当前位置:网站首页>Overview of spark RDD
Overview of spark RDD
2022-07-06 02:04:00 【Diligent ls】
One 、 What is? RDD
RDD(Resilient Distributed Dataset) It's called elastic distributed data sets , yes Spark The most basic data abstraction in .
The code is an abstract class , It represents a flexible 、 immutable 、 Divisible 、 A set of elements that can be calculated in parallel .
1. elastic :
Storage flexibility : Automatic switching between memory and disk
The resilience of fault tolerance : Data loss can be recovered automatically
Elasticity of calculation : Calculation error retrial mechanism
The elasticity of slices : It can be re sliced as needed
2. Distributed
Data is stored on different nodes of the big data cluster
3. Datasets do not store data
RDD Encapsulates the computational logic , Do not save datasets
4. Data abstraction
RDD It's an abstract class , You need a subclass to implement that
5. immutable
RDD Encapsulates the computational logic , It's unchangeable , Want to change can only produce new RDD, In the new RDD Encapsulate computing logic
6. Divisible , Parallel operation
notes : all RDD Operator related operations are Executor End execution ,RDD Operations other than operators are Driver End execution .
stay Spark in , Only meet action Equal action operator , Will execute RDD Arithmetic , That is, delay calculation
Two 、RDD Five characteristics of

1)A list of partitions
RDD By many partition constitute , stay spark in , Calculation formula , How many? partition It corresponds to how many task To execute
2)A function for computing each split
Yes RDD Do calculations , It's equivalent to RDD Each split or partition Do calculations
3)A list of dependencies on other RDDs
RDD There's a dependency , It can be traced back to
4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
If RDD The data stored in it is key-value form , You can pass a custom Partitioner Re zoning , For example, you can press key Of hash Value partition
5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
The best position to calculate , That is, the locality of data
Calculate each split when , stay split Run locally on the machine task It's the best , Avoid data movement ;split There are multiple copies , therefore preferred location More than one
Where is the data , Priority should be given to scheduling jobs to the machine where the data resides , Reduce data IO And network transmission , In this way, we can better reduce the running time of jobs ( Barrel principle : The running time of the job depends on the slowest task Time required ), Improve performance
The feature introduction is reproduced from (https://www.jianshu.com/p/650d6e33914b)
边栏推荐
- Cookie concept, basic use, principle, details and Chinese transmission
- Maya hollowed out modeling
- Force buckle 1020 Number of enclaves
- How to upgrade kubernetes in place
- Concept of storage engine
- 【Flask】官方教程(Tutorial)-part3:blog蓝图、项目可安装化
- 【clickhouse】ClickHouse Practice in EOI
- leetcode-两数之和
- Ali test open-ended questions
- Redis key operation
猜你喜欢

Jisuanke - t2063_ Missile interception
![[depth first search] Ji Suan Ke: Betsy's trip](/img/b5/f24eb28cf5fa4dcfe9af14e7187a88.jpg)
[depth first search] Ji Suan Ke: Betsy's trip
Unity learning notes -- 2D one-way platform production method
Win10 add file extension
Alibaba canal usage details (pit draining version)_ MySQL and ES data synchronization
Online reservation system of sports venues based on PHP

