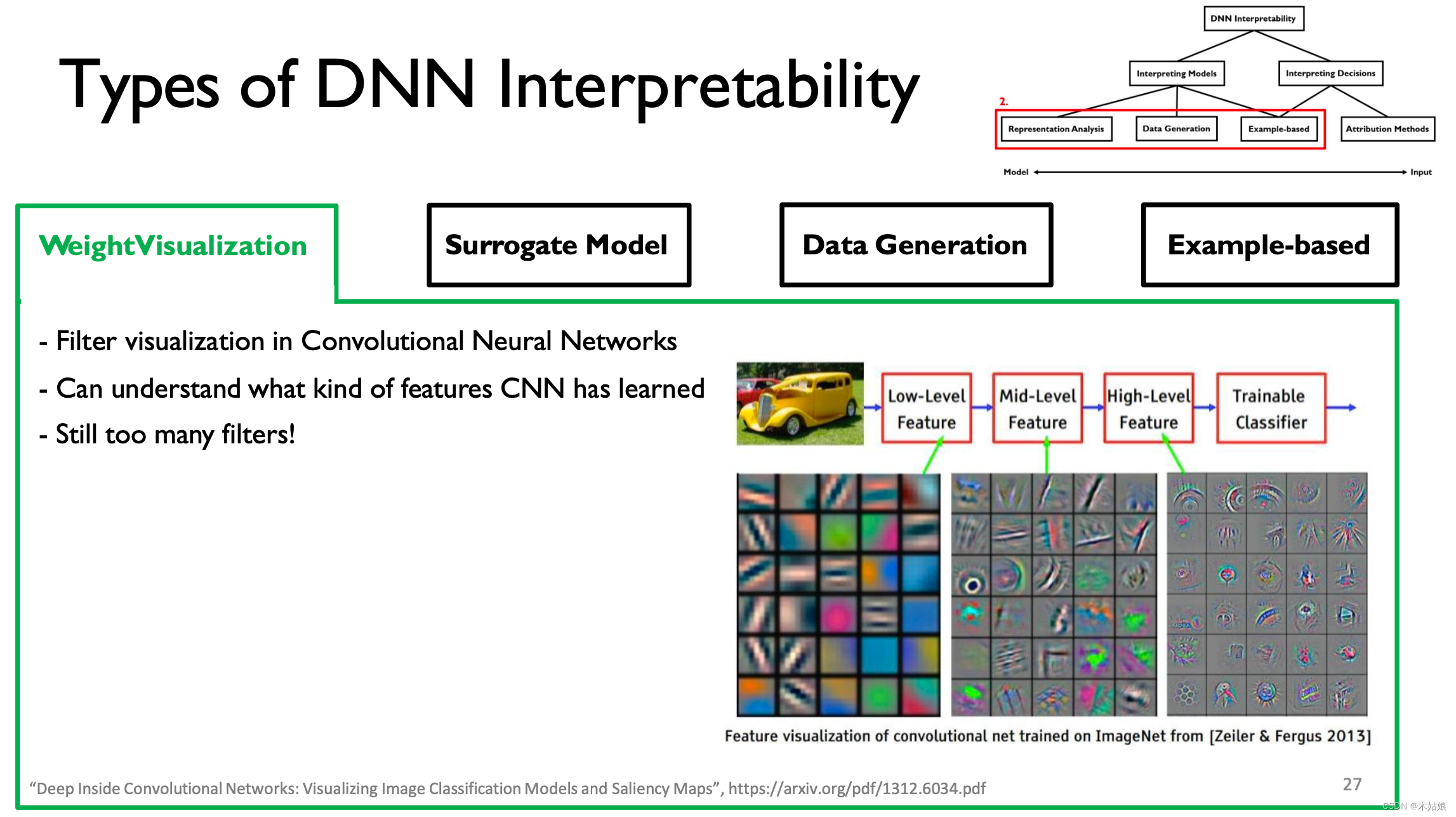
2. Surrogate model 代理模型
使用一个简单的,“可解释的”模型来“summarize”模型的 输出,试图解释“black box”的输出。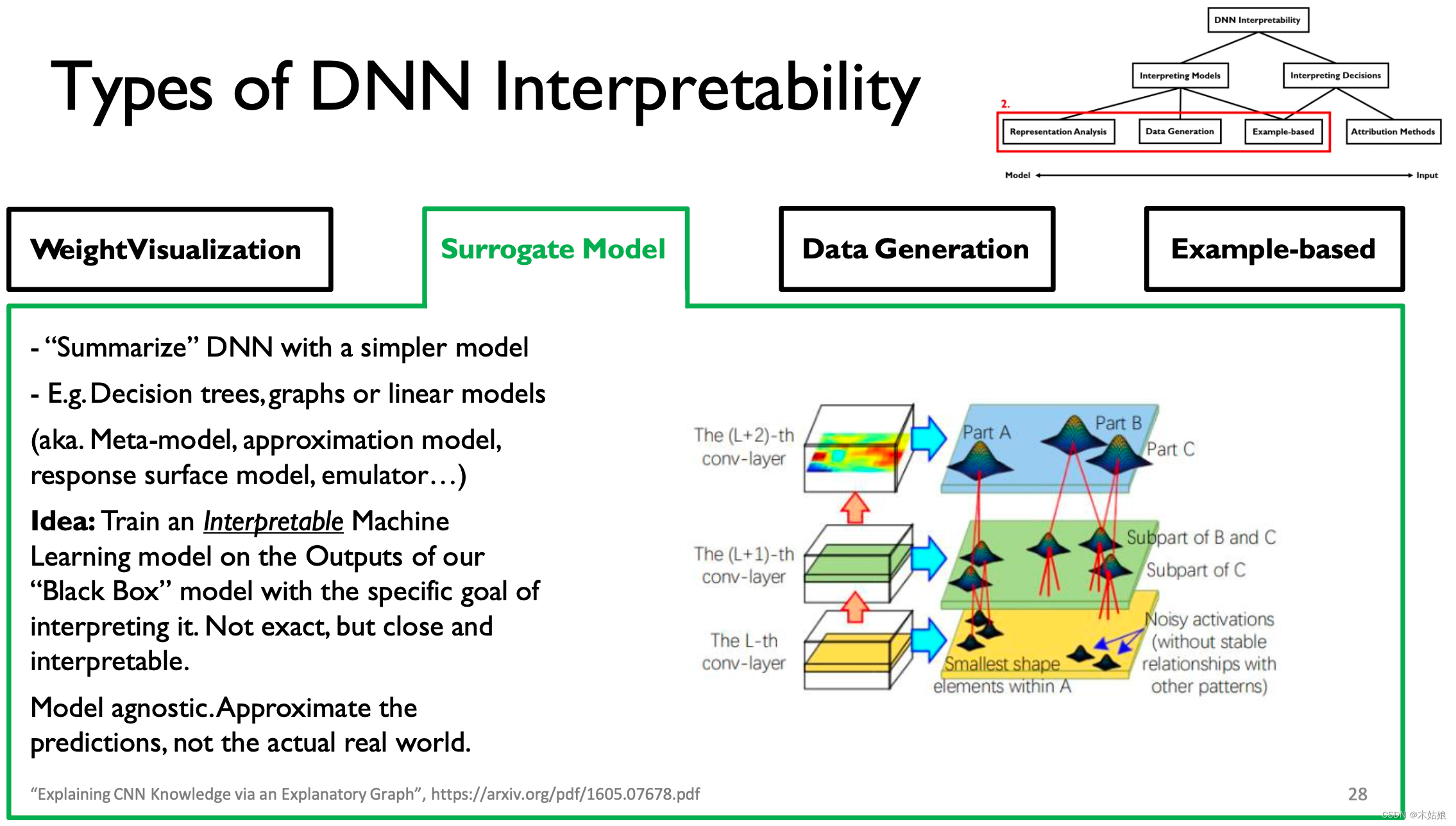
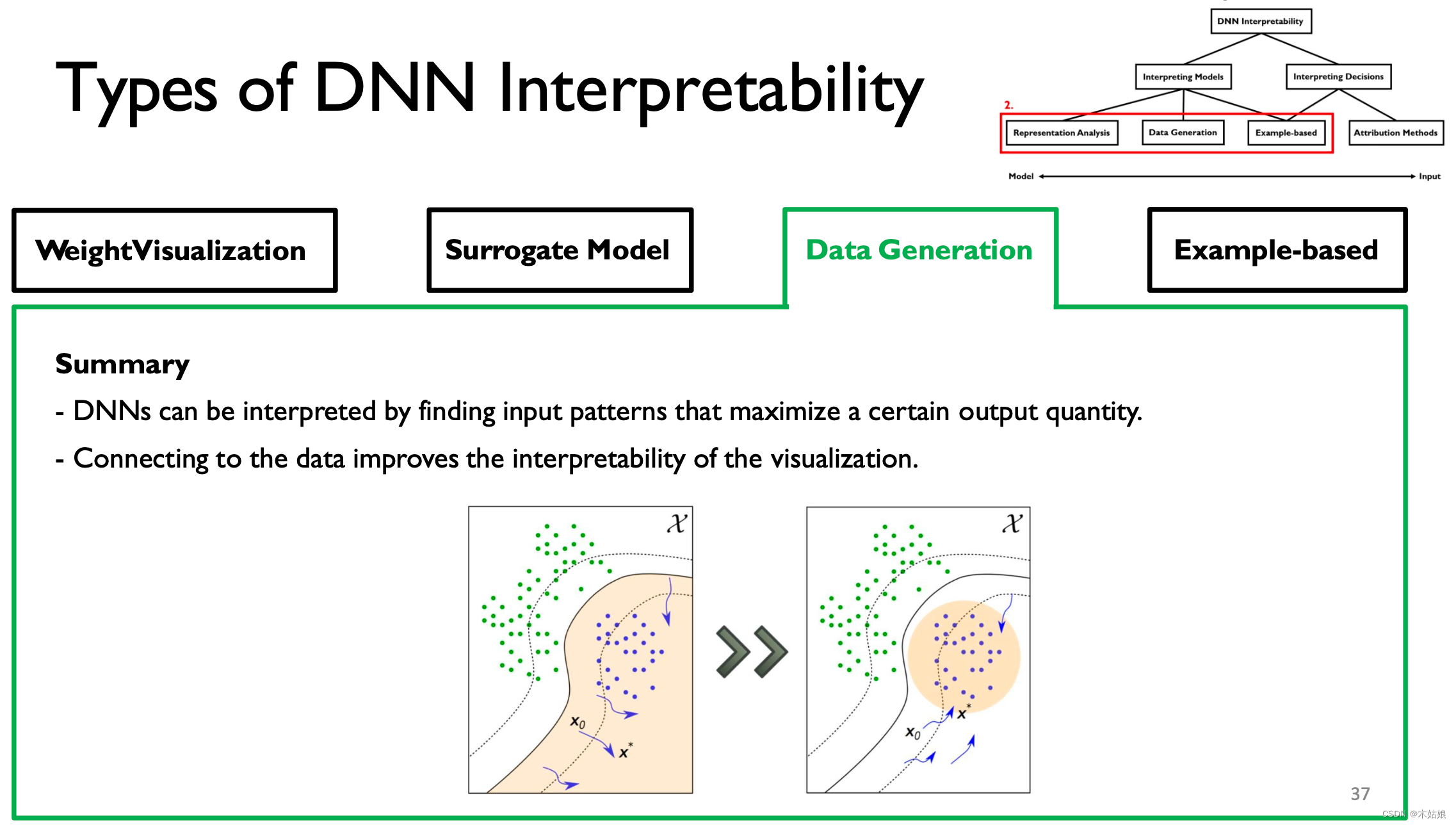
3. Data Generation / Activation maximization 数据生成 / 激活最大化
激活最大化:找到最大程度激活神经元的方式,即找到输入X,使模型在当前类别下的概率最大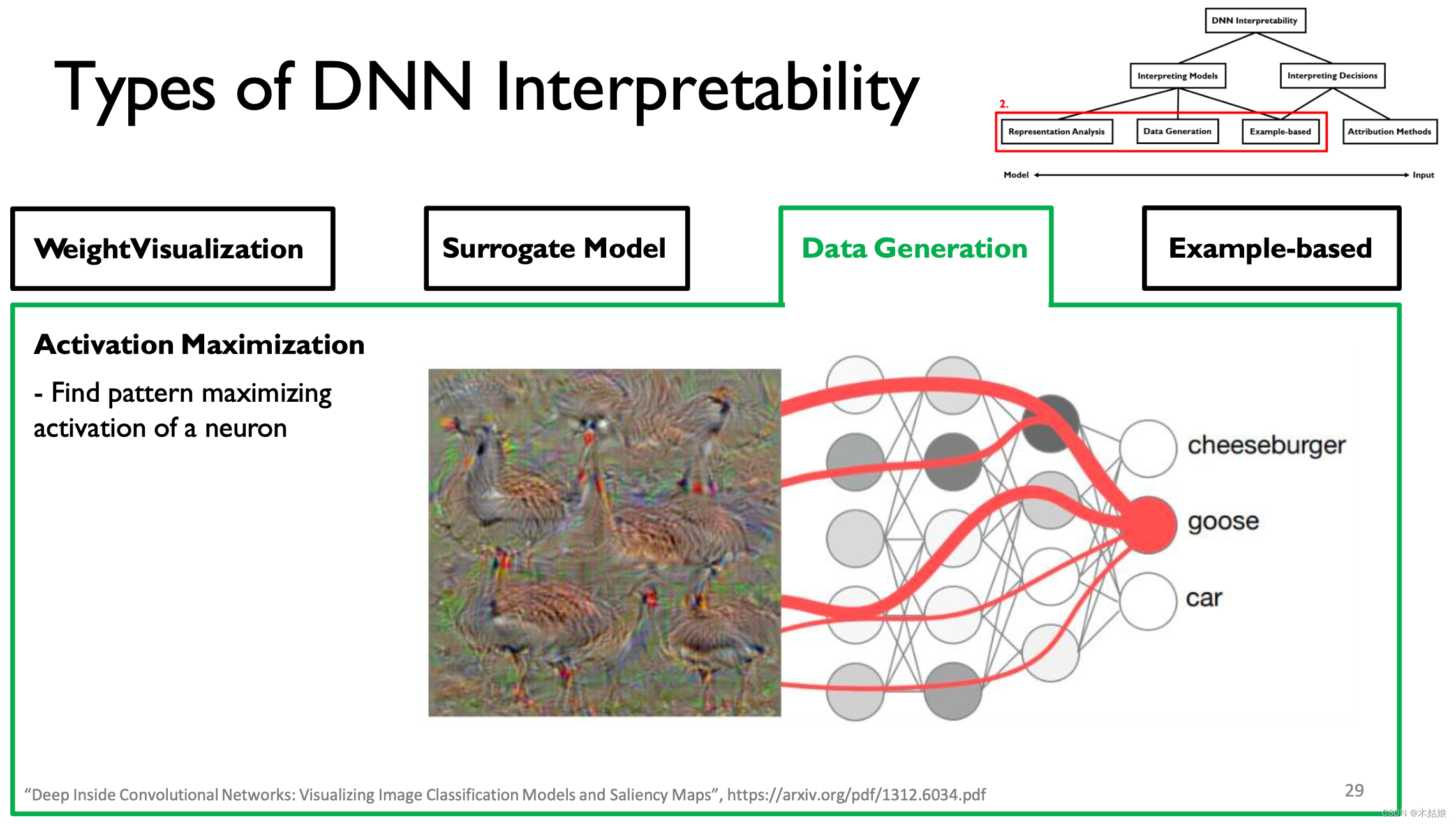
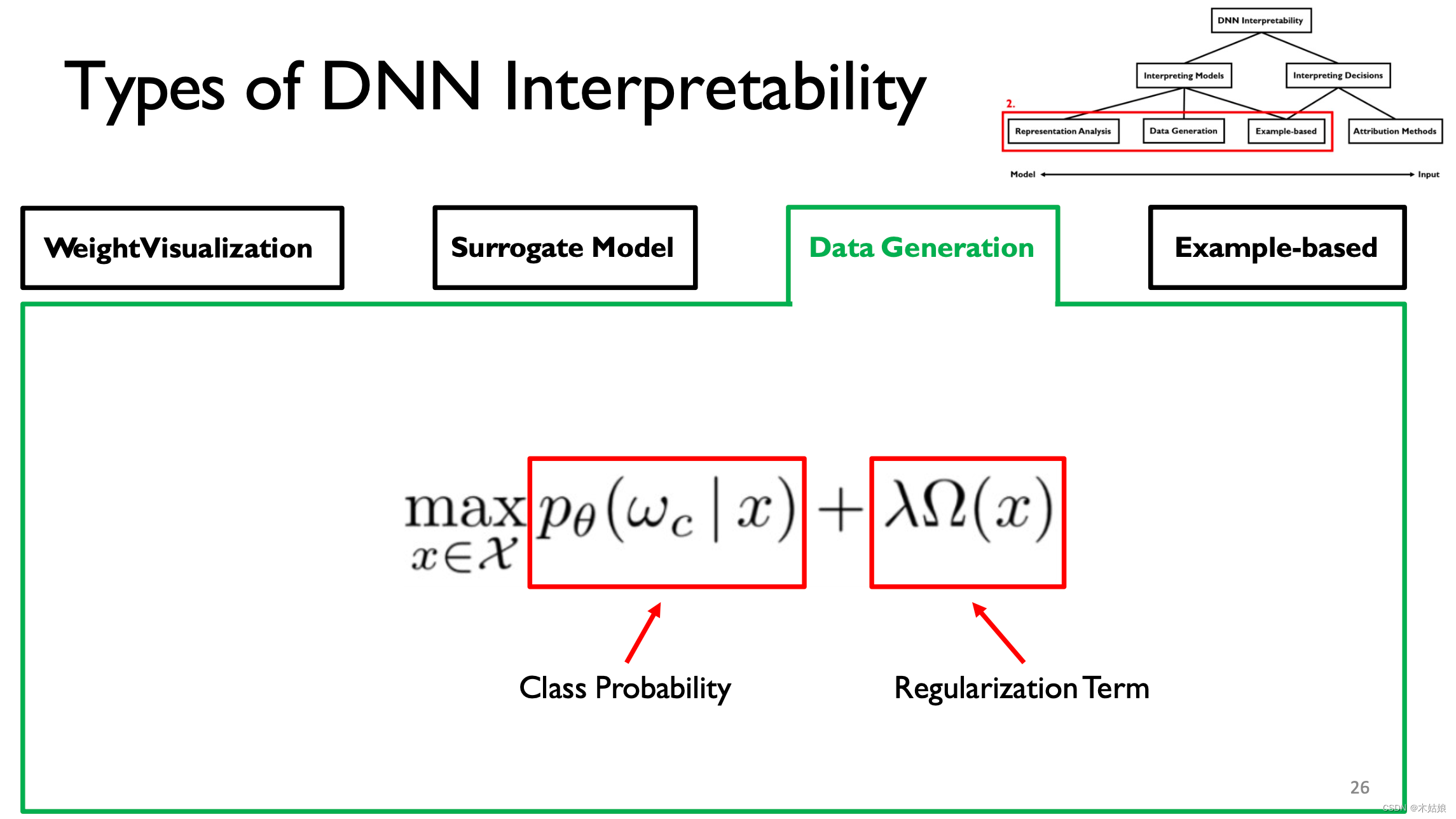
模型的卷积与解卷积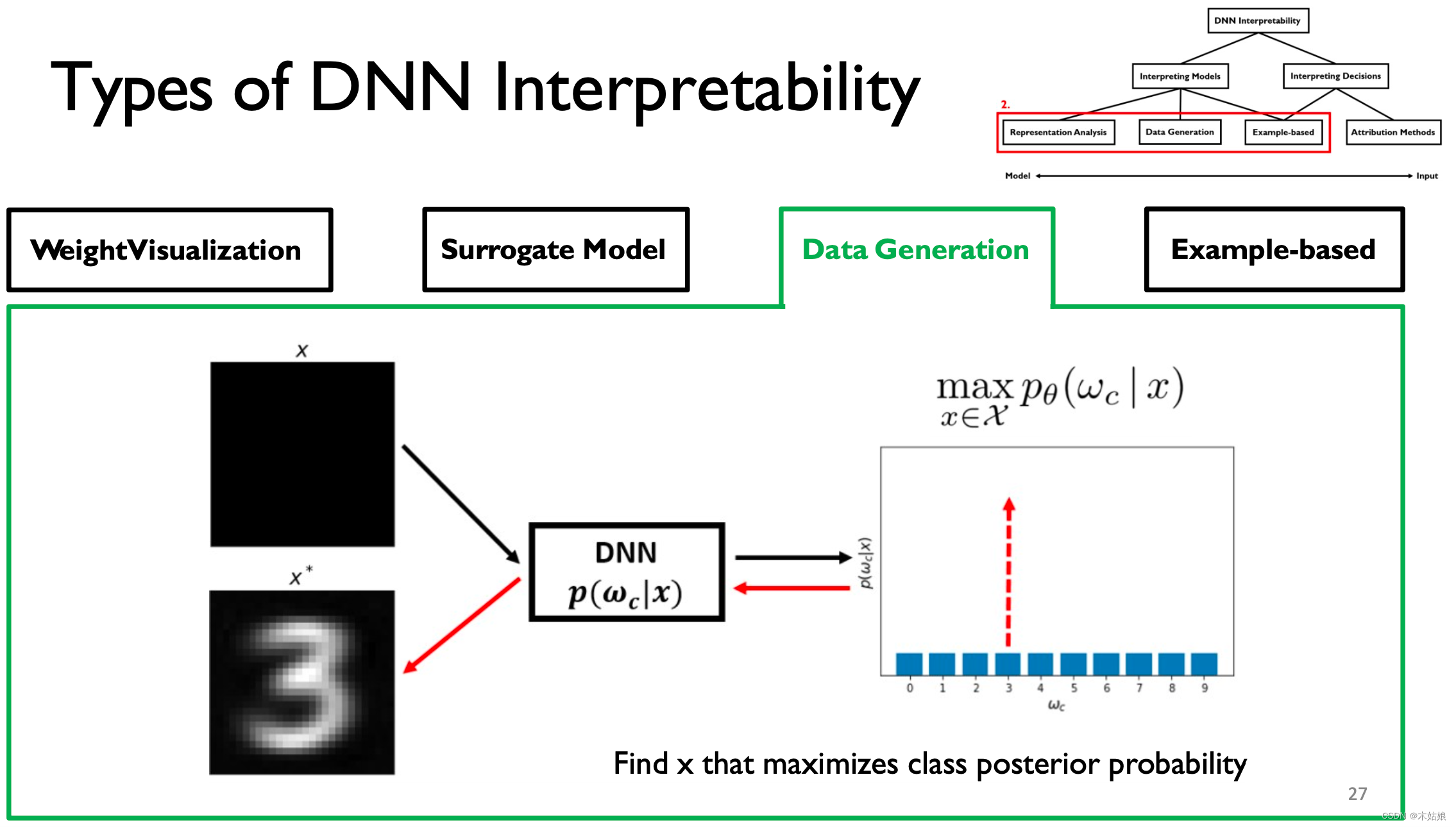
刚开始的输入是混沌的,随着训练层数的增加,渐渐可以分辨数字之间的特征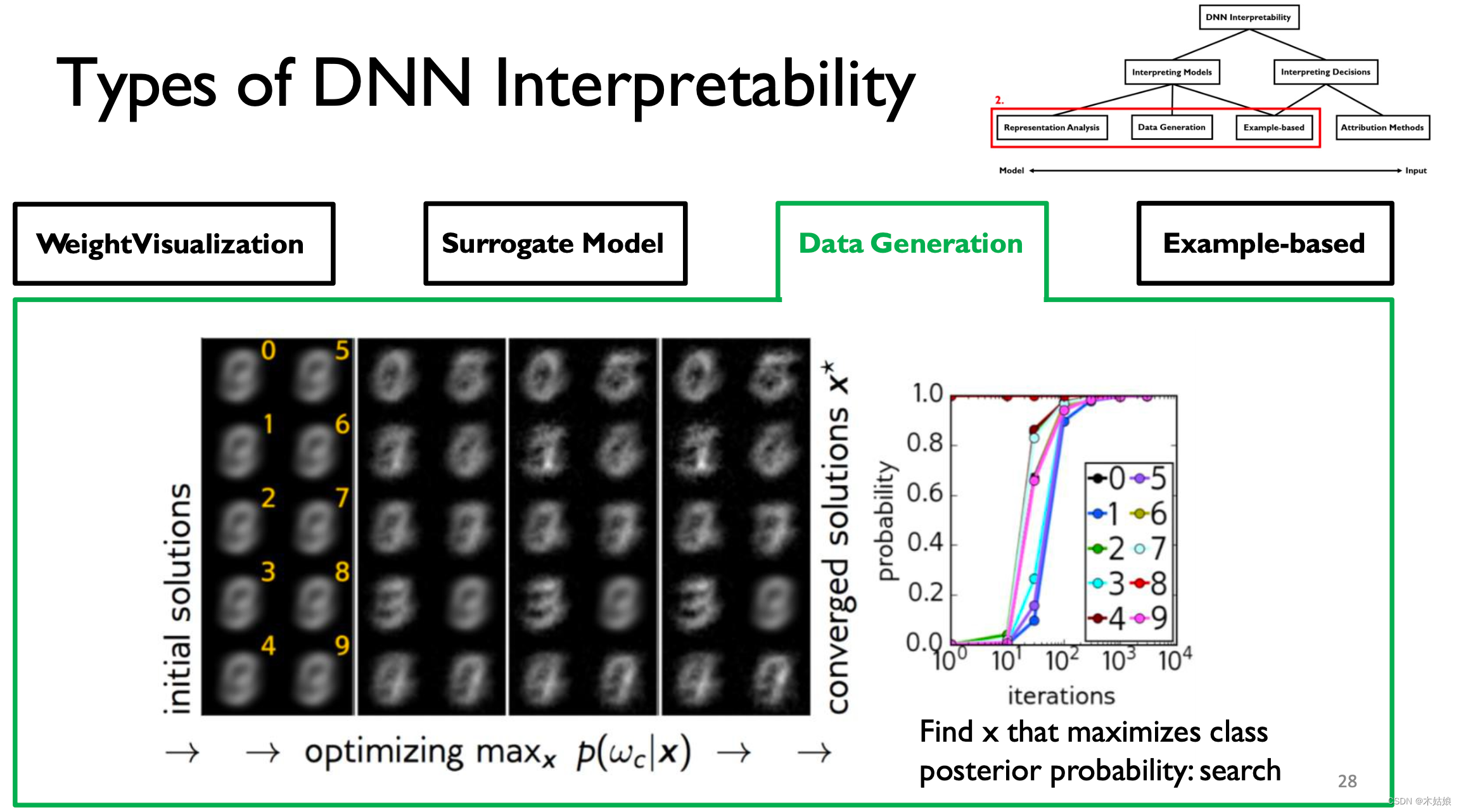
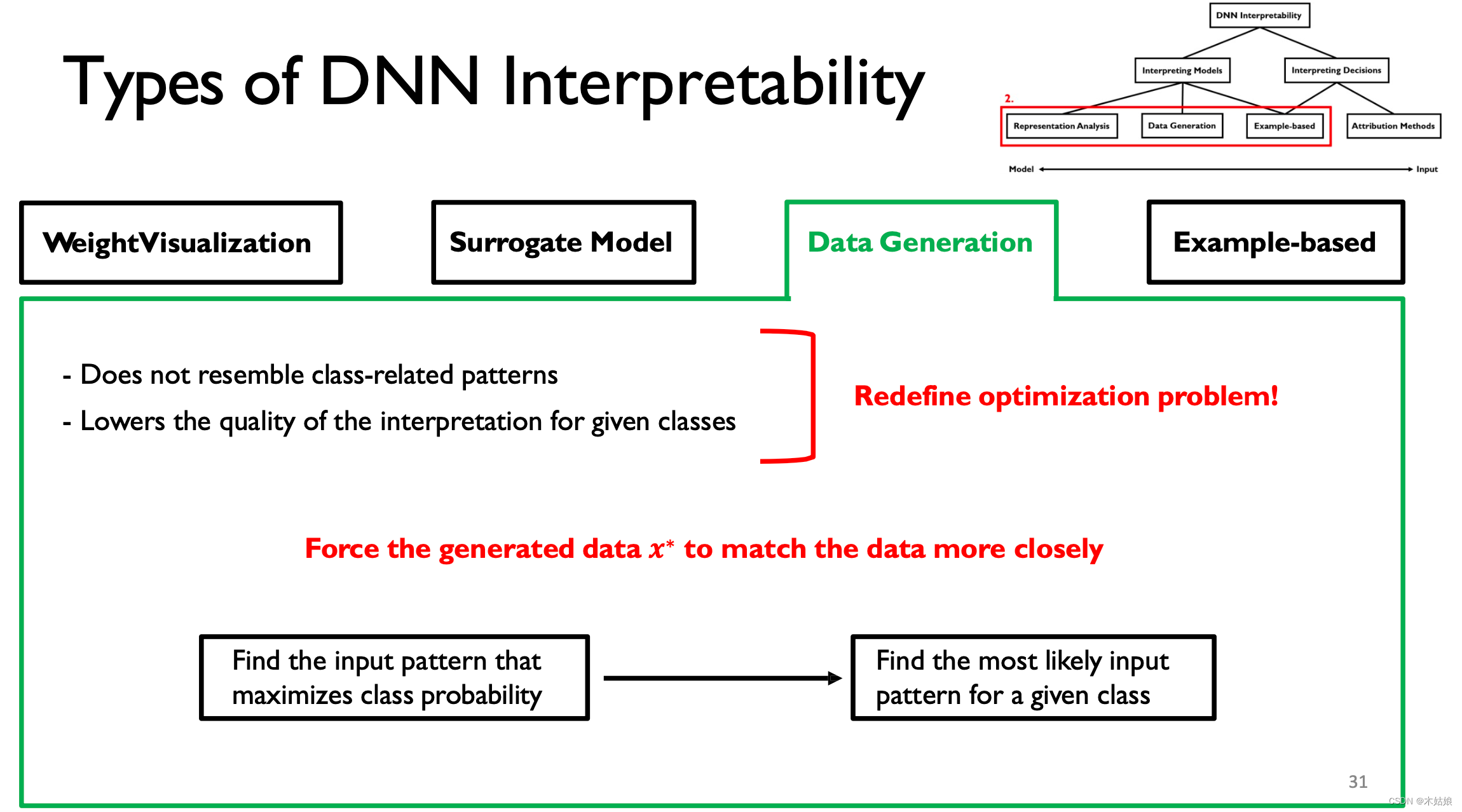
