当前位置:网站首页>Let's see how to realize BP neural network in Matlab toolbox
Let's see how to realize BP neural network in Matlab toolbox
2022-07-07 01:30:00 【Old cake explanation BP neural network】
Catalog
One 、 Source code reproduction effect
3、 ... and 、 Analysis of the source of effect difference
Four 、 Comparison of the effects of different training methods
Original article , Reprint please indicate from 《 Lao Bing explains -BP neural network 》bp.bbbdata.com
If we directly use the gradient descent method to solve BP neural network ,
Often there is no matlab The effect of the toolbox is so good .
This problem has troubled the author for a long time ,

Then we might as well dig out the source code and have a look ,matlab How the toolbox is implemented BP Neural network ,
Why is there no toolbox for our self written training effect BP Neural network is good .
One 、 Source code reproduction effect
Pick out matlab Toolbox gradient drops traingd Algorithm source code , After sorting out the algorithm process ,
One obtained by writing code 2 Cryptic layer BP The weight of the neural network
Call the toolbox newff The weight obtained :
You can see , The two results are the same , It shows that you fully understand and reproduce the BP Neural network training logic .


Two 、 Training mainstream
BP The main process of neural network gradient descent method is as follows
First initialize the weight threshold ,
Then iterate the weight threshold with gradient ,
If the termination conditions are met, quit training
The termination condition is : The error has reached the requirement 、 The gradient is too small or reaches the maximum number
The code is as follows :
function [W,B] = traingdBPNet(X,y,hnn,goal,maxStep)
%------ Variable pre calculation and parameter setting -----------
lr = 0.01; % Learning rate
min_grad = 1.0e-5; % Minimum gradient
%--------- initialization WB-------------------
[W,B] = initWB(X,y,hnn); % initialization W,B
%--------- Start training --------------------
for t = 1:maxStep
% Calculate the current gradient
[py,layerVal] = predictBpNet(W,B,X); % Calculate the predicted value of the network
[E2,E] = calMSE(y,py); % Calculation error
[gW,gB] = calGrad(W,layerVal,E); % Calculate the gradient
%------- Check whether the exit conditions are met ----------
gradLen = calGradLen(gW,gB); % Calculate the gradient value
% If the error has reached the requirement , Or the gradient is too small , Then quit training
if E2 < goal || gradLen <=min_grad
break;
end
%---- Update weight threshold -----
for i = 1:size(W,2)-1
W{i,i+1} = W{i,i+1} + lr * gW{i,i+1};% Update gradient
B{i+1} = B{i+1} + lr * gB{i+1};% Update threshold
end
end
end( In the code reproduction here, we shield the normalization processing 、 Generalization verifies the general operation of these two algorithms )
3、 ... and 、 Analysis of the source of effect difference
Source of effect difference
There is no difference between the main process and the conventional algorithm tutorial ,
So why matlab The result will be better ,
The main reason is initialization ,
A lot of tutorials , Random initialization is recommended ,
But in fact ,matlab The tool box uses nguyen_Widrow Method to initialize
nguyen_Widrow Law
nguyen_Widrow The idea of method initialization is as follows :
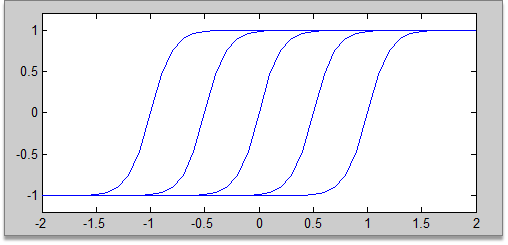
Take the single input network as an example , It initializes the network in the following form :
Its purpose is to make all hidden nodes evenly distributed in the range of input data .
The reason is , If BP Finally, every neuron of neural network is fully utilized ,
Then it should be more similar to the above distribution ( Full coverage of input range 、 Every neuron is fully utilized ),
Instead of randomly initializing and slowly adjusting , It's better to give such an initialization at the beginning .
The original text of this method is :
Derrick Nguyen and Bernard Widrow Of 《Improving the learning Speed of 2-Layer Neural Networks by Choosing Initial Values of the Adaptive Weights 》
Four 、 The effect of different training methods is different
Effect comparison
And the author uses traingd、traingda、trainlm Compare the effect ,
Find the same problem ,
traingd Training will not come out ,traingda Can train ,
and traingda Training will not come out ,trainlm Can train again .
That is, in the training effect
traingd< traingda < trainlm
that , If we directly use the gradient descent method written by ourselves ,
It is still far inferior to what we use matlab The tool box works well .
matlab Of BP The default neural network is trainlm Algorithm
A brief account of the cause
that traingda Why is it better than traingd Strong ,trainlm Why is it better than that traingda Strong ?
After source code analysis , Mainly traingda Adaptive learning rate is added in ,
and trainlm It uses the information of the second derivative , Make learning faster .
5、 ... and 、 Related articles
See :
《 rewrite traingd Code ( Gradient descent method )》
See :
This is it. matlab The algorithm logic of gradient descent method in neural network toolbox , It's so simple ~!
边栏推荐
猜你喜欢



随机推荐
树莓派/arm设备上安装火狐Firefox浏览器
Taro中添加小程序 “lazyCodeLoading“: “requiredComponents“,
JS reverse -- ob confusion and accelerated music that poked the [hornet's nest]
域分析工具BloodHound的使用说明
[JS] obtain the N days before and after the current time or the n months before and after the current time (hour, minute, second, year, month, day)
Receive user input, height BMI, BMI detection small business entry case
Meet in the middle
C language - array
Supersocket 1.6 creates a simple socket server with message length in the header
[signal and system]
负载均衡性能参数如何测评?
Google released a security update to fix 0 days that have been used in chrome
Transformation transformation operator
Transplant DAC chip mcp4725 to nuc980
Gnet: notes on the use of a lightweight and high-performance go network framework
[chip scheme design] pulse oximeter
hdu 4661 Message Passing(木DP&amp;组合数学)
字节P7专业级讲解:接口测试常用工具及测试方法,福利文
第三方跳转网站 出现 405 Method Not Allowed
让我们,从头到尾,通透网络I/O模型