当前位置:网站首页>[algorithm post interview] interview questions of a small factory
[algorithm post interview] interview questions of a small factory
2022-07-05 06:32:00 【Evening scenery at the top of the mountain】
List of articles
- zero 、 Project questions
- One 、 About bert Model and distillation problems :
- Two 、 About transformer The problem of :
- 3、 ... and 、 And Python Questions about :
- 3.1 How to exchange dimensions (transpose)、 Dimension transformation (reshape)?
- 3.2 The difference between dot product and matrix multiplication ?
- 3.3 How to sort dictionary values ?
- 3.4 SQL: Internal connection 、 Left connection 、 The difference between right connection ( All fields in the right table of the result set must exist and be displayed )?
- 3.5 Python What optimizations have been made in memory ?
- 3.6 How to save memory ?
- 3.7 Pandas Library how to read super large files ?
- 3.8 climb Insects :
- Four 、 Algorithm problem :
- 6、 ... and 、 Scene question :
- Reference
zero 、 Project questions
According to the background 、 difficulty 、 Solutions and results are four aspects .
0.1 background
Sometimes the interviewer and you have different directions , I'm not sure what problem your project is solving , At this time, it is necessary to quickly and clearly tell the background of the project . Including but not limited to What needs to be met , In what scene , What kind of task .
0.2 difficulty
There must be difficulties in a project , It is the problem that this project strives to solve , If it is a very simple thing, it is certainly not worth saying . We need to extract the difficult points in the project , For example, lack of data 、 The cost of large model training is high 、 Existing methods ignore XX Information / Conditions, etc .
0.3 Solution
Things done in the project , Including but not limited to How to analyze problems , How to design for difficulties . One of the questions that interviewers often ask is why A without B,A Than B What are the advantages , This kind of problem should be prepared in advance . This is where the interviewer's level is very reflected in the interview process , Great interviewers will ask many sharp and profound questions here .
0.4 result
The results are best presented in an intuitive way , For example, the accuracy of baseline comparison is improved XX%, Competition ranking XX,PV increase XX% etc. .
One 、 About bert Model and distillation problems :
1.1 The idea of distillation , Why distillation ?
Distillation of knowledge (Knowledge Distillation,KD) Is a commonly used method of knowledge transfer , Usually by teachers (Teacher) Models and students (student) Model composition . Knowledge distillation is like the process of teachers teaching students , Transfer knowledge from teacher model to student model , Make the student model as close as possible to the teacher model .
In a general way , A large model is often a single complex network or a collection of several networks , It has good performance and generalization ability , And the small model because the network scale is small , Limited ability to express . therefore , The knowledge learned from the large model can be used to guide the small model training , Make the small model have the same performance as the large model , But the number of parameters is greatly reduced , So as to realize model compression and acceleration , This is the application of knowledge distillation and transfer learning in model optimization .
1.2 The student model in distillation is ?
1.3 What distillation methods are there ?
- Three classical pre training models based on knowledge distillation :
- DistilBERT( Based on triple loss );
- TinyBERT( Mainly used Additional words vector layer distillation and intermediate layer distillation Further improve the effect of knowledge distillation );
- MobileBERT( Slimming version Bert-large Model ).

1、 Off line distillation
Offline distillation is the traditional distillation of knowledge , Pictured above (a). Users need to train a known dataset in advance teacher Model , Then I'm right student When the model is trained , Use what you get teacher The model is supervised to achieve the purpose of distillation , And this teacher The training accuracy is better than student The accuracy of the model should be high , The greater the difference , The more obvious the distillation effect . In general ,teacher The model parameters remain unchanged during the distillation training , Reach training student Purpose of the model . Loss function of distillation distillation loss Calculation teacher and student The difference between previous output predictions , and student Of loss Put it all together as a whole training loss, To do gradient update , Finally, we get a higher performance and precision student Model .
2、 Semi supervised distillation
Semi supervised distillation takes advantage of teacher The prediction information of the model is used as a label , Come on student Online supervised learning , Pictured above (b). So it's different from the traditional offline distillation way , In the face of student Before model training , First, enter the unmarked data of the part , utilize teacher The network output label is input into the student In the network , To complete the distillation process , This allows you to use a dataset with less dimensions , To improve the accuracy of the model .
