当前位置:网站首页>yolov5目標檢測神經網絡——損失函數計算原理
yolov5目標檢測神經網絡——損失函數計算原理
2022-07-05 11:36:00 【網絡星空(luoc)】
文章目錄
前面已經寫了4篇關於yolov5的文章,鏈接如下:
1、基於libtorch的yolov5目標檢測網絡實現——COCO數據集json標簽文件解析
2、基於libtorch的yolov5目標檢測網絡實現(2)——網絡結構實現
3、基於libtorch的yolov5目標檢測網絡實現(3)——Kmeans聚類獲取anchor框尺寸
4、C++實現Kmeans聚類算法獲取COCO目標檢測數據集的anchor框
其中:
第一篇講COCO數據集json標簽的解析;
第二篇講yolov5神經網絡正向傳播的liborch實現;
第三篇講使用Opencv提供的Kmeans算法來獲取anchor框尺寸;
第四篇講自己使用C++實現的Kmeans算法來獲取anchor框尺寸,相對來說,本篇獲取的anchor比第三篇獲取的更精確。
本文我們主要講yolov5網絡的損失函數計算原理。
目標檢測結果精確度的度量
目標檢測任務有三個主要目的:
(1)檢測出圖像中目標的比特置,同一張圖像中可能存在多個檢測目標;
(2)檢測出目標的大小,通常為恰好包圍目標的矩形框;
(3)對檢測到的目標進行識別分類。
所以,判斷檢測結果精確不精確,主要基於以上三個目的來衡量:
(1)首先我們來定義理想情况:圖像中實際存在目標的所有比特置,都被檢測出來。檢測結果越接近這個理想狀態,也即漏檢/誤檢的目標越少,則認為結果越精確;
(2)同樣定義理想情况:檢測到的矩形框恰好能包圍檢測目標。檢測結果越接近這個理想狀態,那麼認為結果越精確;
(3)對檢測到的目標,進行識別與分類,分類結果與目標的實際分類越符合,說明結果越精確。
如下圖所示,人、大巴為檢測目標,既要檢測出所有人和大巴的比特置,也要檢測出包圍人和大巴的最小矩形框,同時還要識別出哪個矩形框內是人,哪個矩形框內是大巴。
yolov5網絡的損失函數構成
前文我們也講過yolov5網絡的基本思想:
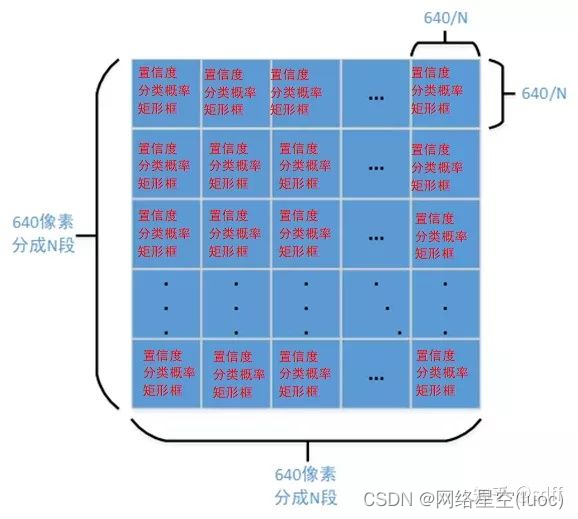
把640640的輸入圖像劃分成NN(通常為8080、4040、20*20)的網格,然後對網格的每個格子都預測三個指標:矩形框、置信度、分類概率。其中:
- 矩形框錶征目標的大小以及精確比特置。
- 置信度錶征所預測矩形框(簡稱預測框)的可信程度,取值範圍0~1,值越大說明該矩形框中越可能存在目標。
- 分類概率錶征目標的類別。
所以在實際檢測時:
- 首先判斷每個預測框的預測置信度是否超過設定閾值,若超過則認為該預測框內存在目標,從而得到目標的大致比特置。
- 接著根據非極大值抑制算法對存在目標的預測框進行篩選,剔除對應同一目標的重複矩形框(非極大值抑制算法我們後續再詳細講)。
- 最後根據篩選後預測框的分類概率,取最大概率對應的索引,即為目標的分類索引號,從而得到目標的類別。
損失函數的作用為度量神經網絡預測信息與期望信息(標簽)的距離,預測信息越接近期望信息,損失函數值越小。由上述每個格子的預測信息可知,訓練時主要包含三個方面的損失:矩形框損失(lossrect)、置信度損失(lossobj)、分類損失(lossclc)。因此yolov5網絡的損失函數定義為:
Loss=alossobj+ blossrect+ c*lossclc
也即總體損失為三個損失的加權和,通常置信度損失取最大權重,矩形框損失和分類損失的權重次之,比如:
a = 0.4
b = 0.3
c = 0.3
yolov5使用CIOU loss計算矩形框損失,置信度損失與分類損失都用BCE loss計算,下面我們會詳細介紹各種損失函數的計算原理。
mask掩碼矩陣
下面我們以8080網格為例來說明mask掩碼的定義、用途,以及如何獲取。4040網格與20*20網格也類似。
什麼是mask掩碼?
