当前位置:网站首页>Redis+caffeine two-level cache enables smooth access speed
Redis+caffeine two-level cache enables smooth access speed
2022-07-05 17:19:00 【Ma nongshen Shang】
In the design of high-performance service architecture , Caching is an indispensable part . In the actual project , We usually store some hot data in Redis or MemCache In this kind of caching middleware , Query the database only when the cache access does not hit . While improving access speed , It can also reduce the pressure on the database .
With continuous development , This architecture has also produced improvements , In some scenarios, you may simply use Redis The remote cache of class is not enough , It also needs to be further used with local cache , for example Guava cache or Caffeine, So as to improve the response speed and service performance of the program again . therefore , This results in using the local cache as the first level cache , Add the remote cache as the second level cache Two level cache framework .
Without considering complex problems such as concurrency , The access flow of two-level cache can be represented by the following figure :
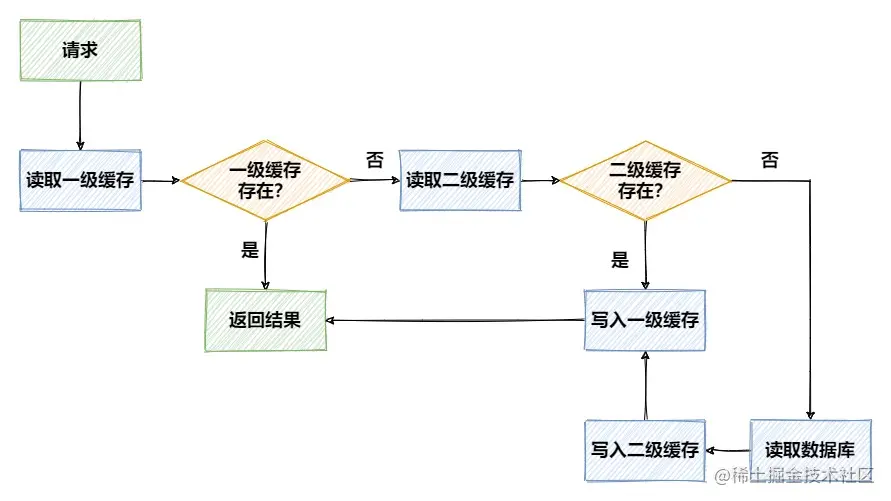
Advantages and problems
that , Using two-level cache is better than simply using remote cache , What are the advantages ?
- Local cache is based on the memory of the local environment , Very fast access , For some changes, the frequency is low 、 Data with low real-time requirements , Can be put in the local cache , Improve access speed
- Using local caching can reduce and
RedisData interaction between remote caches of classes , Reduce network I/O expenses , Reduce the time-consuming of network communication in this process
But in design , There are still some problems to consider , For example, data consistency . First , The two-level cache should be consistent with the data in the database , Once the data is modified , While modifying the database , Local cache 、 The remote cache should be updated synchronously .
in addition , In case of distributed environment , There will also be consistency problems between L1 caches , When the local cache under a node is modified , You need to notify other nodes to refresh the data in the local cache , Otherwise, the expired data will be read , This problem can be solved by something like Redis Release in / The subscription function solves .
Besides , Cache expiration time 、 Expiration strategy and multi-threaded access also need to be taken into account , But we won't consider these problems for the time being , Let's take a look at how to manage the two-level cache in code simply and efficiently .
preparation
After a brief review of the problems to be faced , Let's start the code practice of two-level cache , We integrate what is known as the strongest local cache Caffeine As a first level cache 、 The king of performance Redis As a second level cache . First build a springboot project , Introduce the relevant dependencies to be used in the cache :
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.8.1</version>
</dependency>
stay application.yml Middle configuration Redis Connection information :
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 10000ms
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
In the following example , We will use RedisTemplate Come on redis Read and write ,RedisTemplate Before use, you need to configure ConnectionFactory And serialization , This process is relatively simple, so we don't post the code , If you need all the sample code in this article, you can find it in At the end of the article .
Let's do it in a stand-alone environment , According to the different degree of business intrusion , It is divided into three versions to realize the use of two-level cache .