优点:这种做法的优点和缺点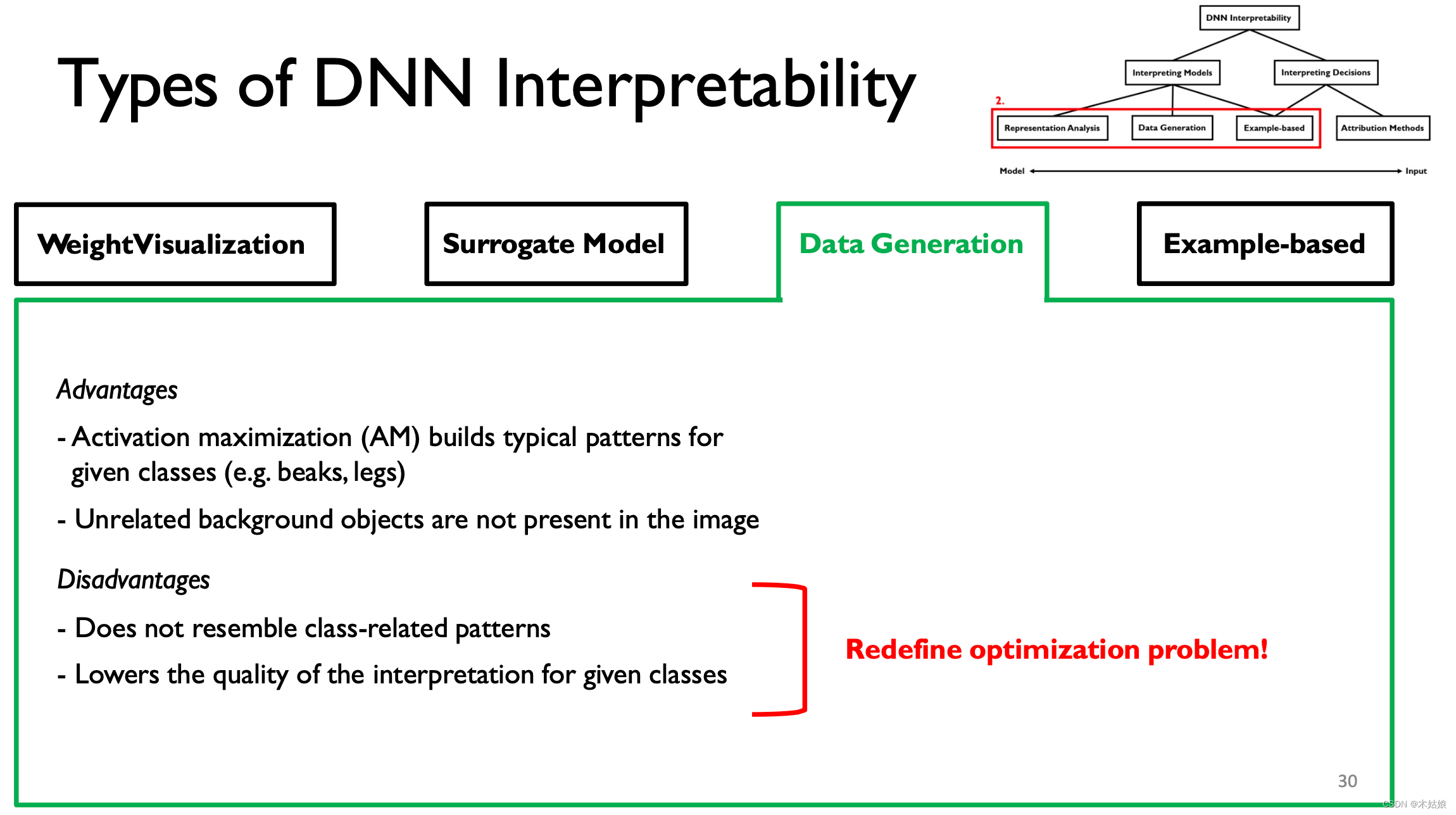
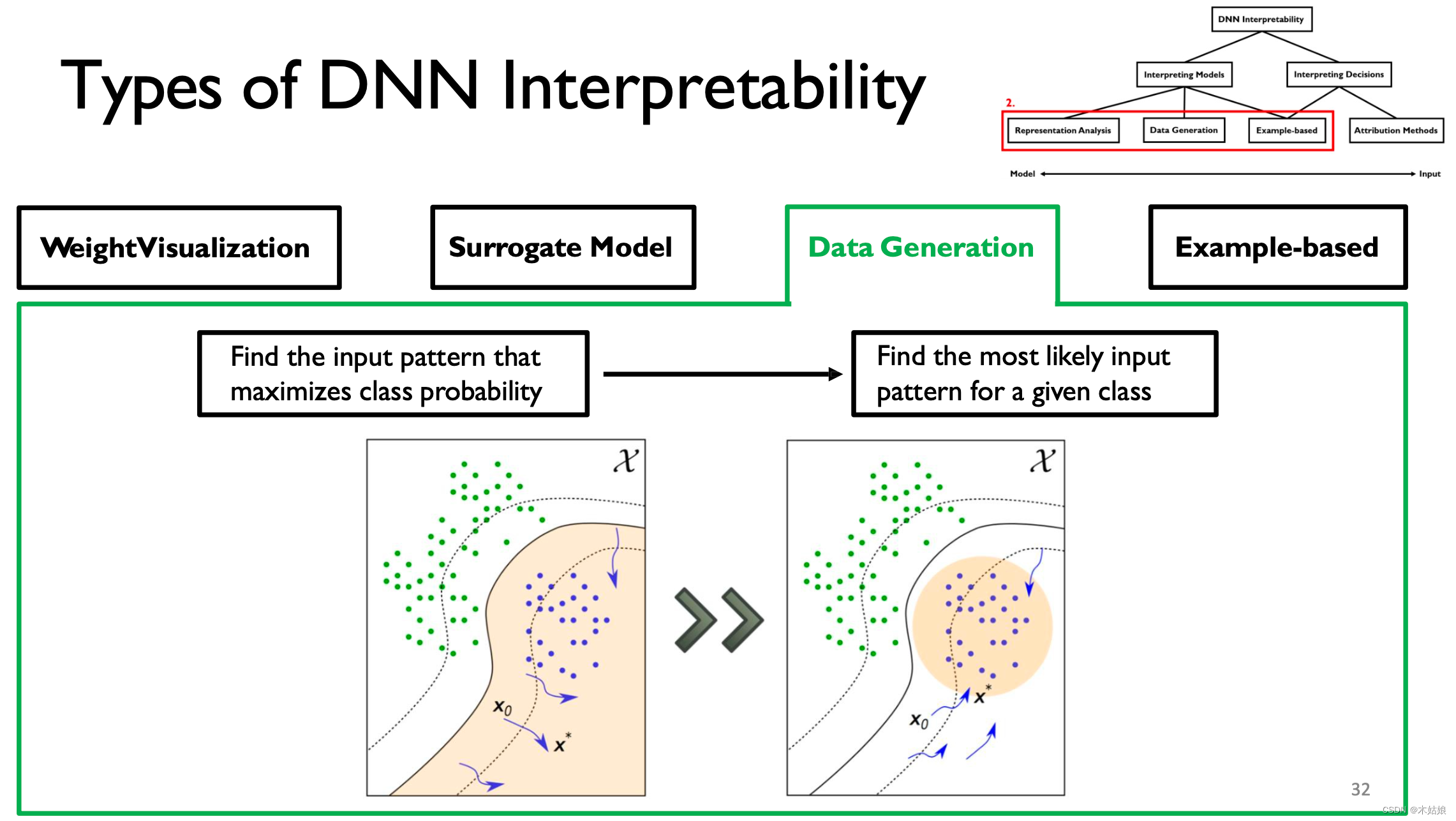
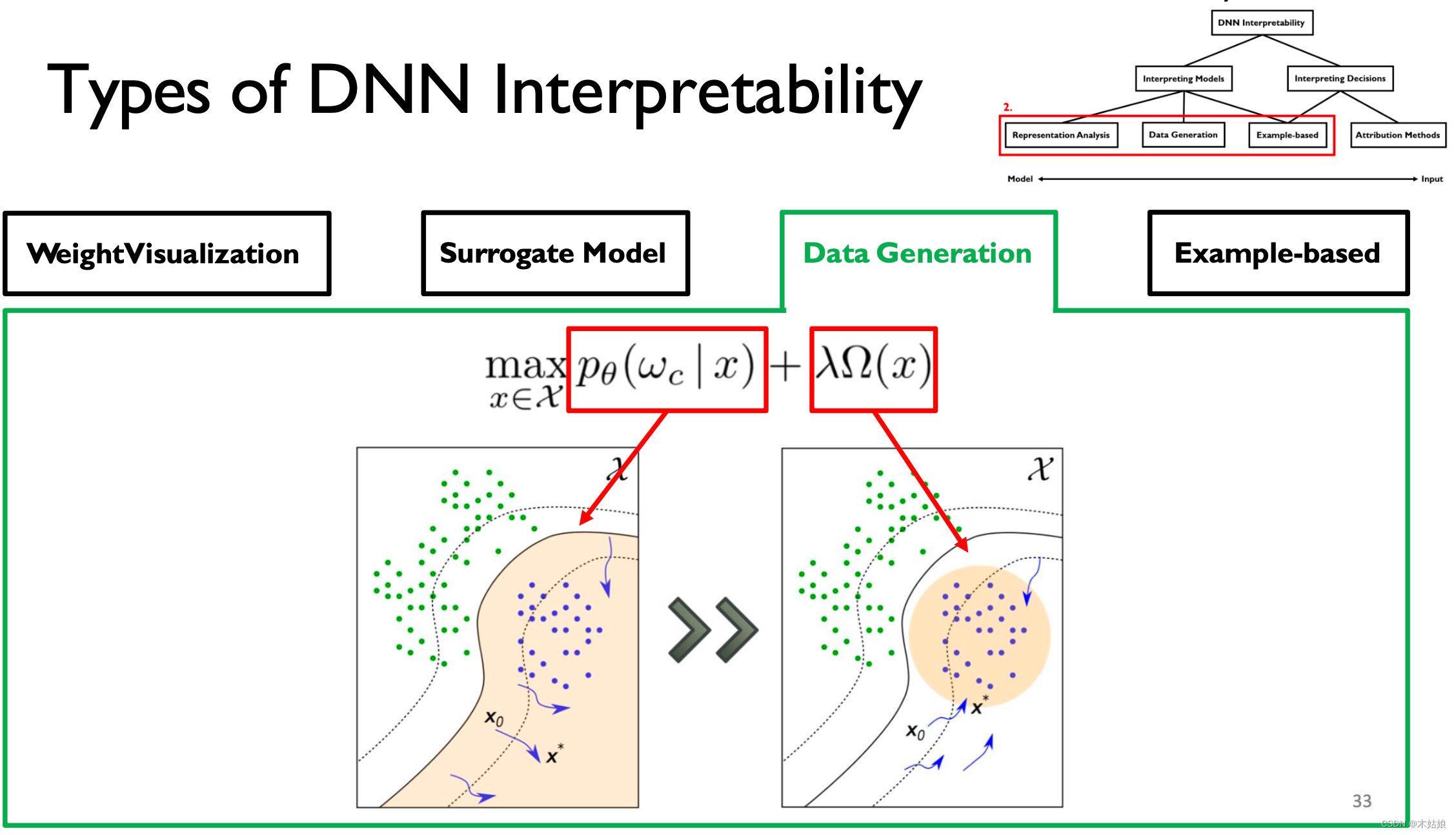
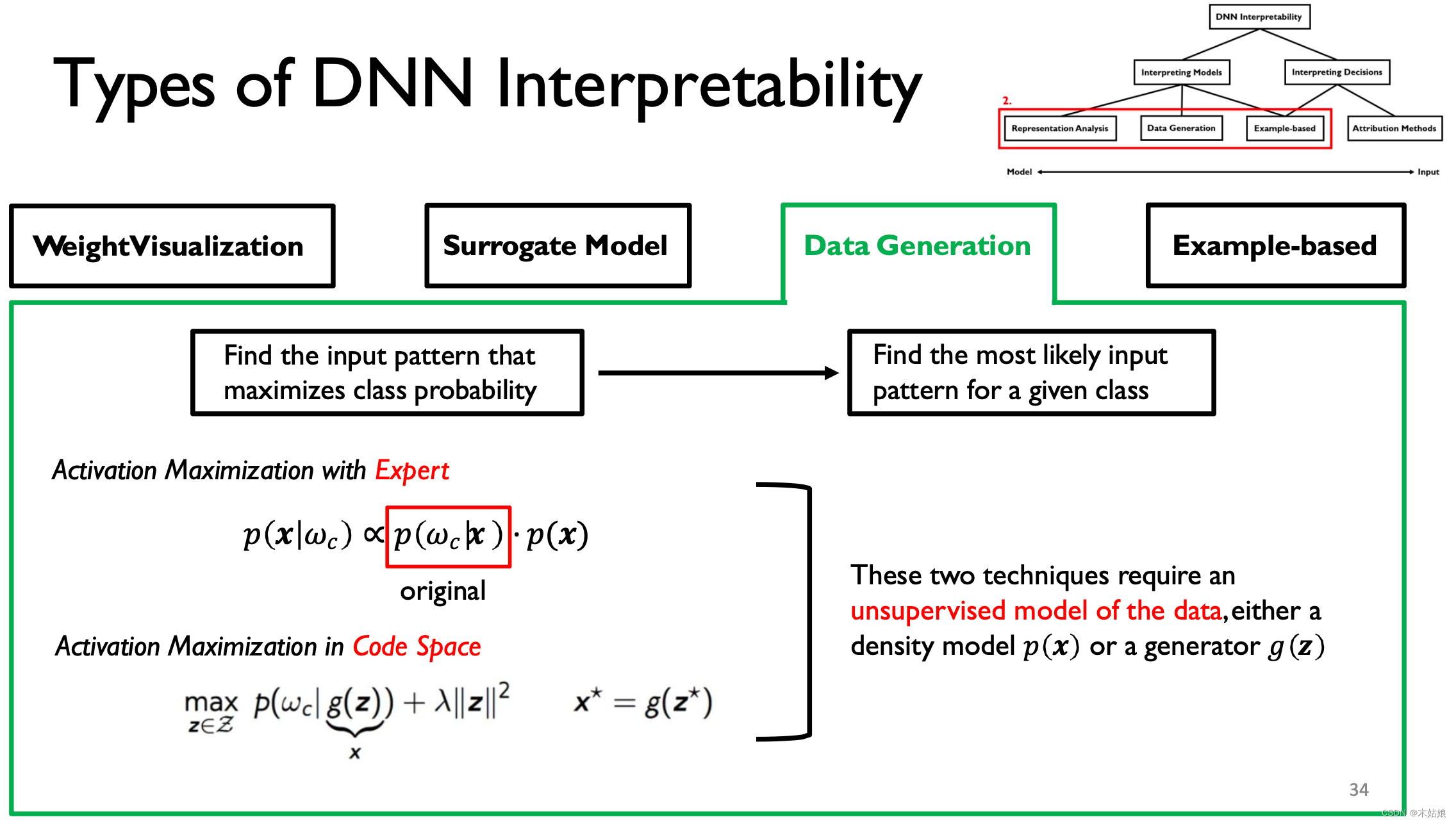
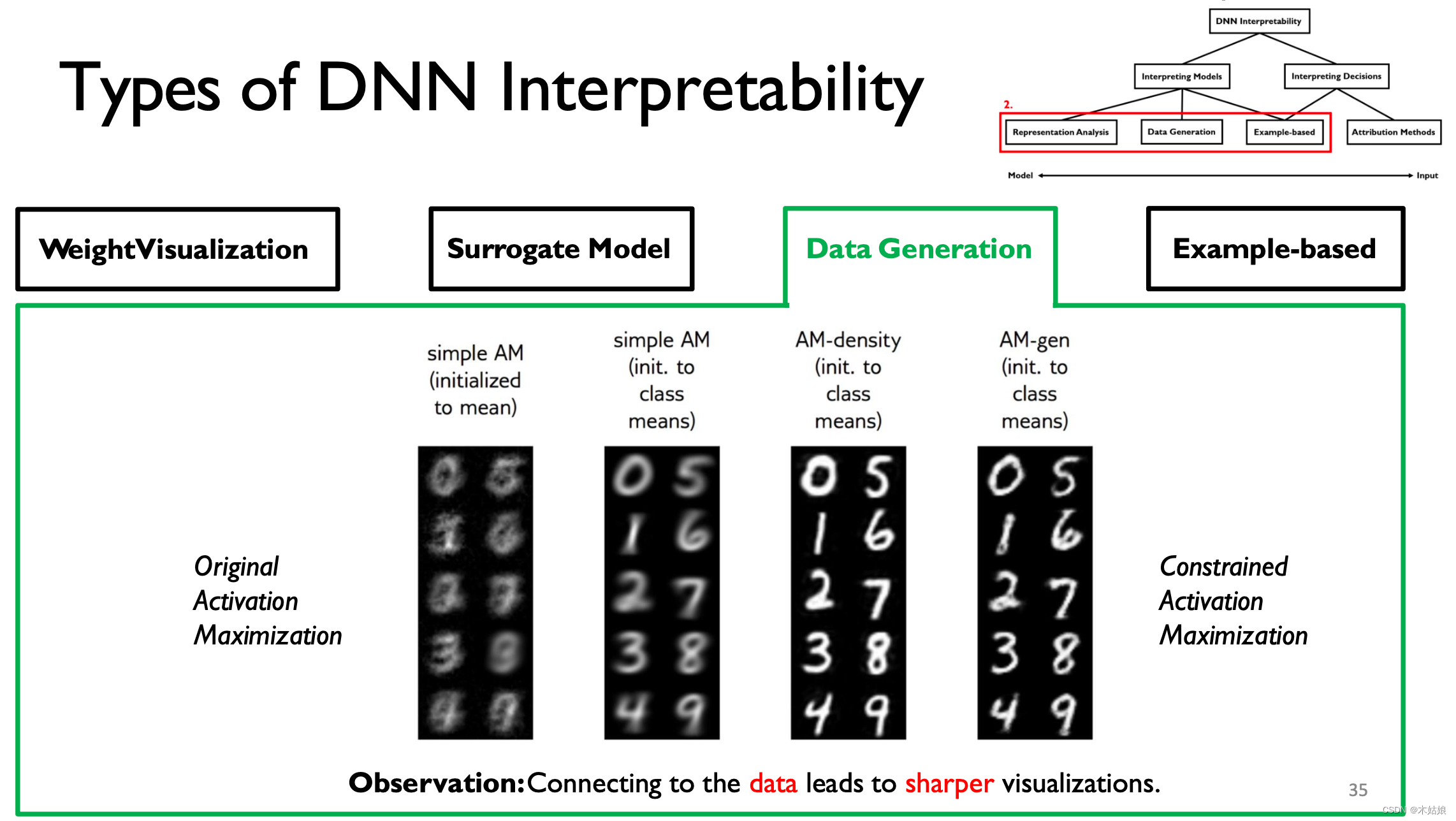
- DNN可以通过寻找输出量最大化的输入模式来解释。
- 与数据连接可以提高可视化的可解释性。
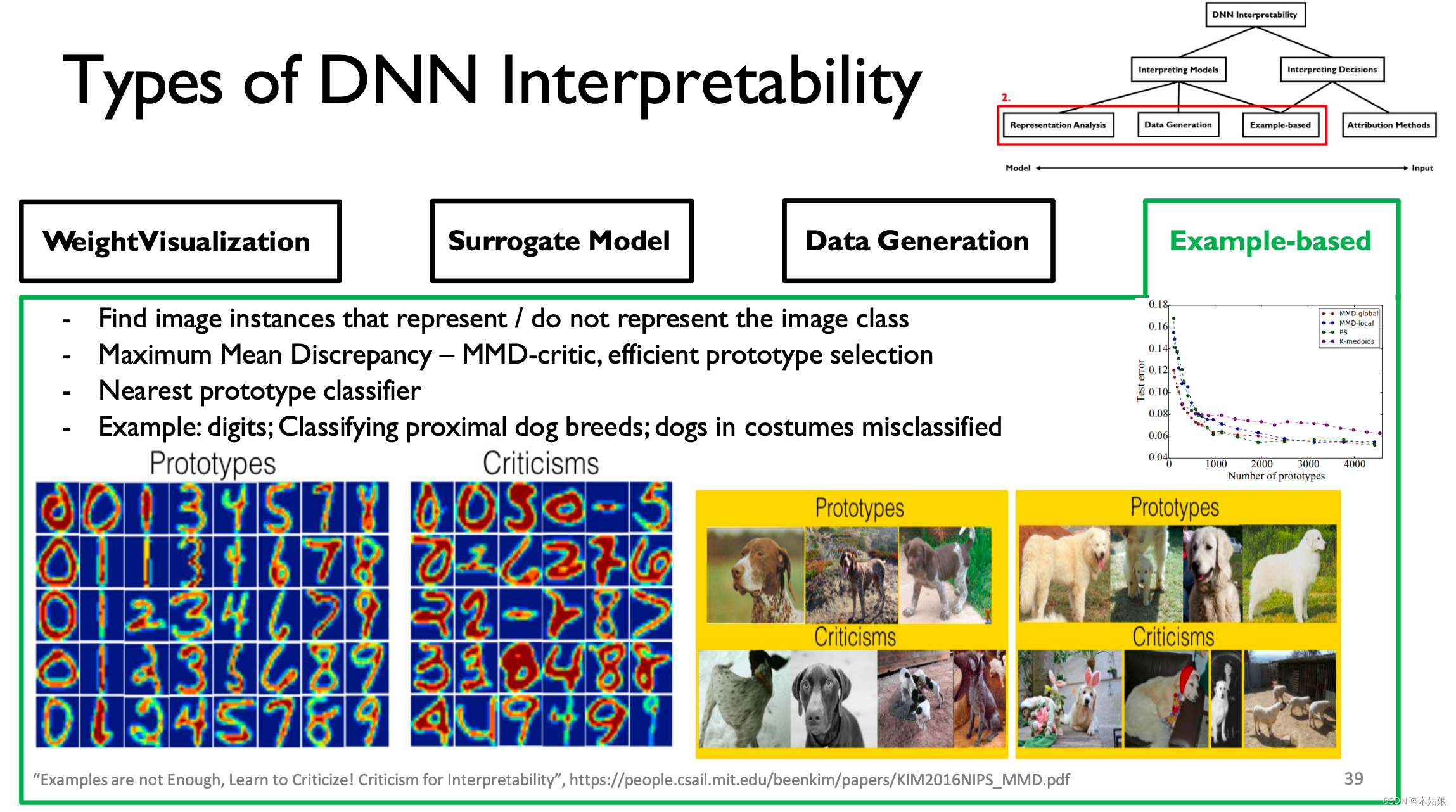
4. Example-based
小结:
- 通过将每层权重可视化
- 替代准确性不高但可解释性强的模型
- 在某种程度上通过最大化激活函数获得有用的特征/信息
- 通过有效构造prototype和criticism,指导模型学习获取该类别下最有用的,用于区分的信息
2c. Interpreting Decisions:

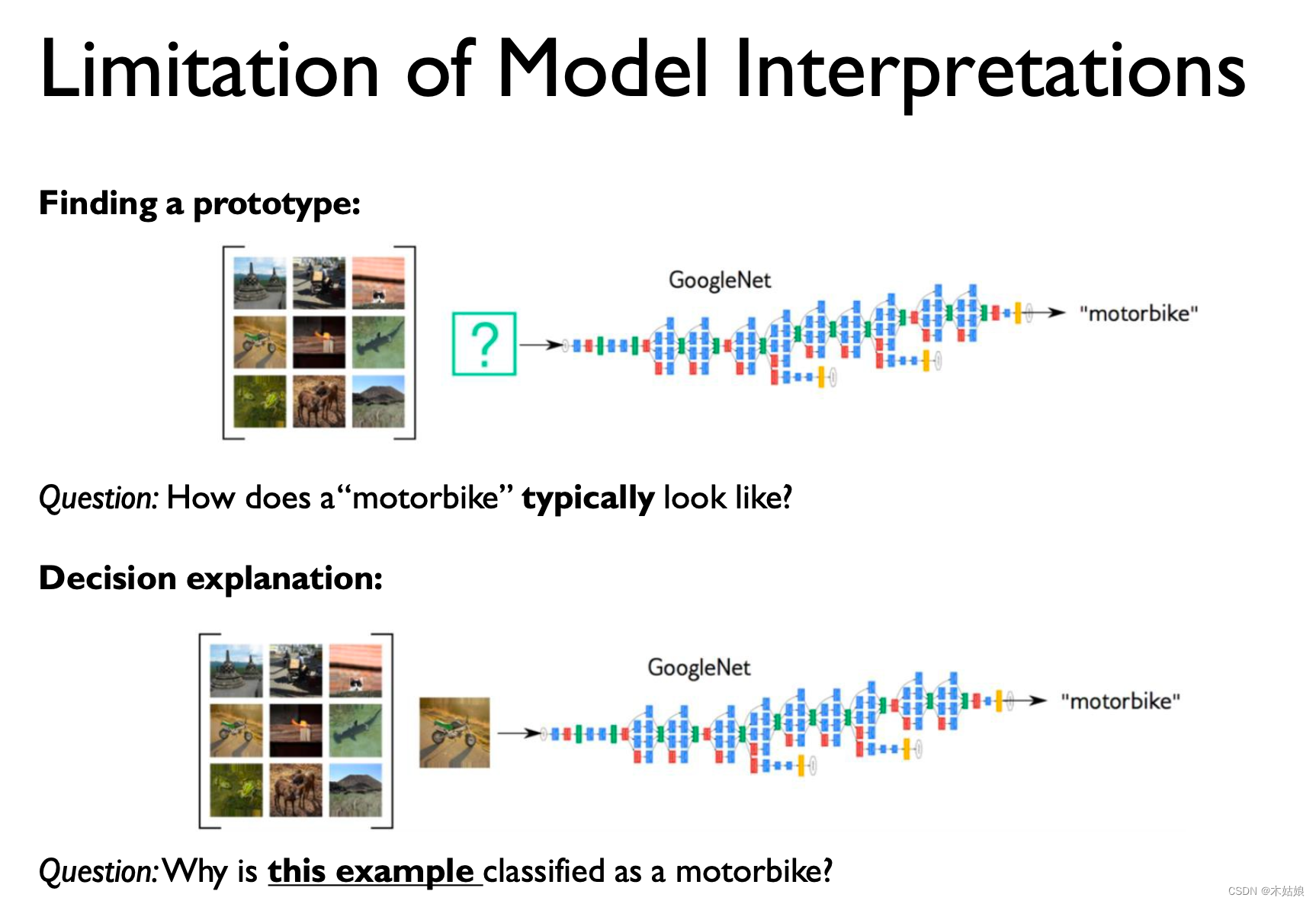
Example-based
输入的训练样本对模型的结果产生决定性的影响
Attribution Methods: why are gradients noisy?
