当前位置:网站首页>Do you choose pandas or SQL for the top 1 of data analysis in your mind?
Do you choose pandas or SQL for the top 1 of data analysis in your mind?
2022-07-07 03:56:00 【Game programming】

author | Junxin
source | About data analysis and visualization
Today, Xiaobian is going to talk about Pandas and SQL Grammatical differences between , I believe for many data analysts , Whether it's Pandas Module or SQL , They are all very many tools used in daily study and work , Of course, we can also be in Pandas From the module SQL sentence , By calling read_sql() Method .
Building a database
First we pass SQL Statement is creating a new database , I'm sure everyone knows the basic grammar ,
CREATE TABLE Table name ( Field name data type ...)Let's take a look at the specific code
import pandas as pdimport sqlite3connector = sqlite3.connect('public.db')my_cursor = connector.cursor()my_cursor.executescript("""CREATE TABLE sweets_types( id integer NOT NULL, name character varying NOT NULL, PRIMARY KEY (id));... Limited space , Refer to the source code for details ...""")At the same time, we also insert data into these new tables , The code is as follows
my_cursor.executescript("""INSERT INTO sweets_types(name) VALUES ('waffles'), ('candy'), ('marmalade'), ('cookies'), ('chocolate');... Limited space , Refer to the source code for details ...""") We can view the new table through the following code , And convert it to DataFrame Data set in format , The code is as follows
df_sweets = pd.read_sql("SELECT * FROM sweets;", connector)output

We have built a total of 5 Data sets , It mainly involves desserts 、 Types of desserts and data of processing and storage , For example, the data set of desserts mainly includes the weight of desserts 、 Sugar content 、 Production date and expiration time 、 Cost and other data , as well as :
df_manufacturers = pd.read_sql("SELECT * FROM manufacturers", connector)output

The data set of processing involves the main person in charge and contact information of the factory , The warehouse data set involves the detailed address of the warehouse 、 City location, etc .
df_storehouses = pd.read_sql("SELECT * FROM storehouses", connector)output

And the dessert category data set ,
df_sweets_types = pd.read_sql("SELECT * FROM sweets_types;", connector)output

Data screening
Screening of simple conditions
Next, let's do some data screening , For example, the weight of desserts is equal to 300 The name of dessert , stay Pandas The code in the module looks like this
# Convert data type df_sweets['weight'] = pd.to_numeric(df_sweets['weight'])# Output results df_sweets[df_sweets.weight == 300].nameoutput
1 Mikus6 Soucus11 MacusName: name, dtype: object Of course, we can also pass pandas In the middle of read_sql() Method to call SQL sentence
pd.read_sql("SELECT name FROM sweets WHERE weight = '300'", connector)output

Let's look at a similar case , The screening cost is equal to 100 The name of dessert , The code is as follows
# Pandasdf_sweets['cost'] = pd.to_numeric(df_sweets['cost'])df_sweets[df_sweets.cost == 100].name# SQLpd.read_sql("SELECT name FROM sweets WHERE cost = '100'", connector)output
MiltyFor text data , We can also further screen out the data we want , The code is as follows
# Pandasdf_sweets[df_sweets.name.str.startswith('M')].name# SQLpd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M%'", connector)output
MiltyMikusMiviMiMisaMaltikMacus Of course. SQL Wildcards in statements , % Means to match any number of letters , and _ Means to match any letter , The specific differences are as follows
# SQLpd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M%'", connector)output

pd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M_'", connector)output

Screening of complex conditions
Let's take a look at data filtering with multiple conditions , For example, we want the weight to be equal to 300 And the cost price is controlled at 150 The name of dessert , The code is as follows
# Pandasdf_sweets[(df_sweets.cost == 150) & (df_sweets.weight == 300)].name# SQLpd.read_sql("SELECT name FROM sweets WHERE cost = '150' AND weight = '300'", connector)output
MikusOr the cost price can be controlled within 200-300 Dessert name between , The code is as follows
# Pandasdf_sweets[df_sweets['cost'].between(200, 300)].name# SQLpd.read_sql("SELECT name FROM sweets WHERE cost BETWEEN '200' AND '300'", connector)output