V1.0 edition
We can operate it manually Caffeine Medium Cache Object to cache data , It's a similar Map Data structure of , With key As index ,value Store the data . In the use of Cache front , You need to configure relevant parameters first :
@Configuration
public class CaffeineConfig {
@Bean
public Cache<String,Object> caffeineCache(){
return Caffeine.newBuilder()
.initialCapacity(128)// Initial size
.maximumSize(1024)// The largest number
.expireAfterWrite(60, TimeUnit.SECONDS)// Expiration time
.build();
}
}
A brief explanation Cache The significance of several relevant parameters :
initialCapacity: Initial cache empty sizemaximumSize: The maximum number of caches , Setting this value can avoid memory overflowexpireAfterWrite: Specify the expiration time of the cache , Is the time after the last write operation , here
Besides , The expiration policy of the cache can also be through expireAfterAccess or refreshAfterWrite Appoint .
After creation Cache after , We can inject and use it in business code . Before using any cache , A simple Service The layer code is as follows , Only crud operation :
@Service
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;
@Override
public Order getOrderById(Long id) {
Order order = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return order;
}
@Override
public void updateOrder(Order order) {
orderMapper.updateById(order);
}
@Override
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
}
Next , Right up there OrderService To transform , In addition to performing normal business, add the code that operates the two-level cache , Let's look at the query operation after transformation :
public Order getOrderById(Long id) {
String key = CacheConstant.ORDER + id;
Order order = (Order) cache.get(key,
k -> {
// First query Redis
Object obj = redisTemplate.opsForValue().get(k);
if (Objects.nonNull(obj)) {
log.info("get data from redis");
return obj;
}
// Redis If not, query DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(k, myOrder, 120, TimeUnit.SECONDS);
return myOrder;
});
return order;
}
stay Cache Of get In the method , Will first look in the cache , If the cached value is found, it returns directly . If not found, execute the following method , And add the results to the cache .
Therefore, the above logic is to find it first Caffeine Cache in , If you don't find Redis,Redis If it doesn't hit again, query the database , write in Redis The operation of cache needs to be written manually , and Caffeine Written by get How to do it yourself .
In the example above , Set up Caffeine Expires on 60 second , and Redis Expires on 120 second , So let's test that out , First look at the first interface call , Query the database :

And after that 60 When accessing the interface within seconds , Didn't print or type anything sql Or custom log content , It indicates that the interface does not query Redis Or database , Directly from Caffeine Cache read in .
Wait until the first time you call the interface for caching 60 Seconds later , Call the interface again :
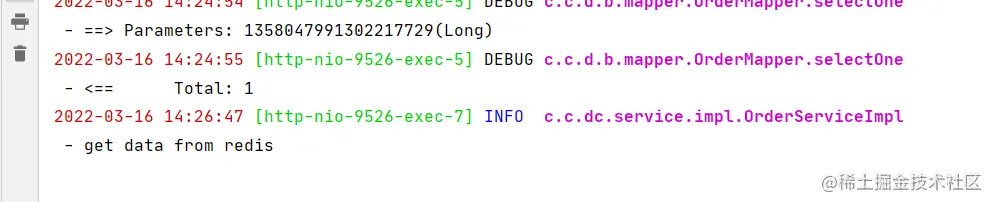
You can see from Redis Read data from , Because at this time Caffeine The cache in has expired , however Redis The cache in is not expired and is still available .