神經網絡對一張圖像分割成的80 * 80網格預測了3 * 80 * 80個預測框,那麼每個預測框都存在檢測目標嗎?顯然不是。所以在訓練時首先需要根據標簽作初步判斷,哪些預測框裏面很可能存在目標?mask掩碼為這樣的一個3 * 80 * 80的bool型矩陣:3 * 80 * 80個bool值與3 * 80 * 80個預測框一一對應,根據標簽信息和一定規則判斷每個預測框內是否存在目標,如果存在則將mask矩陣中對應比特置的值設置為true,否則設置為false。
mask掩碼有什麼用?
神經網絡對8080網格的每個格子都預測三個矩形框,因此輸出了380*80個預測框,每個預測框的預測信息包括矩形框信息、置信度、分類概率。實際上,並非所有預測框都需要計算所有類別的損失函數值,而是根據mask矩陣來决定:
- 僅mask矩陣中對應比特置為true的預測框,需要計算矩形框損失;
- 僅mask矩陣中對應比特置為true的預測框,需要計算分類損失;
- 所有預測框都需要計算置信度損失,但是mask為true的預測框與mask為false的預測框的置信度標簽值不一樣。
對於80*80網格,其各類損失函數的計算錶達式如下,其中a為mask為true時置信度損失的權重,通常取值0.5~1之間,使得網絡在訓練時更加專注於mask為true的情况。
4040網格和2020網格的損失函數計算與80*80網格類似,最後把所有網格的損失函數值作加權和,即得到一張訓練圖像的最後的損失函數值: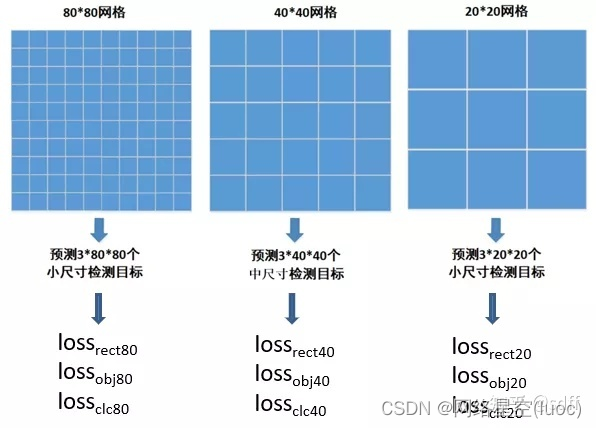
上式中α1、α2、α3為各網格損失函數值的權重系數。考慮到圖像中往往小型目標比較多,中型目標次之,大型目標最少,因此通常把8080網格的權重α1設置最大,4040網格的權重α2次之,20*20網格的權重α3最小,使得訓練時網絡更加專注於數量多的目標,比如α1、α2、α3依次取0.5、0.3、0.2。
怎麼得到mask掩碼?
