当前位置:网站首页>【Rust 笔记】15-字符串与文本(上)
【Rust 笔记】15-字符串与文本(上)
2022-07-05 05:50:00 【phial03】
15 - 字符串与文本
15.1-Unicode
15.1.1-ASCII、Latin-1 与 Unicode
Unicode 与 ASCII 的所有 ASCII 码点都相同(0 ~ 0x7f)。
Unicode 将(0 ~ 0x7f)码点范围称为 Latin-1 编码块(
ISO/IEC 8859-1)。即 Unicode 是 Latin-1 的超集:
Latin-1 转换为 Unicode:
fn latin1_to_char(latin1: u8) -> char { latin1 as char }Unicode 转换为 Latin-1:
fn char_to_latin1(c: char) -> Option<u8> { if c as u32 <= 0xff { Some(c as u8) } else { None } }
15.1.2-UTF-8
- Rust 的
String和str类型使用 UTF-8 编码格式表示文本。UTF-8 将字符编码为 1 到 4 个字节序列。 - UTF-8 序列的格式限制:
- 对于给定的码点,只有最短的编码才被认为是格式良好的,即不能用 4 个字节去编码只需 3 个字节的码点。
- 格式良好的 UTF-8 不能对 0xd800 ~ 0xdfff,以及大于 0x10ffff 的数值编码。
- UTF-8 的重要属性:
- UTF-8 对码点 0 到 0x7f 的编码就是字节 0 到 0x7f,保存 ASCII 文本的字节是最有效的 UTF-8。ASCII 与 UTF-8 是可逆的,而 Latin-1 与 UTF-8 不具备可逆性。
- 通过观察任意字节的前几位,就能知道它是某些字符 UTF-8 编码的首字节,还是中间字节。
- 通过编码首字节的前几位就能知道编码的总长度。
- 编码最长为 4 个字节,UTF-8 不需要无限循环,可用于处理不受信的数据。
- 格式良好的 UTF-8 种,可以快速指出字符编码的起始和结束位置。UTF-8 的首字节与后续字节有明显区别。
15.1.5 - 文本方向性
- 有些文字是从左向右书写:属于正常情况下的书写或阅读方式,也是 Unicode 采用的顺序存储字符。
- 有些文字是从右向左书写:字符串的首字节保存的是要写在最右边的字符的编码。
15.2 - 字符(char)
char类型是保存 Unicode 码点的 32 位值。- 范围为:0 到 0xd7ff,或者 0xe000 到 0x10ffff。
char类型实现了Copy和Clone,以及比较、散列、格式的所有常用特型。
15.2.1 - 字符分类 —— 检测字符类别的方法
ch.is_numeric():数值字符,包括 Unicode 普通类别Number; digit和Number; letter,但不包括Number; other。ch.is_alphabetic():字母字符,包括 Unicode 的 “Alphabetic” 派生属性。ch.is_alphanumeric():数值或字母字符,包括上面两个类别。ch.is_whitespace():空白字符,包括 Unicode 字符属性 “WSpace=Y”。ch.is_control:控制字符,包括 Unicode 的Other, control普通类别。
15.2.2 - 处理数字
ch.to_digit(radix):决定ch是否是基数为radix的 ASCII 数字。如果是就返回Some(num),其中num是u32。否则,返回None。radix的范围是 2~36。如果radix > 10,那么 ASCII 字母将作为值为 10~35 的数字。std::char::from_digit(num, radix):把u32数值num转换为char。如果radix > 10,ch是小写字母。ch.is_digit(radix):在ch是基数为radix下的 ASCII 数字时,返回true。等价于ch.to_digit(radix) != None。
15.2.3 - 字符大小写转换
ch.is_lowercase():判断ch是否为小写字母。ch.is_uppercase():判断ch是否为大写字母。ch.to_lowercase():将ch转换为小写字母。ch.to_uppercase():将ch转换为大写字母。
15.2.4 - 与整数相互转换
as操作符可以把char转换为任何整数类型,高位会被屏蔽。as操作符可以把任何u8值转换为char。char类型也实现了From<u8>。推荐使用std::char::from_u32,返回Option<char>。
15.3-String 与 str
Rust 的