Let's take another look at the operation , The code adds manual modification to the original Redis and Caffeine The logic of caching :
public void updateOrder(Order order) {
log.info("update order data");
String key=CacheConstant.ORDER + order.getId();
orderMapper.updateById(order);
// modify Redis
redisTemplate.opsForValue().set(key,order,120, TimeUnit.SECONDS);
// Modify local cache
cache.put(key,order);
}
Take a look at the interface call in the figure below 、 And the cache refresh process . You can see that after updating the data , Synchronously flushed the contents of the cache , In the subsequent access interface, the database is not queried , You can also get the right results :
Finally, let's take a look at the deletion operation , While deleting data , Remove... Manually Reids and Caffeine Cache in :
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
String key= CacheConstant.ORDER + id;
redisTemplate.delete(key);
cache.invalidate(key);
}
After we delete a cache , When calling the previous query interface again , There will be a re query of the database :
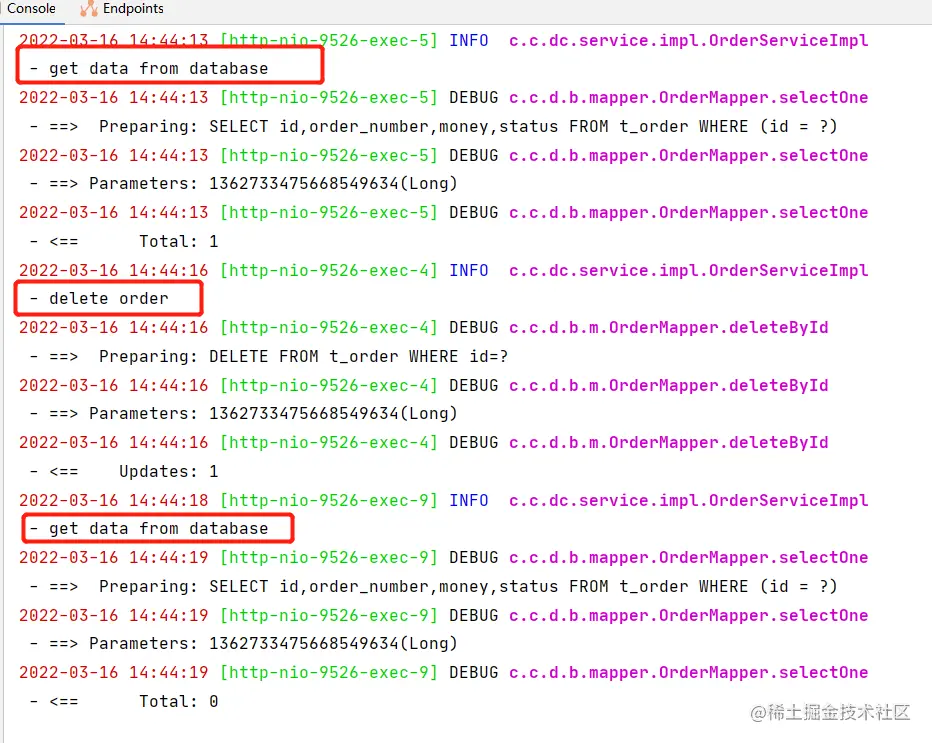
That's the end of the simple demonstration , You can see the above way of using cache , Although it doesn't seem like a big problem , But the code is more invasive . In the process of business processing, we should frequently operate the two-level cache , It will put a great burden on developers . that , What can be done to simplify this process ? Let's look at the next version .
V2.0 edition
stay spring In the project , Provides CacheManager Interface and some annotations , Allows us to manipulate the cache through annotations . Let's take a look at some common annotations :
@Cacheable: Take value from cache according to key , If the cache exists , After the cache is successfully obtained , Directly return the cached results . If the cache does not exist , Then the execution method , And put the results in the cache .@CachePut: Regardless of whether the cache corresponding to the previous key exists , All execution methods , And force the results into the cache@CacheEvict: After executing the method , Will remove the data from the cache .
If you want to use the above annotations to manage the cache , We don't need to configure V1 The type in the version is Cache Of Bean 了 , Instead, you need to configure spring Medium CacheManager Related parameters of , The configuration of specific parameters is the same as before :
@Configuration
public class CacheManagerConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager=new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.initialCapacity(128)
.maximumSize(1024)
.expireAfterWrite(60, TimeUnit.SECONDS));
return cacheManager;
}
}
Then add... To the startup class @EnableCaching annotation , You can use... Based on annotations in your project Caffeine Our cache supports . below , Again Service Layer code transformation .
First , Or transform the query method , Add... To the method @Cacheable annotation :
@Cacheable(value = "order",key = "#id")
//@Cacheable(cacheNames = "order",key = "#p0")
public Order getOrderById(Long id) {
String key= CacheConstant.ORDER + id;
// First query Redis
Object obj = redisTemplate.opsForValue().get(key);
if (Objects.nonNull(obj)){
log.info("get data from redis");
return (Order) obj;
}
// Redis If not, query DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(key,myOrder,120, TimeUnit.SECONDS);
return myOrder;
}
@Cacheable Annotation has as many attributes as 9 individual , Fortunately, we only need to configure two common ones for daily use . among value and cacheNames They are aliases to each other , Indicates where the results of the current method will be cached Cache On , In application through cacheName Come on Cache In isolation , Every cacheName Corresponding to one Cache Realization .value and cacheNames It can be an array , The binding of multiple Cache.
