当前位置:网站首页>【AI系统前沿动态第40期】Hinton:我的深度学习生涯与研究心法;Google辟谣放弃TensorFlow;封神框架正式开源
【AI系统前沿动态第40期】Hinton:我的深度学习生涯与研究心法;Google辟谣放弃TensorFlow;封神框架正式开源
2022-07-04 12:34:00 【智源社区】
1、Geoffrey Hinton:我的五十年深度学习生涯与研究心法
https://mp.weixin.qq.com/s/kRdlK3VEqeKSr9up0ay5dg
2、Google 辟谣放弃 TensorFlow
https://mp.weixin.qq.com/s/JAGHRVUb1Mla_wIWoyJPeA
3、封神框架正式开源,轻松预训练和微调“封神榜”各大模型
https://mp.weixin.qq.com/s/NtaEVMdTxzTJfVr-uQ419Q
4、训练GPT-3,为什么原有的深度学习框架吃不消?
https://mp.weixin.qq.com/s/qZ6qYfAX442vQBiJXwt6uA
5、对抗软件系统复杂性①:如无必要,勿增实体
https://mp.weixin.qq.com/s/TmbTQYakDcDEh7nbnfumPQ
6、如何开发机器学习系统:高性能GPU矩阵乘法
https://zhuanlan.zhihu.com/p/531498210
7、针对深度学习的GPU共享
https://zhuanlan.zhihu.com/p/285994980
8、深入浅出GPU优化系列:reduce优化
https://zhuanlan.zhihu.com/p/426978026
9、从MLPerf谈起:如何引领AI加速器的下一波浪潮
https://mp.weixin.qq.com/s/n116POs9H9v5wqJA7_km6A
10、写给小白的开源编译器
https://zhuanlan.zhihu.com/p/515999515
11、OneFlow源码解析:算子签名的自动推断
https://mp.weixin.qq.com/s/_0w3qhIk2e8Dm9_csCfEcQ
其他人都在看
- OneFlow v0.7.0发布
- 图解OneFlow的学习率调整策略
- 手把手推导分布式矩阵乘的最优并行策略
- OneFlow源码解析:算子签名的自动推断
- 训练千亿参数大模型,离不开四种并行策略
- 解读Pathways(二):向前一步是OneFlow
- Hinton:我的五十年深度学习生涯与研究心法
欢迎体验OneFlow v0.7.0:https://github.com/Oneflow-Inc/oneflow/

边栏推荐
- Flet教程之 02 ElevatedButton高级功能(教程含源码)(教程含源码)
- Communication tutorial | overview of the first, second and third generation can bus
- 阿里云有奖体验:用PolarDB-X搭建一个高可用系统
- 强化学习-学习笔记1 | 基础概念
- 【云原生 | Kubernetes篇】深入了解Ingress(十二)
- Concepts and theories related to distributed transactions
- Will the concept of "being integrated" become a new inflection point of the information and innovation industry?
- Complementary knowledge of auto encoder
- 轻松玩转三子棋
- Talk about "in C language"
猜你喜欢
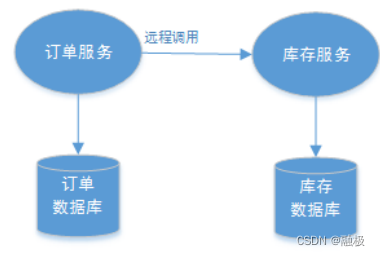
Concepts and theories related to distributed transactions
Detailed explanation of mt4api documentary and foreign exchange API documentary interfaces
![[leetcode] 96 and 95 (how to calculate all legal BST)](/img/d5/788c88064bce6a7c4499017908b3f2.jpg)
[leetcode] 96 and 95 (how to calculate all legal BST)

【云原生 | Kubernetes篇】深入了解Ingress(十二)
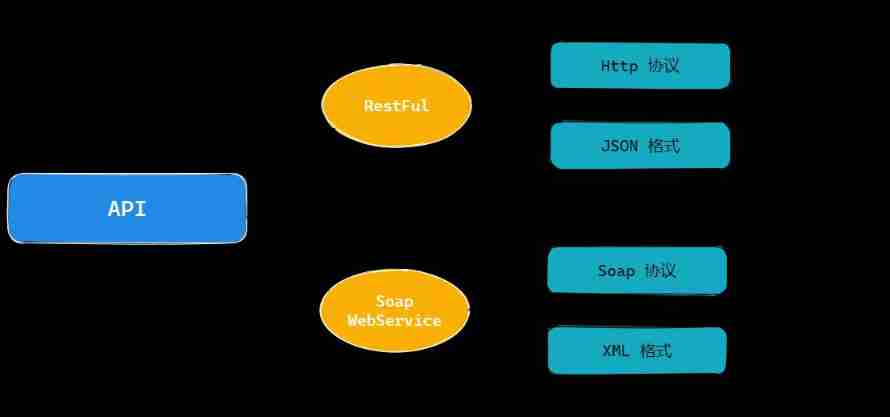
Practice of retro SOAP Protocol

阿里云有奖体验:用PolarDB-X搭建一个高可用系统

C#/VB.NET 给PDF文档添加文本/图像水印
强化学习-学习笔记1 | 基础概念
Fundamentals of container technology

Error: Failed to download metadata for repo ‘AppStream‘: Cannot download repomd. XML solution
随机推荐
How to realize the function of Sub Ledger of applet?
Unity performance optimization reading notes - explore performance issues -profiler (2.1)
Iterm tab switching order
Transformer principle and code elaboration (pytorch)
使用Scrcpy投屏
Cadence physical library lef file syntax learning [continuous update]
Argminer: a pytorch package for processing, enhancing, training, and reasoning argument mining datasets
ArgMiner:一个用于对论点挖掘数据集进行处理、增强、训练和推理的 PyTorch 的包
C語言函數
16. Memory usage and segmentation
Transformer principle and code elaboration (tensorflow)
强化学习-学习笔记1 | 基础概念
DC-5靶机
面试官:Redis 过期删除策略和内存淘汰策略有什么区别?
Complementary knowledge of auto encoder
C language: the sorting problem of circle number reporting
七、软件包管理
C#/VB.NET 给PDF文档添加文本/图像水印
众昂矿业:为保障萤石足量供应,开源节流势在必行
7、 Software package management