给每个像素值一个因果分数,即当前像素对模型给这个结果起到了多大的作用。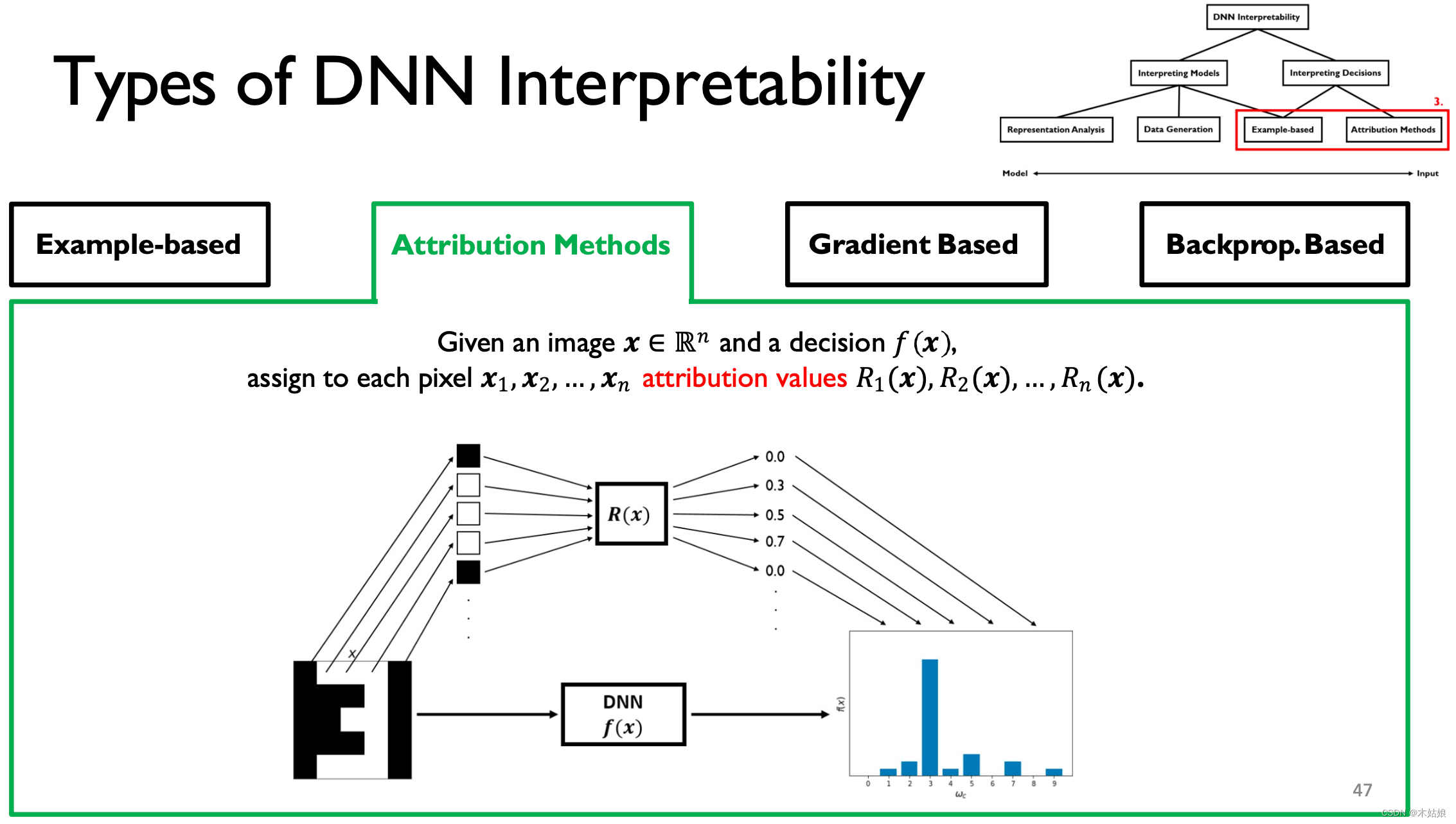
将归因可视化后的结果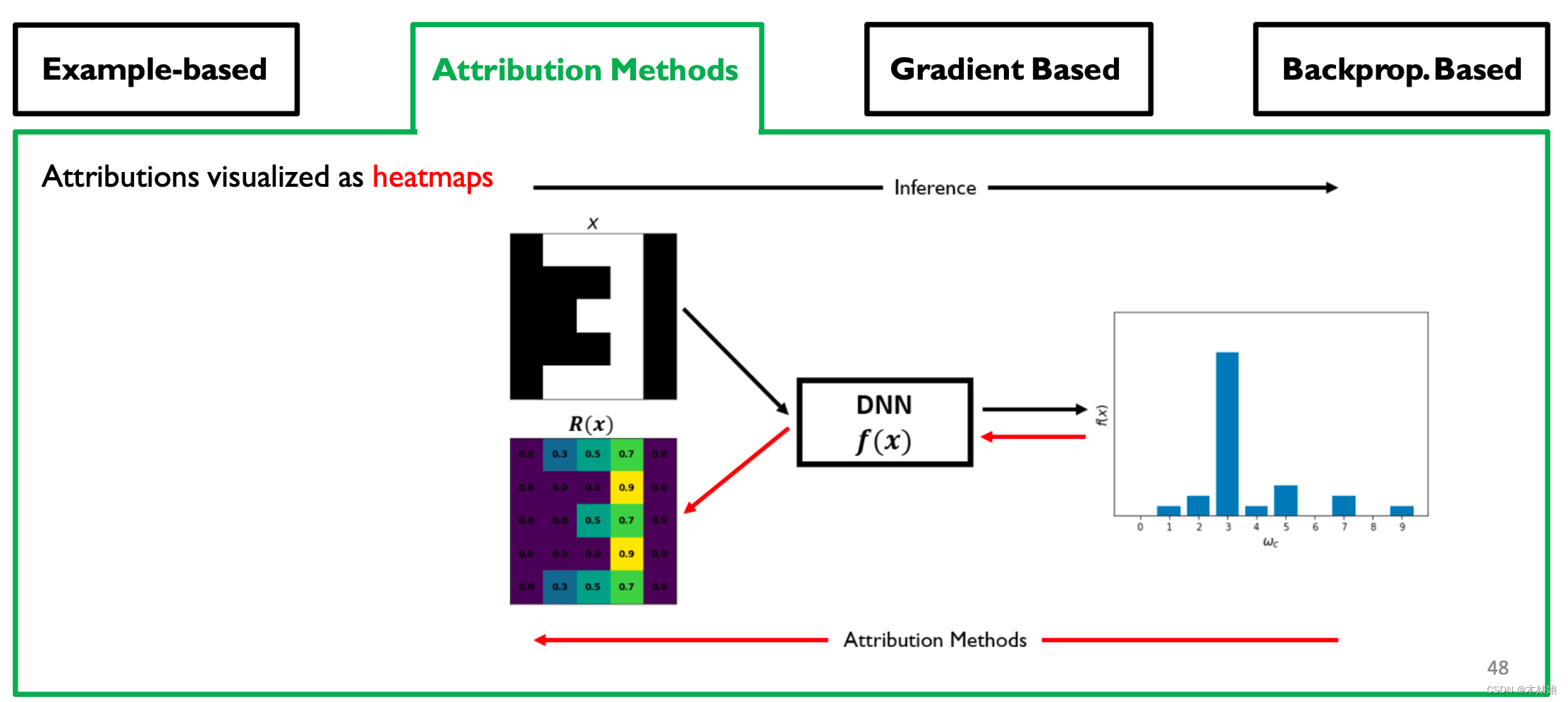
关键是,构建(特征)显著图(Saliency Map)
提升saliency map的方法,首先:思路转变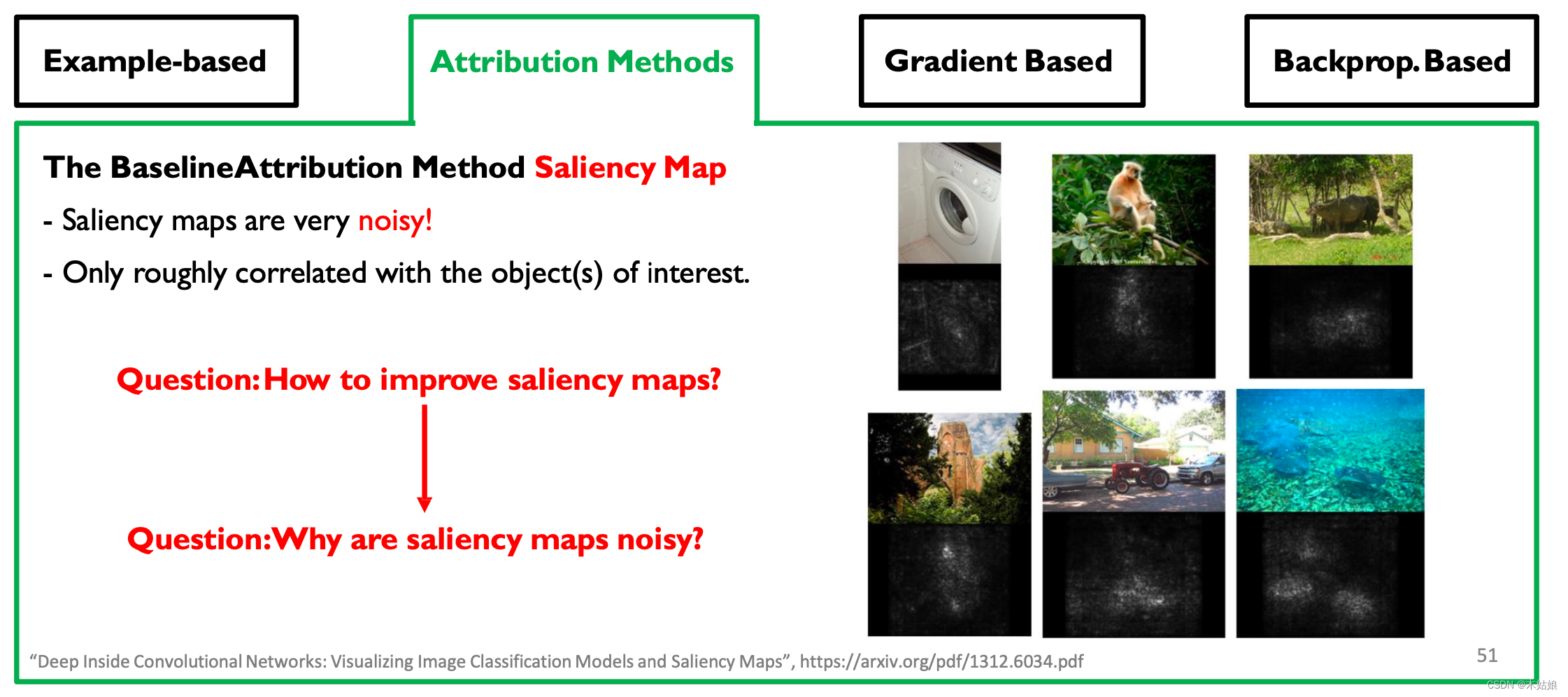
假设1: saliency map是真实的
- 图像中随机分布的某些像素对网络如何做出决定至关重要。
- 噪音很重要

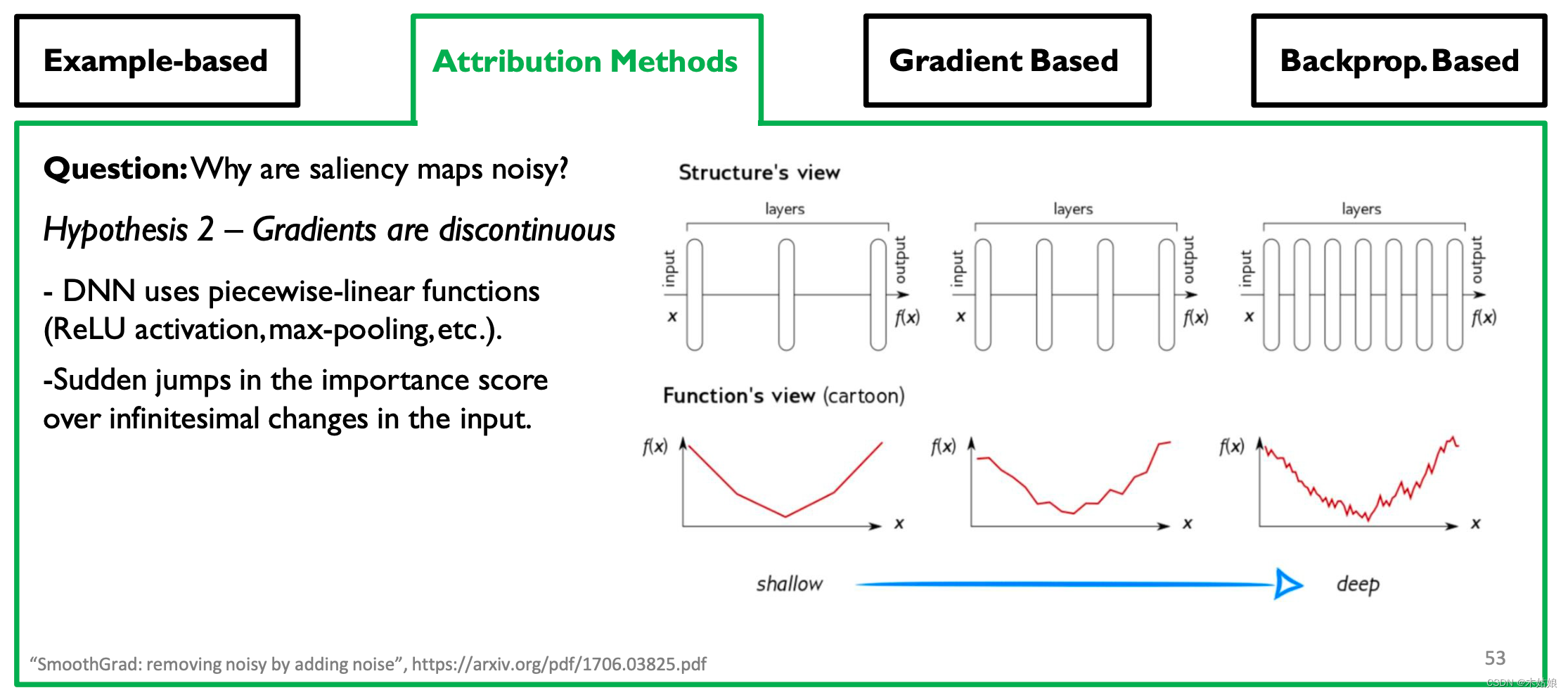
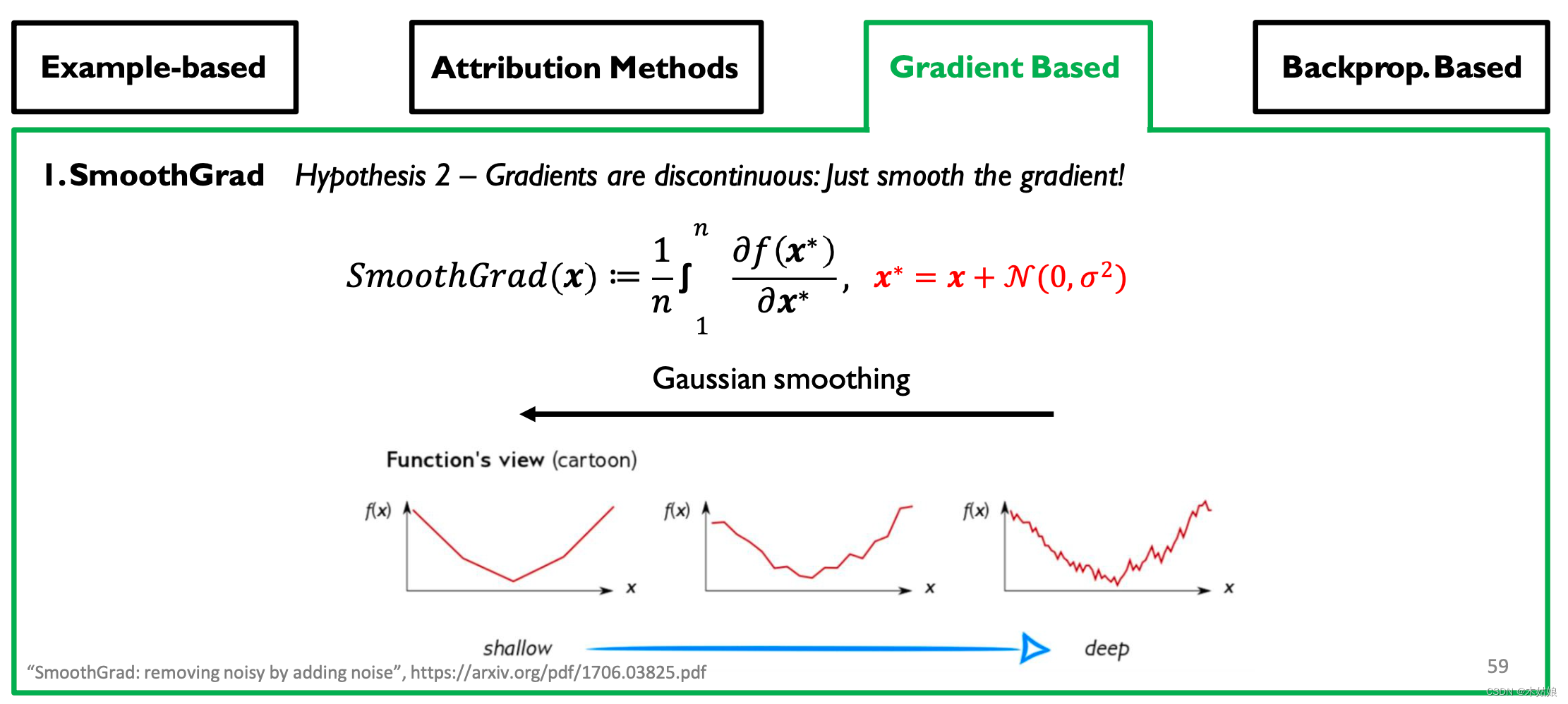
假设2: 梯度是不连续的 - DNN使用分段线性函数(ReLU激活,max-pooling等)。
- 重要性分数在输入的无穷小变化上的突变跳跃。
假设3: - 一个特征可能会在全球范围内产生强大的影响,但在局部却会产生很小的影响
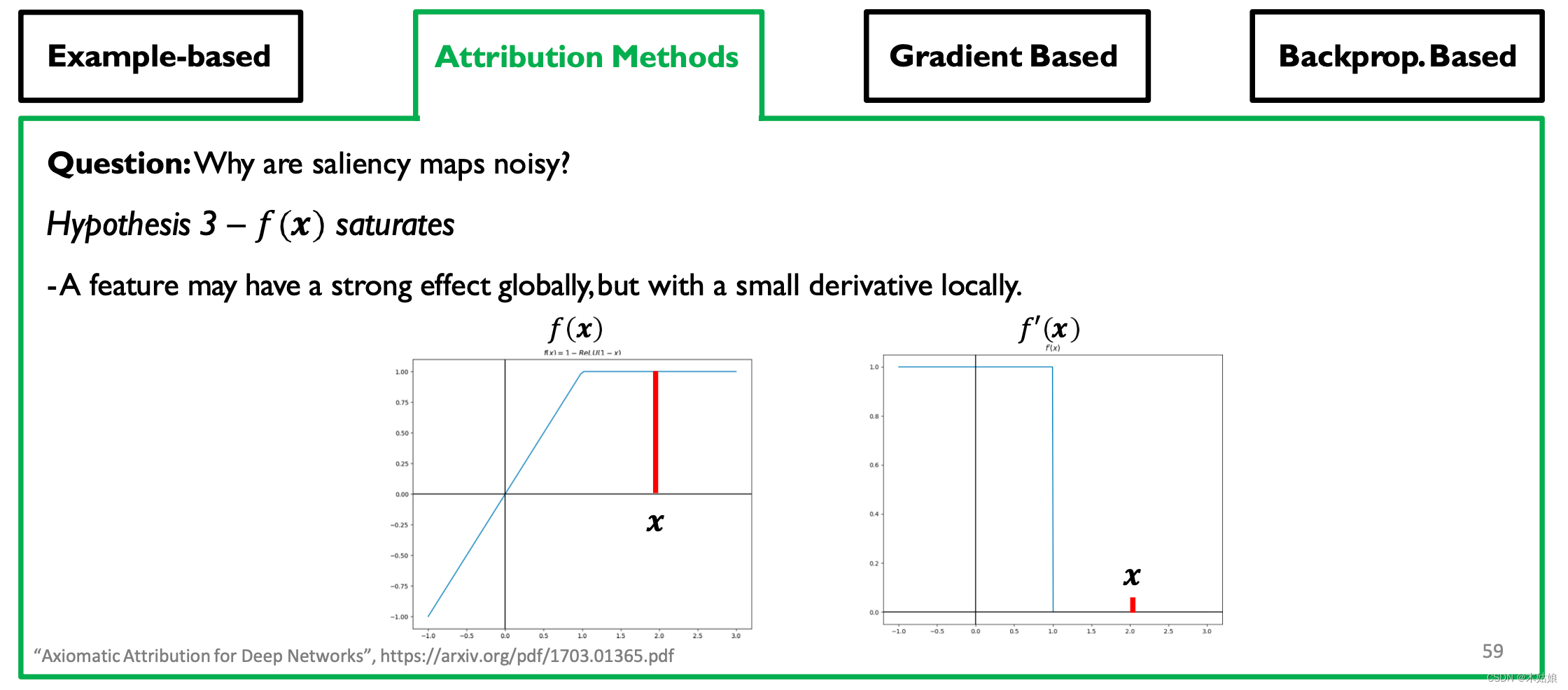

其他的归因方法