If it comes to sorting , stay SQL It uses ORDER BY sentence , The code is as follows
# SQLpd.read_sql("SELECT name FROM sweets ORDER BY id DESC", connector)output

And in the Pandas What is called in the module is sort_values() Method , The code is as follows
# Pandasdf_sweets.sort_values(by='id', ascending=False).nameoutput
11 Macus10 Maltik9 Sor8 Co7 Soviet6 Soucus5 Soltic4 Misa3 Mi2 Mivi1 Mikus0 MiltyName: name, dtype: object Select the dessert name with the highest cost price , stay Pandas The code in the module looks like this
df_sweets[df_sweets.cost == df_sweets.cost.max()].nameoutput
11 MacusName: name, dtype: objectAnd in the SQL The code in the statement , We need to first screen out which dessert is the most expensive , Then proceed with further processing , The code is as follows
pd.read_sql("SELECT name FROM sweets WHERE cost = (SELECT MAX(cost) FROM sweets)", connector) We want to see which cities are warehousing , stay Pandas The code in the module looks like this , By calling unique() Method
df_storehouses['city'].unique()output
array(['Moscow', 'Saint-petersburg', 'Yekaterinburg'], dtype=object) And in the SQL The corresponding sentence is DISTINCT keyword
pd.read_sql("SELECT DISTINCT city FROM storehouses", connector)Data grouping Statistics
stay Pandas Group statistics in modules generally call groupby() Method , Then add a statistical function later , For example, it is to calculate the mean value of scores mean() Method , Or summative sum() Methods, etc. , For example, we want to find out the names of desserts produced and processed in more than one city , The code is as follows
df_manufacturers.groupby('name').name.count()[df_manufacturers.groupby('name').name.count() > 1]output
nameMishan 2Name: name, dtype: int64 And in the SQL The grouping in the statement is also GROUP BY , If there are other conditions later , It's using HAVING keyword , The code is as follows
pd.read_sql("""SELECT name, COUNT(name) as 'name_count' FROM manufacturersGROUP BY name HAVING COUNT(name) > 1""", connector)Data merging
When two or more datasets need to be merged , stay Pandas Modules , We can call merge() Method , For example, we will df_sweets Data set and df_sweets_types Merge the two data sets , among df_sweets In the middle of sweets_types_id Is the foreign key of the table
df_sweets.head()output
df_sweets_types.head()output
The specific data consolidation code is as follows
df_sweets_1 = df_sweets.merge(df_sweets_types, left_on='sweets_types_id', right_on='id')output

We will further screen out chocolate flavored desserts , The code is as follows
df_sweets_1.query('name_y == "chocolate"').name_xoutput
10 Misa11 SorName: name_x, dtype: object and SQL The sentence is relatively simple , The code is as follows
# SQLpd.read_sql("""SELECT sweets.name FROM sweetsJOIN sweets_types ON sweets.sweets_types_id = sweets_types.idWHERE sweets_types.name = 'chocolate';""", connector)output

The structure of the data set
Let's take a look at the structure of the data set , stay Pandas View directly in the module shape Attribute is enough , The code is as follows
df_sweets.shapeoutput
(12, 10) And in the SQL In the sentence , It is
pd.read_sql("SELECT count(*) FROM sweets;", connector)output


Looking back
Share, collect, like and watch author :AI Technology base
Game programming , A game development favorite ~
If the picture is not displayed for a long time , Please use Chrome Kernel browser .
边栏推荐
- termux设置电脑连接手机。(敲打命令贼快),手机termux端口8022
- 【knife-4j 快速搭建swagger】
- Gpt-3 is a peer review online when it has been submitted for its own research
- Create commonly used shortcut icons at the top of the ad interface (menu bar)
- [safe office and productivity application] Shanghai daoning provides you with onlyoffice download, trial and tutorial
- ubuntu20安装redisjson记录
- 华为小米互“抄作业”
- QT 使用QToolTip 鼠标放上去显示文字时会把按钮的图片也显示了、修改提示文字样式
- [security attack and Defense] how much do you know about serialization and deserialization?
- First understand the principle of network
猜你喜欢