3、 Self supervised distillation
Compared with the traditional off-line distillation, self supervised distillation does not need to train one in advance teacher A network model , It is student The network itself is trained to complete a distillation process , Pictured above (c). How to realize it There are many kinds of , For example, start training first student Model , Last few of the whole training process epoch When , Take advantage of the previous training student As a supervisory model , In the rest epoch in , Distill the model . The advantage of doing so is that you don't need to train in advance teacher Model , You can change training to distillation , Save the whole distillation process training time .
1.4 Bert What's your input ?
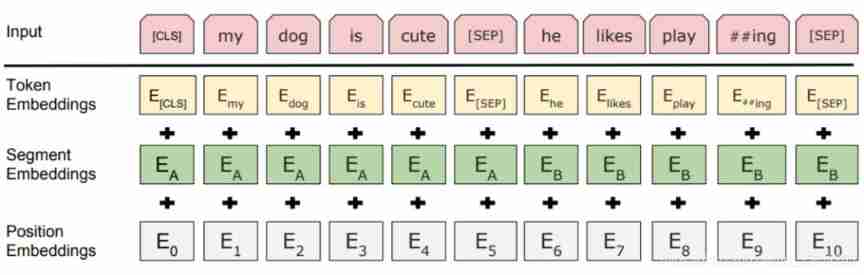
- The word vector
word_embeddings, In this paper subword Corresponding embedded . - Block vector
token_type_embeddings, Used to indicate the sentence in which the current word is located , Assist in distinguishing sentences from padding、 The difference between sentence pairs . - Position vector
position_embeddings, The position of each word in the sentence is embedded , Used to distinguish the order of words . and transformer The design in the paper is different , This one is trained , Not throughSinusoidalFunction to calculate the fixed embedding . It is generally believed that this implementation is not conducive to expansibility ( It is difficult to transfer directly to longer sentences ).
Three embedding Addition without weight , And through a layer LayerNorm+dropout Post output , Its size is (batch_size, sequence_length, hidden_size).
1.5 Word vector embedding How to train ?
Two 、 About transformer The problem of :
2.1 self-attention Understanding and function , Why divide by the root dk?
If we calculate the number of words in the first position in a sentence Attention Score( Attention score ), So the first score is q1 and k1 Inner product , The second score is q1 and k2 The dot product . And so on .
And each Attention Score( Attention score ) Divide ( d k e y ) \sqrt(d_{key}) (dkey) ( d k e y d_{key} dkey yes Key The length of the vector ), Of course, you can also divide by other numbers , Divide by a number so that in back propagation , The gradient is more stable ( Avoid vector dimensions d Too large leads to too large dot product result ).
2.2 Why do we need to Multi-head Attention?
By analogy CNN The function of using multiple filters at the same time , Intuitively speaking , The attention of bulls helps the network capture richer features / Information .
That's what the paper says :Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
About different representation subspaces, Take an example that is not necessarily appropriate : When you're browsing the web , You may pay more attention to dark text in terms of color , In terms of font, I will pay attention to the big 、 Bold text . The color and font here are two different representation subspaces . Focus on both color and font , It can effectively locate the emphasized content in the web page . Use multiple attention , That is to make comprehensive use of all aspects of information / features .
2.3 Layer normlization The role of ?
2.4 LN and BN The difference between ?
(1) The difference between the two
- In terms of operation :BN To the same batch The same characteristic data of all data in ; and LN It is to operate the same sample .
- From the perspective of feature dimension :BN in , Number of feature dimensions = mean value or The number of variances ;LN in , One batch There is
batch_sizeTwo means and variance .
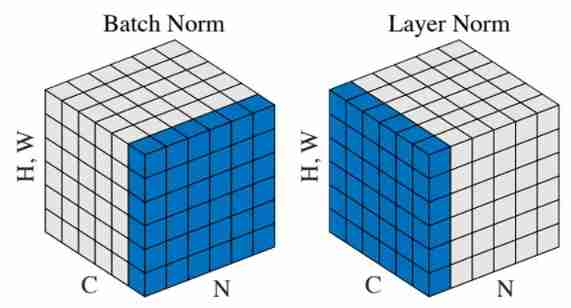
If in NLP Above C、N、H,W meaning :
N:N Sentence , namely batchsize;
C: The length of a sentence , namely seqlen;
H,W: Word vector dimension embedding dim.
