当前位置:网站首页>阿里云视频云技术专家 LVS 演讲全文:《“云端一体”的智能媒体生产制作演进之路》
阿里云视频云技术专家 LVS 演讲全文:《“云端一体”的智能媒体生产制作演进之路》
2020-11-08 12:56:00 【osc_97wmavr6】
2020年11月1日,阿里云视频云亮相 LiveVideoStackCon 音视频技术大会,阿里云智能视频云高级技术专家邹娟,就智能媒体生产展开主题演讲——《“云端一体”的智能媒体生产制作演进之路》,以下为完整的演讲内容:

大家好,我是来自阿里云视频云的邹娟,我在视频云是负责媒体生产平台的架构设计和开发工作。我今天分享的主题是“云端一体的智能媒体生产制作的技术演进之路”。我的整个分享将会从三个部分来展开。
Part 1 媒体生产制作技术的演进
第一部分是媒体生产制作技术的演进,如果我们把制作放大到整个视频全链路的范围来看的话。视频全链路是把它抽象成了5个环节,从采集开始,历经制作管理,最后是分发和消费。
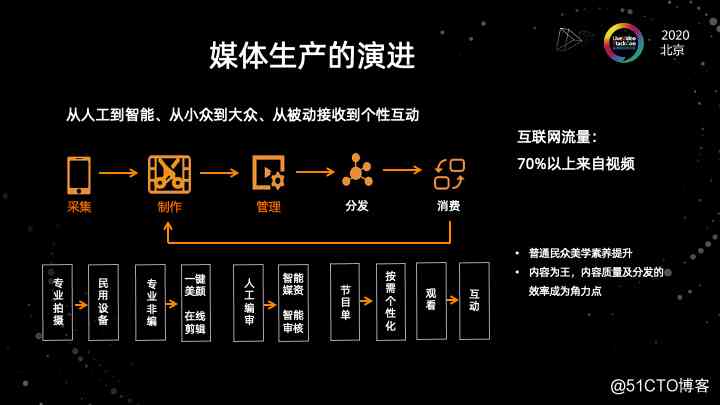
以前到现在,过去这么多年,视频技术在整个行业发展了好几十年。在整个环节的流转当中,视频全链路的每一个环节以前跟现在都发生了很大的变化。
比如,在采集环节,我们从最开始的采集过程,必须要通过专业的像索尼松下这种摄像机来去拍摄。到现在我们可以用手机就能够拍摄视频。在制作这个环节,我们从最开始必须要用专业的非线性编辑软件和桌面的这样的工具,或者是像这种演播车硬件导播台来去做这种后期或者实时的制作,现在,我们可以在手机上一键美颜,可以在外部上做在线的剪辑。
从管理来看,最开始传统模式是我们需要用人工的方式去进行原数据的编幕,然后要历经很多个审核的环节,到现在我们可以用智能思维来构建动态的原数据体系,去做知识图谱的这个素材之间的挖掘。并可以用智能审核去就是减轻审核的压力,提升整个流程的性能。
整个发展的路径是从最开始都是靠人工,到现在我们可以用智能化的方式去融入整个过程当中来提升整个的效率。
以前制作视频的都是专业的机构来制作。像电视台或者电影电视制作公司来制作。到现在每一个老百姓都可以去来制作视频。整个的趋势就是从人工到智能,从小众到大众。
最后分发和消费的环节其实是一个。从我们以前很传统的一个被动的接收,像最早看电视的被动接收模式,到现在我们可以去互动,可以去按需求个性化的去选择我们所看到的内容。整个媒体生产的这个演进过程,实际上就是从一个很专业的门槛到现在一个普惠的变化。
现在关于制作本身的话,其实我觉得是有两方面的因素。第一个是手机的厂商,把视频拍摄的这个技术能够更大更加深入的在手机上应用起来。所以在手机上我们可以拍摄很高清的视频。
另一个是抖音快手这种短视频的平台,它提升了普通老百姓对于审美的追求,以及对于视频质量的追求和视频产量的要求。所以在整个过程当中,制作这个环节越来越重要了。

我们将视野放大到制作这个本身的过程。看一下媒体生产制作模式及它的变迁的过程。最早的时候,其实整个视频制作是线性编辑的过程,也就是编辑需要一边放一边录。
甚至最早的电影制作的阶段是真的要去剪那个胶片的,要把胶片做一个正片,然后用剪子剪开,然后去用透明胶带粘起来。到了八九十年代的时候,出现了一些专业化制作,视频编辑可以用一些软件去做。到中间阶段我们可以把制作分成两个模式了。第一个是现场制作的,然后还有一个是后期制作。
在上一阶段的现场制作的过程中,我们一般会用这种如演播室或者是硬件导播台,或者是转播车来实时制作。到后期使用非线性编辑软件来做。整个的生产制度模式是音频、视频和图文,它们是分开来做的。有专门的字幕制作设备和机器来做。通过进一步的发展,现在这个阶段,我们增加了一些云端制作和快速制作的一些方式。比如说我们的现场制作,可以在直播的过程中实时的去叠加很多的东西,做很多的加工。然后在云端把硬件导播台换成云导播台,在云端去实时做个性化的导播的切换。
在后期制作这个环节,我们不再只局限于用非线性编辑软件来做。我们可以在云端使用云剪辑,然后在手机端用短视频app制作工具进行视频制作。生产制作模式发生了很大的变化。生产制作模式是在原有的基础上叠加了一些新的场景和模式。
整个云计算和AI的发展,实际上是补充了很多新的一些生产制度模式,能够让内容的生产方式会更加的丰富。在整个过程当中,AI在整个现在整个制作的模式的变迁过程中,它起到的是一个辅助的作用。我们希望未来AI能够达到智能创作一些有故事的视频的阶段。
这是我们视频云在整个智能化制作中演进的路线。
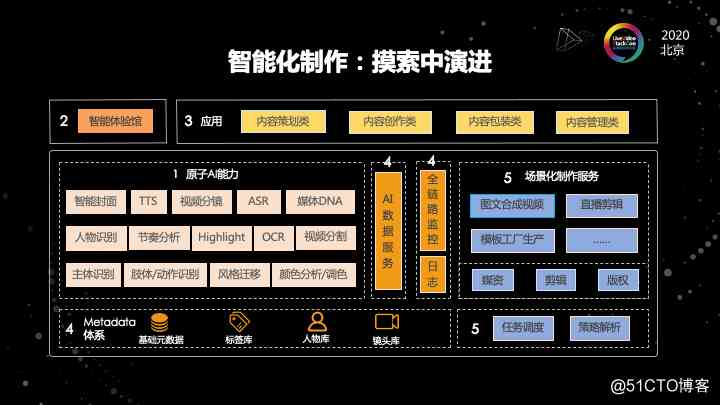
我们要知道智能化制作的需求,第一步要做的是什么?