String和str类型只保存格式良好的 UTF-8。String类型能创建可伸缩缓冲区,用于保存字符串。本质为Vec<u8>的包装类型。str类型则就地操作字符串文本。String的解引用为&str。str上定义的所有方法,都可以在String上直接调用。文本处理的方法按照字节偏移量来索引文本,也按字节来度量长度,并不是按照字符。
Rust 会根据变量的名称,推测其类型,如:
变量名 推测类型 stringStringslice&str或解引用为&str的类型,如String或Rc<String>chcharnusize,长度i, jusize,字节偏移量rangeusize字节偏移量范围,可能是全限定i..j,部分限定i..或..j,或无限定..pattern任意模式类型: char, String, &str, &[char], FnMut(char) -> bool
15.3.1 - 创建 String 值
String::new():返回全新的空字符串。没有分配在堆上的缓冲区,后续会根据需要分配。String::with_capacity(n):返回全新的空字符串,同时在堆上分配至少容纳n字节的缓冲区。slice.to_string():常用于通过字符串字面量创建String。分配一个全新的String,其内容就是slice的副本。iter.collect():通过拼接迭代器的所有项(char、&str或String值)来构建String。如下删除字符串中的空格举例:let spacey = "man hat tan"; let spaceless: String = spacey.chars().filter(|c| !c.is_whitespcae()).collect(); assert_eq!(spaceless, "manhattan");slice.to_owned():将slice的副本作为一个全新分配的String返回。&str类型不能实现Clone,可以通过此方法达到克隆的效果。
15.3.2 - 简单检查 —— 从字符串切片获得基本信息
slice.len():返回以字节计算的slice的长度。slice.is_empyt():在slice.len() == 0时返回true。slice[range]:返回借用slice中指定部分的切片。不能像
slice[i]这样的格式取得一个位置索引的字符串切片。而是需要基于切片产生一个 chars 迭代器,让迭代器解析出相应字符串的 UTF-8:let par = "rust he"; assert_eq!(par[6..].chars().next(), Some('e'));slice.split_at(i):返回从slice借用的两个共享切片的元组,slice[..i]和slice[i..]。slice.is_char_boundary(i):在i为字符边界上时返回true。切片可以比较相等、顺序和散列。
15.3.3 - 向 String 追加和插入文本
string.push(ch):把字符ch追加到字符串末尾。string.push_str(slice):追加slice的全部内容。string.extend(iter):将迭代器iter生成的所有项追加到字符串。迭代器可以生成char、str或String值。string.insert(i, ch):在字节偏移值i的位置,向字符串中插入字符ch。i之后的所有字符向后移一位。string.insert_str(i, slice):在字节偏移值i的位置,向字符串中插入slice的全部内容。String实现了std::fmt::Write,因此可以使用write!和writeln!宏,给String追加格式化文本。它们的返回值类型是Result。需要在结尾添加?操作符来处理错误。use std::fmt::Write; let mut letter = String::new(); writeln!(letter, "Whose {} these are I think I know", "rustabagas")?;+操作符:在操作数为字符串时,可以用于拼接字符串操作。
15.3.4 - 删除文本
string.shrink_to_fit():在删除字符串内容后,可以用来释放内存。string.clear():将字符串重置为空字符。string.truncate(n):丢弃字节偏移值n之后的所有字符。string.pop():从字符串中删除最后一个字符,并以Option<char>作为返回值。string.remove(i):从字符串中删除字节偏移值i所在的字符,并返回该字符,后面的字符会向前移动。string.drain(range):根据戈丁字节索引的返回,返回迭代器,并且在迭代器被清除时删除相应字符。
15.3.5 - 搜索与迭代的约定
Rust 标准库与搜索和迭代文本相关的函数,遵循下述命名约定:
- 大多数操作可以从左向右处理文本;
- 名字以
r开头的操作从右向左处理,如rsplit和split的相反操作。 - 改变处理方向,不仅会影响产生值的顺序,也会影响值本身。
- 名字以
- 迭代器的名字如果以
n结尾,就表示会对自己限定匹配的次数。 - 迭代器的名字如果以
_indices结尾,表示会产生它们在切片中的字节偏移量,以及通常可迭代的值。
15.3.6 - 搜索文本的模式
模式(pattern):
- 当标准库函数需要搜索(search)、匹配(match)、分割(split)或修剪(trim)文本时,会接收不同类型的参数,来表示要查找的内容。这些类型被称为模式。
- 模式是可以实现
std::str::Pattern特型的任何类型。
标准库支持的 4 种主要模式:
char作为模式用于匹配字符;String、&str或&&str作为模式,用于匹配等于模式的子字符串。FnMut(char) -> bool闭包作为模式,用于匹配闭包返回true的一个字符。&[char]作为模式,表示char值的切片,用于匹配出现在列表中的任一字符。let code = "\t funcation noodle() { "; assert_eq!(code.trim_left_matchs(&[' ', 't'] as &[char]), "function noodle() { ");as操作符,可以将字符数组字面量转换为&[char];&[char; n]表示固定大小n的数组类型,不是模式类型。&[' ', 't'] as &[char]也可写作&\[' ', '\t'][..]。
15.3.7 - 搜索与替换
slice.contains(pattern):在slice包含与pattern匹配的内容时返回true。slice.starts_with(pattern)和slice.ends_with(pattern):在slice的初始或最终文本与pattern匹配时返回true。assert!("2017".starts_with(char::is_numeric));slice.find(pattern)和slice.rfind(pattern):在slice包含匹配pattern的内容时,返回Some(i)。i是匹配项的字节偏移量。slice.replace(pattern, replacement):返回以replacement替换所有pattern的内容之后得到的新String。slice.replacen(pattern, replacement, n):功能与上同,但是最多替换前n个匹配项。
15.3.8 - 迭代文本
slice.chars():基于slice的字符返回一个迭代器。slice.char_indices():基于slice的字符及它们的字节偏移量返回一个迭代器。assert_eq!("elan".char_indices().collect::<Vec<_>>(), vec![(0, 'e'), (2, 'l'), (3, 'a'), (4, 'n')]);slice.bytes():基于slice中的个别字节返回一个迭代器,暴露 UTF-8 编码。assert_eq!("elan".bytes().collect::<Vec<_>>(), vec![b'e', b'l', b'a', b'n']);slice.lines():基于slice中的文本行,返回一个迭代器。每行的终止符是\n或\r\n。这个迭代器所产生的值是从slice借用的&str。并且,所产生的值不包含终止符。slice.split(pattern):基于按照pattern分割slice得到的部分返回一个迭代器。两个相邻的匹配或者与slice开头、结尾的匹配都会返回空字符串。slice.rsplit(pattern):功能同上,但是会从后向前扫描和匹配slice。slice.split_terminator(pattern)和slice.rsplit_terminator(pattern):功能与上两个方法相同,不过pattern被当成终止符,而不是分隔符。如果pattern恰好匹配slice的两头,那么迭代器不会生成表示匹配与切片两头之间空字符串的空切片。slice.splitn(n, pattern)和slice.rsplitn(n, pattern):与split和rsplit类似,但是最多把字符串分割成n个切片,从pattern的第 1 次匹配到第n-1次匹配。slice.split_whitespace():基于空白slice分隔的部分返回一个迭代器。连续多个空白符作为一个分隔符。末尾的空白会被忽略。此处的空白与char::is_whitespace中的描述一致。slice.matches(pattern)和slice.rmatches(pattern):基于pattern在slice中找到的匹配项返回一个迭代器。slice.match_indices(pattern)和slice.rmatch_indices(pattern):与上同。不过产生的值是(offset, match)对,其中offset是匹配开始位置的字节偏移量,match是匹配的切片。