And another important attribute key, Used to specify the corresponding... When caching the returned results of the method key, This property supports the use of SpringEL expression . Usually , We can use the following ways as key:
# Parameter name
# Parameter object . Property name
#p The parameter corresponds to the subscript
In the code above , We see the addition of @Cacheable After the note , In the code, you only need to retain the original business processing logic and operations Redis Part of the code can ,Caffeine Part of the cache is left to spring Processed .
below , Let's transform the update method again , Again , Use @CachePut Remove the manual update after annotation Cache The operation of :
@CachePut(cacheNames = "order",key = "#order.id")
public Order updateOrder(Order order) {
log.info("update order data");
orderMapper.updateById(order);
// modify Redis
redisTemplate.opsForValue().set(CacheConstant.ORDER + order.getId(),
order, 120, TimeUnit.SECONDS);
return order;
}
Be careful , Here and V1 The version of the code is a little different , In the previous update operation method , There is no return value void type , But here you need to change the type of the return value , Otherwise, an empty object will be cached to the corresponding... In the cache key On . When the next query operation is executed , Will directly return an empty object to the caller , Instead of querying the database or... In the method Redis The operation of .
Last , The modification of the deletion method is very simple , Use @CacheEvict annotation , Method only needs to delete Redis Cache in :
@CacheEvict(cacheNames = "order",key = "#id")
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
redisTemplate.delete(CacheConstant.ORDER + id);
}
You can see , With the help of spring Medium CacheManager and Cache Related notes , Yes V1 Version of the code has been improved , The strong intrusion code mode of fully manual operation of two-level cache , Improve the local cache to spring management ,Redis Cache manually modified semi intrusion mode . that , It can be further transformed , Make it a completely non intrusive way to business code ?
V3.0 edition
imitation spring Manage the cache through annotations , We can also choose Custom annotations , Then process the cache in the slice , So as to minimize the intrusion of business code .
Define an annotation first , Used to add methods that need to operate the cache :
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DoubleCache {
String cacheName();
String key(); // Support springEl expression
long l2TimeOut() default 120;
CacheType type() default CacheType.FULL;
}
We use cacheName + key As a real cache key( There is only one Cache in , Do not do CacheName Isolation ),l2TimeOut For the L2 cache that can be set Redis The expiration time of ,type Is a variable of enumeration type , Indicates the type of operation cache , Enumeration types are defined as follows :
public enum CacheType {
FULL, // access
PUT, // Only exist
DELETE // Delete
}
Because to make key Support springEl expression , So you need to write a way , Use the expression parser to parse parameters :
public static String parse(String elString, TreeMap<String,Object> map){
elString=String.format("#{%s}",elString);
// Create an expression parser
ExpressionParser parser = new SpelExpressionParser();
// adopt evaluationContext.setVariable Variables can be set in context .
EvaluationContext context = new StandardEvaluationContext();
map.entrySet().forEach(entry->
context.setVariable(entry.getKey(),entry.getValue())
);
// Analytic expression
Expression expression = parser.parseExpression(elString, new TemplateParserContext());
// Use Expression.getValue() Get the value of the expression , Here comes Evaluation Context
String value = expression.getValue(context, String.class);
return value;
}
In the parameter elString The corresponding is in the annotation key Value ,map Is the result of encapsulating the parameters of the original method . A simple test :
public void test() {
String elString="#order.money";
String elString2="#user";
String elString3="#p0";
TreeMap<String,Object> map=new TreeMap<>();
Order order = new Order();
order.setId(111L);
order.setMoney(123D);
map.put("order",order);
map.put("user","Hydra");
String val = parse(elString, map);
String val2 = parse(elString2, map);
String val3 = parse(elString3, map);
System.out.println(val);
System.out.println(val2);
System.out.println(val3);
}
The results are as follows , You can see that the support is based on the parameter name 、 Read the property name of the parameter object , However, reading by parameter subscript is not supported , Leave a small pit for the time being and deal with it later .
123.0
Hydra
null
as for Cache Configuration of related parameters , We use V1 The configuration in the version is sufficient . The preparatory work is done , Let's define the section , Operate in section Cache Read and write Caffeine The cache of , operation RedisTemplate Reading and writing Redis cache .
