当前位置:网站首页>Interpretation of deepsort source code (VII)
Interpretation of deepsort source code (VII)
2022-07-27 07:05:00 【Delin enbao】
Catalog
deepsort Principle and analysis summary
tracker.py
# vim: expandtab:ts=4:sw=4
from __future__ import absolute_import
import numpy as np
from . import kalman_filter
from . import linear_assignment
from . import iou_matching
from .track import Track
class Tracker:
"""
This is the multi-target tracker.
Parameters
----------
metric : nn_matching.NearestNeighborDistanceMetric
A distance metric for measurement-to-track association.
max_age : int
Maximum number of missed misses before a track is deleted.
n_init : int
Number of consecutive detections before the track is confirmed. The
track state is set to `Deleted` if a miss occurs within the first
`n_init` frames.
Attributes
----------
metric : nn_matching.NearestNeighborDistanceMetric
The distance metric used for measurement to track association.
max_age : int
Maximum number of missed misses before a track is deleted.
n_init : int
Number of frames that a track remains in initialization phase.
kf : kalman_filter.KalmanFilter
A Kalman filter to filter target trajectories in image space.
tracks : List[Track]
The list of active tracks at the current time step.
"""
def __init__(self, metric, max_iou_distance=0.7, max_age=30, n_init=3):
# metric Is a class , Used to calculate the distance ( Cosine distance or Mahalanobis distance )
self.metric = metric
# iou Maximum value when matching
self.max_iou_distance = max_iou_distance
# Unmatched track Maximum mismatch times , That is, directly specify cascading matching cascade_depth Parameters
self.max_age = max_age
# from unconfirmed track To confirmed track The minimum number of matches
self.n_init = n_init
# Kalman filter
self.kf = kalman_filter.KalmanFilter()
# Save a series of tracks
self.tracks = []
# Next assigned track id
self._next_id = 1
def predict(self):
"""Propagate track state distributions one time step forward.
This function should be called once every time step, before `update`.
"""
# First frame ,tracks It's empty , Do not execute forecast
for track in self.tracks:
track.predict(self.kf)
def update(self, detections):
"""Perform measurement update and track management.
Parameters
----------
detections : List[deep_sort.detection.Detection]
A list of detections at the current time step.
"""
# Run matching cascade.
matches, unmatched_tracks, unmatched_detections = \
self._match(detections)
# Update track set.
# For the result of matching , to update track
for track_idx, detection_idx in matches:
self.tracks[track_idx].update(
self.kf, detections[detection_idx])
# For unmatched track, call mark_missed marked
for track_idx in unmatched_tracks:
self.tracks[track_idx].mark_missed()
# For unmatched detection, Set up new track And initialize , Put in track list
for detection_idx in unmatched_detections:
self._initiate_track(detections[detection_idx])
# Traverse to get the latest tracks list , What is kept is confirmed And unconfirmed State of tracks
# contain detection New track
self.tracks = [t for t in self.tracks if not t.is_deleted()]
# Update distance metric.
# Get all confirmed State of track id
active_targets = [t.track_id for t in self.tracks if t.is_confirmed()]
features, targets = [], []
for track in self.tracks:
if not track.is_confirmed():
continue
features += track.features
targets += [track.track_id for _ in track.features]
track.features = []
self.metric.partial_fit(
np.asarray(features), np.asarray(targets), active_targets)
