当前位置:网站首页>Evolution of MySQL database architecture
Evolution of MySQL database architecture
2022-07-04 04:04:00 【Melting pole】
summary
Cluster and distributed concepts
Cluster concept : Bring multiple servers together , Deal with the same business ; With scalability 、 High availability .
In a narrow sense, the concept of cluster is that multiple servers are clustered together , Each server handles the same business .
The concept of generalized cluster is that multiple servers are clustered together , The server may handle the same business and different businesses .
Clusters can be distributed or non distributed .
Distributed concept : Different businesses are distributed in different nodes , Each node can use cluster processing .
In a narrow sense, distribution is similar to clustering , The organization is relatively loose , Not as organized as a cluster , A server is abnormal , Others can be pushed up immediately ; Each distributed node handles different businesses , A node exception , The whole business cannot be handled .
Cluster and distribution are two dimensional concepts , Distributed refers to the concept of architecture , Different nodes handle different businesses ; Cluster refers to the physical concept , That is to put multiple machines together to process business .
Distributed may or may not be clustered .
Distributed database concept
Distributed database refers to the use of high-speed network to connect physically dispersed multiple data storage units to form a logically unified database .
The basic idea of distributed database is to distribute the data in the original centralized database to multiple data storage nodes connected through the network , To obtain larger storage capacity and higher concurrent access .
In recent years , As the volume of data grows , Distributed database technology has also developed rapidly , The traditional relational database starts from centralized mode to distributed storage , From centralized computing to distributed computing .
The main purpose of distributed database system is disaster recovery 、 Remote data backup , And through the principle of proximity , Users can access the nearest database node , This is the realization of remote load balancing . meanwhile , Synchronization through data transmission between databases , It can maintain the consistency of data in a distributed way , This process completes the data backup , Data stored in different places will not affect service access in case of a single point of failure , Just switch the access traffic to the remote image .
The advantages of distributed database application are as follows :
- Suitable for distributed database management , It can effectively provide system performance .
- The system is economical and flexible .
- The system has strong reliability and availability .
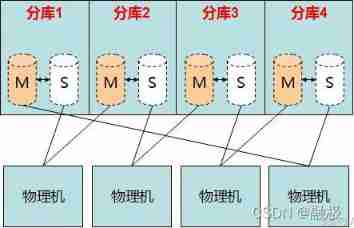
mysql The main technology of distributed application
mysql Data cutting
Data cutting (sharding) Means through a specific condition , Distribute the data stored in the same database to multiple databases ( host ) above , In order to achieve the effect of distributing the load of single equipment . Data segmentation can also improve the overall availability of the system , Because a single machine crash after , It's just that some part of the overall data doesn't work , Not all the data .
According to the type of segmentation rules , It can be divided into two segmentation modes . One is to segment into different databases according to different tables ( host ) above , This segmentation is called data verticality ( Vertical segmentation ) segmentation ; The other is based on the logical relationship of the data in the table , Split the data in the same table into multiple databases according to certain conditions ( host ) above , This segmentation is called data level ( The transverse ) segmentation .
The specific rule of vertical segmentation is simple , Easier to implement , It is especially suitable for businesses with low coupling , Little mutual influence 、 A very clear system of business logic . In this system, it is easy to split the tables used by different business modules into different databases . Split into different tables , Less impact on Applications , The splitting rules will be simple and clear .
Horizontal splitting is a little more complicated than vertical splitting , Because you want to split different data in the same table into different databases , For applications , The splitting rule itself is complex , Later data maintenance is also more complicated .
Why segment data
- When the load is high ,Master-Slaver There are bottlenecks in the pattern . In the existing technology , Use the relevant... At the high point of the load Replication Mechanism to achieve related read-write throughput performance . There are two bottlenecks in this mechanism : First, effectiveness depends on the proportion of read operations , here Master Often become the bottleneck , Write operations require a sequential queue to execute , Overload Master Can't bear ,Slaver The data synchronization delay will also be very large , It will also consume CPU Computing power , by write Operation in Master After the implementation on, it still needs to be on each Slave The machine is synchronized once . and Sharding You can easily calculate 、 Storage 、I/O Parallel distribution to multiple machines , In this way, various processing capacities of multiple machines can be fully utilized , At the same time, it can avoid single point of failure , Provide system availability , Good error isolation .
- With free MySQL And cheap Server Even PC Clustering , Achieve minicomputer + Large commercial DB The effect of , Reduce a lot of capital investment , Reduce operating costs , Why not .
Data integration solutions
Mysql5.1 The above versions all support the data table partition function . The data in the database is stored in different database hosts after vertical or horizontal segmentation , The main problem faced by the application system is how to integrate these data sources better , There are usually two solutions .
- In each application module, configure one that you need to manage yourself ( Or more ) data source , Direct access to various databases , Complete data integration in modules .
- Manage all data sources through the middle agent layer , The database cluster after is transparent to the front-end application .
Second option , Although in the short term, the cost may be larger , But for the scalability of the whole system , It was very helpful .
mysql Read / write separation
Read write separation is the use of database replication technology , Distribute read and write on different processing nodes , So as to improve availability and scalability . Main database provides write operation , Provide read operation from database . When the master database writes , Data should be synchronized to the slave database , In this way, database integrity can be effectively guaranteed .Mysql It also has its own synchronous data technology .Mysql Copy data through binary logs , After the master database is synchronized to the slave database , The slave database is generally composed of multiple databases , Only in this way can we achieve the purpose of reducing pressure . Read operations should be distributed to different servers according to the pressure of the server , Instead of simple random assignment .Mysql Provides mysql proxy Realize read-write separation operation .
At present, the more common mysql The separation of reading and writing can be divided into the following two types .
- Based on the internal implementation of program code
In the code according to select、insert Route classification , This kind of method is also the most widely used in the current production environment . - Based on the intermediate agent layer
The agent is between the client and the server , After receiving the client request, the proxy server forwards it to the back-end database through judgment .
mysql colony
Mysql Cluster Technology in distributed systems is Mysql Data provides redundancy , Enhanced security , To make a single mysql Server failure will not have a huge negative effect on the system , The stability of the system is guaranteed .
Mysql cluster use shared-nothing( No sharing ) framework .Mysql custer Mainly used NDB Storage engine to achieve ,NDB The storage engine is a memory storage engine , It is required that all data must be loaded into memory . The data is automatically distributed on different storage nodes in the cluster , Each storage node stores only one slice of complete data (fragment). meanwhile , Users can set the same data to be saved on multiple different storage nodes , To ensure that a single point of failure will not cause data loss .
Mysql cluster Need a set of computers , The role of each computer may be different .Mysql cluster According to the node type, it can be divided into 3 class : The management node ( Manage other nodes )、 Data nodes ( Deposit cluster Data in , There can be multiple ) and mysql node ( Storage table structure , There can be multiple ).Cluster A computer in can be a node , It can also be 2 To plant or 3 A collection of nodes . this 3 These nodes are only logically divided , So they don't necessarily have a one-to-one correspondence with physical computers . Multiple nodes can be distributed in different geographical locations , So it is also a scheme to realize distributed database .
Mysql The emergence of clusters well realizes the load balancing of databases , Reduce the pressure of data center nodes and big data processing , When the central node of the database fails , The cluster will adopt certain strategies to switch to other backup nodes , The fault problem is effectively shielded , The failure of a single node will not affect the external service of the entire database . And through the use of database cluster architecture , The master and slave databases are synchronized and redundant at all times , Databases are multipoint 、 A distributed , Well completed the backup of database data , Avoid data loss .
Reference resources
mysql The difference between cluster and distributed database
MySQL Cluster architecture
边栏推荐
- 支持首次触发的 Go Ticker
- STM32外接DHT11显示温湿度
- Simple dialogue system -- text classification using transformer
- warning: LF will be replaced by CRLF in XXXXXX
- 华为云鲲鹏工程师培训(广西大学)
- Exercices de renforcement des déclarations SQL (MySQL 8.0 par exemple)
- Objective-C member variable permissions
- 【webrtc】m98 ninja 构建和编译指令
- MySQL maxscale realizes read-write separation
- Aperçu du code source futur - série juc
猜你喜欢
Infiltration practice guest account mimikatz sunflower SQL rights lifting offline decryption
SQL語句加强練習(MySQL8.0為例)

