当前位置:网站首页>RDD partition rules of spark
RDD partition rules of spark
2022-07-06 02:04:00 【Diligent ls】
1.RDD Data is created from a collection
a. Do not specify partition
Create... From collection rdd, If you do not write the number of partitions manually , The default number of partitions is the same as that of local mode cpu The number of cores is related to
local : 1 individual local[*] : Number of all cores of notebook local[K]:K individual
b. The specified partition
object fenqu {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkCoreTest")
val sc: SparkContext = new SparkContext(conf)
//1)4 Data , Set up 4 Zones , Output :0 Partition ->1,1 Partition ->2,2 Partition ->3,3 Partition ->4
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 4)
//2)4 Data , Set up 3 Zones , Output :0 Partition ->1,1 Partition ->2,2 Partition ->3,4
//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 3)
//3)5 Data , Set up 3 Zones , Output :0 Partition ->1,1 Partition ->2、3,2 Partition ->4、5
//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5), 3)
rdd.saveAsTextFile("output")
sc.stop()
}
}The rules
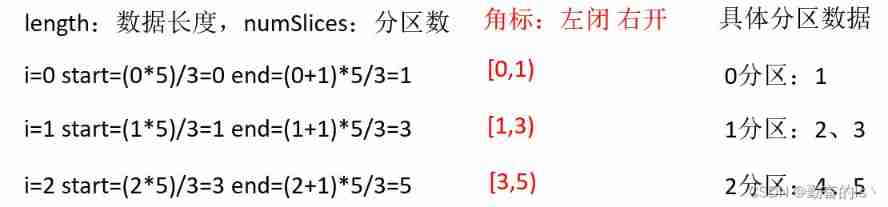
The starting position of the partition = ( Zone number * Total data length )/ Total number of divisions
End of partition =(( Zone number + 1)* Total data length )/ Total number of divisions
2. Create after reading in the file
a. Default
The default value is the current number of cores and 2 The minimum value of , It's usually 2
b. Appoint
1). How to calculate the number of partitions :
totalSize = 10
goalSize = 10 / 3 = 3(byte) Indicates that each partition stores 3 Bytes of data
Partition number = totalSize/ goalSize = 10 /3 => 3,3,4
4 Subsection greater than 3 Subsection 1.1 times , accord with hadoop section 1.1 Double strategy , Therefore, an additional partition will be created , That is, there are 4 Zones 3,3,3,1
2). Spark Read the file , It's using hadoop Read by , So read line by line , It has nothing to do with the number of bytes
3). The calculation of data reading position is in the unit of offset .
4). Calculation of offset range of data partition
0 => [0,3] 1 012 0 => 1,2
1 => [3,6] 2 345 1 => 3
2 => [6,9] 3 678 2 => 4
3 => [9,9] 4 9 3 => nothing
边栏推荐
- Basic operations of databases and tables ----- unique constraints
- Leetcode skimming questions_ Verify palindrome string II
- [flask] official tutorial -part2: Blueprint - view, template, static file
- Extracting key information from TrueType font files
- Redis如何实现多可用区?
- 阿裏測開面試題
- Accelerating spark data access with alluxio in kubernetes
- Computer graduation design PHP campus restaurant online ordering system
- [understanding of opportunity-39]: Guiguzi - Chapter 5 flying clamp - warning 2: there are six types of praise. Be careful to enjoy praise as fish enjoy bait.
- Derivation of Biot Savart law in College Physics
猜你喜欢
![[flask] official tutorial -part3: blog blueprint, project installability](/img/fd/fc922b41316338943067469db958e2.png)
[flask] official tutorial -part3: blog blueprint, project installability

2022 PMP project management examination agile knowledge points (8)
2 power view
![[solved] how to generate a beautiful static document description page](/img/c1/6ad935c1906208d81facb16390448e.png)
[solved] how to generate a beautiful static document description page
Visualstudio2019 compilation configuration lastools-v2.0.0 under win10 system
0211 embedded C language learning

国家级非遗传承人高清旺《四大美人》皮影数字藏品惊艳亮相!

Basic operations of databases and tables ----- non empty constraints
Computer graduation design PHP part-time recruitment management system for College Students
同一个 SqlSession 中执行两条一模一样的SQL语句查询得到的 total 数量不一样
随机推荐
3D vision - 4 Getting started with gesture recognition - using mediapipe includes single frame and real time video
Dynamics 365 开发协作最佳实践思考
【Flask】静态文件与模板渲染
[flask] obtain request information, redirect and error handling
Ali test open-ended questions
Basic operations of databases and tables ----- primary key constraints
Executing two identical SQL statements in the same sqlsession will result in different total numbers
[Clickhouse] Clickhouse based massive data interactive OLAP analysis scenario practice
SQL statement
Computer graduation design PHP campus restaurant online ordering system
Internship: unfamiliar annotations involved in the project code and their functions
Apicloud openframe realizes the transfer and return of parameters to the previous page - basic improvement
国家级非遗传承人高清旺《四大美人》皮影数字藏品惊艳亮相!
500 lines of code to understand the principle of mecached cache client driver
Maya hollowed out modeling
leetcode-两数之和
Virtual machine network, networking settings, interconnection with host computer, network configuration
How does redis implement multiple zones?
阿里测开面试题
Win10 add file extension