当前位置:网站首页>Kafaka技术第一课
Kafaka技术第一课
2022-07-05 16:57:00 【teayear】
1,课程回顾
zk 分布式协调框架
2,本章重点
消息队列的概念
消息队列的特点和作用
常见的MQ框架有哪些
kafka的简介
基本术语
集群搭建,启动和关闭
常用命令
3,具体内容
3.1 消息队列(message queue)的概念
消息是在两台计算机之间传递的数据单位,它可以是简单的字符串,也可以是复杂的嵌入对象。消息队列是消息传递过程中保存消息的容器,将消息从源头中继到目标时充当中间人的角色。
3.2 消息队列的作用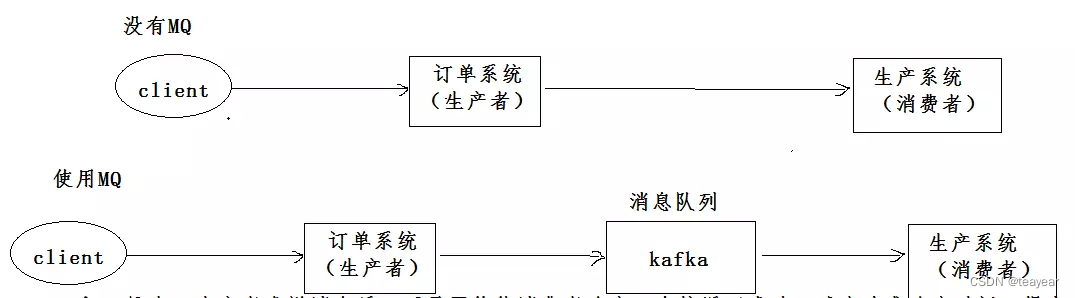
解耦:
A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果
C 系统现在不需要了呢?A 系统负责人几乎崩溃…A 系统跟其它各种乱七八糟的系统严重耦合,A 系统 产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。如果使用 MQ,A 系统产生一 条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统 压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超 时等情况。 就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但 是其实这个调用是不需要直接同步调用接口的,如果用 MQ 给它异步化解耦。
异步:
A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库
要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求。如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应 给用户,总时长是 3 + 5 = 8ms。
削峰:
减少高峰时期对服务器压力。 上游系统性能好,压力突然增大,下游系统性能稍差,承受不了突然增大的压力,这时候消息中间件就起到了削峰的作用。
使用场景:
当系统中出现生产和消费的速度和稳定性等因素不一致的时候,使用消息队列,作为中间层,来弥合双方的差异。
例子:业务系统中存在短信发送业务,处理定时任务等等
3.3 消息队列的两种模式
3.3.1 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。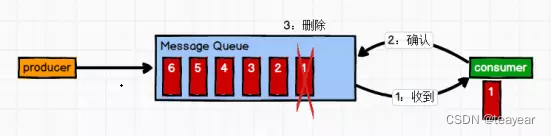
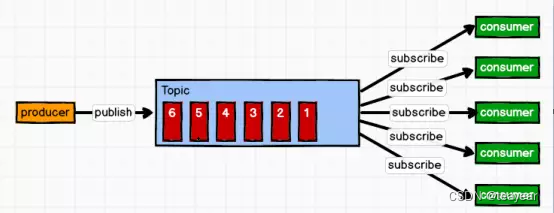
3.3.2 发布/订阅模式(一对多,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
3.4 常见的MQ框架有哪些
kafka activeMQ rabbitMQ zeroMQ metaMQ rocketMQ等等。。。
3.5 kafka简介
https://kafka.apachecn.org/
http://kafka.apache.org/
kafka是由apache软件基金会开发的一个开源流处理框架,由JAVA和scala语言编写。是一个高吞吐量的分布式的发布和订阅消息的一个系统。Kafka 用于构建实时的数据管道和流式的app.它可以水平扩展,高可用,速度快,并且已经运行在数千家公司的生产环境。
3.6 基本术语
topic(话题):kafka将消息分门别类,每一类的消息称之话题,是逻辑上的一个概念,如果是真正到磁盘上,映射的是一个partition的一个目录。
生产者(producer): 发布消息的对象称之为生产者,只负责数据的产生,生产的来源,可以不在kafka集群上,而是来自其他的业务系统。
消费者(consumer):订阅消息并处理发布消息的对象,称为消费者。
消费者组(consumerGroup):多个消费者可以构成消费者组,同一个消费者组的消费者,只能消费一个topic数据,不能重复消费。
broker : kafka本身可以是一个集群,集群中的每一个服务器都是一个代理,这个代理称为broker。只负责消息的存储,不管生产者和消费者,和他们没有任何关系。在集群中每个broker有唯一个ID,不能重复。
3.7 kafka集群的搭建,启动和关闭
3.7.1 搭建单机的zookeeper(集群最好)
使用现有的zookeeper集群
3.7.2 搭建kafka集群
在现有cluster1,2,3上搭建
上传kafka压缩包,到linux系统上
解压缩:
tar -xzvf /root/software/kafka_2.12-2.7.0.tgz -C /usr/
修改名称:
mv /usr/kafka_2.12-2.7.0/ /usr/kafka
配置环境变量:
vim /etc/profile
复制下面内容:
export KAFKA_HOME=/usr/kafka
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: Z K H O M E / b i n : / u s r / a p a c h e − t o m c a t − 9.0.52 / b i n : ZK_HOME/bin:/usr/apache-tomcat-9.0.52/bin: ZKHOME/bin:/usr/apache−tomcat−9.0.52/bin:KAFKA_HOME/bin
