当前位置:网站首页>Raki's notes on reading paper: soft gazetteers for low resource named entity recognition
Raki's notes on reading paper: soft gazetteers for low resource named entity recognition
2022-07-05 04:25:00 【Sleeping Raki】
Abstract & Introduction & Related Work
- Research tasks
Low resource named entity recognition - Existing methods and related work
- Will be based on discourse tags 、 Morphology and manually created entity list ( It is called place name index ) The integration of linguistic features into neural models will lead to Achieve better on English data NER
- Facing the challenge
- However, it is difficult to integrate the features of place name dictionaries directly into these models , Because the Toponymic dictionaries of these languages either have limited coverage , Or not at all . Due to the lack of annotators of available low resource languages , Expanding them takes time and money .
- Innovative ideas
- Introduced soft-gazetteers, A method of creating gazetteer features with continuous values based on ready-made data from high resource languages and large English knowledge bases
- The entity connection method is used
- The experimental conclusion
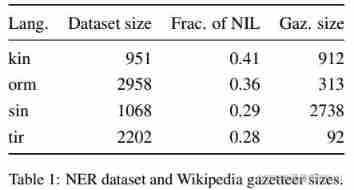
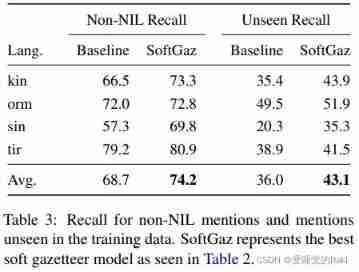
Our experiments have proved the effectiveness of our proposed soft place name dictionary feature , Among the four low resource languages , Average ratio baseline Improved 4 individual F1 spot . The four languages are : Kinyarwanda 、 Oromo 、 Sinhala and Tigrinya ( What kind of language ?)
Binary Gazetteer Features
Binary gazetteer features are used to indicate the corresponding n-gram Whether it appears in the gazetteer
Entity Linking
Entity link (EL) Is the name of the entity mention Rather than in a structured knowledge base (KB) Tasks associated with the corresponding entries in (Hachey wait forsomeone ,2013). for example , Entities to be mentioned " Mars " Link to Wikipedia entries . In most entity linking systems (Hachey wait forsomeone ,2013 year ;Sil wait forsomeone ,2018 year ), The first step is to screen out candidates KB entry , These entries are further processed by the entity disambiguation Algorithm . Candidate search method , Generally speaking , Also according to the input mention Score each candidate result
Soft Gazetteer Features
Creating gazetteers for low resource languages is difficult , We propose a list of soft lands , The value of comparing specific specified gazetteer features is 0 or 1, The soft land list is continuous , Its value is between 0 To 1 Between
For each of these span, We assume that there is an entity link extraction method that returns a series of candidate structured knowledge bases , And rank the candidate results 
Try different ways , Candidate list to generate feature vectors :
- Select only top1
- choose top3, Three eigenvectors
- about top3, Judgment and candidate types t Is it consistent
- Before calculation 30 Type count of candidates
- Calculate the difference between two consecutive scores


We try different combinations of these features by splicing their respective vectors . The connected vector passes through a vector with tanh Nonlinear fully connected neural network layer , And then for NER In the model
Named Entity Recognition Model
Adding an automatic encoder to reconstruct handmade features will lead to NER Performance improvement . The automatic encoder will BiLSTM As input to a with sigmoid Activate the full connection layer of the function , And reconstruct the features . This has forced BiLSTM Retain information from features . The cross entropy loss of feature reconstruction of soft place name dictionary is the goal of automatic encoder , L A E L_{AE} LAE
The loss of training is CRF And self encoder loss The synthesis of 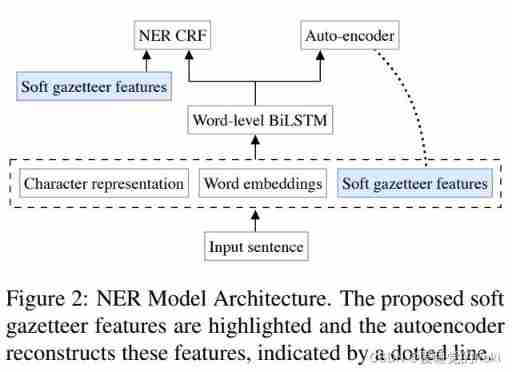
Experiments
Methods
Soft gazetteer methods
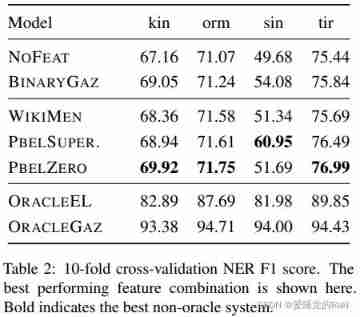
We tested different candidate retrieval methods designed for low resource languages . These methods are only trained with Wikipedia's small bilingual dictionary , Its scale is similar to that of the place name dictionary
- WIKIMEN:WikiMention Methods are used in several of the most advanced EL In the system , among , Links to bilingual Wikipedia are used to retrieve appropriate English KB The candidate
- Pivot-based-entity-linking: This method uses n-gram Neural embedding method (Wieting wait forsomeone ,2016) Encoding entity references at the character level , And calculate its relation with KB Similarity of items . We experimented with two variants , And follow Zhou wait forsomeone (2020) Super parameter selection .
