当前位置:网站首页>Neon Optimization: an instruction optimization case of matrix transpose
Neon Optimization: an instruction optimization case of matrix transpose
2022-07-07 01:14:00 【To know】
NEON Optimize : Matrix transpose instruction optimization case
NEON Optimization series :
- NEON Optimize 1: Software performance optimization 、 How to reduce power consumption ?link
- NEON Optimize 2:ARM Summary of optimized high frequency instructions , link
- NEON Optimize 3: Matrix transpose instruction optimization case ,link
- NEON Optimize 4:floor/ceil Optimization case of function ,link
- NEON Optimize 5:log10 Optimization case of function ,link
- NEON Optimize 6: About cross access and reverse cross access ,link
- NEON Optimize 7: Performance optimization experience summary ,link
- NEON Optimize 8: Performance optimization FAQs QA,link
background
Transpose operation is often used in matrix operation , Here, the atomic matrix 4x4 The transpose NEON Summary of optimization cases .
original C The function is responsible for M[4][4] Transpose to MT[4][4], The effect is as follows :
M[4][4]- a1, b1, c1, d1
- a2, b2, c2, d2
- a3, b3, c3, d3
- a4, b4, c4, d4
M[4][4]^T- a1, a2, a3, a4
- b1, b2, b3, b4
- c1, c2, c3, c4
- d1, d2, d3, d4
Optimization idea
There are two parallel computing methods to transpose it .
- Method 1
- be used 4 Orders :vld4q_f32/vtrnq_f32/vuzpq_f32/vst4q_f32
- ld4q First, a batch of cross reads from memory into registers
- trnq Use the internal binary transpose function , Transpose some rows and columns
- uzpq Use the deinterleaving read-write function , Transpose some rows and columns
- Then use registers to assign values to different rows
- st4q Write the register result to memory
- Method 2
- Use the cross read-write relationship between memory and registers , Two instructions realize transpose , Don't flip around in the register
- ld1q Realize reading data to register by line
- st4q Cross read register values and write them to memory
Sample code
#include <stdio.h>
#include <stdint.h>
#include <arm_neon.h>
#define ROW_NUM 4
#define COL_NUM 4
int main(void)
{
// initial
float M[ROW_NUM][COL_NUM] = {
{
0, 1, 2, 3},
{
4, 5, 6, 7},
{
8, 9, 10, 11},
{
12, 13, 14, 15},
};
float MT[ROW_NUM][COL_NUM] = {
0};
// to do this:
// a1 b1 c1 d1 => a1 a2 a3 a4
// a2 b2 c2 d2 => b1 b2 b3 b4
// ...
// a4 b4 c4 d4 => d1 d2 d3 d4
// origin
int32_t i, j;
for (i = 0; i < ROW_NUM; i++) {
for (j = 0; j < COL_NUM; j++) {
MT[j][i] = M[i][j];
}
}
printf("ver1:\n");
for (i = 0; i < ROW_NUM; i++) {
for (j = 0; j < COL_NUM; j++) {
printf("%f ", MT[i][j]);
MT[i][j] = 0.;
}
printf("\n");
}
// method1
float32x4x4_t vf32x4x4fTmpABCD = vld4q_f32(&M[0][0]); // vf32x4x4fTmpABCD in val[0]: a1 b1 c1 d1, val[1]: a2 b2 c2 d2