@Slf4j @Component @Aspect
@AllArgsConstructor
public class CacheAspect {
private final Cache cache;
private final RedisTemplate redisTemplate;
@Pointcut("@annotation(com.cn.dc.annotation.DoubleCache)")
public void cacheAspect() {
}
@Around("cacheAspect()")
public Object doAround(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
// Splicing analysis springEl Of expression map
String[] paramNames = signature.getParameterNames();
Object[] args = point.getArgs();
TreeMap<String, Object> treeMap = new TreeMap<>();
for (int i = 0; i < paramNames.length; i++) {
treeMap.put(paramNames[i],args[i]);
}
DoubleCache annotation = method.getAnnotation(DoubleCache.class);
String elResult = ElParser.parse(annotation.key(), treeMap);
String realKey = annotation.cacheName() + CacheConstant.COLON + elResult;
// Force update
if (annotation.type()== CacheType.PUT){
Object object = point.proceed();
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
cache.put(realKey, object);
return object;
}
// Delete
else if (annotation.type()== CacheType.DELETE){
redisTemplate.delete(realKey);
cache.invalidate(realKey);
return point.proceed();
}
// Reading and writing , Inquire about Caffeine
Object caffeineCache = cache.getIfPresent(realKey);
if (Objects.nonNull(caffeineCache)) {
log.info("get data from caffeine");
return caffeineCache;
}
// Inquire about Redis
Object redisCache = redisTemplate.opsForValue().get(realKey);
if (Objects.nonNull(redisCache)) {
log.info("get data from redis");
cache.put(realKey, redisCache);
return redisCache;
}
log.info("get data from database");
Object object = point.proceed();
if (Objects.nonNull(object)){
// write in Redis
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
// write in Caffeine
cache.put(realKey, object);
}
return object;
}
}
The following work is mainly done in the section :
- Through the parameters of the method , Parsing comments
keyOfspringElexpression , Assemble the real cachekey - Depending on the type of operation cache , Handle access separately 、 Only exist 、 Delete cache operation
- Delete and force update of cache , All need to execute the original method , And perform corresponding cache deletion or update operations
- Before access , First check if there is data in the cache , Direct return if any , If not, execute the original method , And cache the results
modify Service Layer code , Only the original business code is retained in the code , Add our custom annotation :
@DoubleCache(cacheName = "order", key = "#id", type = CacheType.FULL)
public Order getOrderById(Long id) {
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return myOrder;
}
@DoubleCache(cacheName = "order",key = "#order.id", type = CacheType.PUT)
public Order updateOrder(Order order) {
orderMapper.updateById(order);
return order;
}
@DoubleCache(cacheName = "order",key = "#id", type = CacheType.DELETE)
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
Come here , The transformation of cache based on slice operation is completed ,Service The code is also instantly refreshing a lot , Let's continue to focus on business logic processing , Instead of bothering to operate the two-level cache .
summary
According to the decreasing degree of business intrusion , Three methods of managing two-level cache are introduced in turn . As for whether you need to use L2 cache in your project , You need to consider your own business situation , If Redis This remote cache has been able to meet your business needs , Then there is no need to use the local cache . After all, the actual use is far from that simple , This article only introduces the most basic use , Concurrency in practice 、 Transaction rollback needs to be considered , You also need to think about what data is suitable for the first level cache 、 What data is suitable for the second level cache and other problems .
that , This sharing is here , I am a Hydra, See you next time .
All the code examples of this article have been passed to Hydra Of Github On , Students in need can take it by themselves ~
Git Address :
Author's brief introduction ,
Manongshen, An official account of sharing love , Interesting 、 thorough 、 direct , Talk to you about technology .
I am participating in the recruitment of nuggets technology community creator signing program , Click the link to sign up for submission .
边栏推荐
- 33:第三章:开发通行证服务:16:使用Redis缓存用户信息;(以减轻数据库的压力)
- 一个满分的项目文档是如何书写的|得物技术
- CMake教程Step5(添加系统自检)
- China Radio and television officially launched 5g services, and China Mobile quickly launched free services to retain users
- The survey shows that the failure rate of traditional data security tools in the face of blackmail software attacks is as high as 60%
- 启牛商学院股票开户安全吗?靠谱吗?
- [Jianzhi offer] 61 Shunzi in playing cards
- 机器学习01:绪论
- MySql 查询符合条件的最新数据行
- 【机器人坐标系第一讲】
猜你喜欢

Error in composer installation: no composer lock file present.