首先,我们现在有很多的AI算法能力,这些能力可以跟制作流程有联系的。比如说视觉相关的,像分镜,人物的识别,视频的分割,包括一些视频画面的主体的识别。还有声音的语音识别,语音合成,颜色相关的,颜色的分析,还有调色等。还有一些图片内容相关的。比方说智能的封面可能是静态的,也可能是动态的。这些是我们能够达到的。在制作这个领域可能会用到的一些原子的AI能力。我们第一步是把这些原子的AI能力,通过API化让大家可以看到。
第二个阶段是我们做了一个智能的体验馆。因为AI的原子能力可能隐藏在后台,我们只放出API的话,可能没有办法给人很直观的感觉。
所以第二阶段我们做了一个体验馆,然后能够让很多客户去尝试这样的能力,看到这样的效果。经过了第二阶段之后,我们发现一些客户他会对其中的一些点会比较感兴趣。因为AI的能力是很多的,但是针对不同的场景,可能客户关注的点也是不一样的。
我们抽象了几种场景、几种应用,从内容的策划到创作的包装管理。客户可以根据在体验馆上提交一些自己的反馈。经过这个反馈我们就可以了解到客户的需求。
于是我们把它变成一个真正云服务的过程。也就是第四个阶段。因为把一个原子的 AI 能力,将它 API 化使我们能够真正的提供一个云服务。但中间的 gap 是巨大的。所以我们做了一些体系的构建。我们做了基础源数据,提供了一些标签库、人物库、镜头库,并且从工程上去做了很多数据的服务体系,包括日志和监控的体系。把这一套体系都做完,才能算是我们做了一个可提供给客户的服务。
到了第五个阶段的话,我们发现这些服务能够很稳定的提供出去是远远不够的。客户可能需要的不是人脸识别的一个结果,而是需要解决实际场景中的问题。这里可能我们就需要就进入到下一阶段。我必须要把这些AI的服务跟场景去结合起来,能够为生产制作本身发挥作用。这里我们抽象了一些场景,图文合成视频,模板工厂等,根据模板化来生产视频,像直播剪辑、智能字幕、智能配音等。这些场景才是客户最终需要的。所以在第五阶段,我们把整个制作和AI做了一个结合,提供了一波场景化制作服务。
在整个过程中,我们会依赖像媒资系统,像剪辑系统,像版权系统,做一些任务的调度和策略的解析。然后把不同场景的服务去使用不同的策略去实现。所以,可以看到我们整个视频云在智能化的制作过程中,它不是一个凭空想象的过程。AI 的能力,是需要跟场景结合起来,才能真正的为客户提供服务的。
Part 2 云端一体的架构设计

接下来是我们智能制作云端一体化架构设计。
在讲这个架构设计之前,我想先给大家分享一下我们之前所分析的一些媒体市场制作的核心组成和核心痛点。在媒体生产制作的过程当中,我们可以把整个的制作过程抽象成四个阶段。
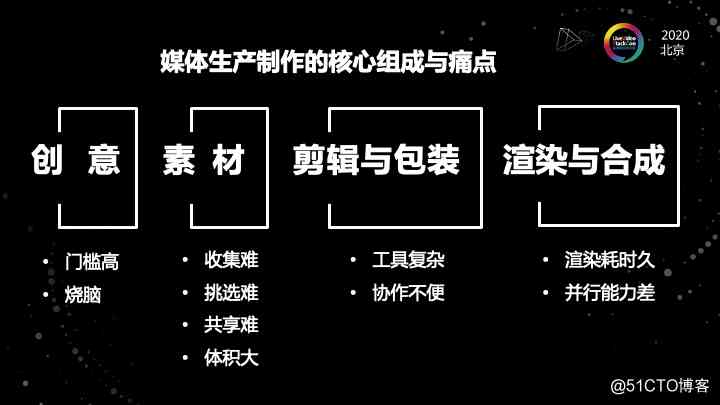
第一个阶段是创意的过程,这个过程实际上是目前整个过程中我认为耗时最久的一个过程。
首先创意这个门槛就比较高,创意的过程是非常烧脑的。所以创意的过程中,我需要去搜集,去编排很多的素材。那素材的收集和挑选就成了一个难题。如果是在做一个需要多人协同来完成的一项工作的时候,那会发现素材共享也很困难。并且原始的素材,这些素材需要在多人之间流转,但可能它的体积会很大。文件大小的问题也是一个很突出的问题。
到了第三个阶段是我素材已经大概找好了,但我是需要能够把它通过剪辑或者包装的手段去实现我想要的一个效果。这个时候我发现工具用起来非常复杂。
举个例子:比如说我周五的时候做了一个大概4分钟的视频,在创意过程大概花了我4个小时,然后收集素材又花了两个小时。然后最后我在整个剪辑和包装的过程,又花了我好几个小时。所以我从周五中午就开始,最终那个视频是在周六的凌晨两点才出来的。