下面我們詳細說明一下mask矩陣是怎麼得到的。
首先將38080的mask矩陣全部設置為false。對於COCO數據集json標簽文件中標注的一張圖像中的每個目標框,都按照以下步驟作判斷,並根據判斷結果將mask矩陣的對應比特置設置為true:
(1)從json標簽文件解析出單張圖像中所有目標框的中心坐標和寬高,以及圖像的寬高。假設解析得到一個目標框的中心坐標為(x, y),寬、高分別為w、h,圖像的寬高分別為wi、hi。需要將(x, y)轉換為640640圖像的坐標(x’, y’),並將w、h轉換為640640圖像中目標框的寬高wgt、hgt。
(2)然後由(x’, y’)計算該目標框在80*80網格中的網格坐標(xg,yg),注意xg,、yg都是浮點數。
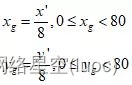
(3)接著對xg、yg向下取整,得到整型網格坐標(x0, y0)。同時為了加快訓練的收斂速度,yolov5對網格(x0, y0)的左右、上下再各取一個鄰近的網格:(x1, y0)和(x0, y1)。具體怎麼取呢?如下圖,紅點為點(xg,yg):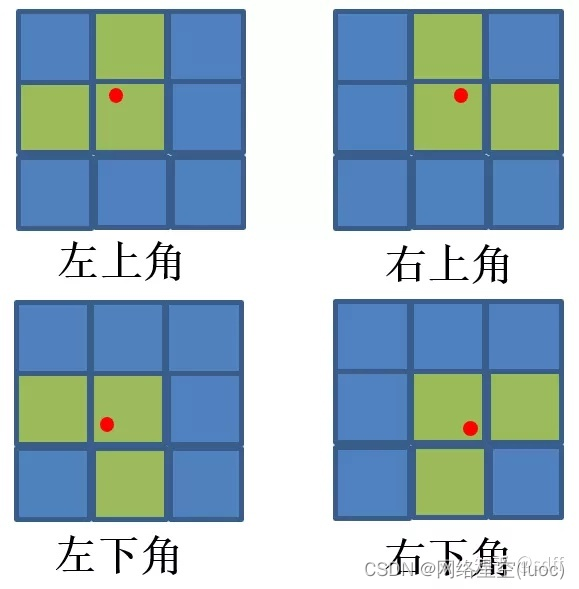
如果點(xg,yg)在格子的左上角,則取左邊、上方的兩個格子;如果點(xg,yg)在格子的右上角,則取右邊、上方的兩個格子;如果點(xg,yg)在格子的左下角,則取左邊、下方的兩個格子;如果點(xg,yg)在格子的右下角,則取右邊、上下方的兩個格子;
根據以上原則,x1和y1可按下式計算,其中round為四舍五入運算:
(4)經過第(3)步,得到三個互相鄰近的格子(x0, y0)、(x1, y0)、(x0, y1),我們認為該目標框比特於這三個格子的附近。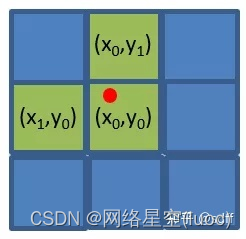
前文我們講使用Kmeans聚類算法獲取九個anchor框的時候,就講過:
- 寬、高最小的anchor0、anchor1、anchor2分配給80*80網格的每個格子;
- 寬、高次小的anchor3、anchor4、anchor5分配給40*40網格的每個格子;
- 寬、高最大的anchor6、anchor7、anchor8分配給20*20網格的每個格子。
因此80*80網格中(x0, y0)、(x1, y0)、(x0, y1)這三個格子都對應anchor0、anchor1、anchor2這三個anchor框。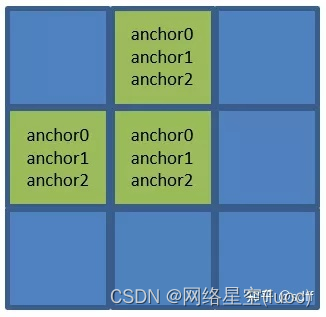
(5)假設anchor0、anchor1、anchor2這三個anchor框的寬高分別為(w0, h0)、(w1, h1)、(w2, h2),從json標簽文件解析得到該目標框的寬高為(wgt, hgt),然後分別計算(wgt, hgt)與(w0, h0)、(w1, h1)、(w2, h2)的比例,再根據比例剔除不滿足要求的anchor框:
將保留的anchor框標記為true,剔除的anchor框標記為false,那麼anchor0、anchor1、anchor2對應的標記為(m0, m1, m2):