让配置文件生效:
source /etc/profile
测试:
echo $KAFKA_HOME
进入kafka目录:
cd /usr/kafka
创建目录(存放消息),为后面配置做准备
mkdir logs
修改配置server.properties文件:
vim /usr/kafka/config/server.properties
修改下面内容:
#broker的全局唯一编号,不能重复 21行
broker.id=0
#是否允许删除topic 22行
delete.topic.enable=true
#处理网络请求和响应的线程数量 42行
num.network.threads=3
#用来处理磁盘IO的线程数量 45
num.io.threads=8
#发送套接字的缓冲区大小 48
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小 51
socket.receive.buffer.bytes=102400
#请求套接字的最大缓冲区大小 54
socket.request.max.bytes=104857600
#kafka运行日志存放的路径 60
log.dirs=/usr/kafka/logs
#topic在当前broker上的分区个数 65
num.partitions=1
#用来恢复和清理data下数据的线程数量 69
num.recovery.threads.per.data.dir=1
#以下配置控制日志段的处理。可以将策略设置为在一段时间后或在给定大小累积后删除段。只要满足这些条件中的任一项,就会删除段。删除总是从日志的末尾开始。
#segment文件保留的最长时间,超时将被删除,单位小时,默认是168小时,也就是7天 103
log.retention.hours=168
#基于大小的日志保留策略。除非剩余的段低于log.retention.bytes,否则将从日志中删除段。独立于log.retention.hours的功能
#log.retention.bytes=1073741824
#日志段文件的最大大小。当达到此大小时,将创建一个新的日志段。
log.segment.bytes=1073741824
#检查日志段以查看是否可以根据保留策略删除日志段的间隔
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址 123
zookeeper.connect=hdcluster1:2181,hdcluster2:2181,hdcluster3:2181
因为配置文件中使用的zk主机名称链接,所以配置本地域名:
vim /etc/hosts
完整的hosts:
192.168.170.41 cluster1
192.168.170.42 cluster2
192.168.170.43 cluster3
修改producer.properties:
vim /usr/kafka/config/producer.properties
修改21行为:
bootstrap.servers=cluster1:9092,cluster2:9092,cluster3:9092
修改consumer.properties:
vim /usr/kafka/config/consumer.properties
修改19行为:
bootstrap.servers=cluster1:9092,cluster2:9092,cluster3:9092
发送配置好的kafka到另外两台机子(先做免密登录):
ssh-keygen -t rsa
ssh-copy-id cluster2
ssh-copy-id cluster3
scp -r /usr/kafka/ cluster2:/usr/
scp -r /usr/kafka/ cluster3:/usr/
检查发送是否成功,在all session执行:
ls /usr
修改broker.id(切记)
在cluster2和cluster3上修改broker.id
vim /usr/kafka/config/server.properties
修改21行为
broker.id=1
broker.id=2
发送环境变量配置文件:
scp -r /etc/profile cluster2:/etc/
scp -r /etc/profile cluster3:/etc/
在all session执行:
source /etc/profile
echo $KAFKA_HOME
发送hosts配置文件:
scp -r /etc/hosts cluster2:/etc/
scp -r /etc/hosts cluster3:/etc/
测试是否成功:
在all session执行:
cat /etc/hosts
3.7.3 集群的启动和关闭
启动kafka之前一定要保证zk在启动,并且可用:
启动zk:
/root/shelldir/zk-start-stop.sh
测试是否启动:
jps //在all session执行:
启动kafka:
//在all session执行
kafka-server-start.sh -daemon /usr/kafka/config/server.properties
jps
停止kafka:
kafka-server-stop.sh
jps
3.8 常用命令
查看当前服务器中的所有topic主题:
kafka-topics.sh --zookeeper cluster1:2181 --list
如果是zk集群可以使用这样的命令:
kafka-topics.sh --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --list
创建topic: list
kafka-topics.sh --zookeeper cluster2:2181 --create --replication-factor 3 --partitions 5 --topic ordertopic
kafka-topics.sh --zookeeper cluster2:2181 --create --replication-factor 2 --partitions 2 --topic goodstopic
参数说明:
–zookeeper 链接zk
–replication-factor 指定副本数目(副本数目不能大于总的brokers数目)
–partitions 指定分区数
–topic 指定topic名称
删除topic:
kafka-topics.sh --zookeeper cluster1:2181 --delete --topic tp3
This will have no impact if delete.topic.enable is not set to true
生产消息:
kafka-console-producer.sh --broker-list cluster2:9092 --topic goodstopic
消费消息:
kafka-console-consumer.sh --bootstrap-server cluster2:9092 --from-beginning --topic goodstopic
同组消费者消费消息(多个窗口):
kafka-console-consumer.sh --bootstrap-server kafka1:9092 --consumer-property group.id=gtest --from-beginning --topic tp1
查看一个topic详情:
kafka-topics.sh --zookeeper cluster2:2181,cluster1:2181 --describe --topic tp1
图片: https://uploader.shimo.im/f/qxOF7yGzME5lSY0F.png
partitioncount 分区总数量
replicationfactor 副本数量
partition 分区
leader 每个分区有3个副本,每个副本都有leader
replicas 所有副本节点,不管leader follower
isr: 正在服务中的节点
4,知识点总结
5,本章面试题
https://www.cnblogs.com/kx33389/p/11182082.html
https://blog.csdn.net/qq_28900249/article/details/90346599
kafka的分区中,有leader和follower如何同步数据,ISR(In Sync Replica)是什么意思?
5 个broker为例
leader follower
2 3 4 0 1
kafka不是完全同步,也不是完全异步,是一种特殊的ISR(In Sync Replica)
1.leader会维持一个与其保持同步的replica集合,该集合就是ISR,每一个partition都有一个ISR,它是由leader动态维护。
2.我们要保证kafka不丢失message,就要保证ISR这组集合存活(至少有一个存活),并且消息commit成功。
所以我们判定存活的概念是什么呢?分布式消息系统对一个节点是否存活有这样两个条件判断:
第一个,节点必须维护和zookeeper的连接,zookeeper通过心跳机制检查每个节点的连接;
第二个,如果节点时follower,它必要能及时同步与leader的写操作,不是延时太久。
如果满足上面2个条件,就可以说节点时“in-sync“(同步中的)。leader会追踪”同步中的“节点,如果有节点挂了,卡了,或延时太久,那么leader会它移除,延时的时间由参数replica.log.max.messages决定,判断是不是卡住了,由参数replica.log.time.max.ms决定。
边栏推荐
- Embedded-c Language-3
- BigDecimal除法的精度问题
- Database design in multi tenant mode
- Summary of optimization scheme for implementing delay queue based on redis
- 7.Scala类
- CMake教程Step6(添加自定义命令和生成文件)
- 忽米沄析:工业互联网标识解析与企业信息系统的融合应用
- C how TCP restricts the access traffic of a single client
- Use JDBC technology and MySQL database management system to realize the function of course management, including adding, modifying, querying and deleting course information.
- Use of ThinkPHP template
猜你喜欢

WR | 西湖大学鞠峰组揭示微塑料污染对人工湿地菌群与脱氮功能的影响

stirring! 2022 open atom global open source summit registration is hot!
