当前位置:网站首页>论文阅读报告
论文阅读报告
2022-07-05 06:18:00 【mentalps】
0 2022/6/23-2022/6/25
1. FLAME: Taming Backdoors in Federated Learning
1.1 本文的贡献
- 我们提出了FLAME,这是一种针对FL中后门攻击的防御框架,能够消除后门而不影响聚合模型的良性性能。与早期的后门防御相反,FLAME适用于一般对手模型,即它不依赖于对手攻击策略的有力假设,也不依赖于良性和敌对数据集的底层数据分布。
- 我们表明,通过以下方法可以从根本上减少所需的高斯噪声:a)应用我们的聚类方法来删除潜在的恶意模型更新,b)将局部模型的权重裁剪到适当的水平,以限制单个(尤其是恶意)模型对聚合模型的影响。
- 我们为噪声注入(受DP启发)所需的高斯噪声量提供了噪声边界证明,以消除后门贡献。
- 我们对来自三个非常不同的应用领域的真实世界数据集的防御框架进行了广泛的评估。我们表明,FLAME减少了所需的噪声量,因此聚合模型的良性性能不会显著降低,与直接注入基于DP的噪声的最先进防御相比,它具有重要的优势。
1.2 问题设置和目标
后门特征描述: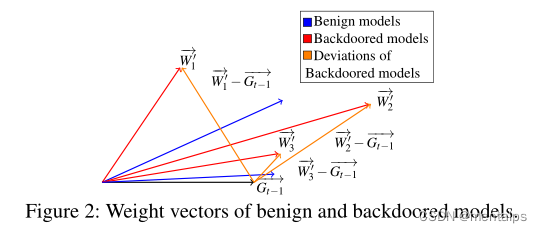
Benign models:良性模型;
Backdoored models:后门攻击模型;
Deviations of Backdoored models:后门模型的偏差;
G t − 1 G_{t-1} Gt−1:上一轮局部模型和全局模型之间的偏差;
W 1 , , W 2 , , W 3 , , W_{1}^{,},W_{2}^{,},W_{3}^{,}, W1,,W2,,W3,,:分别代表三种不同的后门攻击;
防御目标:
在FL环境下,能够有效缓解后门攻击的通用防御需要实现以下目标:(i)有效性:为了防止对手实现其攻击目标,必须消除后门模型更新的影响,以便聚合的全局模型不会显示后门行为。(ii)性能:必须保持全局模型的良性性能,以保持其效用。(iii)独立于数据分布和攻击策略:防御方法必须适用于一般对手模型,即不得要求事先了解后门攻击方法,或对本地客户端的特定数据分布作出假设,例如,数据是iid还是非iid。
1.2 FLAME概述和设计
动机:
早期的工作使用聚合模型的差异隐私启发噪声消除后门。它们确定了根据经验使用的足够数量的噪声。然而,在FL设置中,这是一个挑战,因为通常不能假设聚合器可以访问训练数据,尤其是有毒数据集。因此,需要一种通用方法来确定多少噪声足以有效地移除后门。另一方面,模型中注入的噪声越多,对其良性性能的影响就越大。
FLAME概述:
FLAME估计了在FL环境中后门拆除所需的噪声级,无需进行广泛的经验评估,也无需获取培训数据。此外,为了有效限制所需的噪声量,FLAME使用一种新的基于聚类的方法来识别和删除影响较大的对手模型更新,并应用动态权重裁剪方法来限制对手为提高性能而扩大的模型的影响。如§3所述,我们无法保证所有后门模型都能被检测到,因为对手可以完全控制角度和幅度偏差,使模型任意难以检测。因此,我们的聚类方法旨在删除具有高攻击影响(角度偏差较大)的模型,而不是所有恶意模型。图3说明了由上述三个组件组成的FLAME的高级概念:过滤、剪裁和噪声。然而,我们强调,这些组件中的每一个都需要非常小心地应用,因为噪声与聚类和剪裁的天真结合会导致不良结果,因为它很容易无法缓解后门和/或恶化模型的良性性能。
FLAME设计:
FLAME使用成对余弦距离来测量所有模型更新之间的角度差,并应用HDBSCAN聚类算法。这里的优点是,即使对手放大模型更新以增强其影响,余弦距离也不会受到影响,因为这不会改变更新权重向量之间的角度。由于HDBSCAN算法根据余弦距离分布的密度对模型进行聚类,并动态确定所需的聚类数。
步骤:
1.服务器获取n个用户的模型。
2.计算 n n n个模型两两之间的余弦相似度。
3.使用动态聚类算法HDBSCAN对两两之间的余弦相似度进行聚类,超过50 % 的类为良性更新。其他类均视为离群值,将其剔除,得到剩余的 L L L个良性模型。
4.对 n n n个模型中的每个模型计算和当前全局模型的欧式距离 ( e 1 , e 2 , . . . , e n ) (e_{1},e_{2},...,e_{n}) (e1,e2,...,en),并令其中值为 S t S_{t} St。
5.对于每一轮的 L L L个用聚类算法筛选出来的模型,令其动态自适应剪裁阈值为 γ = S t / e l \gamma=S_{t}/e_{l} γ=St/el。
6.计算剪裁后的局部模型 W l = G t − 1 + ( W l − G t − 1 ) ∗ M I N ( 1 , γ ) W_{l}=G_{t-1}+(W_{l}-G_{t-1})*MIN(1,\gamma) Wl=Gt−1+(Wl−Gt−1)∗MIN(1,γ)。
7.对剪裁后的局部模型赋予相同的权重进行聚合得到全局模型 G t G_{t} Gt。
8.基于局部模型之间的差异(距离)得到动态自适应噪声量 σ = λ ∗ S t \sigma=\lambda*S_{t} σ=λ∗St,其中超参数 λ \lambda λ是根据经验设置的噪声水平因子。
9.得到加噪后的全局模型 G t = G t + N ( 0 , σ 2 ) G_{t}=G_{t}+N(0,\sigma^{2}) Gt=Gt+N(0,σ2)。
0 2022/6/27
1 The Limitations of Federated Learning in Sybil Settings
主要idea:
1.对于每一个客户端 i i i,服务器保存其历史更新向量为 H i = ∑ t Δ i , t H_{i}=\sum_{t}\Delta_{i,t} Hi=∑tΔi,t。
2.寻找指示性特征。
3.计算客户端历史更新中指示性特征两两之间的余弦相似性 c s i , j cs_{i,j} csi,j,并令 v i v_{i} vi为客户端 i i i与其他所有客户端余弦相似性中的最大值。
4.两两之间的余弦相似性计算完毕之后,对于每一个客户端 i i i,如果存在另一个客户端 j j j满足 v j > v i v_{j}>v_{i} vj>vi ,则将客户端 i i i的 c s i , j cs_{i,j} csi,j修正为 c s i , j ∗ v i / v j cs_{i,j}*v_{i}/v_{j} csi,j∗vi/vj。通过重新衡量余弦相似度,可以使得诚实客户端与恶意客户端的相似性进一步减小,而恶意客户端与恶意客户端的相似性基本不变,从而减少误报。
