当前位置:网站首页>数据工程系列精讲(第四讲): Data-centric AI 之样本工程
数据工程系列精讲(第四讲): Data-centric AI 之样本工程
2022-07-06 02:00:00 【亚马逊云开发者】

前言
我们之前通过三讲给大家介绍了Data-centric AI之特征工程,主要包括连续特征与category特征的特点,特征工程的详细步骤即特征预处理,特征生成,特征选择和特征降维,让大家对特征工程有了更多和更深的理解。接下来我们介绍与特征工程紧密相关的样本工程,这里讨论的是针对结构化数据的样本工程。
从我参与的多个ML项目来看,样本工程可以让不同角色的人员都参与进来(比如项目负责人,业务运营人员,算法工程师,机器学习产品经理,机器学习技术咨询专家,解决方案架构师等等),从而形成全方位的头脑风暴,更加通透的进行机器学习建模。
样本工程会涉及到建模思路的梳理,它不像特征工程那样还有一些典型的方法论,它更加艺术,更像是一种思维旅行,是一个需要反复进行脑中走查的过程,我们之后来慢慢体会。
更详细的data-centric AI相关的内容请参考该github repo。(https://github.com/yuhuiaws/ML-study/tree/main/Data-centric%20AI)
本文大纲
一、什么是样本工程
二、目标任务的抽象和定义
三、样本的表示
四、样本集的构造
五、举例:用户流失预测任务
什么是样本工程
我们首先看什么是样本,简单讲就是多个自变量和一个或多个因变量/目标变量组成的一个表示,或者说特征表示集合 + 标注/label就认为是一个样本。上面指的是训练时带有监督信号(监督信号就是指标注)的样本,预测时的样本不需要因变量/标注,对于非监督任务训练时和预测时都不需要因变量/标注。
样本工程没有看到什么正式的定义,这里我粗略的定义如下,样本工程即对某个目标任务或者多个相关目标的任务建模来准备样本集的整个工程化过程。而我认为的样本工程的三个要素是,目标任务的抽象和定义,样本的表示和样本集的构造,接下来我们讨论每个要素。
目标任务的抽象和定义
机器学习建模可以简单认为是把一个业务问题转化为数学问题的过程。很多情况下,这个过程不是那么显而易见和直接的,所以准确无歧义的表达目前想要实现的目标任务是什么非常重要,而用举例子的方式来表达这个目标任务可能效果更好。
实际项目中,目标任务的抽象和定义的过程可能并不是一蹴而就的,可能是一个迭代的过程,我根据项目的经验总结如下:首先在项目刚启动的时候最少需要1-2次面对面的头脑风暴,这个头脑风暴最好有各种角色的人(至少需要算法工程师,机器学习技术咨询专家,业务运营)参与进来,把目标任务给初步确定下来;然后在下面的每个节点做review。
review节点 | 介绍 | 备注 |
原始数据review | 就目前所有能拿到的原始表或者日志来进行,目的是讨论原始特征的抽取/生成。 | 需要逐个字段深入讨论,并根据当前对目标任务的理解挖掘一些可能的候选特征。 |