# Firstly, the Mahalanobis distance based on appearance information is calculated tracks and detections The cost matrix of ,
# Then cascade matching and IOU matching , Finally, all matching pairs of the current frame are obtained 、 Unmatched tracks And unmatched detections
def _match(self, detections):
# track For all track
# dets by detections
# track_indices by
def gated_metric(tracks, dets, track_indices, detection_indices):
# Characteristics of all tested objects
features = np.array([dets[i].feature for i in detection_indices])
# Tracking object id
targets = np.array([tracks[i].track_id for i in track_indices])
# What is returned here is the cost matrix calculated using cosine distance
cost_matrix = self.metric.distance(features, targets)
# gate_cost_matrix, Calculate the Mahalanobis distance
cost_matrix = linear_assignment.gate_cost_matrix(
self.kf, cost_matrix, tracks, dets, track_indices,
detection_indices)
# Returns the cost matrix processed by cosine distance and Mahalanobis distance
return cost_matrix
# Split track set into confirmed and unconfirmed tracks.
confirmed_tracks = [
i for i, t in enumerate(self.tracks) if t.is_confirmed()]
unconfirmed_tracks = [
i for i, t in enumerate(self.tracks) if not t.is_confirmed()]
# Associate confirmed tracks using appearance features.
# Make a cascade match ( Special , about track It's empty time , Do not perform cascading matching )
matches_a, unmatched_tracks_a, unmatched_detections = \
linear_assignment.matching_cascade(
gated_metric, self.metric.matching_threshold, self.max_age,
self.tracks, detections, confirmed_tracks)
# Conduct iou Matching calculation
# Associate remaining tracks together with unconfirmed tracks using IOU.
# Only calculate time_since_update be equal to 1 Of track( Special , Don't do it for the first frame iou Handle )
iou_track_candidates = unconfirmed_tracks + [
k for k in unmatched_tracks_a if
self.tracks[k].time_since_update == 1]
# Screen out non-conforming products iou Matching track
unmatched_tracks_a = [
k for k in unmatched_tracks_a if
self.tracks[k].time_since_update != 1]
# Conduct iou matching
matches_b, unmatched_tracks_b, unmatched_detections = \
linear_assignment.min_cost_matching(
iou_matching.iou_cost, self.max_iou_distance, self.tracks,
detections, iou_track_candidates, unmatched_detections)
matches = matches_a + matches_b
unmatched_tracks = list(set(unmatched_tracks_a + unmatched_tracks_b))
return matches, unmatched_tracks, unmatched_detections
# Initialize the first frame
def _initiate_track(self, detection):
# By detection target detection Coordinates of ((center x, center y, aspect ratio, height) structure
# Mean vector (1×8 Vector , Initialize to [center_x,center_y,w/h,h,0,0,0,0] And covariance matrix (8*8 matrix , A diagonal matrix constructed according to the height of the target )
mean, covariance = self.kf.initiate(detection.to_xyah())
# Track() Itself is a class , Here, each new target is characterized by a class , Put in tracks list
self.tracks.append(Track(
mean, covariance, self._next_id, self.n_init, self.max_age,
detection.feature))
self._next_id += 1
边栏推荐
- 事件捕获方式和冒泡方式—它们的区别是什么?
- Boostrap
- 大疆livox定制的格式CustomMsg格式转换pointcloud2
- [latex format] there are subtitles side by side on the left and right of double columns and double pictures, and subtitles are side by side up and down
- 基于SSM医院预约管理系统
- What is the reason why the channel list is empty on the intelligent security video platform easycvr?
- 网易云信亮相 GIAC 全球互联网架构大会,解密新一代音视频架构在元宇宙场景的实践...
- MySql数据库
- vscode运行命令报错:标记“&&”不是此版本中的有效语句分隔符。
- Pytorch uses data_ Prefetcher improves data reading speed
猜你喜欢