所以工具的复杂,素材巨大传输的不便,还有包括协作的不便。这样的场景可能适用于非个人制作,需要多人去协同完成。
所以我们设计了一套这样的架构。
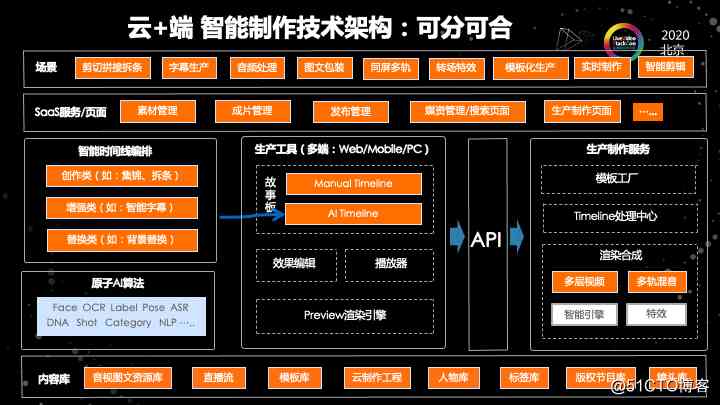
我们这套架构的一个核心的点是,它是包括了云和端的部分,并且整个架构它不是通常大家理解的 SaaS 工具这样的一个架构,它是云+端,可以分开也可以合起来的一个非常开放的架构。
首先,中间这个部分是生产工具的部分,这个部分也是大家最容易想到的,因为我们在进入云剪辑之前,我们都是在用一些客户端的工具来做。
在整个过程中,我们的工具会抽象成三个组件。其中最核心的是这个故事版的组件,也就是时间线。其中还有两个子组件,一个是播放器,因为要去在播放器上去预览剪辑过程的效果,并且还有一些效果编辑的一些组件。这些组件会完成针对视频音频包括贴图,包括字幕的一些各种效果编辑。
最核心的是我的预览的渲染引擎。这个其实组成了生产工具的一个端侧的组件。在这个端的话,实际上我们最开始只做了外部端和移动端。而且最开始的时候,外部端和移动端它的时间线是没有统一的。在这个过程当中,最终是这样一个架构。开始可能这个架构比较简单,我们只考虑了外部端,没有考虑某外部端跟外部端的协同。现在我们是一个多端统一的架构。
在整个在右侧,是我们的一个生产制度的服务端,相当于我们把整个云服务的体系划分成了三个组件。其中最核心的是时间线的处理中心。也就是当我拿到了一个时间轴,这个时间轴上有很多的轨道素材及效果。我需要对这个时间线进行处理。因为有可能我拿到了一个时间线,是一个我的客户直接通过 API 请求提交过来的时间线,那么这个时间线的参数可能会有很多的问题。
如果我简单粗暴的把它拒绝掉的话,那么整个体验是比较差的。所以我们在服务端做了很多的容错校验和补全,以及预测的机制,能够让这个时间线呈现给客户所预期需要的状态。最终通过模板工厂降低整个门槛。渲染合成是最终的硬实力。我们支持多层的视频,然后多轨的混音,并且支持智能的引擎去调度到不同的底层,有特效引擎去用来做视频的渲染。
可以看到 API 的左侧、API 的右侧的部分(上图中),分别是端和云的部分。整个的设计是这两部分可以独立来使用的。比方说我可以只使用外部 sdk 的部分,我也可以只使用云端的部分,或者直接不使用外部 sdk,直接通过请求来去调用。
当然也可以在一个 SaaS 化的工具上,把这两个部分去融合。这个是我们一个云端可分可合的架构设计,它的设计初衷是,不是一个纯 PaaS 或者是一个纯 SaaS ,或者是一个只是端和云的结构,它是一体化并且可以拆开的一个结构。在这个结构的上面,是我们基于结构包装出来的一些服务和页面。这部分是可以由阿里云来做,也可以由我们的客户来做。最终上面的是我们的一些场景。我们可以把这些技术抽象成一些场景,能够在这些场景上用到我们这些技术。
最左边的这一块实际上是我们后来加上的,在开始我们做第一版的时候,是没有 AI 部分的。把 AI 的这个部分加上来,是为了能够智能的对时间线做一个编排。对时间线的编排,我们把它抽象成了三个场景。
第一个场景是创作类的场景。第二个是增强类的场景。第三个是替换类的场景。在这三个场景当中,我们可以对素材去进行分析,拿到一个初步的时间线,并且将这个时间线跟人工的时间线再去做一个结合。生产一个最终的时间线。
所以可以看到在整个智能制作中最核心的关键点是关于时间线的设计。因为时间线它描述了多个轨道,然后多个素材按照一个创意,去编排、做多种效果融合的这样的一个产物。
所以后面我们要讲的是一个我们对时间线的设计。

时间线的话,其实业界是没有标准的,不管是专业的还是云端的,都是没有标准的。