15.3.9 - 修剪
- 修剪(trim)字符串:
- 从字符串的开头和末尾去掉内容(通常是空白符)。
- 常用于清理文件中读到的带缩进的文本,或者一行末尾意外带着的空白符,以便让结果更清晰
slice.trim():返回slice的子切片,不包含切片开头和末尾的空白符。slice.trim_left():只忽略切片开头的空白符。slice.trim_right():只忽略切片末尾的空白符。slice.trim_matches(pattern):返回slice的子切片,不包含切片开头和末尾匹配pattern的内容。slice.trim_left_match(pattern):仅对切片开头的内容执行匹配操作。slice.trim_right_match(pattern):仅对切片末尾的内容执行匹配操作。
15.3.10 - 字符串大小写转换
slice.to_uppercase():返回新匹配的字符串,其保存着转换为大写之后的slice文本。结果的长度不一定与slice相同。slice.to_lowercase():与上面类似,但是转换的是小写之后的slice文本。
15.3.11 - 从字符解析出其他类型
所有常见的类型都实现了
std::str::FromStr特型,拥有从字符串切片中解析值的标准方法。pub trait FromStr: Sized { type Err; fn from_str(s: &str) -> Result<Self, self::Err>; }用于存储 IPv4 或 IPv6 互联网地址的枚举(enum)类型
std::net::IpAddr也实现了FromStr。use std::net::IpAddr; let address = IpAddr::from_str("fe80::0000:3ea9:f4ff:fe34:7a50")?; assert_eq!(address, IpAddr::from([0xfe80, 0, 0, 0, 0x3ea9, 0xf4ff, 0xfe34, 0x7a50]));字符串切片的
parse方法,可以将切片解析为任何类型。在调用时,需要写出给定的类型。let address = "fe80::0000:3ea9:f4ff:fe34:7a50".parse::<IpAddr>()?;
15.3.12 - 将其他类型转换为字符串
实现了
std::fmt::Display特型的打印类型,可以在format!宏中使用{}格式说明符。- 对于智能指针类型,如果
T实现了Display,则Box<T>、Rc<T>和Arc<T>也会实现:它们所打印出来的形式就是它们引用目标的形式。 Vec和HashMap等容器没有实现Display。
- 对于智能指针类型,如果
如果一个类型实现了
Display,则标准库会自动为其实现std::str::ToString特型:- 这个特型唯一的方法
to_string。 - 对于自定义类型建议实现
Display,而不是ToString。
- 这个特型唯一的方法
标准库的公共类型都实现了
std::fmt::Debug特型:可以接收一个值并将其格式化为字符串形式,用于程序的调试。
Debug生成的字符串,可以借助format!宏的{:?}格式说明符打印。自定义类型也可以实现
Debug,建议使用派生特型:#[derive(Copy, Clone, Debug)] struct Complex { r: f64, i: f64 }
15.3.13 - 作为其他类文本类型借用 —— 切片的借用
- 切片和
String实现了AsRef<str>、AsRef<[u8]>、AsRef<Path>和AsRef<OsStr>:使用这些特型作为自己参数类型的绑定,可以直接将切片或字符串传递给它们,及时这些函数需要的是其他类型。 - 切片和
String也实现了std::borrow::Borrow<Str>特型:HashMap和BTreeMap使用Borrow让String可以作为表中的键。
15.3.14 - 访问 UTF-8 格式的文本(字节表示的文本)
slice.as_bytes():借用slice的字节作为&[u8]。获取的字节必须是格式良好的 UTF-8。string.into_bytes():取得String的所有权并按值返回这个字符串字节的Vec<u8>。获取的字节可以不是格式良好的 UTF-8。
15.3.15 - 从 UTF-8 数据产生文本