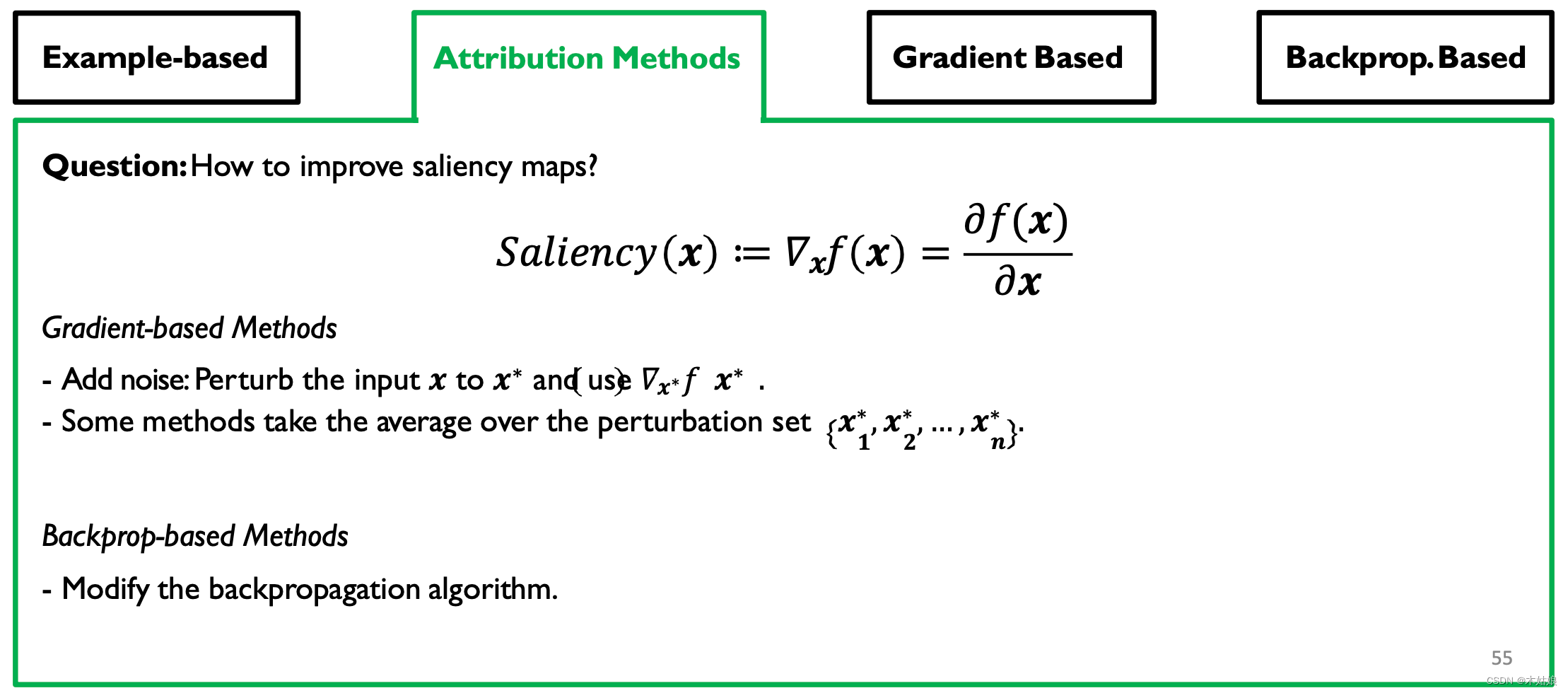
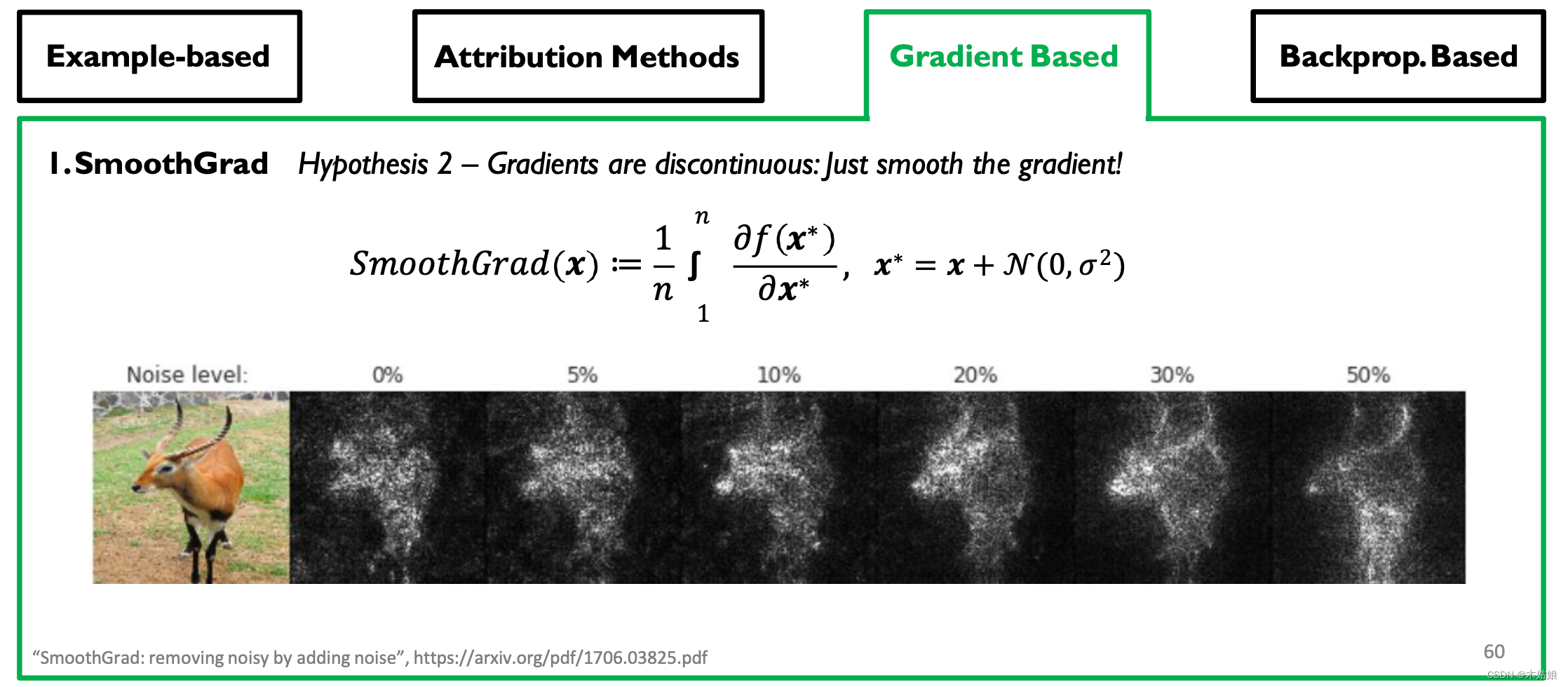
Gradient-based Attribution: SmoothGrad, Interior Gradient
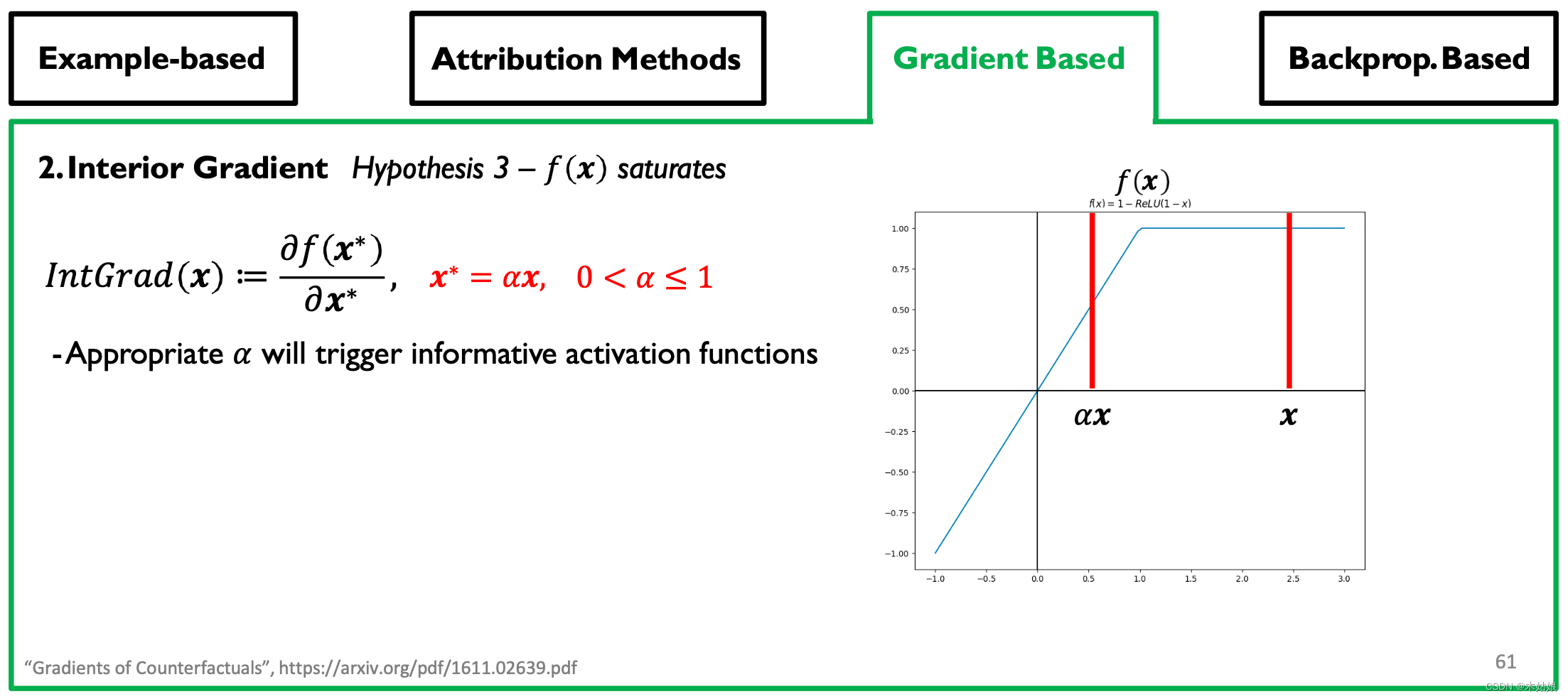

Backprop-based Attribution: Deconvolution, Guided Backpropagation
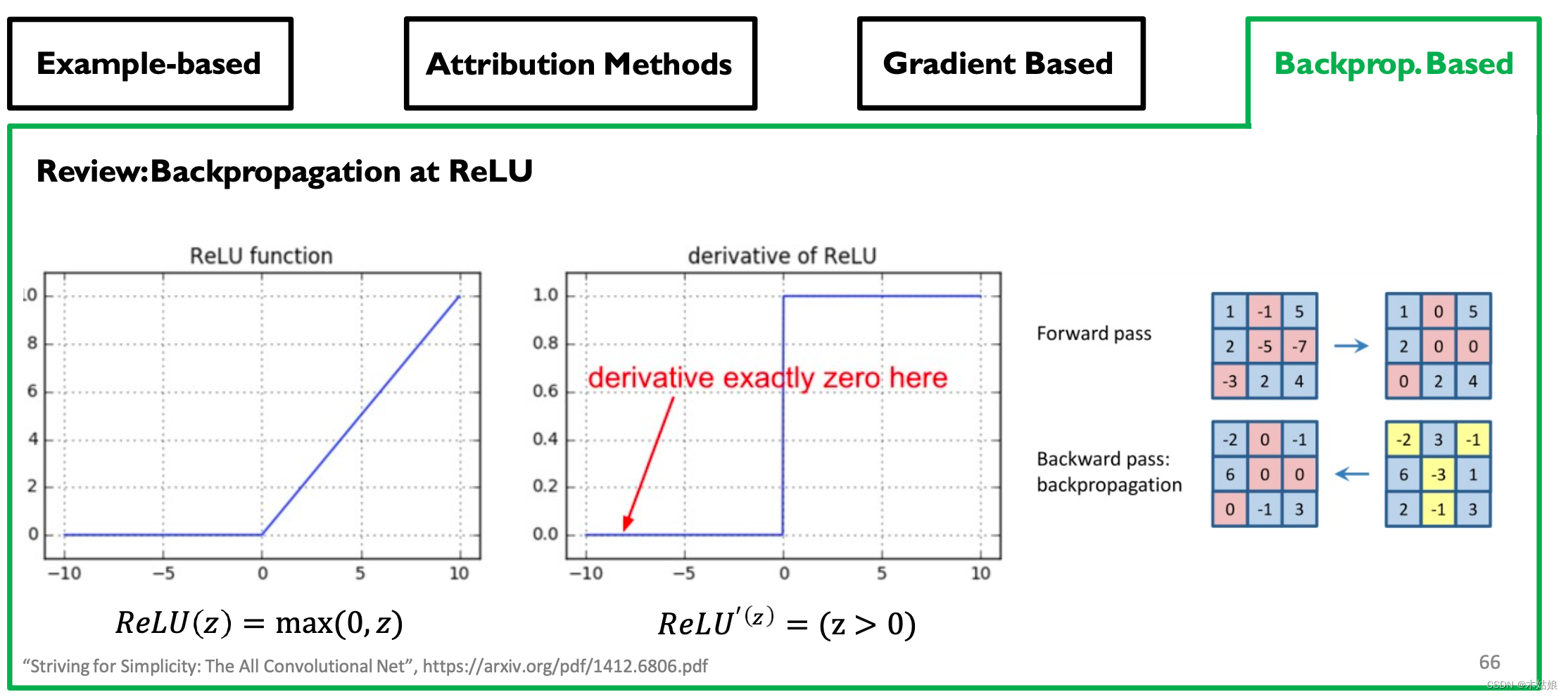
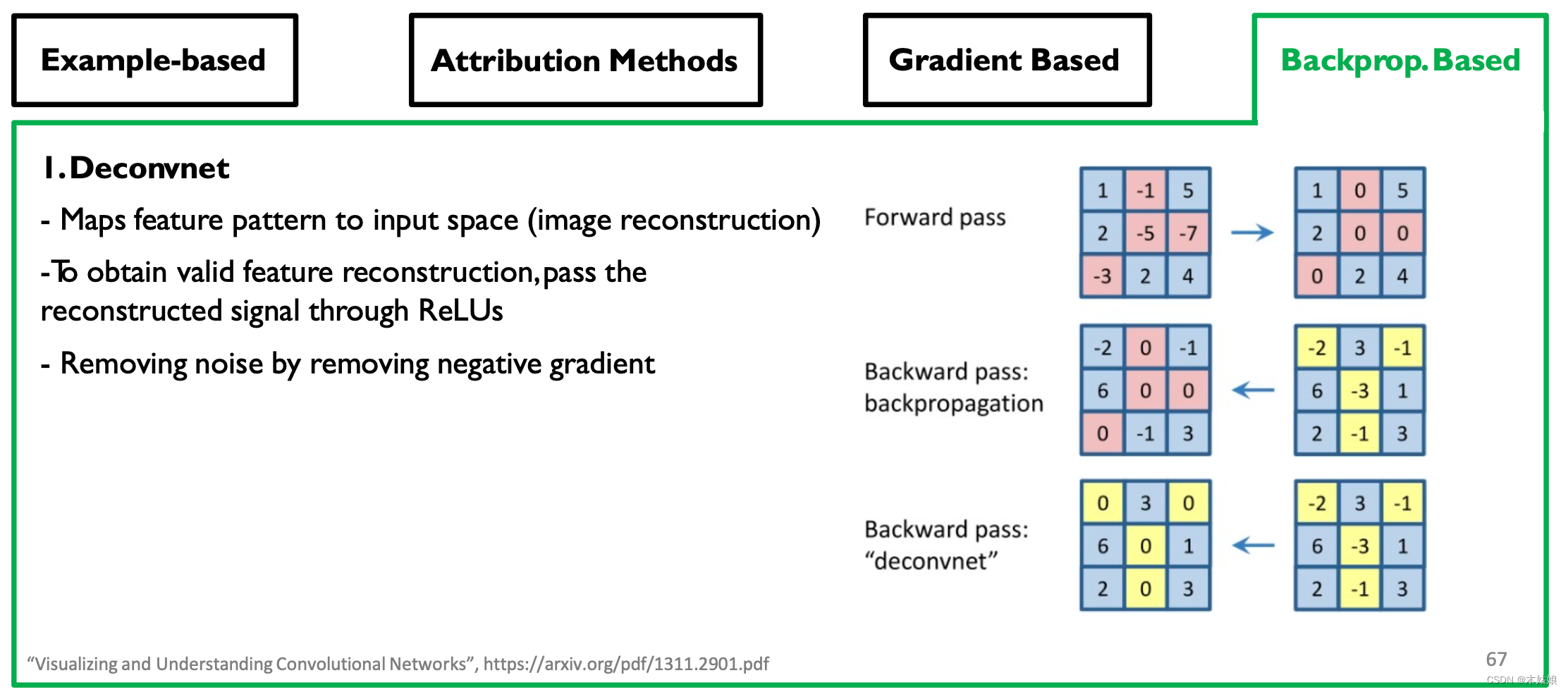
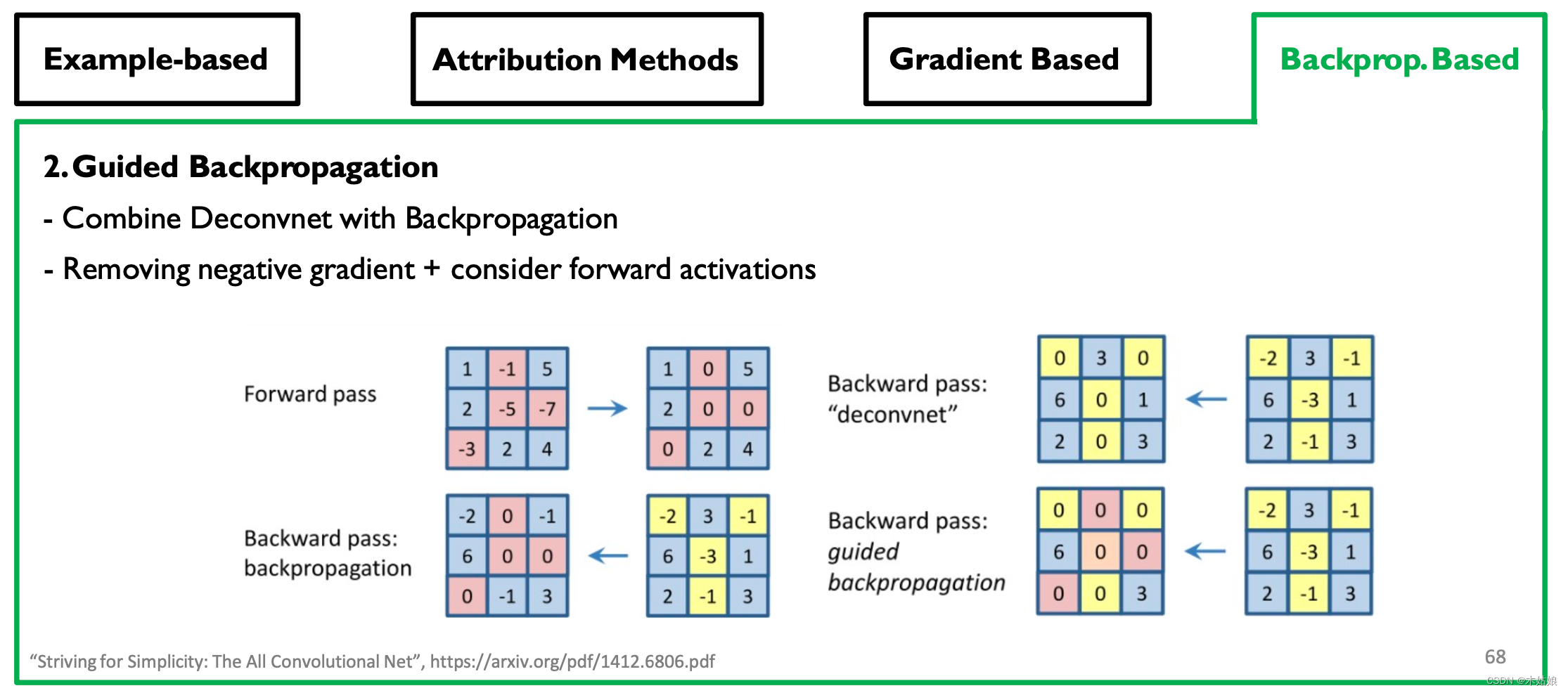
- 观察:移除更多的梯度会带来更清晰的视觉效果

Evaluating Attribution Methods
3a. Qualitative: Coherence: Attributions should highlight discriminative features / objects of interest
- 归因应基于区别性特征
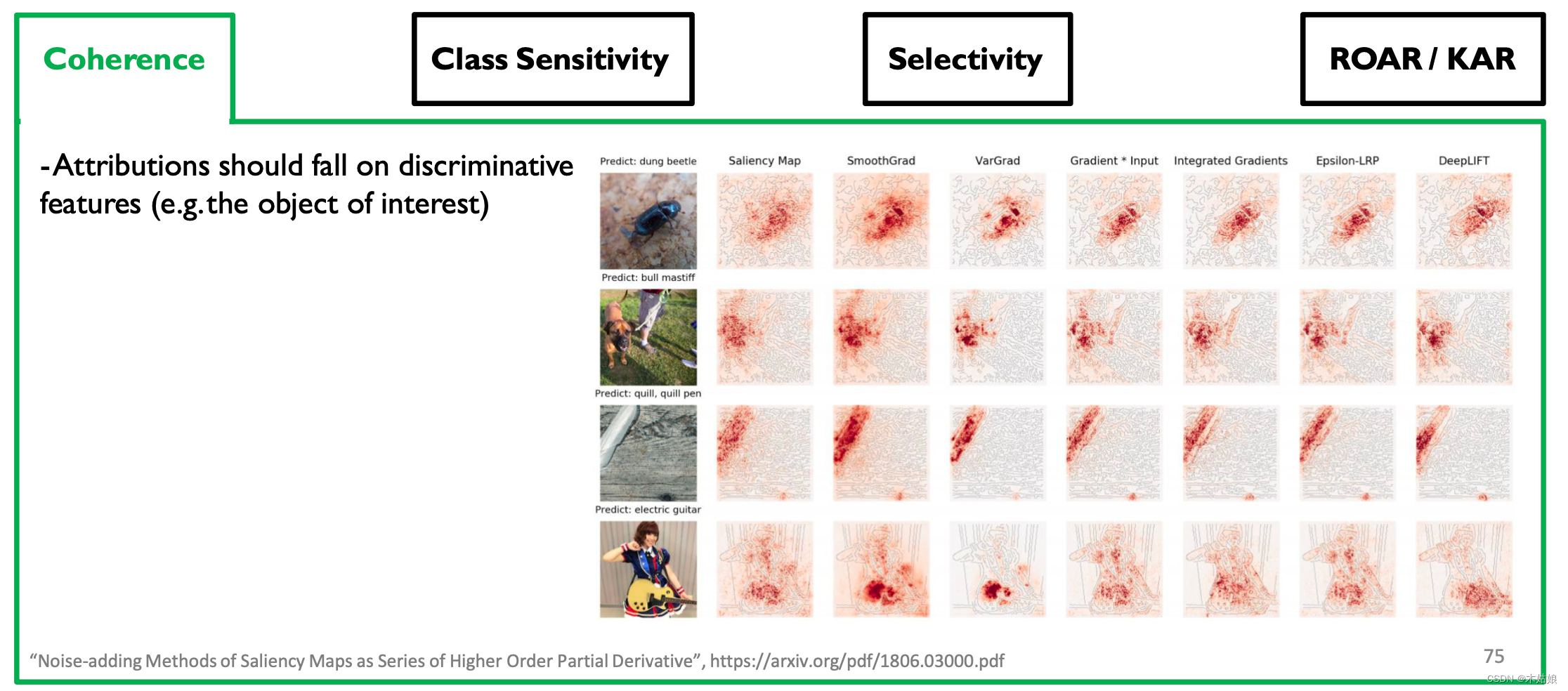
