当前位置:网站首页>图像检索(image retrieval)
图像检索(image retrieval)
2022-07-04 15:38:00 【InfoQ】
边栏推荐
- 照明行业S2B2B解决方案:高效赋能产业供应链,提升企业经济效益
- 【测试开发】软件测试——基础篇
- 2022年国内云管平台厂商哪家好?为什么?
- 【Unity UGUI】ScrollRect 动态缩放格子大小,自动定位到中间的格子
- 安信证券手机版下载 网上开户安全吗
- 矿产行业商业供应链协同系统解决方案:构建数智化供应链平台,保障矿产资源安全供应
- Solution du système de gestion de la chaîne d'approvisionnement du parc logistique intelligent
- Yanwen logistics plans to be listed on Shenzhen Stock Exchange: it is mainly engaged in international express business, and its gross profit margin is far lower than the industry level
- System. Currenttimemillis() and system Nanotime (), which is faster? Don't use it wrong!
- Li Kou today's question -1200 Minimum absolute difference
猜你喜欢
第十八届IET交直流输电国际会议(ACDC2022)于线上成功举办
第十八届IET交直流輸電國際會議(ACDC2022)於線上成功舉辦

新的职业已经出现,怎么能够停滞不前 ,人社部公布建筑新职业
Can you really use MySQL explain?

矿产行业商业供应链协同系统解决方案:构建数智化供应链平台,保障矿产资源安全供应
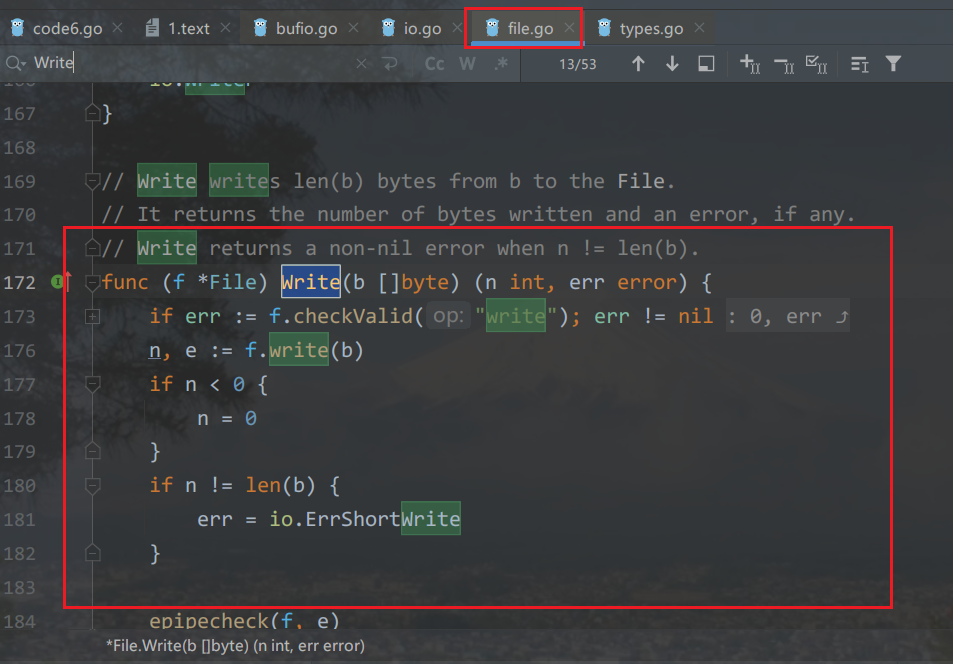
【Go ~ 0到1 】 第六天 文件的读写与创建

Detailed process of DC-2 range construction and penetration practice (DC range Series)

The test experience "tortured" by the PMP test is worth your review
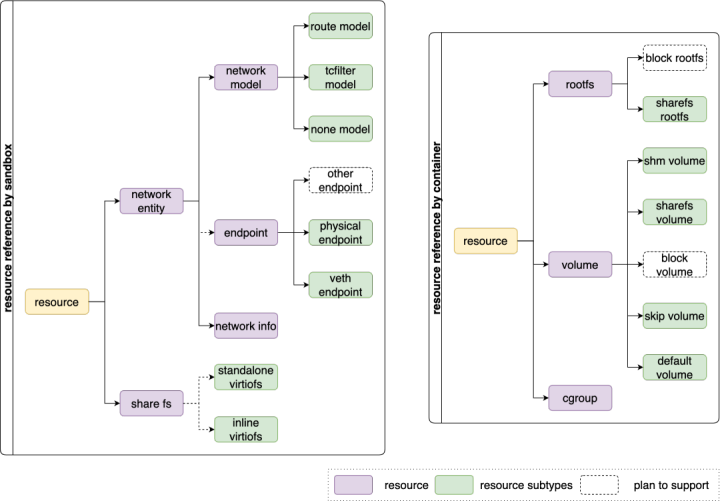
Years of training, towards Kata 3.0! Enter the safe container experience out of the box | dragon lizard Technology
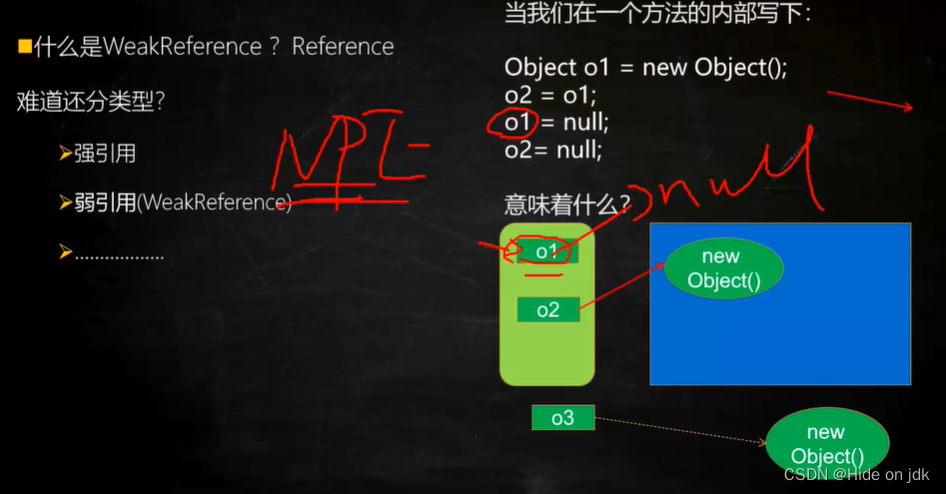
Understand ThreadLocal in one picture
随机推荐
PingCode 性能测试之负载测试实践
周大福践行「百周年承诺」,真诚服务推动绿色环保
Is it safe for CITIC Securities to open an account online? Is the account opening fee charged
Position encoding practice in transformer
How to choose one plus 10 pro and iPhone 13?
第十八届IET交直流输电国际会议(ACDC2022)于线上成功举办
利用win10计划任务程序定时自动运行jar包
PyTorch深度学习快速入门教程
Leetcode list summary
C# 更加优质的操作MongoDB数据库
leetcode刷题目录总结
51 single chip microcomputer temperature alarm based on WiFi control
Object.keys()的用法
NFT liquidity market security issues occur frequently - Analysis of the black incident of NFT trading platform quixotic
中信证券网上开户安全吗 开户收费吗
一加10 Pro和iPhone 13怎么选?
祝贺Artefact首席数据科学家张鹏飞先生荣获 Campaign Asia Tech MVP 2022
【云原生】服务网格是什么“格”?
Is it safe for Bank of China Securities to open an account online?
GO开发:如何利用Go单例模式保障流媒体高并发的安全性?