float32x4x2_t vf32x4x2fTmpABCD01 = vtrnq_f32(vf32x4x4fTmpABCD.val[0], vf32x4x4fTmpABCD.val[1]); // vf32x4x2fTmpABCD01 in val[0]: a1 a2 c1 c2, val[1]: b1 b2 d1 d2
float32x4x2_t vf32x4x2fTmpABCD23 = vtrnq_f32(vf32x4x4fTmpABCD.val[2], vf32x4x4fTmpABCD.val[3]);
float32x4x2_t vf32x4x2fTmpABCD02 = vuzpq_f32(vf32x4x2fTmpABCD01.val[0], vf32x4x2fTmpABCD23.val[0]); // row02, Group by line
float32x4x2_t vf32x4x2fTmpABCD13 = vuzpq_f32(vf32x4x2fTmpABCD01.val[1], vf32x4x2fTmpABCD23.val[1]); // row13, Group by line
vf32x4x2fTmpABCD02 = vtrnq_f32(vf32x4x2fTmpABCD02.val[0], vf32x4x2fTmpABCD02.val[1]);
vf32x4x2fTmpABCD13 = vtrnq_f32(vf32x4x2fTmpABCD13.val[0], vf32x4x2fTmpABCD13.val[1]);
vf32x4x4fTmpABCD.val[0] = vf32x4x2fTmpABCD02.val[0]; // a0 a1 a2 a3
vf32x4x4fTmpABCD.val[2] = vf32x4x2fTmpABCD02.val[1];
vf32x4x4fTmpABCD.val[1] = vf32x4x2fTmpABCD13.val[0];
vf32x4x4fTmpABCD.val[3] = vf32x4x2fTmpABCD13.val[1]; // d0 d1 d2 d3
vst4q_f32(&MT[0][0], vf32x4x4fTmpABCD);
printf("ver2:\n");
for (i = 0; i < ROW_NUM; i++) {
for (j = 0; j < COL_NUM; j++) {
printf("%f ", MT[i][j]);
MT[i][j] = 0.;
}
printf("\n");
}
// method2
float32x4x4_t vf32x4x4fTmp1ABCD;
vf32x4x4fTmp1ABCD.val[0] = vld1q_f32(&M[0][0]); // a1 b1 c1 d1
vf32x4x4fTmp1ABCD.val[1] = vld1q_f32(&M[1][0]);
vf32x4x4fTmp1ABCD.val[2] = vld1q_f32(&M[2][0]);
vf32x4x4fTmp1ABCD.val[3] = vld1q_f32(&M[3][0]); // a4 b4 c4 d4
vst4q_f32(&MT[0][0], vf32x4x4fTmp1ABCD); // Take advantage of the cross read and write feature , Put in MT Array
printf("ver3:\n");
for (i = 0; i < ROW_NUM; i++) {
for (j = 0; j < COL_NUM; j++) {
printf("%f ", MT[i][j]);
MT[i][j] = 0.;
}
printf("\n");
}
// Only transpose in register and do not output to memory
// float fTmpABCD4x4[4][4]; // Temporary transit array
// vst4q_f32(&fTmpABCD4x4[0][0], vf32x4x4fTmpABCD); // Suppose the data to be transposed is vf32x4x4fTmpABCD
// vf32x4x4fTmpABCD.val[0] = vld1q_f32(&fTmpABCD4x4[0][0]);
// vf32x4x4fTmpABCD.val[1] = vld1q_f32(&fTmpABCD4x4[1][0]);
// vf32x4x4fTmpABCD.val[2] = vld1q_f32(&fTmpABCD4x4[2][0]);
// vf32x4x4fTmpABCD.val[3] = vld1q_f32(&fTmpABCD4x4[3][0]); // Put the transpose result into the register
return 0;
}
At the end of the above code , With... That transposes only in registers demo, It can be used according to specific scenarios .
Summary
Method 1
Transpose in the register and output to the memory
Only operate in registers ,6 Orders , Add 4 Assignments
Method 2
- Directly realize the transpose function through the cross reading of memory and register , Command down to 3 strip .
- Cross reading between registers and memory ,5 Orders
All in all , Practice knows , Only operate the scene in the register , Law 1 better , It is more efficient than the read-write interaction between memory and registers , Even if there are oneortwo more instructions . When you need to output the results to memory , Law 2 better .