Function reentry, function overloading and function rewriting are understood by yourself
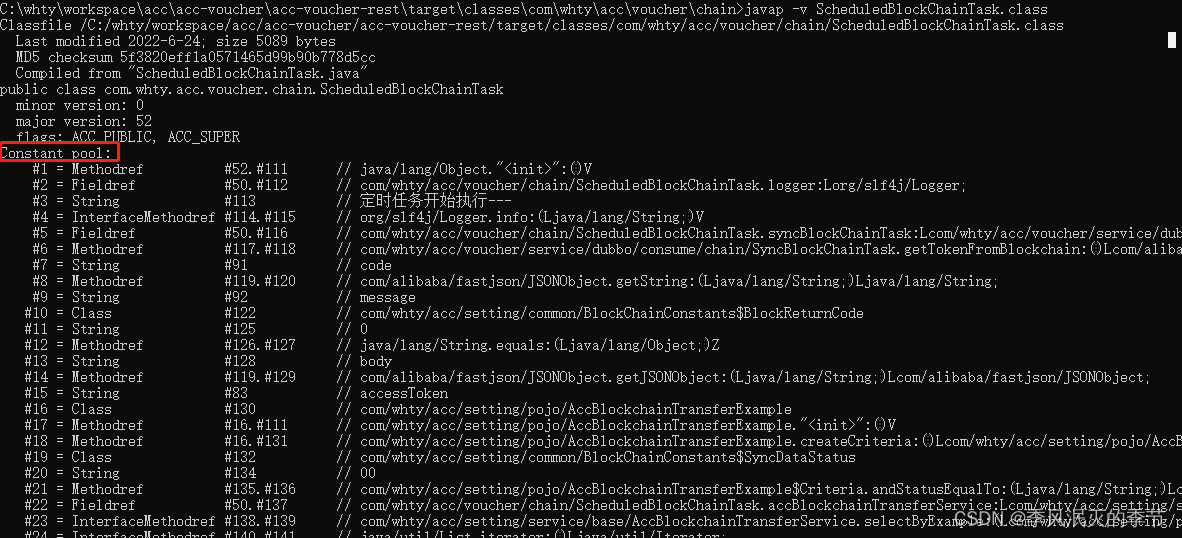
Class常量池与运行时常量池

19. (ArcGIS API for JS) ArcGIS API for JS line acquisition (sketchviewmodel)
![[hcie TAC] question 3](/img/d2/38a7286be7780a60f5311b2fcfaf0b.jpg)
[hcie TAC] question 3
Construction of Hisilicon universal platform: color space conversion YUV2RGB

Search of linear table

What is the experience of maintaining Wanxing open source vector database

21.(arcgis api for js篇)arcgis api for js矩形采集(SketchViewModel)

Probability formula
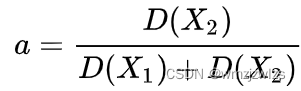
Kalman filter-1
随机推荐
QT thread and other 01 concepts
Can the applet run in its own app and realize live broadcast and connection?
The true face of function pointer in single chip microcomputer and the operation of callback function
MySQL的存储引擎
Construction of Hisilicon universal platform: color space conversion YUV2RGB
接口数据安全保证的10种方式
Free PHP online decryption tool source code v1.2
List interview common questions
Summer 2022 daily question 1 (1)
termux设置电脑连接手机。(敲打命令贼快),手机termux端口8022
你心目中的数据分析 Top 1 选 Pandas 还是选 SQL?
Kotlin Android environment construction
HW-小记(二)
Sorting operation partition, argpartition, sort, argsort in numpy
大白话高并发(二)
21. (article ArcGIS API for JS) ArcGIS API for JS rectangular acquisition (sketchviewmodel)
PIP download only, not install
A 股指数成分数据 API 数据接口
代码质量管理
QT item table new column name setting requirement exercise (find the number and maximum value of the array disappear)