(2)BN and LN The relationship between
- BN and LN Can better suppress gradient disappearance and gradient explosion .BN Not suitable for RNN、transformer Equal sequence network , Not suitable for text with variable length and
batchsizeIn smaller cases , Suitable for CV Medium CNN Wait for the Internet ; - and LN Suitable for use NLP Medium RNN、transformer Wait for the Internet , because sequence The length of may be inconsistent .
- chestnuts : If you put a batch of text into one batch,BN Is to operate the first word of each sentence ,BN Scaling for each position does not conform to NLP The law of .
(3) Summary
(1) after BN Normalized input activation function , Most of the obtained values will fall into the linear region of the nonlinear function , The derivative is far away from the derivative saturation region , Avoiding the disappearance of gradients , So as to speed up the training convergence process .
(2) Normalization technology is to stabilize the distribution of each layer , Let the back layer be based on the front layer “ Study with ease ”.BatchNorm By right batch size This dimension is normalized to stabilize the distribution ( however BN No solution ISC problem ).LayerNorm It's by talking to Hidden size This dimension is unified .
3、 ... and 、 And Python Questions about :
3.1 How to exchange dimensions (transpose)、 Dimension transformation (reshape)?
3.2 The difference between dot product and matrix multiplication ?
Dot product : Multiply two vectors with exactly the same dimension , We get a scalar .
matrix multiplication :( X ∗ N N ∗ Y = = > X ∗ Y X*N N*Y==>X*Y X∗NN∗Y==>X∗Y)
3.3 How to sort dictionary values ?
sorted You can also use the dictionary according to value Value to sort , This is a combination of lambda expression , among key = lambda kv:(kv[1], kv[0]) It means to follow kv[1] Sort the corresponding values ( Default from small to large ), And then according to kv[0] Sort the corresponding values ( Default from small to large ).
def dictionairy():
# Declaration Dictionary
key_value ={
}
# initialization
key_value[2] = 56
key_value[1] = 2
key_value[5] = 12
key_value[4] = 24
key_value[6] = 18
key_value[3] = 323
print (" By value (value) Sort :")
print(sorted(key_value.items(), key = lambda kv:(kv[1], kv[0])))
def main():
dictionairy()
if __name__=="__main__":
main()
The result is :
By value (value) Sort :
[(1, 2), (5, 12), (6, 18), (4, 24), (2, 56), (3, 323)]
3.4 SQL: Internal connection 、 Left connection 、 The difference between right connection ( All fields in the right table of the result set must exist and be displayed )?
3.5 Python What optimizations have been made in memory ?
3.6 How to save memory ?
( Convert numeric data to 32 Bit or 16 position , Manually reclaim unnecessary variables )
3.7 Pandas Library how to read super large files ?
( reads )
3.8 climb Insects :
a. The difference between multiprocessing and multithreading ?
The crawler program we write directly is single threaded , When the data demand is small, it can meet our needs .
But if there's a lot of data , For example, we need to visit hundreds of thousands url Go get the data , A single thread must wait for the current url After the access is completed and the data extraction and saving is completed, the next url To operate , Only one at a time url To operate ;
We use multithreading / More progress , You can achieve multiple url Operate at the same time . This will greatly reduce the running time of the crawler .
b. What are the means to solve anti climbing ?
The main idea of anti climbing is : Simulate the browser as much as possible , How the browser operates , How to implement it in the code . The browser requested the address first url1, Retain the cookie In the local , Then ask for the address url2, Take the previous cookie, It can also be implemented in code .
A lot of times , climb Carried by insects headers Field ,cookie Field ,url Parameters ,post There are a lot of parameters , It's not clear what's useful , What useless situations , Can only try , Because every website is different .