我们来看一下专业的非编,像 3A(Apple/Avid/Adobe),每一家都有自己定义的时间线结构。这些专业非编它的设计都是多个轨道的设计。首先它们肯定是音轨,视轨。
视轨是有多个轨道,并且它的素材和效果的设计都是各不相同的。当然也有传统EDL的这种设计。这种设计的话相对来讲是比较简单的,它只有单轨,只定义的素材,但是它没有定义效果。因为效果在不同厂家之间的描述是不一样的。我们基于这样一个现状,我们做了云加端可以复用的设计。我们是在时间线的核心四个要素,就是轨道、素材、效果和舞台中间进行一个取舍和平衡。
首先来讲特效这个东西是比较复杂的。在一些专业的设计当中,特效轨道是独立出现的,很有可能是独立出现的。在我们这个设计当中,特效轨道不强求独立出现,它可以作为视频素材的一个属性来出现。这样是为了降低云端用户和互联网用户的使用复杂度。
同时我们会保留轨道素材的设计,然后轨道素材所指向的原始视频仅仅是一个引用的关系。这样的话是为了增加应用性。否则的话整个时间线的设计会非常的臃肿。
另外,我们为了考虑后面的可扩展性,我们对整个时间线做了一个多轨的设计。因为最开始,很多智能制作在设计的过程中,都是单轨。但我们做第一版设计的时候,就考虑了一个多轨。因为多轨的设计可以保证之后程序迭代的过程中,不会因为打地基打的不好,而在原有基础上做颠覆性的改造。
所以我们在开始就把这个轨道按照素材类型去做了一个多轨的设计。最后,我们对于输出的画布,也就是输出的舞台的设计,是一个自动化、个性化和自定义结合的设计。既可以在不设置布局舞台的时候,能够根据原始素材的分辨率做自动的输出,也可以通过指定布局的方式做自定义的布局。
因为云端的设计需要考虑很多,要考虑很多不同的场景需求。可能绝大部分场景是 4:3、16:9 或者 9:16 或者 3:4 这样的需求。还有一些特殊的场景,它的分辨率可能是需要自定义的。所以我们整个的设计实际上是在轨道效果舞台和素材中间去进行了一个取舍和平衡。
(图中)左边的 timeline 的四个要素,是我们整个设计的核心元素,也就是时间线抽象成四层,每一层都是逐层递进的。可能一个 timeline 有多个轨道,每个轨道有多个素材,每个素材有多种效果。效果可以由人编排,也可以由机器编排。最后输出到舞台也好,画布也好。
这是视频最终输出的一个形态,这四个要素是时间线设计的核心。

前面说到的时间线可以大家可以想象一下,它的整体是比较复杂的。如果我自己要组织这样一个时间线的数据结构的话,那么我的工作量会非常大。为了降低时间线使用的门槛,并且同时保证专业性。我们做了一个模板工厂的设计。
在模板工厂的设计当中,我们会抽象出一些模板来。
这些模板是相当于把时间线完整的部分,或者是时间线一小部分进行抽象,然后用参数的方式去指定。在整个模板的设计过程中,支持嵌套或者组合。比如说做的一个比较炫酷的视频,需要素材的编排,包括效果的切换。或者添加些动图或者字幕,那我们可以用对应的模板去做嵌套和组合式的设计。
这样可以最大的利用模板的成果转化。这个模板工厂它核心解决的问题是:降低了使用时间线的门槛。同时还有一个最重要的,解决了制作创意的门槛。这两个设计为整个制作领域的专业度的提供保障。
模板工厂真正体现在包装和使用上。能在保证专业性的同时降低门槛,把整个制作设计普惠到每一个想要制作视频的民众身上。这两个门槛是我们认为在整个制作过程中最核心的门槛。
基于前面的一个结果,这是我们设计的一个智能媒体生产数据的数据流。
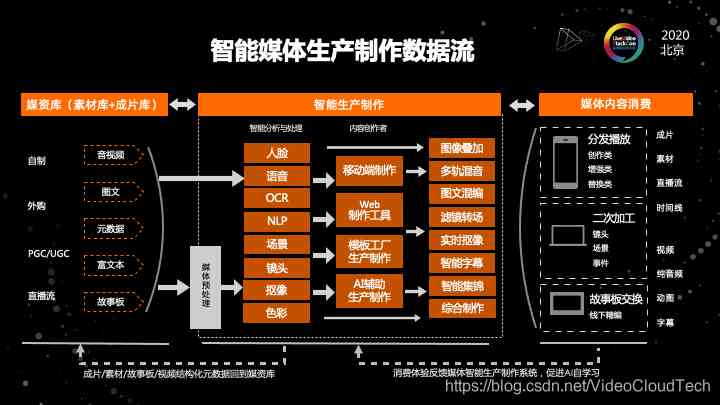
因为前面的架构比较干涩,是一个纯技术架构。那最终数据是怎么流转,怎么能从最原始的素材到最后合成出我想要的视频呢?
