当前位置:网站首页>什么是套接字?Socket基本介绍
什么是套接字?Socket基本介绍
2022-07-05 06:16:00 【Ostrich5yw】
一、什么是套接字?
套接字是一种通信机制(通信的两方的一种约定),socket屏蔽了各个协议的通信细节,提供了tcp/ip协议的抽象,对外提供了一套接口,同过这个接口就可以统一、方便的使用tcp/ip协议的功能。这使得程序员无需关注协议本身,直接使用socket提供的接口来进行互联的不同主机间的进程的通信。我们可以用套接字中的相关函数来完成通信过程。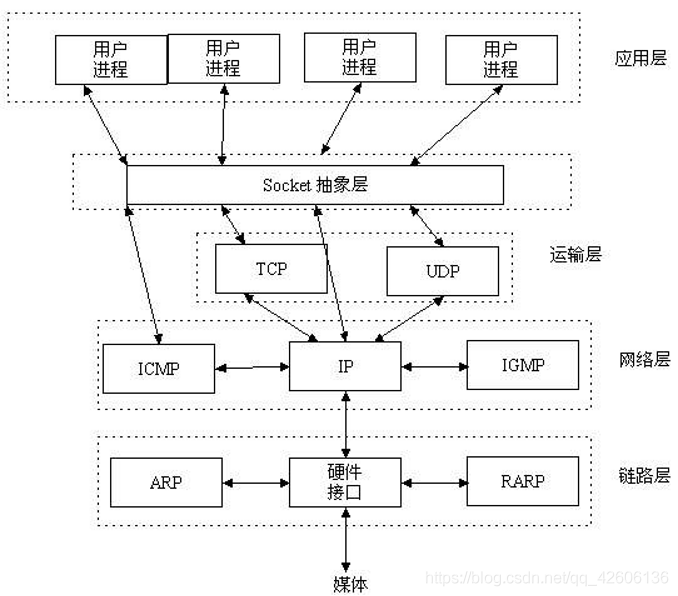
发送方的发送数据的处理流程大致为:用户空间 -> 内核 -> 网卡 -> 网络
在用户态空间,调用发送数据接口 send/sento/wirte 等写数据包,在内核空间会根据不同的协议走不同的流程。以TCP为例,TCP是一种流协议,内核只是将数据包追加到套接字的发送队列中,真正发送数据的时刻,则是由TCP协议来控制的。TCP协议处理完成之后会交给IP协议继续处理,最后会调用网卡的发送函数,将数据包发送到网卡。
接收方的接收数据的处理流程大致为:网络 -> 网卡 -> 内核(epoll等) -> 进程(业务处理逻辑)
网卡会通过轮询或通知的方式接收数据,Linux做了优化,组合了通知和轮询的机制,简单来说,在CPU响应网卡中断时,不再仅仅是处理一个数据包就退出,而是使用轮询的方式继续尝试处理新数据包,直到没有新数据包到来,或者达到设置的一次中断最多处理的数据包个数。数据离开网卡驱动之后就进入到了协议栈,经过IP层、网络层协议的处理,就会触发IO读事件,比如epoll的reactor模型中,就会触发对应的读事件,然后回调对应的IO处理函数,数据之后会交给业务线程来处理,比如Netty的数据接收处理流程就是这样的。
二、套接字特性
套接字的特性有三个属性确定,它们是:域(domain),类型(type),和协议(protocol)。
域:指定套接字通信中使用的网络介质。最常见的套接字域是 AF_INET(IPv4)或者AF_INET6(IPV6),它是指 Internet 网络。
类型:
流套接字(SOCK_STREAM):
流套接字用于提供面向连接、可靠的数据传输服务。该服务将保证数据能够实现无差错、无重复发送,并按顺序接收。流套接字之所以能够实现可靠的数据服务,原因在于其使用了传输控制协议,即TCP数据报套接字(SOCK_DGRAM):
数据报套接字提供了一种无连接的服务。该服务并不能保证数据传输的可靠性,数据有可能在传输过程中丢失或出现数据重复,且无法保证顺序地接收到数据。数据报套接字使用UDP(User Datagram Protocol)协议进行数据的传输。原始套接字(SOCK_RAW):
原始套接字与标准套接字(标准套接字指的是前面介绍的流套接字和数据报套接字)的区别在于:原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送数据必须使用原始套接字。
协议:IPPROTO_TCP,IPPROTO_UDP
三、套接字缓冲区
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。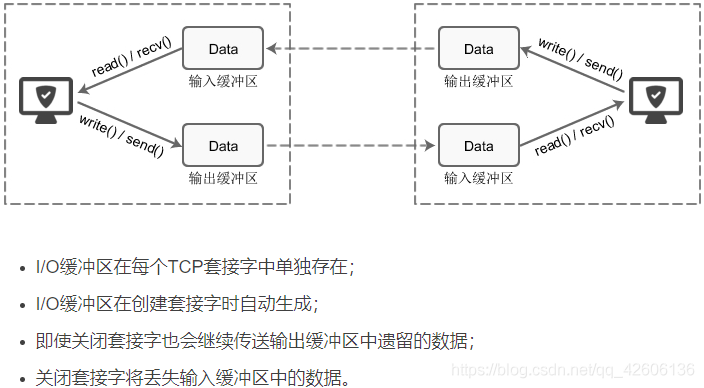
用户程序缓冲区
用户进程通过系统调用访问系统资源的时候,需要切换到内核态,而这对应一些特殊的堆栈和内存环境,必须在系统调用前建立好。而在系统调用结束后,cpu会从核心模式切回到用户模式,而堆栈又必须恢复成用户进程的上下文。而这种切换就会有大量的耗时。
一些程序在读取文件时,会先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer(用较小的次数填满buffer)。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。所以说:用户缓冲区的目的是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。除了在进程中设计缓冲区,内核也有自己的缓冲区。
内核缓冲区
当一个用户进程要从磁盘读取数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程缓冲区中。但若是内核缓冲区中没有数据,内核会把对数据块的请求,加入到请求队列,然后把进程挂起,为其它进程提供服务。等到数据已经读取到内核缓冲区时,把内核缓冲区中的数据读取到用户进程中,才会通知进程。
你可以认为,read是把数据从内核缓冲区复制到进程缓冲区。write是把进程缓冲区复制到内核缓冲区。当然,write并不一定导致内核的写动作,比如os可能会把内核缓冲区的数据积累到一定量后,再一次写入。这也就是为什么断电有时会导致数据丢失。所以说内核缓冲区,是为了在OS级别,提高磁盘IO效率,优化磁盘写操作。
边栏推荐
- Règlement sur la sécurité des réseaux dans les écoles professionnelles secondaires du concours de compétences des écoles professionnelles de la province de Guizhou en 2022
- One question per day 1765 The highest point in the map
- LeetCode 1200. Minimum absolute difference
- leetcode-556:下一个更大元素 III
- Leetcode heap correlation
- Sword finger offer II 058: schedule
- [practical skills] technical management of managers with non-technical background
- Leetcode backtracking method
- SPI details
- Traditional databases are gradually "difficult to adapt", and cloud native databases stand out
猜你喜欢
Navicat連接Oracle數據庫報錯ORA-28547或ORA-03135