边栏推荐
- Segmenttree
- [C language] dynamic address book
- 第七篇,STM32串口通信编程
- [100 cases of JVM tuning practice] 04 - Method area tuning practice (Part 1)
- UI控件Telerik UI for WinForms新主题——VS2022启发式主题
- golang中的atomic,以及CAS操作
- 再聊聊我常用的15个数据源网站
- Explain in detail the matrix normalization function normalize() of OpenCV [norm or value range of the scoped matrix (normalization)], and attach norm_ Example code in the case of minmax
- 【JVM调优实战100例】05——方法区调优实战(下)
- ESP Arduino (IV) PWM waveform control output
猜你喜欢
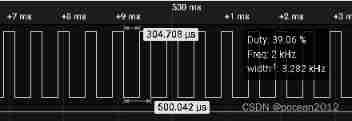
ESP Arduino (IV) PWM waveform control output
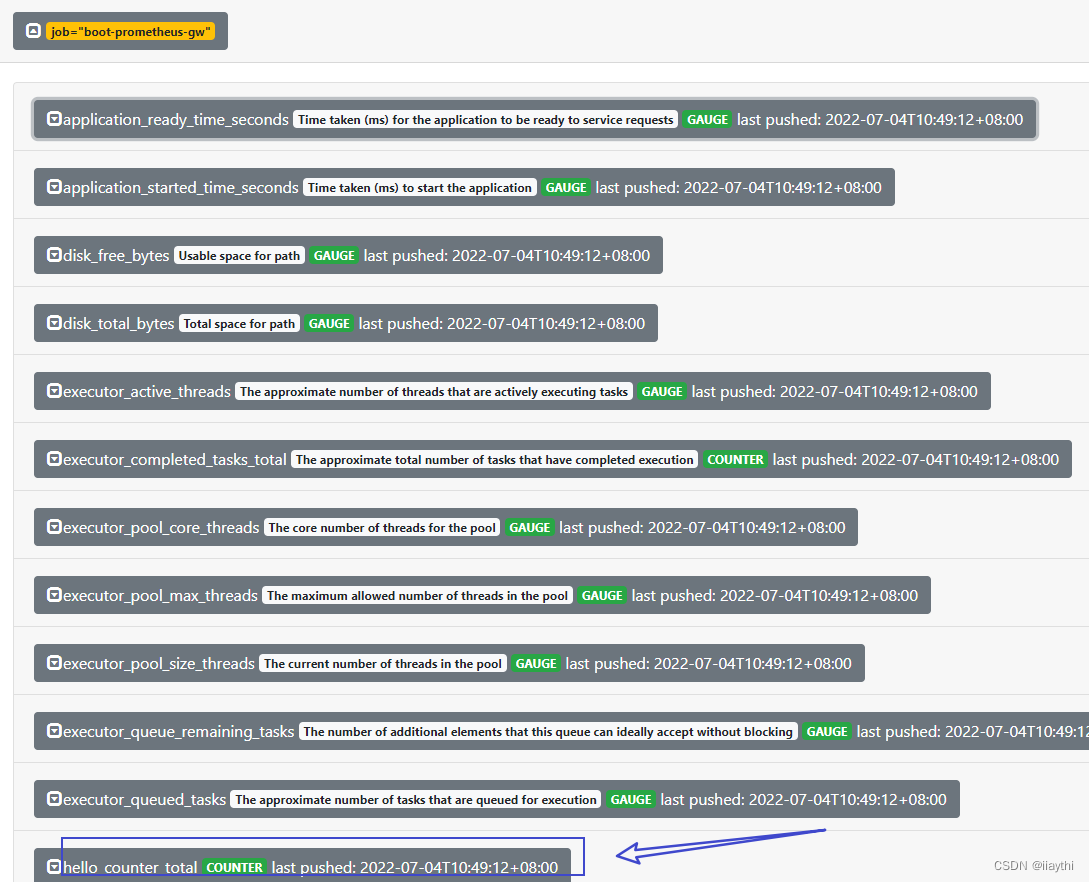
Boot - Prometheus push gateway use