数据清洗后第一版特征集即原始特征review | 目的是根据当前可用的特征来进行模型的选型,比如可直接用以及用其他办法生成的特征仍然太少,可能用深度学习模型不合适,甚至用机器学习都不合适(比如在可用特征不多的情况下,对付费人群和非付费人群计算聚合后的特征向量,并基于向量相似度做新用户是否付费预测的效果可能会更好)。 | 可能需要对目标任务进行重新设定:或者把目标任务拆分为多个子任务,当前先实现其中某一个子任务;或者把目标任务转为某个类似的任务,或者在这个时候才弄清楚目标任务真正想要做什么事情。 |
建模后第一个版本review | 根据实际预测的效果来做分析,看当前模型/算法是否符合预期。如果不符合预期的话,可能需要在样本/特征,模型/算法选型或者目标任务设定上重新思考。 | 回归任务可能比分类任务更难拟合,可以考虑是否可以把回归任务转为分类任务来近似满足目标任务。 |
对于有监督信号的目标任务,我们需要判断标注/label如何确定(这个事情没有想象中那么简单),也就是说需要有一个合理的逻辑来进行标注。下面举两个例子来说明:
_ | 介绍 |
电商推荐的CTR点击率预估排序任务 | 并不是物品item被点击了就要标注为1,要理解我们本质上是想建模用户是否对item感兴趣而不是点击动作。比如点击了某个item(可能是误点击)并很快关闭了这个item的详情页,这个情况可能应该标注为0而不是1;比如点击了某个item但是把这个item加入了黑名单或者点”踩”了,这个时候需要标注为0。 |
视频推荐的CTR点击率预估排序任务 | 打label时,需要考虑长视频和短视频是否分开建模。如果分开建模的话,长视频和短视频的分界线如何确定;如果统一建模的话,如何公平对待长视频和短视频,用播放比率和播放时长做条件或的方式可能更合理(听说Netflix播放时长判断逻辑中使用的阈值是10分钟) |
样本的表示
在目标任务初步确定以后,我们就需要思考如何表示一个样本。样本的表示和样本id是两回事,样本id是为了对齐和跟踪,样本的表示是指样本的内涵展现。样本的表示可以从多个角度来看:
_ | 介绍 | 举例 |
特征 种类 | 对当前的目标任务来说,深入分析可以涵盖的特征的大的种类。 | 对于预测股票价格的任务,种类有股票侧特征,上下文特征,交叉特征; 对于欺诈检测任务,种类有用户侧特征,业务侧特征,上下文特征,交叉特征。 |
是否有 “人”这样的主体 | 如果目标任务是以”人”为主体,就会有人与物之间的交互行为,这样的特征就是强特征,不要漏掉。 另外,对于以“人”为主体的任务,需要考虑每个人一条样本还是每个人多条样本,从而对样本整体规模有个理性把握。 | 智能选址(预测某个地理范围适合建立学校,医院或者酒店这样的任务)的任务,一个地理范围一个样本。 游戏装备推荐的任务,一个用户多个样本。 欺诈检测的任务,如果想根据某个用户最近的一些行为来判定是否是欺诈用户,那么一个用户一个样本;如果是想判定用户的某次行为是否是欺诈行为,那么一个用户会有多个样本。 |
样本是否基于时间戳来构造 | 基于时间戳组织的样本有两种:一种是时间序列预测任务的样本;一种是时间戳加主体作为样本的区分。 | 预测衣服销量的任务,目标变量可以按照比如天的频率来组织,和目标变量相关的自变量(包括动态变化的),也按照相同的频率来组织。 预测每次广告当天拉新的用户可能在接下来三个月带来的总收入这样的任务,每个时间戳+每个广告ID来组织一条样本。 |