redis发布订阅命令行实现
The connection and solution between the shortest Hamilton path and the traveling salesman problem
Leetcode stack related
Groupbykey() and reducebykey() and combinebykey() in spark

Dynamic planning solution ideas and summary (30000 words)
Is it impossible for lamda to wake up?

Doing SQL performance optimization is really eye-catching

1.15 - input and output system

数据可视化图表总结(二)
随机推荐
传统数据库逐渐“难适应”,云原生数据库脱颖而出
LeetCode 0108. Convert an ordered array into a binary search tree - the median of the array is the root, and the left and right of the median are the left and right subtrees respectively
MySQL advanced part 1: triggers
【Rust 笔记】15-字符串与文本(上)
打印机脱机时一种容易被忽略的原因
[rust notes] 16 input and output (Part 1)
Erreur de connexion Navicat à la base de données Oracle Ora - 28547 ou Ora - 03135
MySQL advanced part 2: the use of indexes
7. Processing the input of multidimensional features
多屏电脑截屏会把多屏连着截下来,而不是只截当前屏
MySQL怎么运行的系列(八)14张图说明白MySQL事务原子性和undo日志原理
Leetcode dynamic programming
Dynamic planning solution ideas and summary (30000 words)
Leetcode recursion
MySQL advanced part 2: MySQL architecture
Leetcode-22: bracket generation
LaMDA 不可能觉醒吗?
Leetcode-6109: number of people who know secrets
1041 Be Unique
[rust notes] 16 input and output (Part 2)