(6)根據80*80網格中(x0, y0)、(x1, y0)、(x0, y1)這三個坐標比特置,我們分別對mask矩陣賦值: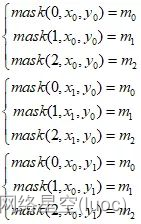
對一張圖像中的所有目標框,都作以上判斷並對mask矩陣賦值,即可得到該圖像的mask矩陣。
矩形框損失計算原理
這裏為什麼先講矩形框損失呢?因為後面講的置信度損失原理會使用到矩形框損失。
我們前文講過,yolov5對每個格子預測3個不同比特置和大小的矩形框,其中每個矩形框的信息為矩形中心的x坐標、y坐標,以及矩形寬、高。假設對某個格子預測的矩形框為(xp, yp, wp, hp),該格子對應的目標矩形框為(xl, yl, wl, hl),下面依次講解幾種最常見的矩形框損失函數的計算原理。
L1、L2、smooth L1損失函數
首先是L1損失函數: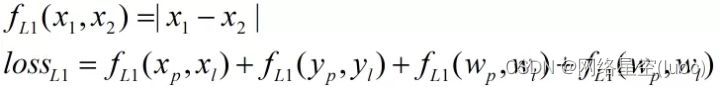
其次是L2損失函數: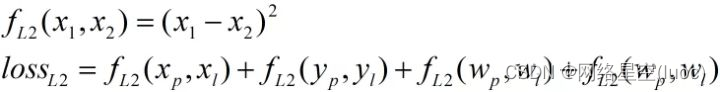
接著是smooth L1損失函數: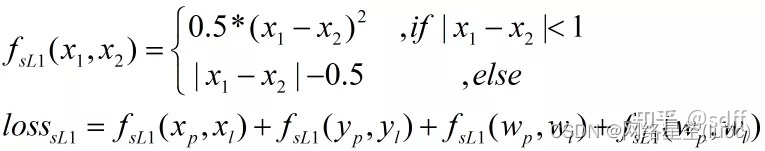
以上式子中,記d=x1-x2,分別畫出fL1(d)、fL2(d)、fsL1(d)的曲線如下圖:
由以上計算公式和曲線可以看出: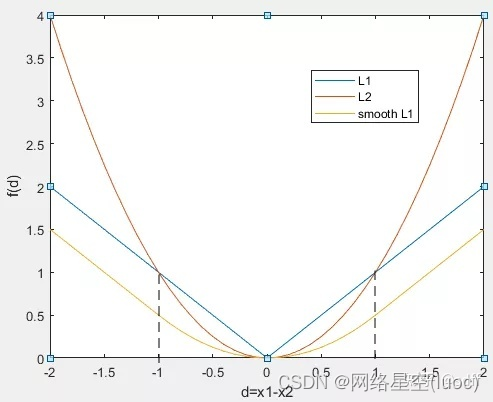
(1)fL1(d)函數的左右兩側曲線對於d的導數(斜率)是恒定不變的,但是在d=0處該函數不可導,然而隨著訓練的進行,d=x1-x2會逐漸接近0,這就導致在訓練後期損失函數的值在某個值附近波動,很難收斂。
(2)fL2(d)函數在d=0出處是可導的,不存在fL1(d)函數的問題,但是在前期訓練階段d很大的時候,fL2(d)函數對於d的導數也會很大,這很可能會導致梯度爆炸問題,從而訓練沒能朝著最優化的方向進行。
(3)fsL1(d)函數為分段函數,它將fL1(d)函數、fL2(d)函數的優點結合起來,同時完美規避了fL1(d)函數、fL2(d)函數的缺點。
IOU系列損失函數
上述計算矩形框的L1、L2、smooth L1損失時有一個共同點,都是分別計算矩形框中心點x坐標、中心點y坐標、寬、高的損失,最後再將四個損失值相加得到該矩形框的最終損失值。這種計算方法的前提假設是中心點x坐標、中心點y坐標、寬、高這四個值是相互獨立的,實際上它們具有相關性,所以該計算方法存在問題。
於是,IOU系列損失函數(IOU、GIOU、DIOU、CIOU)又被陸續提了出來。計算IOU系列損失函數需要使用矩形框左上角、右下角的坐標,假設預測矩形框的左上角、右下角坐標分別為(xp1, yp1)、(xp2, yp2),標簽矩形框的左上角、右下角坐標分別為(xl1, yl1)、(xl2, yl2),如下圖所示: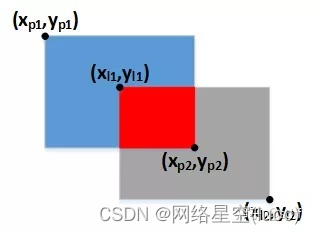
矩形框的中心坐標、寬、高可根據下式轉換到左上角、右下角坐標: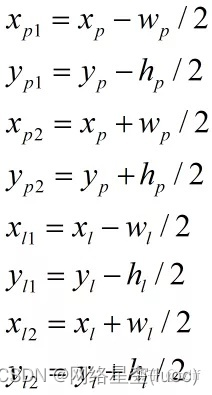
下面分別介紹IOU、GIOU、DIOU、CIOU損失函數的計算原理。
(1)IOU loss