样本中字段的用途 | 样本中有的字段用于模型学习;有的字段不用于模型学习(比如上面提到的用来对齐的样本id)。 | 智能派活任务中,每个jobid只会出现一次,不需要作为特征建模到模型中。 如果用LightGBM模型跑排序任务的话,那么usrid和itemid这样的字段可以考虑不作为特征建模,或者对usrid和itemid做了embedding以后再送入LightGBM;但是如果用深度模型来跑同样的任务的话,usrid和itemid最好作为特征建模。 |
样本集的构造
1.样本集的切分
只要有监督信号,不管是不是用监督学习来建模,都可以划分为训练集和验证集(比如有时候会把监督学习任务转为非监督学习任务,这个时候切分验证集是因为有监督信号对于非监督学习来说更容易评估)。
训练集和验证集的切分准则是,每个集合的样本量都要足够,如果是分类任务还要保证训练集和验证集中的小类别样本数量足够多。
训练集和验证集常见的切分方法:按照时间窗口来切分,训练集在前,验证集在后;随机按照比例来切分,如果是分类任务的话,最好按照类别分层来随机切分(按照类别来分层切分的目的是让训练集和验证集都和原始数据集有一样的类别样本比例)。
2.样本的采样
对于是否需要从已经收集的样本集中采样一些样本,需要考虑:如果是因为数据集太大单机训练时间太长所以做采样,那么建议还是优先考虑用分布式训练来加速而不是做采样;如果是为了缓解样本类别不均衡,可以尝试采样大类别的样本来看模型效果;如果要采样,针对的是训练集做采样,不要对验证集做采样(因为需要尽量让验证集和线上的数据分布一致);采样后训练集的数据分布发生了变化,如果是简单的排序比如推荐系统中的CTR预估排序任务,它只关心相对顺序,采样前后不会改变这个相对顺序,如果是类似竞价广告CTR预估排序任务,它使用ECPM排序公式,它需要关注点击概率pctr的绝对值(因为它需要用pctr 乘以bidding价格以及动态排序因子),所以采样前后pctr的绝对值可能会变化,所以这个情况下需要做校准。
对大类别做采样,除了随机采样,还可以考虑按照时间窗口来采样,有两种方法:每天按照固定采样率做等量采样或者按照时间的权重来增加采样(在确定整体采样比例情况下,根据总的负样本量计算出需要采样的量,然后计算每天的采样比重。需要满足的条件是,离当前越近,采样比重越大)。
举例:用户流失预测任务
判定一个用户是否流失有2种思路:第一种思路,设置一个时间锚点(比如5月10号),只要用户最近一次关键行为(比如登录行为)的时间戳距离时间锚点的长度大于等于设定的某个固定时间长度(比如7天),就认为该用户是流失的;第二种思路,设置一个观察期时间窗口(比如从5月1日到5月7日共7天),只关心用户在观察期时间窗口内是否有关键行为(比如登录行为),没有的话该用户就是流失的(第二种思路可能用的更多,因此我们下面的讨论都是基于第二种思路)。
这里的目标任务是对某游戏的老用户预测是否流失,对于这个目标任务的梳理,我们至少需要考虑下面的几个问题:如何定义一个用户是流失的,模型训练好以后如何使用该模型来预测用户的流失,数据集的时间窗口选择,训练集和验证集如何切分,用户流失预测模型的训练迭代。
1.如何定义一个用户是流失的
先解释一下流失周期,它定义的是某用户没有发生某种关键行为的最小时间间隔(也就是说用户已经流失的时间是大于等于流失周期的)。对流失比较经典的定义是“超过一段时间间隔未进行关键行为的用户”,关键点在于如何界定这个时间间隔(即流失周期)和关键行为(即流失行为)。不同的业务场景,这个关键行为一般会有区别。