5.计算每一个客户端 i i i的学习速率 a i = 1 − m a x j ( c s i ) a_{i}=1-max_{j}(cs_{i}) ai=1−maxj(csi)为并通过除以 a i a_{i} ai中的最大值,将其标准化缩放到0到1之间。
6.对每一个客户端的学习速率 a i a_{i} ai,使用以0.5为中心logit函数,使得接近0和1的学习速率变得更加发散。
7.将最终的学习速率与对应的模型更新相乘,得到聚合后的模型更新,并用其更新全局模型
0 2022/7/1
1 Defending Against Backdoors in Federated Learning with Robust Learning Rate
主要idea:
- 服务器获取 n n n个用户的局部更新。
- 对于每一个维度 j j j,服务器对 n n n个模型的第 j j j个参数求符号函数,再对符号函数的运算结果求和,即求 ∑ k = s g n ( Δ j k ) \sum_{k}=sgn(\Delta_{j}^{k}) ∑k=sgn(Δjk).
- 设置一个学习阈值的超参数 θ \theta θ,若 ∣ ∑ k s g n ( Δ j k ) ∣ |\sum_{k}sgn(\Delta_{j}^{k})| ∣∑ksgn(Δjk)∣,则 η j = − η \eta_{j}=-\eta ηj=−η。
- 选用一种聚合函数对局部更新进行聚合,唯一的区别是,每个参数的学习速率不是固定相同的 η \eta η,而是前面求出的 η j \eta_{j} ηj。
边栏推荐
- 高斯消元 AcWing 884. 高斯消元解异或线性方程组
- RGB LED infinite mirror controlled by Arduino
- 博弈论 AcWing 893. 集合-Nim游戏
- WordPress switches the page, and the domain name changes back to the IP address
- Niu Mei's math problems
- 容斥原理 AcWing 890. 能被整除的数
- [rust notes] 13 iterator (Part 2)
- Single chip computer engineering experience - layered idea
- Alibaba established the enterprise digital intelligence service company "Lingyang" to focus on enterprise digital growth
- Leetcode backtracking method
猜你喜欢
![Introduction to LVS [unfinished (semi-finished products)]](/img/72/d5a943a8d6d71823dcbd7f23dda35b.png)
Introduction to LVS [unfinished (semi-finished products)]
Sqlmap tutorial (II) practical skills I
Groupbykey() and reducebykey() and combinebykey() in spark
实时时钟 (RTC)
MIT-6874-Deep Learning in the Life Sciences Week 7

MySQL advanced part 2: SQL optimization
Appium automation test foundation - Summary of appium test environment construction

Network security skills competition in Secondary Vocational Schools -- a tutorial article on middleware penetration testing in Guangxi regional competition

Operator priority, one catch, no doubt

Arduino 控制的 RGB LED 无限镜
随机推荐
MySQL advanced part 2: MySQL architecture
【LeetCode】Easy | 20. Valid parentheses
liunx启动redis
Open source storage is so popular, why do we insist on self-development?
背包问题 AcWing 9. 分组背包问题
CPU内核和逻辑处理器的区别
Leetcode stack related
One question per day 1020 Number of enclaves
SQLMAP使用教程(二)实战技巧一
Error ora-28547 or ora-03135 when Navicat connects to Oracle Database
Series of how MySQL works (VIII) 14 figures explain the atomicity of MySQL transactions and the principle of undo logging
[2020]GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
MySQL advanced part 2: SQL optimization
Appium foundation - use the first demo of appium
LeetCode-61
[BMZCTF-pwn] ectf-2014 seddit
Leetcode dynamic programming
[rust notes] 16 input and output (Part 2)
[rust notes] 14 set (Part 1)
【Rust 笔记】13-迭代器(中)