Speech and language processing (3rd ed. draft) Chapter 2 - regular expression, text normalization, editing distance reading notes

Express receive request parameters

DNA modified near infrared two region GaAs quantum dots | GaAs DNA QDs | DNA modified GaAs quantum dots

硫化镉CdS量子点修饰脱氧核糖核酸DNA|CdS-DNA QDs|近红外CdS量子点偶联DNA规格信息
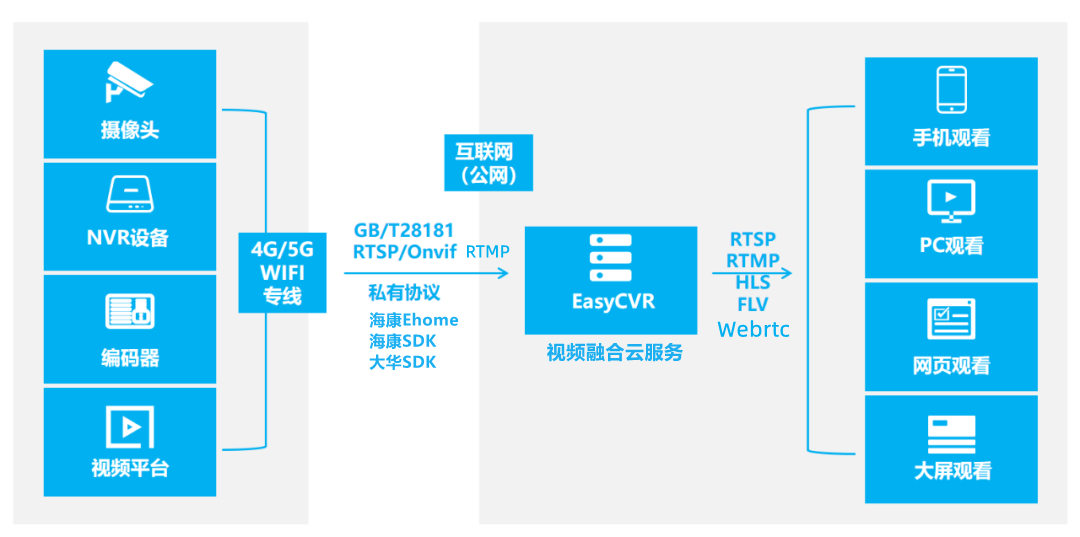
如何删除或替换EasyPlayer流媒体播放器的loading样式?
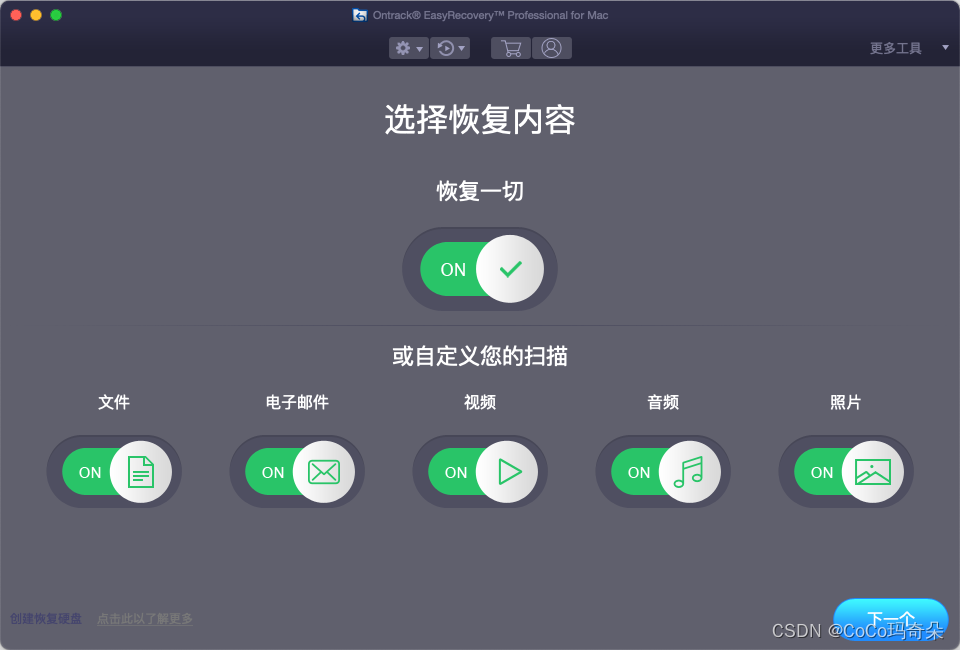
EasyRecovery14数据恢复软件官方功能简介

Future, futuretask and completable future are often asked in interviews

Record of pychart running jupyter notebook in virtual environment

O2O电商线上线下一体化模式分析
Introduction to the official functions of easyrecovery14 data recovery software
随机推荐
基于SSM音乐网站管理系统
Vscode connection remote server development
Express框架
Interpretation of deepsort source code (V)
Derivative, partial derivative and gradient
Do it yourself container
Dsgan degenerate network
MySQL的基本语句(1)—增删改查
聊聊大火的多模态
正则表达式
Linux Installation and uninstallation of MySQL
Redis operation of Linux Installation
Memo @restcontrolleradvice and exception interception class example
Px4 source code compilation to establish its own program module
Pymysql query result conversion JSON
基于SSM医院预约管理系统
大疆livox定制的格式CustomMsg格式转换pointcloud2
Day012 一维数组的应用
Problems related to compilation and training of Darknet yolov3 and Yolo fast using CUDA environment of rtx30 Series graphics card on win10 platform
Pytorch uses data_ Prefetcher improves data reading speed