对于游戏场景下用户的流失,可以选择“有效登录”这一行为作为是否流失的关键行为。这里需要考虑如何判定用户为有效登录:如果登录后马上就退出可能就应该不算做有效登录;或者登录以后马上把这个应用切换到了后台来挂机,这种也不应该算做有效登录。也就是说,应该把用户有登录动作,并且把应用放在前台,且有足够长的停留时间(比如10分钟)才认为是一次“有效登录”。
对于流失周期的界定,常见有两种方法:
分位数界定法:可以使用90%分位数的方式来选择流失周期,也就是根据用户最近连续两次关键行为(比如登录)的时间间隔从小到大来排序,90%分位数对应的时间间隔就作为流失周期。
拐点界定法(可能应该优先用这个方法)
参考如下:
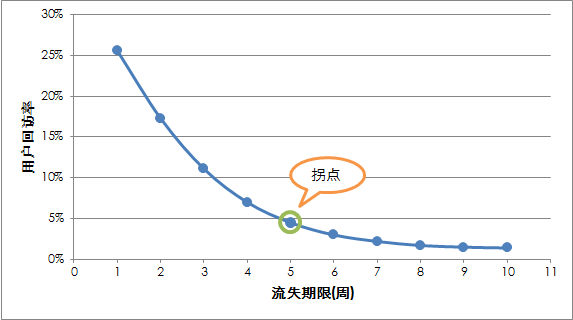
每个流失周期对应的用户回访率的计算需要计算流失用户数和回访用户数(用户回访率 = 回访用户数 ÷ 流失用户数 × 100%),具体计算过程参考如下:流失用户数计算比较直接,根据流失周期设定观察期窗口的开始和结束位置,在窗口内没有进行登录的用户就认为是流失(这里为了方便的对比不同的流失周期,观察期窗口的开始位置设置为相同的,不同的流失周期得到不同的结束位置)。
对于如何计算回访用户数,我理解应该会首先定义一个比较长的周期,对于这里的例子来说,因为横坐标中有数据点的最大流失周期为10周,这里就把这个用户回流周期也设定为10周,对于流失周期是1周并且被判定为流失的用户如果在后续的10周内只要有有效登录就认为是回流用户;同理,对于流失周期是10周并且判定为流失的用户在后续的10周内只要有有效登录就认为是回流用户(我这里是假设对不同的流失周期使用了一致的回流周期,这样设置是否合理以及回流周期具体多长,最好与业务运营人员确认)。
如果曲线没有拐点的话,也可以依据产品经验来拍脑袋,一般产品的回访率5%-10%(通过固定了回访率然后在曲线找到对应的流失周期),不管划分多长的时间周期作为流失周期都会存在回访,误差不可避免。
2.模型训练好以后,
如何使用该模型来预测用户的流失
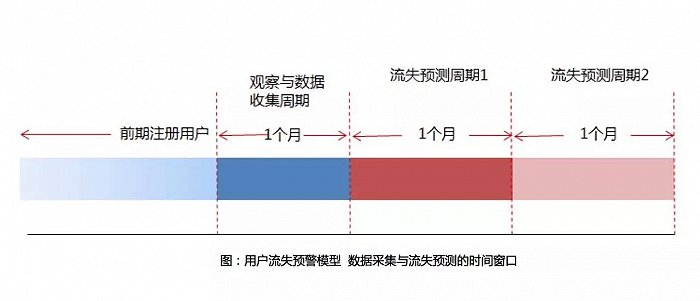
如上图所示,这里设定的流失周期是1个月,那么在准备开始训练的时间点往前推一个月这个时间窗口就是用来观察我们感兴趣的“老用户”在这个时间窗口内是否有有效登录行为,如果有的话,表示该用户是留存用户,如果没有的话说明该用户有超过1个月时间没有有效登录行为了,标记为流失用户。
模型训练完以后就可以马上针对在观察期窗口内有关键行为的那些用户进行预测,预测他们从训练结束的时间点开始往将来外推一个时间段来看他们是否有关键行为。这个外推的时间段就是流失预测周期,流失预测周期应该设置为与流失周期一致,因为我们要尽量保证预测时和训练时一致(也就是说,训练时打label给的观察期窗口的长度即流失周期需要和预测时给的外推时间段一样长才合理)。
正如上图中看到的:在第一次流失预测周期窗口的开始处预测的是观察期窗口内有关键行为的那些用户在第一个流失预测时间窗口内是否有关键行为;第二次流失预测周期窗口的开始处预测的是在第一个流失预测时间窗口内有关键行为的那些用户在第二个流失预测时间窗口内是否有关键行为,以此类推!