adopt headers Medium User-Agent Field to reverse crawl : adopt User-Agent If the field crawls backward , Just add it to him before the request User-Agent that will do , A better way is to use it User-Agent Pool to solve , We can consider collecting a pile User-Agent The way , Or randomly generated User-Agen
Four 、 Algorithm problem :
4.1 Longest substring without repeating characters
The sliding window :【LeetCode3】 Longest substring without repeating characters ( The sliding window )
4.2 Determine if the list has links 、 The entry to the link
Speed pointer , Actually sum 【 Circular list I】 almost , That is to judge whether there is a ring , Now the problem is to find the first node that begins to enter the ring . The same applies to fast and slow pointers , From the following figure , Because the speed of the fast pointer is set to that of the slow pointer 2 times ( Every time I walk with full pointer 1 Step , Let's go 2 Step ), from 2(F+a)= F+a+b+a, obtain F=b Key information . So when two pointers meet for the first time , Let's go back to head origin , At this time, let the fast pointer and the full pointer advance at the same speed , That is, go with the pointer F Step , Slow pointer b Step , You can reach the desired ring entrance , Have met .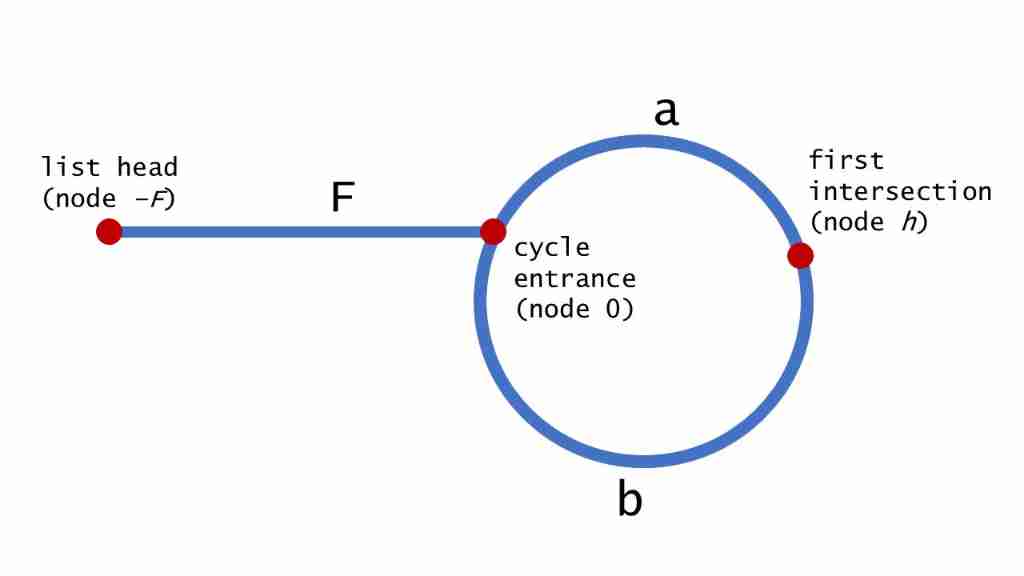
6、 ... and 、 Scene question :
How to assign problems to multi-level directories ?
Reference
[1] One minute brings you to know the distillation of knowledge in deep learning
[2] Niuke algorithm interview question
边栏推荐
- Stack acwing 3302 Expression evaluation
- [QT] QT multithreading development qthread
- 2. Addition and management of Oracle data files
- ‘mongoexport‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