它的流程是这样的。我的左边是素材,我的素材和我想要制作的视频是一脉相承的。原始素材是有很多的类型的,可能会有音视图文,有一些副文本,甚至会有html 代码片段。这些都是我的素材库。
到了中间的过程,是最核心的智能生产制作链路。首先我的素材会经过一系列的AI处理,拿到结构化的信息。
在拿到结构化的信息之前,会先对素材进行处理。比方说会先去分析这个音视频的流信息,包括一些尺寸信息格式信息,这些信息会辅助中间智能生产过程中的输入。之后拿到这个预处理的信息之后,会对整个智能化的这个过程去做一个分析。这里的分析是多维度的。输出的可能是视觉层面上跟时间轴相关的,或者是跟时间区间相关的,也有可能是语音方面的,还有可能是一些颜色的配比,还是实时过程中抠像出来的像素集。然后拿到这些经过处理的数据之后,我就可以去跟工具结合制作了。
当然这些工具并不是每种工具都会用到每种能力。但是这些能力都可以作为这些工具的输入。工具的也是有多种的。包括移动端及web端、通过模板化批量化来生产的,以及通过AI的方式来辅助的。最终我们会有一系列生产效果。
图中智能生产制作右边这一部分,就是在制作过程中最常用的效果的抽象概念。
比方说我们会用到多层的图像的叠加,这个图像可能是视频,有可能是图片,会用到多轨的混音调音,用到图文在同一个轨道上的混编,会把素材的效果去做一个滤镜或者转场,会对一些直播流做前景人物或者主体的实时的抠像,也可以做智能的字幕。还可以做智能的集锦。也就说通过对视频的分析去提取出这个视频的精彩片段做一个集锦。
当然还有一些综合的制作过程,就是需要人工和智能去结合,来完成整个制作过程。
最终输出的话,实际上我们也把它抽象成三类。
- 第一类是用于分发播放的成片。成片我们可以把它总结为创作类,集锦就是创作类。
- 第二类是增强类:视频本來沒有字幕,通过语音识别加上字幕,这是属于增强类的。
- 第三类是替换类:主播直播时的背景不太美观,把背景替换成较吸引人的背景。
这个是输出成片的3种类型,当然还可以输出的是素材,输出的是素材时候,输出的内容是可以用于二次制作的。
这些素材其实是有的时候是比成片更为宝贵的。因为它是可以反复利用的。我们这套系统也能够输出素材。
最后我们在技术上并不是跟专业非编对立的,我们和专业非编是技术上合作的关系。
我们的模式相当于是互联网方式的新媒体剪辑。我们需要专业场合的时候,可以在云端做一个粗剪,然后在线下去做一个精编。这样可以把时间线去做一个交换,能够把整体的效果达到最优。
所以说我们在整个媒体内容消费过程中,得到一些反馈的体验,又会回馈到AI的体系。在数据上成一个闭环。推动这些算法继续迭代。同时的话我们生产的内容也会回到媒资库。回到媒资库之后,这些内容同时也会作为下一次视频制作的一个输入。大家可以看到阿里云在整个智能媒体生产制作中,设计的中心理念,是以生产制作为核心、AI 辅助。
Part 3 生产制作为核心、AI 辅助

但是我们为什么还需要 AI 呢?为什么还那么重视 AI 呢?这张图比较简单,但是,是一个我们实际上在思考这个用 AI 来辅助我们做生产的一个思路。
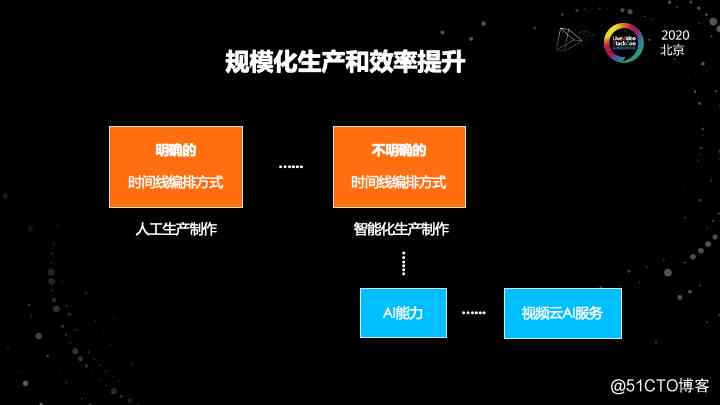
当最开始我们最原始的阶段是所有的东西都是由人来去编辑的,时间线的编排也是明确的,完全由人来主导。但是有一些场景是人比较费时间来主导或者不那么容易主导的。
举个例子,比方说幼儿园监控视频。家长说我特别想看到我们家小孩在幼儿园的表现,那从监控视频一帧一帧找自己小孩是非常费劲的。海量的视频要去处理的时候,会发现通过人已经没有办法去处理识别了,所以产量会很低。
当我们从人工编排方式要进化到大规模化的制作方式时,以及需要大幅度的提升自我效率的时候,我们势必要通过云计算和 AI 相结合的方式来做这件事情。
在整个过程当中,我们是要使用 AI 的能力。我觉得这个也是AI最大的魅力和价值,就是它能跟云计算很好的结合,能够为规模化制作以及海量素材分析提供帮助,提升媒体制作的一个效率。
接下来我会从三个实际的例子,来跟大家分享一下 AI 技术跟生产制作流程的一个融合。
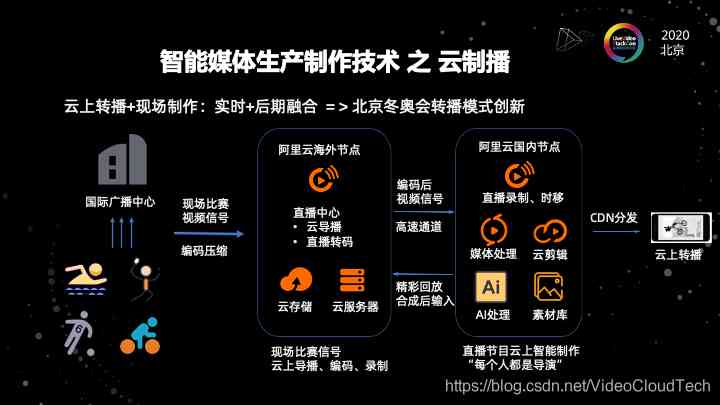
这是一个我们一个在云上转播的一个例子。在这个例子当中,我们可以看到传统的转播可能在现场有很多机位,有很多镜头,拍下来很多的视频素材。
但是我们在电视上看到的就是那几个频道,可能很多的视频素材被浪费掉了。我们在电视台看到的,是现场导播给我们生成的这样的画面。但实际上还有非常多的视频素材没有利用上。
因此,我们做了一个云上转播的一个架构。技术逻辑是这样的,我们首先还是会把视频的直播流,通过直播中心保存下来。然后我们用云端的导播创建多个导播的实例,在每一个实例可以使用不同的视角去做我想要的导播的场景。
云转播因为可以在互联网上分发,所以它对于原始直播流和素材的利用率是非常高的。我们也可以把这个视频收下来,进入这个直播的录制的过程。对这个实时的直播流用AI进行快速的处理。
在冬奥会转播之前,青奥会的演练有一个例子。我们当时是做了三种体育赛事的演练。针对这三个赛事,我们对运动员的运动轨迹进行跟踪,做云端的分析。然后把每一个运动员每一段运动当中精彩镜头通过AI处理的方式,利用云端剪辑的方式快速的生成素材,并且把素材又转推成视频流,再回转到云导播的输入,这相当于是对单边的直播流的收入。