3b. Qualitative: Class Sensitivity: Attributions should be sensitive to class labels
- 归因应该是类别敏感的

3c. Quantitative: Sensitivity: Removing feature with high attribution --> large decrease in class probability
- 移除属性高的特征会导致类概率大幅下降

3d. Quantitative: ROAR & KAR. Low class prob cuz image unseen --> remove pixels, retrain, measure acc. drop

边栏推荐
- Graduation project of game mall
- Palindrome (csp-s-2021-palin) solution
- Sword finger offer 58 - ii Rotate string left
- SSH password free login settings and use scripts to SSH login and execute instructions
- Codeforces Round #716 (Div. 2) D. Cut and Stick
- 【Rust 笔记】17-并发(下)
- 网络工程师考核的一些常见的问题:WLAN、BGP、交换机
- Educational Codeforces Round 107 (Rated for Div. 2) E. Colorings and Dominoes
- One question per day 1447 Simplest fraction
- Introduction et expérience de wazuh open source host Security Solution
猜你喜欢
【Jailhouse 文章】Look Mum, no VM Exits

1.15 - 输入输出系统
Graduation project of game mall

剑指 Offer 58 - II. 左旋转字符串
leetcode-6108:解密消息
![[cloud native] record of feign custom configuration of microservices](/img/39/05cf7673155954c90e75a8a2eecd96.jpg)