Batch obtain the latitude coordinates of all administrative regions in China (to the county level)
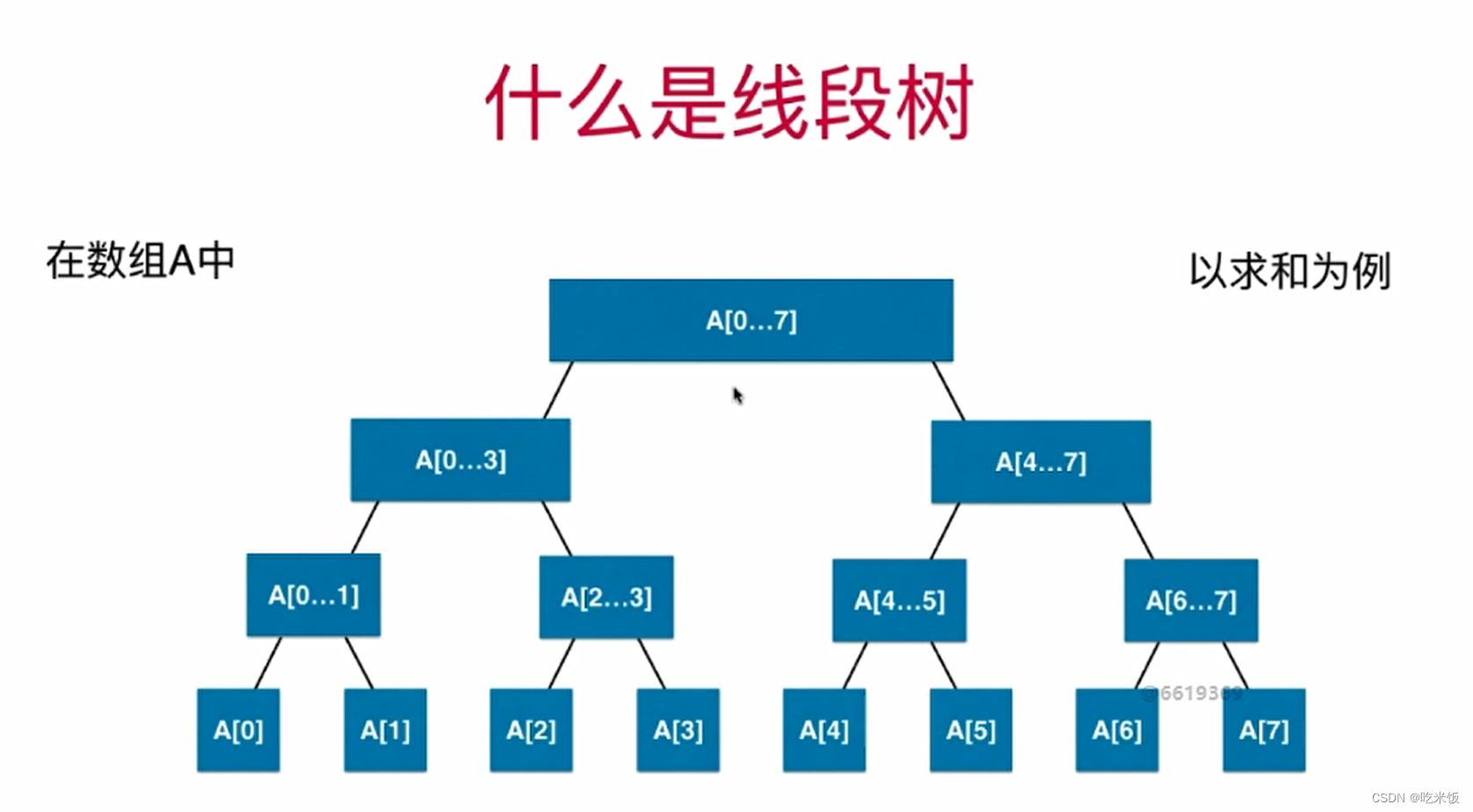
Segmenttree
![[100 cases of JVM tuning practice] 04 - Method area tuning practice (Part 1)](/img/7a/bd03943c39d3f731afb51fe2e0f898.png)
[100 cases of JVM tuning practice] 04 - Method area tuning practice (Part 1)

Telerik UI 2022 R2 SP1 Retail-Not Crack
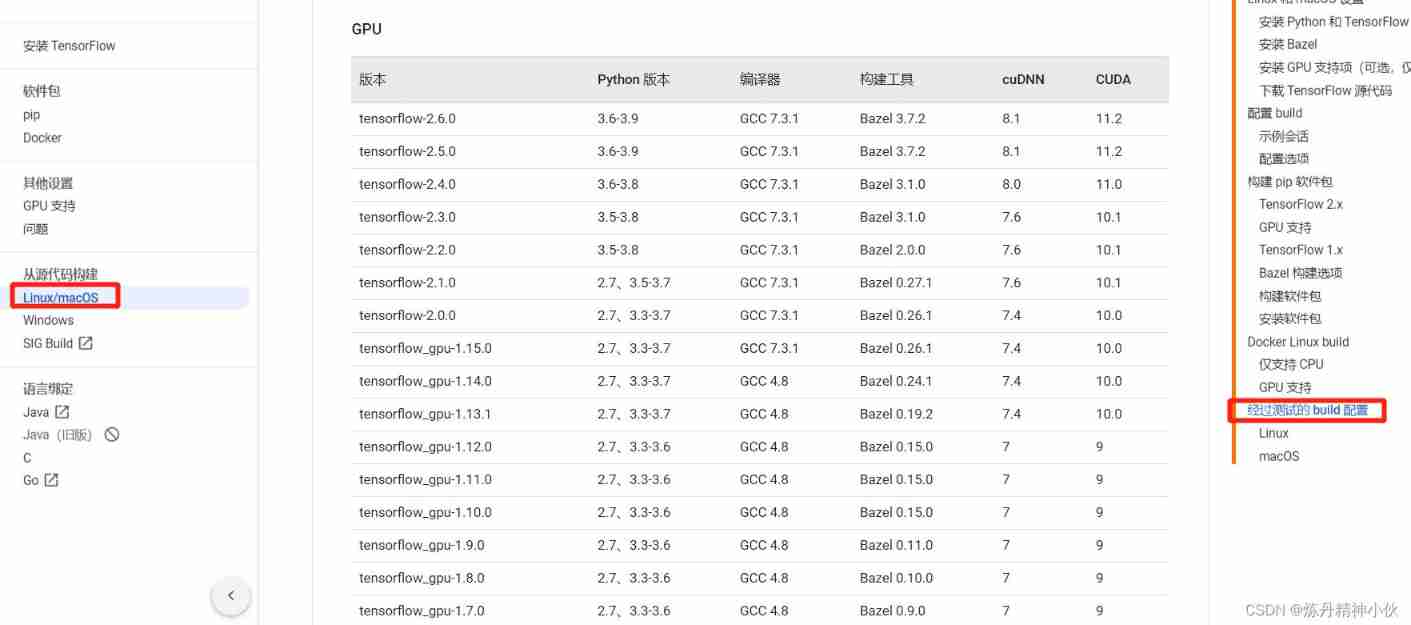
Tensorflow GPU installation

筑梦数字时代,城链科技战略峰会西安站顺利落幕

ARM裸板调试之JTAG调试体验
第六篇,STM32脉冲宽度调制(PWM)编程
随机推荐
SuperSocket 1.6 创建一个简易的报文长度在头部的Socket服务器
Zabbix 5.0:通过LLD方式自动化监控阿里云RDS
《安富莱嵌入式周报》第272期:2022.06.27--2022.07.03
golang中的atomic,以及CAS操作
「笔记」折半搜索(Meet in the Middle)
第五篇,STM32系统定时器和通用定时器编程
【批處理DOS-CMD命令-匯總和小結】-字符串搜索、查找、篩選命令(find、findstr),Find和findstr的區別和辨析
boot - prometheus-push gateway 使用
windows安装mysql8(5分钟)
线段树(SegmentTree)
[batch dos-cmd command - summary and summary] - view or modify file attributes (attrib), view and modify file association types (Assoc, ftype)
阿里云中mysql数据库被攻击了,最终数据找回来了
Link sharing of STM32 development materials
随时随地查看远程试验数据与记录——IPEhub2与IPEmotion APP
力扣1037. 有效的回旋镖
Address information parsing in one line of code
【JVM调优实战100例】05——方法区调优实战(下)
界面控件DevExpress WinForms皮肤编辑器的这个补丁,你了解了吗?
Atomic in golang and CAS operations
gnet: 一个轻量级且高性能的 Go 网络框架 使用笔记