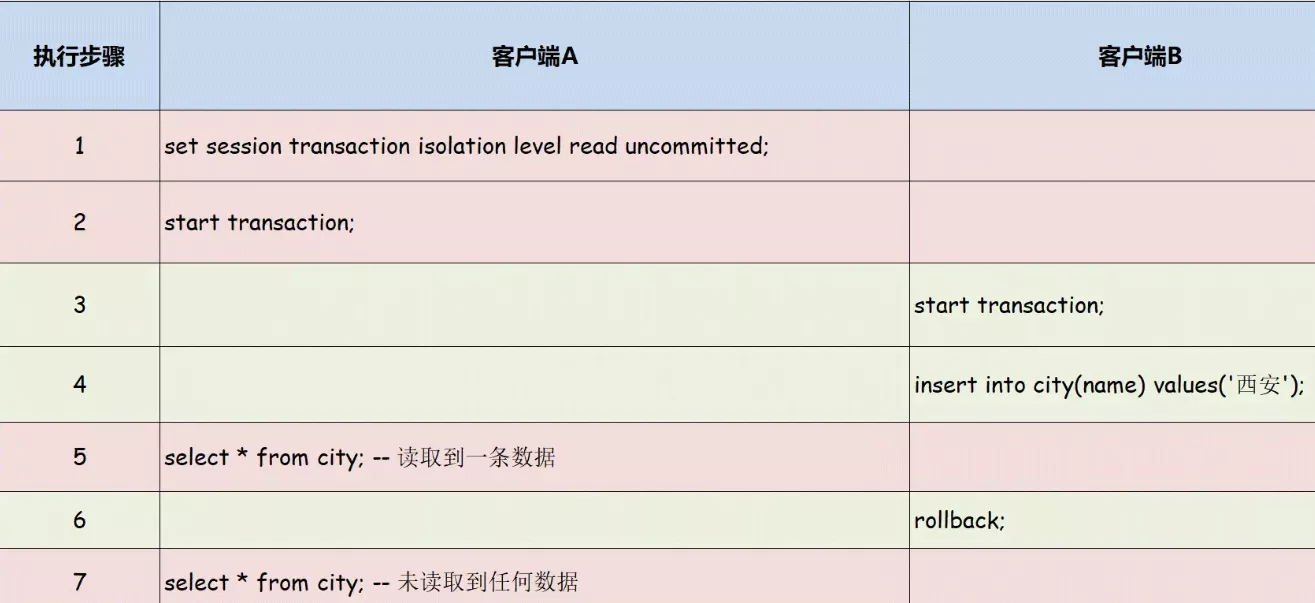
Learn about MySQL transaction isolation level
CMake教程Step2(添加库)
Rider set the highlighted side of the selected word, remove the warning and suggest highlighting

Deeply cultivate 5g, and smart core continues to promote 5g applications

Error in composer installation: no composer lock file present.
Summary of optimization scheme for implementing delay queue based on redis

IDC报告:腾讯云数据库稳居关系型数据库市场TOP 2!
mysql中取出json字段的小技巧

随机推荐
Machine learning 01: Introduction
Embedded-c Language-1
Etcd build a highly available etcd cluster
【jmeter】jmeter脚本高级写法:接口自动化脚本内全部为变量,参数(参数可jenkins配置),函数等实现完整业务流测试
MySQL queries the latest qualified data rows
叩富网开期货账户安全可靠吗?怎么分辨平台是否安全?
How MySQL uses JSON_ Extract() takes JSON value
The first lesson of EasyX learning
深耕5G,芯讯通持续推动5G应用百花齐放
flask解决CORS ERR 问题
IDC报告:腾讯云数据库稳居关系型数据库市场TOP 2!
张平安:加快云上数字创新,共建产业智慧生态
CMake教程Step1(基本起点)
7. Scala class
Browser rendering principle and rearrangement and redrawing
33:第三章:开发通行证服务:16:使用Redis缓存用户信息;(以减轻数据库的压力)
ClickHouse(03)ClickHouse怎么安装和部署
33: Chapter 3: develop pass service: 16: use redis to cache user information; (to reduce the pressure on the database)
一文了解Go语言中的函数与方法的用法
The first EMQ in China joined Amazon cloud technology's "startup acceleration - global partner network program"