1)PBELSUPERVISED: Train according to a small number of bilingual Wikipedia links in the target low resource language .
2)PBELZERO: In some high resource languages (“ Fulcrum ”) Training , And transfer to the target language in the way of zero starting point . The transfer language we use is Swahili for Kinyarwanda , Indonesian is used for Oromo , Hindi is used in Sinhala , And Amharic for Tigre
Oracles
As the upper limit of accuracy , We compare it with two powerful human systems .
- ORACLEEL: For the soft place name dictionary , We assume a perfect candidate search , If the content mentioned is not NIL, Always return the correct KB Items as primary candidates .
- ORACLEGAZ: We artificially increase by adding all named entities to the place name dictionary BINARYGAZ The capacity of . All named entities in our dataset .
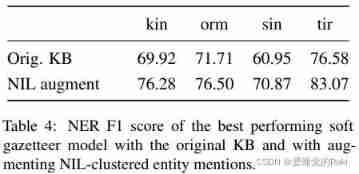
Conclusion
We propose a low resource NER How to create features , And it shows its effectiveness in four low resource languages . Possible future directions include the use of a combination of more complex feature designs and candidate retrieval methods
Remark
The model is very simple , This soft land listing method feels a little complicated (
Anyway, it's OK
边栏推荐
- 官宣!第三届云原生编程挑战赛正式启动!
- Machine learning -- neural network
- Threejs realizes sky box, panoramic scene, ground grass
- Threejs factory model 3DMAX model obj+mtl format, source file download
- How can CIOs use business analysis to build business value?
- Judge whether the stack order is reasonable according to the stack order
- Sword finger offer 07 Rebuild binary tree
- 机器学习 --- 神经网络
- web资源部署后navigator获取不到mediaDevices实例的解决方案(navigator.mediaDevices为undefined)
- 根据入栈顺序判断出栈顺序是否合理
猜你喜欢
Interview related high-frequency algorithm test site 3

Components in protective circuit
托管式服务网络:云原生时代的应用体系架构进化
小程序中实现文章的关注功能
Managed service network: application architecture evolution in the cloud native Era
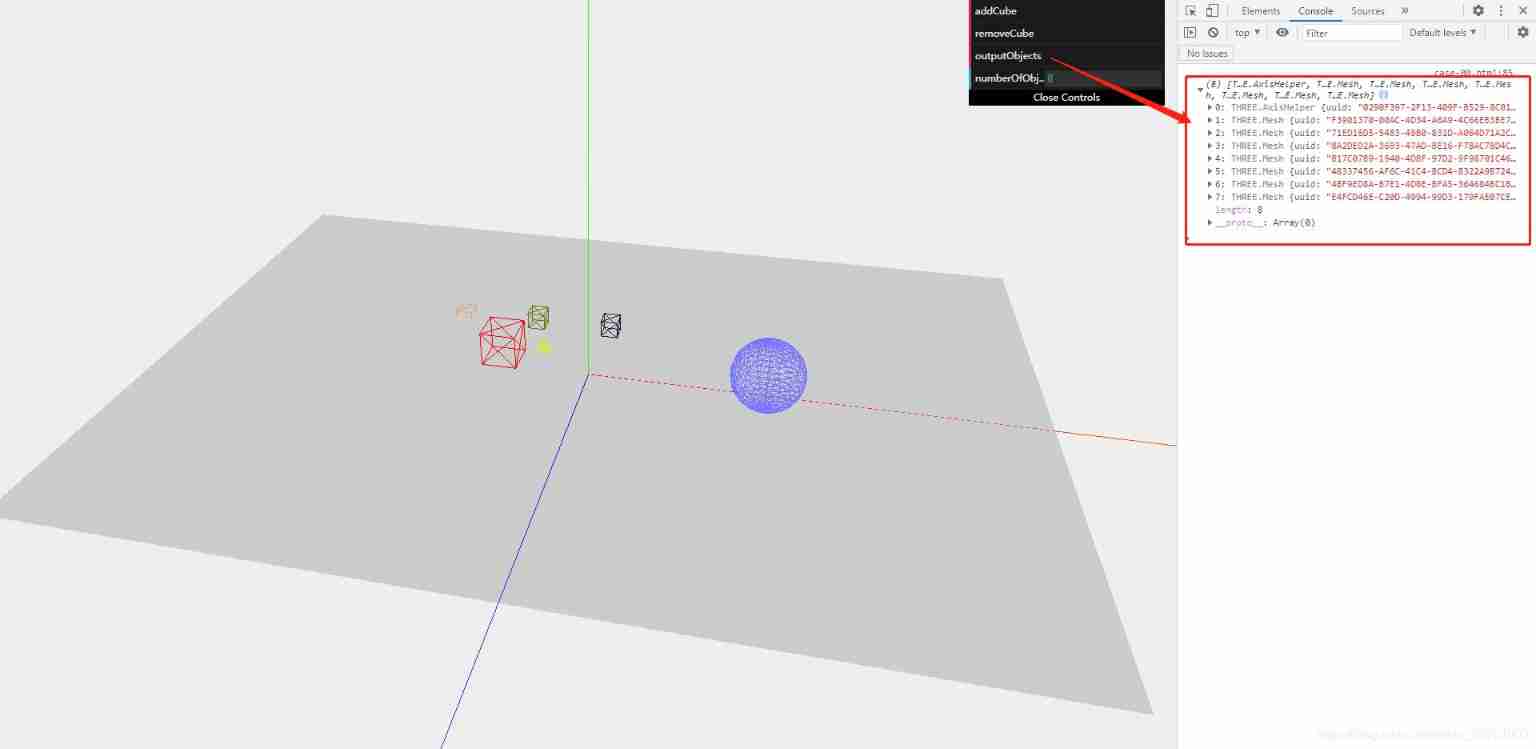
Use threejs to create geometry, dynamically add geometry, delete geometry, and add coordinate axes

美国5G Open RAN再遭重大挫败,抗衡中国5G技术的图谋已告失败
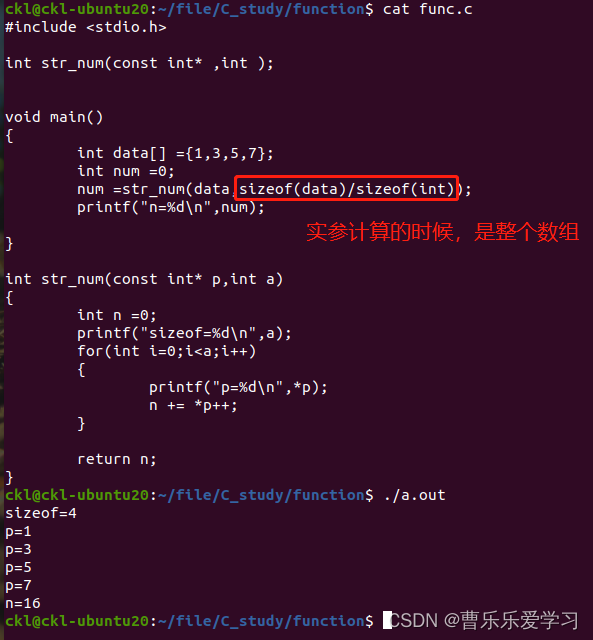
函數(易錯)
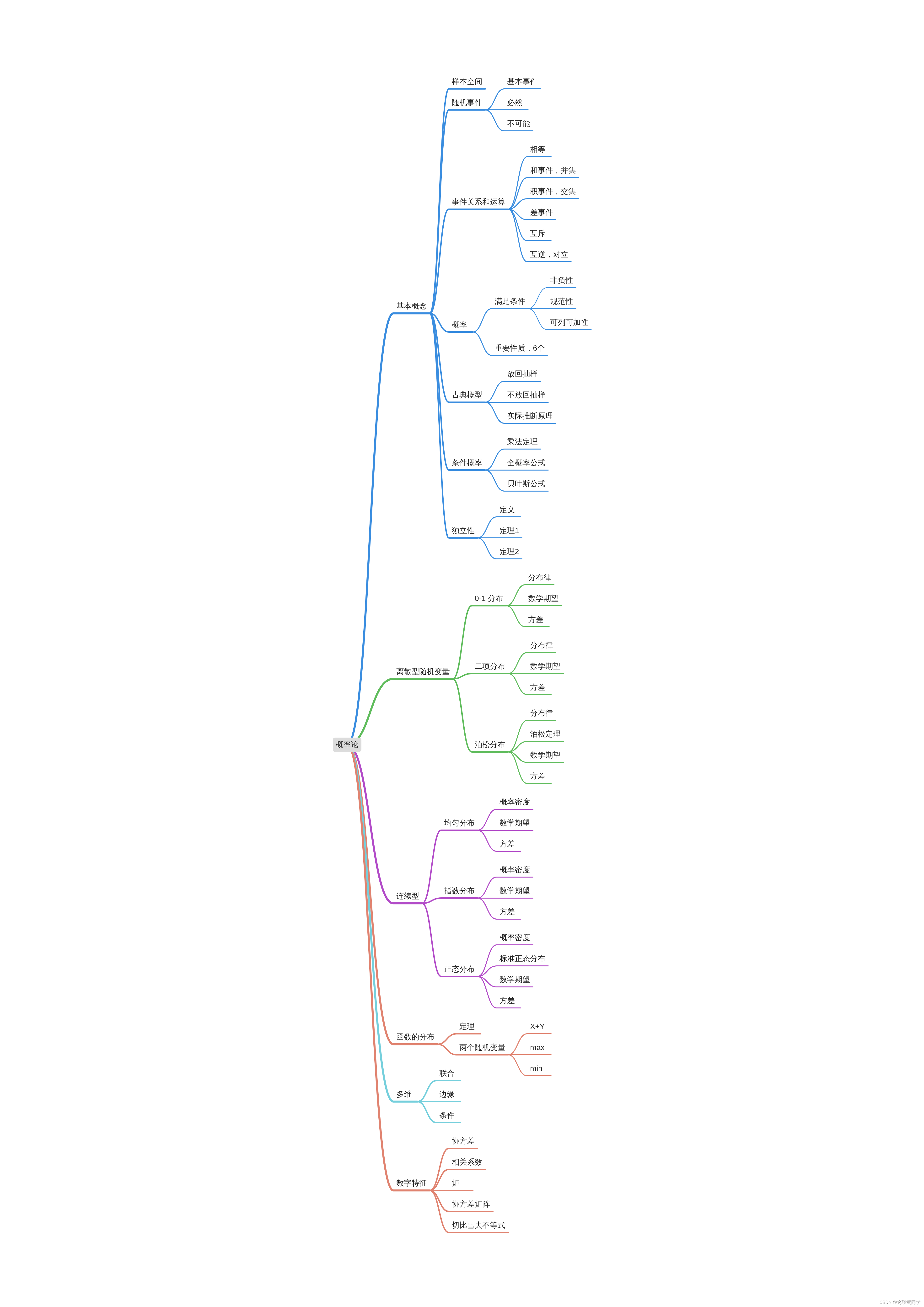