3.数据集的时间窗口选择
在流失周期确定以后,我们需要来选择数据集的时间窗口。这里的时间窗口又包括两个:
从哪天开始收集用户的登录日志:首先考虑是针对所有用户还是老用户,一般流失预测更多针对的是老用户,而新的用户一般需要时间成长为老用户(而这个新老用户的判定条件也是根据业务来具体设定的,比如累计玩游戏时间超过1个月的新用户就可以认为是老用户了);接着考虑需要纳入数据集来训练的最早的时间如何选择。
那对于上图提到的前期注册用户也就是我这里说的“老用户”,这个时间窗口往前推多少合适呢?我觉得主要有两个原则:一是数据样本要足够(尤其是正样本也就是流失用户的样本要足够);二是前推的时间窗口不要太长(前推时间窗口太长的话,会把一些都已经流失很久的老用户的样本也纳入模型来学习,可能因为时效性等因素这些已经流失很久的老用户并不是我们这个流失预测模型所关心的人群。有的业务可能只是关心比如从观察期窗口的开始位置往过去推一个月,看这一个月活跃的用户是否在观察期窗口内有关键行为,也就是前推窗口就固定设置为1个月 ,那这样得到的数据集可能太小,尤其是流失样本太少,这个时候可以使用多个观察期窗口来得到更多的流失样本)。
需要统计用户多长时间内的行为:这个也没有什么定论,这个时间段是观察期窗口之前的用户last-login最近一次登录时间戳往前推的一段时间。一个方法是通过对多个统计周期的特征来分别建模,然后在验证集上看ROC面积哪个更大也就是预测效果更好,还需要考虑数据的时间成本和公平性(我们关注的人群中会包含那些从新用户转为老用户的人群,因此不适合把这个统计时间窗口弄的很长,因为这批人只有相对比较短的时间内有行为,这个统计时间弄的太长的话对这批人不公平。
比如用6周的数据ROC面积大于1个月的数据,而2个月的数据只略优于6周的数据,在同时考虑数据的时间成本,公平性和预测效果的情况下,这里选择6周而不是2个月作为数据提取的周期是更好的)。
4.训练集和验证集如何切分
对于用户流失预测这样的场景,可能不需要按照时间线来切分训练集和验证集,因为用户流失预测这样的场景可能并不是一个时间依赖相关的任务,那么对这样的数据集就可以按照比例来切分(具体考虑到流失/留存类别样本的不均衡,这里做训练集和验证集切分的时候最好做分层按比例切分)。
当然对于用户流失预测任务,按照时间线来构造训练集和验证集也是可以的。比如流失周期是7天,训练集取的是4月1号到4月30号的这些活跃用户,这些用户在5月1号到5月7号这个窗口内是否有关键行为作为他们的label;验证集取5月1号到5月7号的活跃用户,这些用户在5月8号到5月14号这个窗口内是否有关键行为作为他们的label。
5.用户流失预测模型的训练迭代
针对这个场景来说,模型的训练迭代可以选择的方式是:每隔一段时间做全量数据重新训练;增量训练方式。如果用增量训练方式的话,每个训练周期的用户的知识可能会学习到(假设模型的容量足够大);如果每隔一段时间做全量数据重新训练的话,虽然可以通过把用户的旧的先验知识作为特征建模进来,但是即使这样也可能对用户旧的知识的学习没有增量训练那么好,而且每隔一段时间做全量数据重新训练更强调的是最近时间段的数据对模型影响更大(这个是搜推广三大领域的排序模型最常用的训练方式),对于用户流失预测场景的话,可能这个因素不重要。因此我觉得可能用增量训练方式对这个用户流失预测场景更合适。
另外,用增量训练还是全量训练和选用的模型还有关系:像XGBoost,LightGBM这样的boosting方式的模型,不是很适合做增量训练(尽管他们支持),因为他们的模型内涵更适合做全量数据训练;如果用深度模型的话,天然支持增量训练。
如果选择增量训练的方式,需要考虑增量训练的频率,对于用户流失场景可能不太适合按天来增量做,因为需要等待一定的天数来积累新的样本,增量训练频率(或者我们叫训练周期)和流失预测周期没有什么必然联系,不过把增量训练周期设置为和流失周期以及流失预测周期一致的话,数据处理可能更方便一些;如果选择全量训练的话,对于用户流失预测这个任务,可能每隔几天或者一周来进行训练是比较合适的。
总结
Data-centric AI之样本工程到此介绍完毕,本文介绍了样本工程的基本概念以及三个要素,即目标任务的抽象和定义,样本的表示和样本集的构造,并在此基础上讲解了用户流失预测任务的样本工程。
相信大家开始感受到样本工程的魅力并跃跃欲试了,我们接下来介绍Data-centric AI之数据集的质量。感谢大家的耐心阅读。
本篇作者

梁宇辉
亚马逊云科技
机器学习产品技术专家
负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,深度参与了很多真实客户的机器学习项目的构建以及优化。对于深度学习模型分布式训练,推荐系统和计算广告等领域具有丰富经验。

听说,点完下面4个按钮
就不会碰到bug了!