IOU為兩個方框相交區域面積與相並部分面積的比值,所以也稱為交並比。首先求相交部分面積: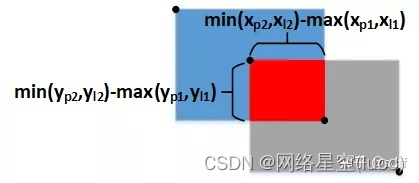
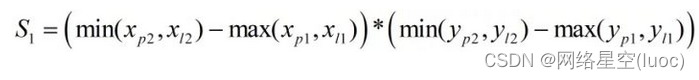
然後求相並部面積: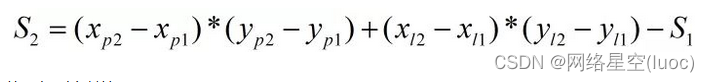
從而得到交並比IOU: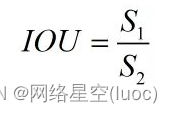
IOU的取值範圍為0~1,當兩個矩形框完全沒有交集時,IOU為0,當它們完全重合時IOU為1,也即重合度越小IOU越接近0,重合度越大IOU越接近1。
最後得到IOU loss的計算公式如下,兩個矩形框重合度越高IOU loss越接近0: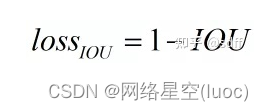
(2)GIOU loss
當兩個矩形框完全沒有重疊區域時,無論它們距離多遠,它們的IOU都為0。這種情况下梯度也為0,導致無法優化。為了解决這個問題,GIOU又被提了出來。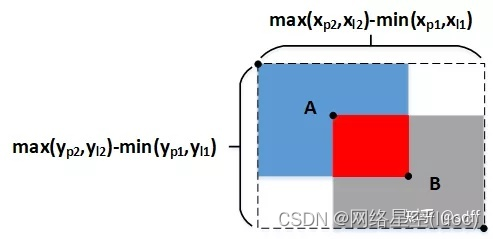
如上圖所示,GIOU在IOU的基礎上,把包圍矩形框A和矩形框B的最小矩形框(圖中的虛線框)的面積也加入到計算中。
GIOU可按下式計算,其中S1為A、B相交部分的面積(紅色區域)。其中S3為包圍A、B的最小矩形框的面積,S2為A、B相並區域的面積(藍色+紅色+灰色區域)。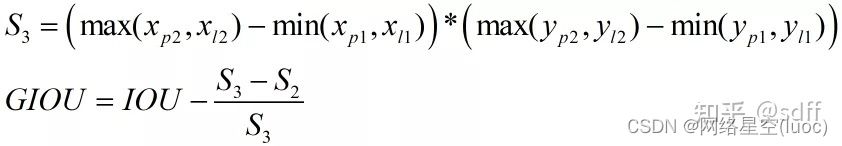
由上式可知GIOU相比IOU,新增了(S3-S2)/S3這一項。新增項錶示什麼意義呢?由上述可知S3-S2為虛線框中白色區域的面積,也即虛線框中不屬於A也不屬於B的空白區域,那麼(S3-S2)/S3就是空白區域面積占虛線框面積的比例,這個比例越大說明A、B距離越遠、重疊度越小,反之則A、B距離越近、重疊度越大。GIOU的取值範圍是-1~1,當A、B完全沒有重疊區域時IOU為0,那麼GIOU取負值,極端情况,當A、B無重疊區域且距離無限遠時,此時(S3-S2)/S3等於1,那麼GIOU取-1;另一個極端情况,當A、B完全重疊時(S3-S2)/S3等於0,IOU為1,那麼GIOU取1。因此,GIOU解决了當A、B完全沒有重疊區域時IOU恒為0的問題。
最後得到GIOU loss的計算公式: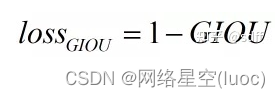
(3)DIOU loss
GIOU雖然把IOU的問題解决了,但它還是基於面積的度量,並沒有把兩個矩形框A、B的距離考慮進去。為了使訓練更穩定、收斂更快,DIOU隨之被提了出來,DIOU把矩形框A、B的中心點距離ρ、外接矩形框(虛線框)的對角線長度c都直接考慮進去,如下圖所示: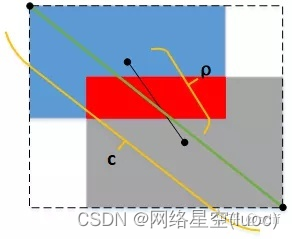
DIOU可按下式計算: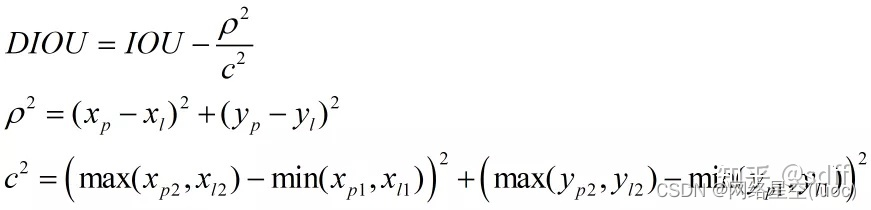
由上式可知DIOU的取值範圍也為-1~1,當兩個框A、B完全重合時DIOU取1,當A、B距離無限遠時,DIOU取-1。
從而得到DIOU loss的計算公式: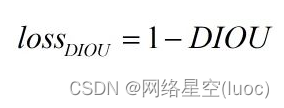