概率论与数理统计考试重点复习路线
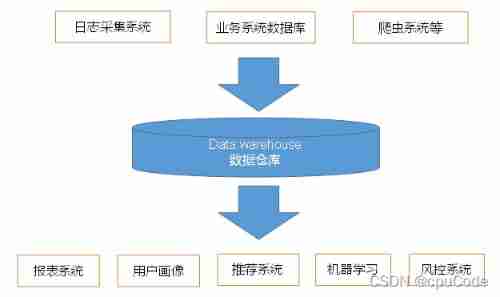
User behavior collection platform
随机推荐
About the project error reporting solution of mpaas Pb access mode adapting to 64 bit CPU architecture
小程序中实现文章的关注功能
包 类 包的作用域
函數(易錯)
3 minutes learn to create Google account and email detailed tutorial!
Use threejs to create geometry and add materials, lights, shadows, animations, and axes
Web开发人员应该养成的10个编程习惯
A application wakes up B should be a fast method
Seven join join queries of MySQL
User behavior collection platform
Threejs Internet of things, 3D visualization of farms (I)
WGS84 coordinate system, web Mercator, gcj02 coordinate system, bd09 coordinate system - brief introduction to common coordinate systems
You Li takes you to talk about C language 7 (define constants and macros)
假设检验——《概率论与数理统计》第八章学习笔记
指针函数(基础)
level17
Fonction (sujette aux erreurs)
Key review route of probability theory and mathematical statistics examination
A solution to the problem that variables cannot change dynamically when debugging in keil5
Possible stack order of stack order with length n