Embedded UC (UNIX System Advanced Programming) -1

Machine learning compilation lesson 2: tensor program abstraction

stirring! 2022 open atom global open source summit registration is hot!
Learn about MySQL transaction isolation level

The two ways of domestic chip industry chain go hand in hand. ASML really panicked and increased cooperation on a large scale

国内首家 EMQ 加入亚马逊云科技「初创加速-全球合作伙伴网络计划」

Deeply cultivate 5g, and smart core continues to promote 5g applications
一文了解MySQL事务隔离级别

American chips are no longer proud, and Chinese chips have successfully won the first place in emerging fields
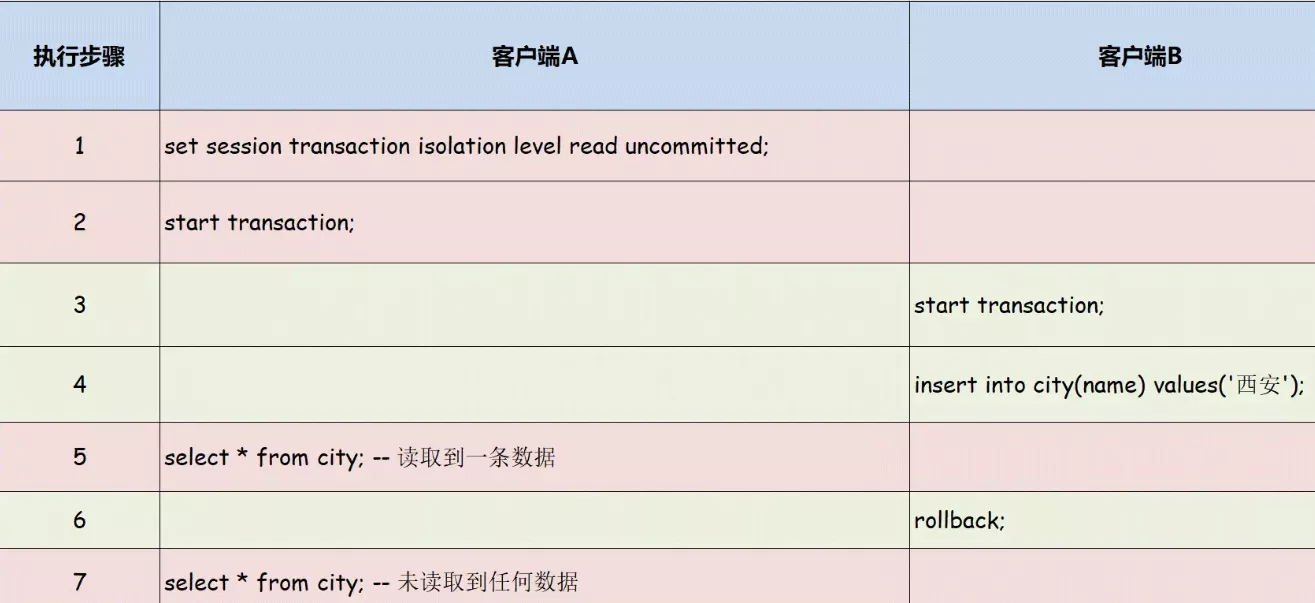
随机推荐
ClickHouse(03)ClickHouse怎么安装和部署
Etcd 构建高可用Etcd集群
[Jianzhi offer] 62 The last remaining number in the circle
The first EMQ in China joined Amazon cloud technology's "startup acceleration - global partner network program"
Error in compiling libssh2. OpenSSL cannot be found
WR | 西湖大学鞠峰组揭示微塑料污染对人工湿地菌群与脱氮功能的影响
thinkphp3.2.3
干货!半监督预训练对话模型 SPACE
Embedded-c Language-3
C how TCP restricts the access traffic of a single client
阈值同态加密在隐私计算中的应用:解读
CMake教程Step2(添加库)
The survey shows that the failure rate of traditional data security tools in the face of blackmail software attacks is as high as 60%
【剑指 Offer】61. 扑克牌中的顺子
ECU introduction
C# TCP如何设置心跳数据包,才显得优雅呢?
Writing method of twig array merging
张平安:加快云上数字创新,共建产业智慧生态
Thoughtworks 全球CTO:按需求构建架构,过度工程只会“劳民伤财”
Is it safe for qiniu business school to open a stock account? Is it reliable?