Select sorting and bubble sorting template
![[untitled]](/img/b5/bf76783aa428222623d760756a14d9.jpg)
[untitled]

Audio and video technology development weekly | 232
三菱M70宏变量读取三菱M80公共变量采集三菱CNC变量读取采集三菱CNC远程刀补三菱机床在线刀补三菱数控在线测量
Objective-C description method and type method

Consul of distributed service registration discovery and unified configuration management
Pytest multi process / multi thread execution test case

Defensive programming skills
随机推荐
Object oriented -- encapsulation, inheritance, polymorphism
华为云鲲鹏工程师培训(广西大学)
postgresql 用户不能自己创建表格配置
MySQL is dirty
What kind of experience is it when the Institute earns 20000 yuan a month!
Package details_ Four access control characters_ Two details of protected
STM32外接DHT11显示温湿度
CesiumJS 2022^ 源码解读[0] - 文章目录与源码工程结构
Infiltration practice guest account mimikatz sunflower SQL rights lifting offline decryption
mysql数据库的存储
2022-07-03: there are 0 and 1 in the array. Be sure to flip an interval. Flip: 0 becomes 1, 1 becomes 0. What is the maximum number of 1 after turning? From little red book. 3.13 written examination.
潘多拉 IOT 开发板学习(HAL 库)—— 实验6 独立看门狗实验(学习笔记)
Consul of distributed service registration discovery and unified configuration management
Add IDM to Google browser
Select sorting and bubble sorting template
Deep thinking on investment
智慧地铁| 云计算为城市地铁交通注入智慧
JDBC 进阶
MySQL maxscale realizes read-write separation
Katalon中控件的参数化