str::from_utf8(byte_slice):接收一个&[u8]字节切片,返回一个Result:如果byte_slice包含格式良好的 UTF-8,则返回Ok(&str),否则返回错误。String::from_utf8(vec):基于传入的Vec<u8>值构建一个字符串。如果
vec保存着格式良好的 UTF-8,from_utf8就返回Ok(string),其中string就是取得vec所有权,并将其作为缓冲的字符串。如果字节不是格式良好的 UTF-8,则返回
Err(e),其中e是一个FromUtf8Error错误值。此时若调用e.into_bytes()则会得到原始的向量vec,即可实现转换失败而不丢失原值。let good_utf8: Vec<u8> = vec![0xe9, 0x8c, 0x86]; let bad_utf8: Vec<u8> = vec![0x9f, 0xf0, 0xa6, 0x80]; let result = String::from_utf8(bad_utf8); // 失败 assert!(result.is_err()); assert_eq!(result.unwrap_err().into_bytes(), vec![0x9f, 0xf0, 0xa6, 0x80]);
String::from_utf8_lossy(byte_slice):基于字节的共享切片&[u8]构建一个String或&str。String::from_utf8_unchecked:将Vec<>u8包装为一个String并返回它,要求必须是格式良好的 UTF-8。只能在unsafe块中使用。str::from_utf8_unchecked:接收一个&[u8],并将其返回为一个&str,同样不会检查字节的格式是不是格式良好的 UTF-8。同样只能在unsafe块中使用。
15.3.16 - 阻止分配
fn get_name() -> String {
std::env::var("USER").unwrap_or("whoever you are".to_string())
}
println!("Greetings, {}!", get_name());
上述例子实现了问候用户的程序,在 Unix 上可以实现,但是在 Windows 上用户名用的是
USERNAME字段,拿不到系统的用户名。std::env::var函数返回String。而get_name可能返回所有型的String,也可能是&'static str'。所以,可以使用
std::borrow::Cow(Clone-on-write 写时克隆)类型实现,可以保存所有型数据,也可以保存借用的数据。use std::borrow::Cow; fn get_name() -> Cow<'static, str> { std::env::var("USER") .map(|v| Cow::Owned(v)) .unwrap_or(Cow::Borrowed("whoever you are")) } println!("Greetings, {}!", get_name());- 如果成功读取
USER环境变量,则map将得到的字符串作为Cow::Owned返回。 - 如果失败,
unwrap_or将其静态的&str作为Cow::Borrowed返回。 - 只要
T实现了std::fmt::Display特型,那么Cow<'a, T>会得到与显示T一样的结果。
- 如果成功读取
std::borrow::Cow常用于可能需要,也可能不需要修改借用的某个文本时。在不需要修改的时候,可以继续借用它;
Cow的to_mut方法,确保Cow是Cow::Owned,必要时会应用值的ToOwned实现,然后返回这个值的可修改引用。fn get_title() -> Option<&'static str> { ... } let mut name = get_name(); if let Some(title) = get_title() { name.to_mut().push_str(", "); name.to_mut().push_str(title); } println!("Greetrings, {}!", name);同时也可以在必要时才会分配内存。
标准库为
Cow<'a, str>提供了对字符串的特殊支持。如提供了来自String和&str的From和Into转换,因此上述get_name可以简写为:fn get_name() -> Cow<'static, str> { std::env::var("USER") .map(|v| v.into()) .unwrap_or("whoever you are".into()) }Cow<'a, str>也实现了std::ops::Add和std::ops::AddAssign字符串重载,因此get_title()判断可以简写为:if let Some(title) = get_title() { name += ", "; name += title; }由于