另一方面是我通过实时技术去自动生成了这种回放集锦。并且在镜头之间还可以加一些效果。那这个时候其实如果不考虑完全实时性跟硬件导播台的差别的话,其实整个生产制作的模式已经跟传统的模式非常接近了。
我们的魅力就在于说,我们可以把非常多的直播流的利用起来。尤其是在一些赛事上,有些国家的运动员可能并不是前三名,可能这个播放镜头没有给到他们太多。但是这个国家的民众会非常关心自己国家的运动员。那这个时候我们可以通过这样的技术去让每一家机构都是一个导演,然后都能够去做整个转播过程,从直播流中导播自己想导播的画面。所以云直播的流程是把AI的能力和实时制作及离线或后期制作进行连接,同时能够大规模的利用上我们的系统,并且能够让所有的直播流都能发挥它的价值。
这是我们在云直播技术上的一个应用。
这个例子也是用的非常多的。我们在做一个片子的时候,我们不可能每个节目都是用完全不一样的创意。当我需要想复制我的创意的时候,但是我又想我复制的不那么的生硬的时候,我会非常需要这种的场景,就是一个成片模板化的制作,就是我的素材库里的东西是很多的。
前面也有讲到我们的素材库,可能是直播流,也有可能是离线的视频文件,还有可能是一些纯音频,可能是人声,可能是背景音乐,然后有可能是一些字幕。这些字幕可能是外挂字幕也有可能是一些横幅文字。然后还有可能是一些各种各样的图片,包括一些文本信息。甚至是一个代码段。例如 html 的代码段,或者是我代码当中的 canvas 的一个结构体。这些其实都是我们用于制作的素材。通过这些素材,我们怎么才能把这个节目制作出来呢?
我们可能还需要一个模板库,这个模板库是一个库的概念,我们可以在模板库利用设计师生态圈,设计师会在里面设计出很多的模板。但是我们其实并不需要用 AI 的方式去对整个的模板化的制作去进行一个进阶。但进阶在哪里呢?也就是说我们并不想原封不动的套用这些模板而不做一点变化。
比方说现在设计师设计了一个泡泡弹来弹去的背景,需要跟我的前景图片进行一个融合。这个泡泡他设计的时候,设计师只会设计配色和一些运动轨迹的一个变化。
但是我实际在做合成的时候,如果我每一张图片都用这个背景去合成的时候,可能会显得这个背景跟我的图片它是不协调的。
那我怎么才能去用 AI 的手段去来做这样一个改进呢?
就我们可能会去分析这个图片的色彩,并且去分析整个图片的调性和这个模板的运动轨迹的变化。通过分析的话,会把当前的素材,它所依赖的特征跟这个模板的参数进行解析的分割。然后能够把整个参数级的变化跟我素材的特征去进行结合。这样的话我就可以把基础的模板裂变成很多个性化的模板。这个个性化的模板可以相对应于每一个不同的素材。通过这个个性化的模板,再结合素材集。那前面的左边是说我的完整的素材集。可能我的素材集是一个海量的,我到底要用什么样的素材来做我的这个视频呢?那这里可能有一个挑选的过程。
挑选其实是包括两部分,一部分是搜索,一部分是截取。搜索的过程是AI能够深度参与的一个过程。可能会根据我的场景去定制,AI 分析可能是基于内容的,也有可能是基于关键词的,甚至是基于知识图谱的。然后搜索之后我到底是截取这个视频中的哪一段。这个是根据我的主题和视频内容选择的。如果我是做一个人物相关的这个视频,那我可能获取的素材是跟人物相关的这样的片段。如果我想要的是一个比如说动作类的,像赛事类的,我要做一个集锦,我可能需要关注的片段是一些跟运动画面,或者是跟一些镜头相关的一些东西。
我们通过两个部分的结合,就是从海量的素材库去搜索到每次制作需要的这个素材集,并且用AI的方式去把一个模板能够裂变成个性化的模板。之后,我们把这个模板和素材集然后去结合。这个就是我们的原材料。最终我们通过这样一个结合去构建时间线。
时间线是最终合成的一个依据。整个时间线通过合成和渲染,就能够渲染出视频或者一些泛媒体的影像.这个是我们就是在成片模板化制作的一个例子。它的核心实际上就是说我的每一个部分都是可以用 AI 的方式去取代的。运用 AI 的方式不只是用于到初步筛选素材,它还可以深度参与到整个制作过程当中。
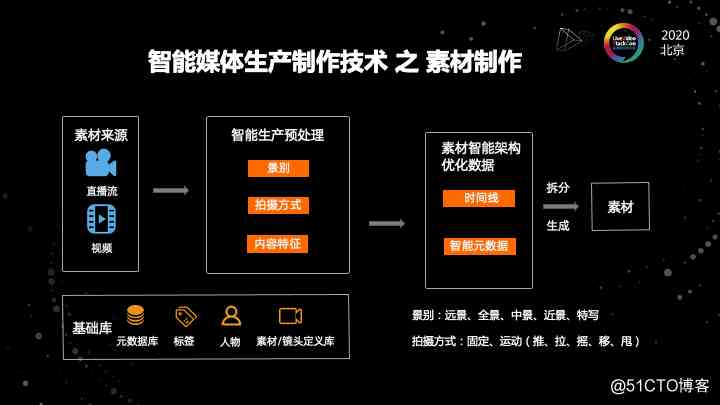
第三个就是刚才前面说到的,我们有时候并不是只是为了制作成片。而我的目标是制作一些素材。这些素材本身又是可以被反复使用。因为制作素材和制作成片有很大的不同。
就拿制作成片来说,我会用到非常多各种各样的效果,来保证我成片在视觉上的冲击力。但是我做素材的时候,我可能尽量的保证一个 clean 的结果。我可能并不希望加过多的效果的修饰。我的核心在于这个视频当中的哪些素材、哪些片段是能被重复使用的。
并且,我可能会根据我重复使用的一些原则和基准来去做我的挑选策略。我的素材源还是两类,大概分成两类,直播流和视频。然后经过视频智能生产的一个预处理,可以看到这个关注点跟原来成片制作是完全不同的。
我原来成片制作可能会关注各种效果,各种编排,各种多轨的一个叠加。但是我在做素材的时候,我关注的是这个视频本身镜头,这是一个重要的因素,我需要对镜头去进行非常严格的分析。这个镜头语言最核心的两个要素,就是景别和拍摄方式。
景别分成远景、全景、中景、近景和特写。每一种类型的镜头它的用法也是不一样的。我可能会通过AI的分析去识别出这个镜头的级别,并且把这个镜头的级别会对画面进行一个标注。
这个标注不光是标注在时间轴上,还要标注在视频画面上。另外一个非常重要的维度就是拍摄方式。