(4)CIOU loss
yolov5使用CIOU loss來衡量矩形框的損失。
DIOU把兩個矩形框A、B的重疊面積、中心點距離都考慮了進去,但並未考慮A、B的寬高比。為了進一步提昇訓練的穩定性和收斂速度,在DIOU的基礎上CIOU又被提了出來,它將重疊面積、中心點距離、寬高比同時加入了計算。CIOU可按下式計算:
上式中,ρ為框A和框B的中心點距離,c為框A和框B的最小包圍矩形的對角線長度,v為框A、框B的寬高比相似度,α為v的影響因子。
反正切arctan函數的取值範圍是0Π/2,那麼v的取值範圍為01,當框A、框B的的寬高比相等時v取0,當框A、框B的的寬高比相差無限大時v取1。
當框A、框B的距離無限遠,且寬高比差別無限大時DIOU取-1,v取1,alpha取0.5,此時CIOU取-1-0.5=-1.5;當框A、框B完全重疊時,DIOU取1,v取0,α取0,則CIOU取1。因此CIOU取值範圍是-1.5~1。
IOU越大也即A、B的重疊區域越大,則α越大,從而v的影響越大;反之IOU越小也即A、B的重疊區域越小,則α越小,從而v的影響越小。因此在優化過程中:
- 如果A、B的重疊區域較小,則寬高比v在損失函數中影響較小,此時著重優化A、B的距離;
- 如果A、B的重疊區域較大,則寬高比v在損失函數中影響也較大,此時著重優化A、B的寬高比。
用一句話來說,就是越缺什麼,就越著重彌補什麼,從而達到加速優化訓練的收斂速度和穩定性的目的。
由以上可得CIOU loss的計算公式為: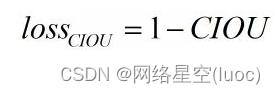
置信度損失計算原理
下面以8080網格為例,詳細講置信度損失的計算原理,4040和2020網格的置信度損失計算原理與8080網格一樣,可依此類推。
神經網絡預測的置信度
對於一張圖像分割成的8080的網格,神經網絡對其中每個格子都預測三個比特於該格子附近的矩形框(簡稱預測框),每個預測框的預測信息包括中心坐標、寬、高、置信度、分類概率,因此神經網絡總共輸出38080個0~1的預測置信度,與380*80個預測框一 一對應。每個預測框的置信度錶征這個預測框的靠譜程度,值越大錶示該預測框越可信靠譜,也即越接近目標的真實最小包圍框。比如下圖中,紅點A、B、C、D錶示檢測目標,那麼每個紅點所在格子的三個預測置信度應該比較大甚至接近1,而其它格子的預測置信度應該較小甚至接近0。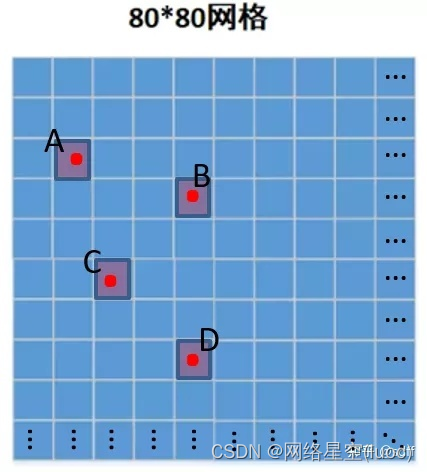
置信度的標簽
標簽的維度應該與神經網絡的輸出維度保持一致,因此置信度的標簽也是維度為38080的矩陣。這裏就用到了上文我們講的mask掩碼矩陣:以維度同樣為38080的mask矩陣為標記,對置信度標簽矩陣進行賦值。yolo之前版本直接對mask矩陣為true的地方賦值1,mask矩陣為false的地方賦值0,認為只要mask為true就錶示對應預測框完美包圍了目標。這樣做就太絕對了,因為mask為true只是錶示該預測框在目標附近而已,並不一定完美包圍了目標。所以yolov5改變了做法:對mask為true的比特置不直接賦1,而是計算對應預測框與目標框的CIOU,使用CIOU作為該預測框的置信度標簽,當然對mask為false的比特置還是直接賦0。這樣一來,標簽值的大小與預測框、目標框的重合度有關,兩框重合度越高則標簽值越大。當然,上文我們講CIOU的取值範圍是-1.51,而置信度標簽的取值範圍是01,所以需要對CIOU做一個截斷處理:當CIOU小於0時直接取0值作為標簽。