[cloud native] record of feign custom configuration of microservices
Some common problems in the assessment of network engineers: WLAN, BGP, switch
Appium自动化测试基础 — Appium测试环境搭建总结
![[practical skills] how to do a good job in technical training?](/img/a3/7a1564cd9eb564abfd716fef08a9e7.jpg)
[practical skills] how to do a good job in technical training?

全国中职网络安全B模块之国赛题远程代码执行渗透测试 //PHPstudy的后门漏洞分析
随机推荐
R language [import and export of dataset]
【实战技能】如何做好技术培训?
Sword finger offer 05 Replace spaces
【Jailhouse 文章】Performance measurements for hypervisors on embedded ARM processors
1.13 - RISC/CISC
【Rust 笔记】16-输入与输出(上)
网络工程师考核的一些常见的问题:WLAN、BGP、交换机
leetcode-6110:网格图中递增路径的数目
Individual game 12
剑指 Offer 04. 二维数组中的查找
【Jailhouse 文章】Look Mum, no VM Exits
【Rust 笔记】13-迭代器(下)
AtCoder Grand Contest 013 E - Placing Squares
Sword finger offer 09 Implementing queues with two stacks
从Dijkstra的图灵奖演讲论科技创业者特点
Introduction and experience of wazuh open source host security solution
2022 极术通讯-Arm 虚拟硬件加速物联网软件开发
Some common problems in the assessment of network engineers: WLAN, BGP, switch
Configuration and startup of kubedm series-02-kubelet
【Rust 笔记】14-集合(上)