因为我们在做不同类型视频的时候,可能关注的拍摄方式不一样。如果我们在做一个故事类节目的时候,我会非常关注拍摄方式,就是镜头移动顺序不能错乱。把人的关注点按照顺序的方式去衔接起来,而不是整个画面去满世界的跳。所以我们需要去研究拍摄方式,就是用固定和运动的拍摄方式去分析镜头语言。然后能够把不同片段的拍摄方式能够提取出来。但是在有些场景,我们恰恰需要把这些拍摄方式去进行一个综合。
比如我们在做一个非常炫酷的音乐或者跳舞节目的集锦的时候,我就要故意制造这种错乱的拍摄视角,从而产生一个炫酷的效果。
所以我们需要根据场景结合来分析镜头语言,把这个镜头能够识别好。然后根据不同的景别和拍摄方式把把标签打好,这样的话才能够为后面再次的节目制作和视频制作做准备。
同时,我们仍然需要一个基础的库。比方我们需要数据库,需要镜头的标签库,还有镜头本身的视频库。以及因为人物创作是整个节目制作的非常关键的点。
所以我们还会构建一个人物库。基于这些基础库的构建和生产预处理,以及镜头的分析。我们就能做素材智能时间线的一个处理。然后我们经过素材的分析之后,我们会拿到素材的级别结果,拿到拍摄方式的结果,拿到内容特征提取的分析的结果。拿到这个东西之后,我们可以开始构建时间线。
在时间线的构建当中,因为我们可能在在中间这个阶段拿到的结果是非常零碎的。在这个零碎结果中,最终到底哪些画面才是我们能够复用的素材呢?那这个时候实际上是需要结合场景去定义一些词库,或者一些特征库的。
基于这些特征库,我们才能够生成需要的素材时间线的结构。这个素材时间线的结构拿到之后就可以去做素材真正的拆分了。有可能我们从新闻联播的一期完整节目,能够拿到一些有价值的片段。这些片段在传统行业被叫做所谓的通稿,或者是 clean 素材的概念。这个过程实际上就是我们整个智能制作相比于生产素材的一个不同。

所以我们举了三个例子,AI 能力是如何在不同的场景去跟我们的制作过程结合的。
最后总结一下我们的视频云智能媒体生产制作的技术层次。在我们的技术层次的设计当中,(图中)右边最下面是最核心的,就云制作的能力。
这个云制作的能力,实际上是一个硬通货和核心能力。像剪切拼接多轨叠加多轨混音,图文混编多帧率,然后多码率的一个自适应融合,还有字幕的能力,还有动图的能力,效果渲染滤镜转场等,这些都属于云制作的部分。
这是整个智能制作的一个最核心的部分,如果没有这些东西的话,不管是AI也好,包装也好,其实都是没有根基的。
在制作能力上面是我们设计的包装能力,包装能力是把制作能力规模化的一个技术层次。第一个看点是规模化,通过包装,可以把一些东西提炼出来,抽象出来,而不是每一次都零从开始制作。这是包装能力的第一个要点。包装能力第二个点是它可以用 AI 的方式多样化。
比方说我有一些模板,通过 AI 包装,可以把一个原始的素材裂变成多种多样的效果。还有就是组件化。当我把包装能力做成工具,或者做成sdk的话,这个是组件化的效果,这也是我们能够快速化和批量化的生成视频的一个能力。相当于制作专注在核心,而包装是专注在应用。
图中左边可以看到是 AI 的部分。
AI 在我们整个的体系当中,它是一个用于做智能化和规模化的一个抓手。就是它会深入的融合,在云制作和云包装的能力的每一个模块当中。
最上面这一层,是我们整个技术体系的生态部分,就是我们要做多端的融合,并且要搞定最后一公里的问题。
在这个过程当中,我们把这些能力有很好的一个出口做一个生态。然后我们对这个智能化的研究路径也有一些展望。
最开始我们批量化做视频,可能会用模板化的生产,或者用AI辅助制作和基于简单规则的就是内容生成。
这些是前三点,是我们已经做到的。第四点是还我们还没有做到的。是基于场景理解模板的推荐。现在的模板还是人去挑的。以及基于视频画面分析的 AI 的滤镜,现在无论是模板还是滤镜,其实都是由我们自己来指定的。
我们希望有一天能够用 AI 来做到这些事情。我的一个终极设想,希望未来 AI 能够真正独立去做创作,去生成有故事的视频。
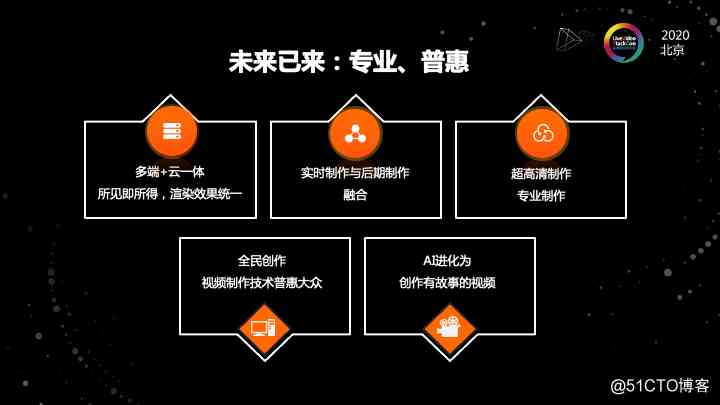
最后是我们对智能制作这个体系未来的一个看法。
我们认为未来在制作这个体系,它一定是两个方面都并重的。
首先是我们会越来越专业。从我们对于视频的需求来看到,最开始互联网上做视频是一个单轨制作,现在可能也是多轨、多种效果,多个素材,多种类型的一个制作。
整个的视频制作的链路会越来越专业。但是在专业的同时,我们觉得整个视频制作的参与者是越来越多了,这是一个普惠的过程,专业和普惠是一对看上去冲突,但又不矛盾的点。
通过我们的核心设计,以及打地基过程,让整个的行业包括AI的能力进一步提升,使未来专业化制作成为可能。
普惠是我们通过各种各样的工具,通过工具化的生产,能够降低创意和使用的门槛,能够让每一个人进入到制作过程中去做自己想要的视频。
这个是我们整体对这个未来的看法。那具体到点的话,我们认为,首先第一个当我们端跟云协同制作的时候,会有一个所见即所得,但是渲染效果不统一的问题。我们希望未来的话,端上的制作和云端的制作,它的效果是一致的。这是未来的一个趋势。这里可能会用到云渲染的技术。现在的实时制作和后期制作相对是割裂的。我们希望未来这两个部分是能够完全融合的。
第三块我们认为随着屏幕的增大和 5G 的到来,超高清的制作已经已经在一些场景去尝试,同时专业制作也是一个方向。
最后第四个一个普惠的过程,后面的进化过程可能是全民创作。视频的制作技术已经不再是所谓的高端的技术,而是一个普惠全民的技术。能够让每一个人都能制作自己想要的视频。最后,我和很多专业制作领域的同行聊,他们也是希望 AI 能够真正的进化为能够创作有故事的视频这样一个阶段。