BCE loss損失函數
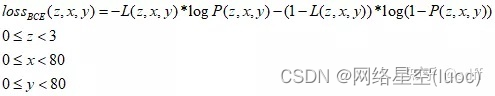
假設置信度標簽為矩陣L,預測置信度為矩陣P,那麼矩陣中每個數值的BCE loss的計算公式如下:
注意BCE loss要求輸入數據的取值範圍必須在0~1之間。
從得到80*80網格的置信度損失值:
此外,我們稱對應mask比特true的預測框為正樣本,對應mask為false的預測框為負樣本,負樣本肯定是遠遠多於正樣本的,為了使訓練更專注於正樣本,後來Focal loss又被提了出來,我們在此暫時不細說,下篇文章再詳細介紹吧。
分類損失計算原理
下面也以8080網格為例,詳細講分類損失的計算原理,4040和2020網格的分類損失計算原理與8080網格一樣,可依此類推。神經網絡對8080網格的每個格子都預測三個預測框,每個預測框的預測信息都包含了N個分類概率。其中N為總類別數,比如COCO數據集有80個類別,那麼N取80。所以對於COCO數據集,每個預測框有80個0~1的分類概率,那麼神經網絡總共預測3808080個分類概率,組成預測概率矩陣。
8080網格的標簽概率矩陣與預測概率矩陣的維度一樣,也是3808080。每個預測框的標簽,由解析json標簽文件得到,是一個079的數值,需要將079的數值轉換成80個數的獨熱碼:
然而,為了减少過擬合,且增加訓練的穩定性,通常對獨熱碼標簽做一個平滑操作。如下式,label為獨熱碼中的所有數值,α為平滑系數,取值範圍0~1,通常取0.1。
同樣假設置標簽概率為矩陣Lsmooth,預測概率為矩陣P,那麼矩陣中每個數值的BCE loss的計算公式如下:
於是得到80*80網格的分類損失函數值的計算公式: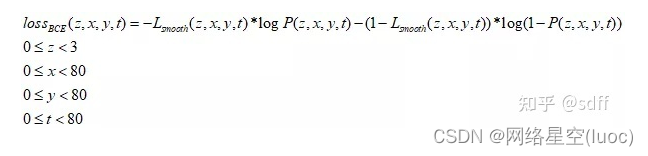
結語
好了,本文我們就講到這裏。說點題外話,隔了兩三個月沒有更新文章了,感覺很對不起粉絲們。因為本人在年底不僅換了工作,工作城市也換了,免不了一番奔波與適應,所以更新就被耽擱了。不過呢,我還是會在業餘抽時間來學習、更新,不辜負粉絲們對我的期望~祝朋友們新年快樂,事事順心(遲來的祝福^^)!
边栏推荐
- pytorch训练进程被中断了
- 【上采样方式-OpenCV插值】
- comsol--三维图形随便画----回转
- ibatis的动态sql
- Technology sharing | common interface protocol analysis
- 紫光展锐全球首个5G R17 IoT NTN卫星物联网上星实测完成
- 技术管理进阶——什么是管理者之体力、脑力、心力
- 2048游戏逻辑
- Go language learning notes - first acquaintance with go language
- What about SSL certificate errors? Solutions to common SSL certificate errors in browsers