- 5. Oracle TABLESPACE
- Winter messenger 2
- 博弈论 AcWing 893. 集合-Nim游戏
- LeetCode-54
- C Primer Plus Chapter 15 (bit operation)
- Knapsack problem acwing 9 Group knapsack problem
猜你喜欢
![[QT] QT multithreading development qthread](/img/7f/661cfb00317cd2c91fb9cc23c55a58.jpg)
[QT] QT multithreading development qthread
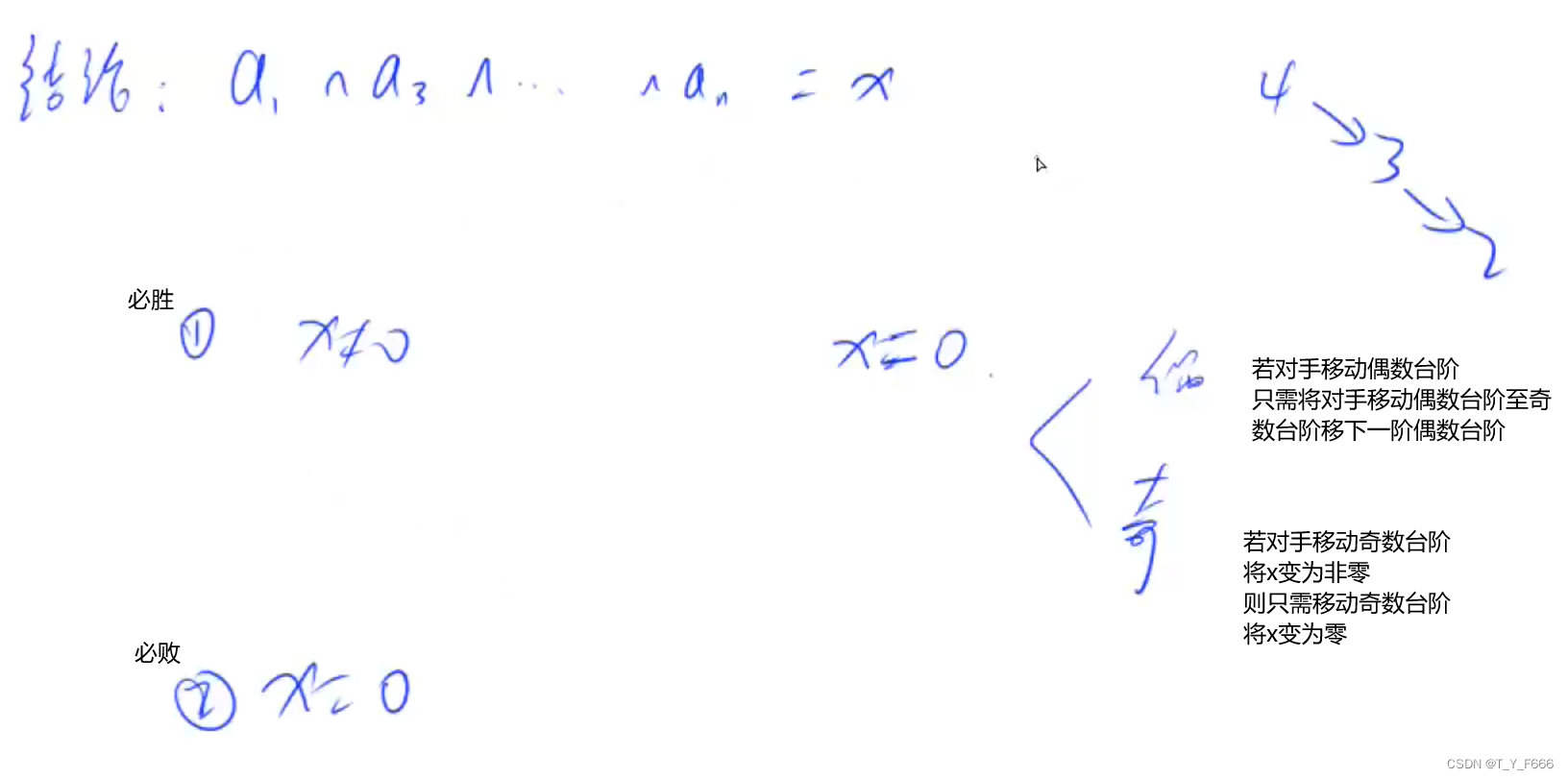
博弈论 AcWing 892. 台阶-Nim游戏
NVM Downloading npm version 6.7.0... Error

Game theory acwing 894 Split Nim game
LSA Type Explanation - detailed explanation of lsa-2 (type II LSA network LSA) and lsa-3 (type III LSA network Summary LSA)
Design specification for mobile folding screen
LeetCode-54
VLAN experiment
将webApp或者H5页面打包成App
SQL三种连接:内连接、外连接、交叉连接
随机推荐
2048项目实现
H5 module suspension drag effect
【高德地图POI踩坑】AMap.PlaceSearch无法使用
Chinese remainder theorem acwing 204 Strange way of expressing integers
3. Oracle control file management
达梦数据库全部
安装OpenCV--conda建立虚拟环境并在jupyter中添加此环境的kernel
C job interview - casting and comparing - C job interview - casting and comparing
Adg5412fbruz-rl7 applies dual power analog switch and multiplexer IC
P3265 [jloi2015] equipment purchase
PR automatically moves forward after deleting clips
TypeScript入门
[Chongqing Guangdong education] 1185t administrative leadership reference test of National Open University in autumn 2018
How to set the drop-down arrow in the spinner- How to set dropdown arrow in spinner?
[learning] database: several cases of index failure
Alibaba's new member "Lingyang" officially appeared, led by Peng Xinyu, Alibaba's vice president, and assembled a number of core department technical teams
Idea debug failed
[2020]GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
June 29, 2022 daily
Leetcode dynamic programming