今天的分享就到这了。谢谢大家。

如果你也对智能媒体生产群感兴趣,欢迎加入微信交流群:点击扫码
阿里云视频云技术公众号分享视频云行业和技术趋势,打造“新内容”、“新交互”。
版权声明
本文为[osc_97wmavr6]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4400708/blog/4708151
边栏推荐
- python小工具:编码转换
- 还不快看!对于阿里云云原生数据湖体系全解读!(附网盘链接)
- Windows10关机问题----只有“睡眠”、“更新并重启”、“更新并关机”,但是又不想更新,解决办法
- Automatically generate RSS feeds for docsify
- Major changes in Huawei's cloud: Cloud & AI rises to Huawei's fourth largest BG with full fire
- BCCOIN告诉您:年底最靠谱的投资项目是什么!
- Enabling education innovation and reconstruction with science and technology Huawei implements education informatization
- 供货紧张!苹果被曝 iPhone 12 电源芯片产能不足
- Tidb performance competition 11.02-11.06
- 分布式文档存储数据库之MongoDB基础入门
猜你喜欢

This year's salary is 35W +! Why is the salary of Internet companies getting higher and higher?
2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
Win10 terminal + WSL 2 installation and configuration guide, exquisite development experience
【Python 1-6】Python教程之——数字
Ali tear off the e-commerce label

擅长To C的腾讯,如何借腾讯云在这几个行业云市场占有率第一?
用 Python 写出来的进度条,竟如此美妙~
Is software testing training class easy to find a job
Bohai bank million level fines continue: Li Volta said that the governance is perfect, the growth rate is declining
为什么 Schnorr 签名被誉为比特币 Segwit 后的最大技术更新
随机推荐
Flink从入门到真香(6、Flink实现UDF函数-实现更细粒度的控制流)
Harbor项目高手问答及赠书活动
11 server monitoring tools commonly used by operation and maintenance personnel
Introduction to mongodb foundation of distributed document storage database
Q & A and book giving activities of harbor project experts
Bohai bank million level fines continue: Li Volta said that the governance is perfect, the growth rate is declining
Iqkeyboardmanager source code to see
Flink的sink实战之一:初探
Python basic syntax
Hematemesis! Alibaba Android Development Manual! (Internet disk link attached)
Share the experience of passing the PMP examination
一个方案提升Flutter内存利用率
Powershell 使用.Net对象发送邮件
Windows10关机问题----只有“睡眠”、“更新并重启”、“更新并关机”,但是又不想更新,解决办法
Bccoin tells you: what is the most reliable investment project at the end of the year!
YGC troubleshooting, let me rise again!
原创 | 数据资产确权浅议
This paper analyzes the top ten Internet of things applications in 2020!
Flink's sink: a preliminary study
Installing MacOS 11 Big Sur in virtual machine