String可以作为write!宏的目标,因此上述代码也等效于:use std::fmt::Write; if let Some(title) = get_title() { write!(name.to_mut(), ", {}", title).unwrap(); }不是所有
Cow<..., str>都必须是'static生命期,在需要复制之前,可以一直使用Cow借用之前计算的文本。
15.3.17 - 字符串作为泛型集合
String实现了std::default::Default和std::iter::Extend::defaultdefault返回一个空字符串。extend可以向一个字符串末尾追加字符、字符串切片或字符串。
&str类型也是实现了Default- 返回一个空切片。
- 常用于在某些边界的情况。比如为包含字符串切片的结构派生
Default。
详见《Rust 程序设计》(吉姆 - 布兰迪、贾森 - 奥伦多夫著,李松峰译)第十七章
原文地址
边栏推荐
- Full Permutation Code (recursive writing)
- [practical skills] technical management of managers with non-technical background
- leetcode-6110:网格图中递增路径的数目
- Brief introduction to tcp/ip protocol stack
- CCPC Weihai 2021m eight hundred and ten thousand nine hundred and seventy-five
- ALU逻辑运算单元
- 【Jailhouse 文章】Look Mum, no VM Exits
- Personal developed penetration testing tool Satania v1.2 update
- One question per day 1447 Simplest fraction
- kubeadm系列-00-overview
猜你喜欢
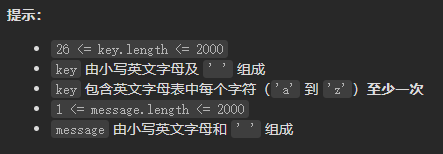
leetcode-6108:解密消息
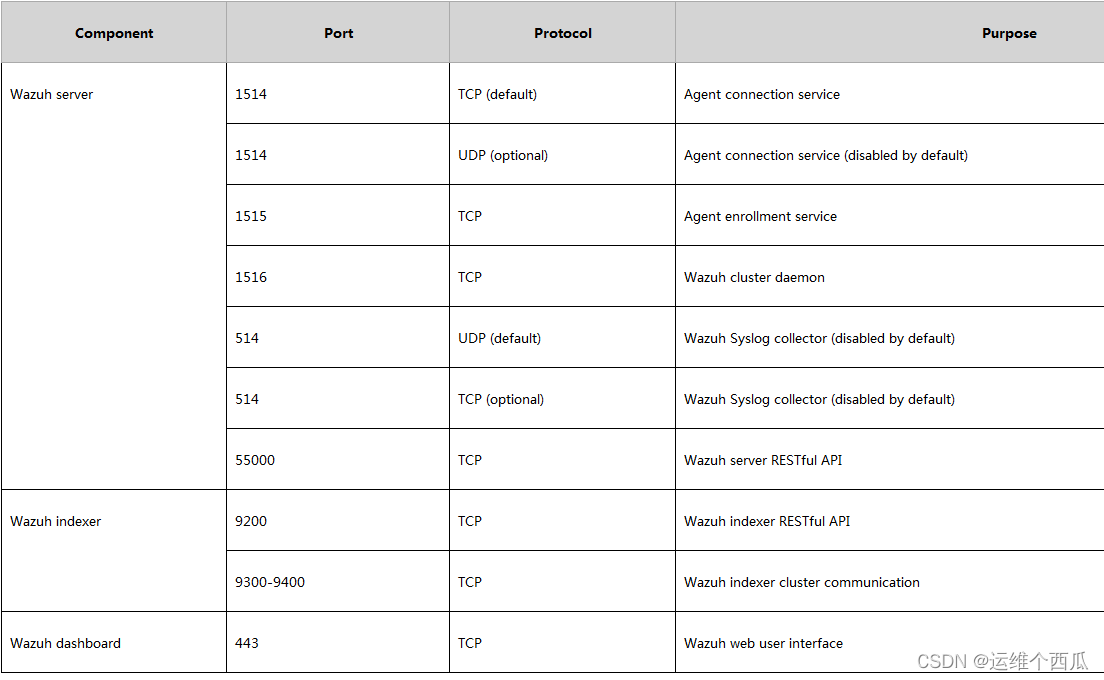
Wazuh開源主機安全解决方案的簡介與使用體驗

2017 USP Try-outs C. Coprimes

全排列的代码 (递归写法)

Hang wait lock vs spin lock (where both are used)
leetcode-6110:网格图中递增路径的数目
Solution to the palindrome string (Luogu p5041 haoi2009)
wordpress切换页面,域名变回了IP地址
Sword finger offer 04 Search in two-dimensional array
A misunderstanding about the console window
随机推荐
kubeadm系列-01-preflight究竟有多少check
Full Permutation Code (recursive writing)
The number of enclaves
CF1634E Fair Share
Developing desktop applications with electron
网络工程师考核的一些常见的问题:WLAN、BGP、交换机
26、 File system API (device sharing between applications; directory and file API)
剑指 Offer 35.复杂链表的复制
1.15 - 输入输出系统
常见的最优化方法
2022年貴州省職業院校技能大賽中職組網絡安全賽項規程
Daily question 2006 Number of pairs whose absolute value of difference is k
leetcode-22:括号生成
Fried chicken nuggets and fifa22
[cloud native] record of feign custom configuration of microservices
Annotation and reflection
Software test -- 0 sequence
全国中职网络安全B模块之国赛题远程代码执行渗透测试 //PHPstudy的后门漏洞分析
从Dijkstra的图灵奖演讲论科技创业者特点
Sword finger offer 53 - I. find the number I in the sorted array