Basic operations of databases and tables ----- default constraints
Leetcode3, implémenter strstr ()
Social networking website for college students based on computer graduation design PHP
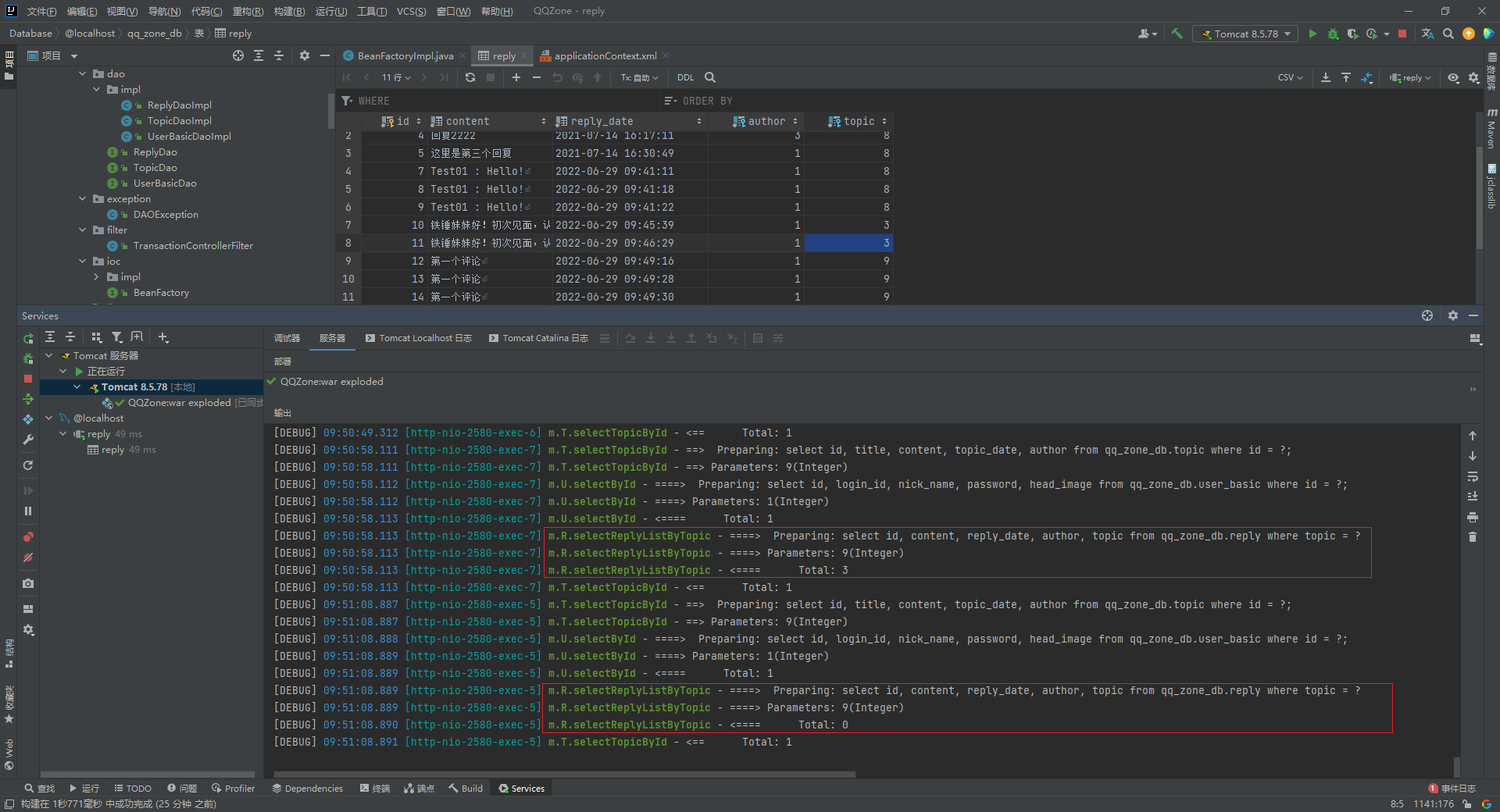
同一个 SqlSession 中执行两条一模一样的SQL语句查询得到的 total 数量不一样
随机推荐
A Cooperative Approach to Particle Swarm Optimization
Leetcode sum of two numbers
Ali test open-ended questions
Card 4G industrial router charging pile intelligent cabinet private network video monitoring 4G to Ethernet to WiFi wired network speed test software and hardware customization
[the most complete in the whole network] |mysql explain full interpretation
Redis daemon cannot stop the solution
How does the crystal oscillator vibrate?
通过PHP 获取身份证相关信息 获取生肖,获取星座,获取年龄,获取性别
GBase 8c数据库升级报错
[network attack and defense training exercises]
02.Go语言开发环境配置
How to set an alias inside a bash shell script so that is it visible from the outside?
[understanding of opportunity-39]: Guiguzi - Chapter 5 flying clamp - warning 2: there are six types of praise. Be careful to enjoy praise as fish enjoy bait.
Dynamics 365 开发协作最佳实践思考
Alibaba canal usage details (pit draining version)_ MySQL and ES data synchronization
Redis-列表
Campus second-hand transaction based on wechat applet
Win10 add file extension
插卡4G工业路由器充电桩智能柜专网视频监控4G转以太网转WiFi有线网速测试 软硬件定制
阿里测开面试题