边栏推荐
- [Jiudu OJ 09] two points to find student information
- Comments on flowable source code (XXXV) timer activation process definition processor, process instance migration job processor
- 同一个 SqlSession 中执行两条一模一样的SQL语句查询得到的 total 数量不一样
- NiO related knowledge (II)
- RDD creation method of spark
- [flask] official tutorial -part3: blog blueprint, project installability
- leetcode3、實現 strStr()
- FTP server, ssh server (super brief)
- [eight part essay] what is the difference between unrepeatable reading and unreal reading?
- 【Flask】官方教程(Tutorial)-part3:blog蓝图、项目可安装化
猜你喜欢
![[flask] official tutorial -part3: blog blueprint, project installability](/img/fd/fc922b41316338943067469db958e2.png)
[flask] official tutorial -part3: blog blueprint, project installability
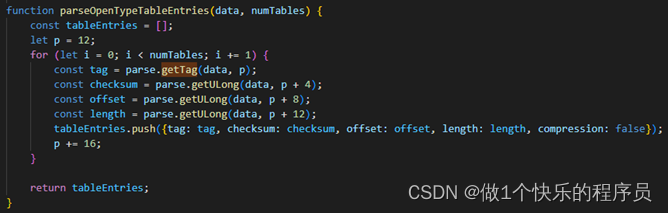
TrueType字体文件提取关键信息
![NLP fourth paradigm: overview of prompt [pre train, prompt, predict] [Liu Pengfei]](/img/11/a01348dbfcae2042ec9f3e40065f3a.png)
NLP fourth paradigm: overview of prompt [pre train, prompt, predict] [Liu Pengfei]
【clickhouse】ClickHouse Practice in EOI
0211 embedded C language learning

Audio and video engineer YUV and RGB detailed explanation

Multi function event recorder of the 5th National Games of the Blue Bridge Cup

插卡4G工业路由器充电桩智能柜专网视频监控4G转以太网转WiFi有线网速测试 软硬件定制

Basic operations of databases and tables ----- default constraints
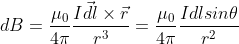
Derivation of Biot Savart law in College Physics
随机推荐
阿裏測開面試題
leetcode3、實現 strStr()
Extracting key information from TrueType font files
Virtual machine network, networking settings, interconnection with host computer, network configuration
[depth first search notes] Abstract DFS
Unity learning notes -- 2D one-way platform production method
Jisuanke - t2063_ Missile interception
It's wrong to install PHP zbarcode extension. I don't know if any God can help me solve it. 7.3 for PHP environment
MySQL learning notes - subquery exercise
D22:indeterminate equation (indefinite equation, translation + problem solution)
Use image components to slide through photo albums and mobile phone photo album pages
How to improve the level of pinduoduo store? Dianyingtong came to tell you
leetcode3、实现 strStr()
[flask] official tutorial -part3: blog blueprint, project installability
Campus second-hand transaction based on wechat applet
Ali test Open face test
Redis守护进程无法停止解决方案
Basic operations of database and table ----- delete data table
Using SA token to solve websocket handshake authentication
RDD partition rules of spark