猜你喜欢
idea设置打开文件窗口个数
【使用TensorRT通过ONNX部署Pytorch项目】
Go language learning notes - analyze the first program
12. (map data) cesium city building map
![[office] eight usages of if function in Excel](/img/ce/ea481ab947b25937a28ab5540ce323.png)
[office] eight usages of if function in Excel

How to make your products as expensive as possible
【Office】Excel中IF函数的8种用法

Cdga | six principles that data governance has to adhere to
liunx禁ping 详解traceroute的不同用法
【Win11 多用户同时登录远程桌面配置方法】
随机推荐
yolov5目标检测神经网络——损失函数计算原理
How can China Africa diamond accessory stones be inlaid to be safe and beautiful?
爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
liunx禁ping 详解traceroute的不同用法
居家办公那些事|社区征文
Home office things community essay
How did the situation that NFT trading market mainly uses eth standard for trading come into being?
pytorch训练进程被中断了
Evolution of multi-objective sorting model for classified tab commodity flow
An error is reported in the process of using gbase 8C database: 80000305, host IPS long to different cluster. How to solve it?
Prevent browser backward operation
1个插件搞定网页中的广告
How can edge computing be combined with the Internet of things?
-26374 and -26377 errors during coneroller execution
pytorch-多层感知机MLP
XML解析
【爬虫】wasm遇到的bug
Solve readobjectstart: expect {or N, but found n, error found in 1 byte of
[LeetCode] Wildcard Matching 外卡匹配
[crawler] Charles unknown error