当前位置:网站首页>A brief history of deep learning (I)
A brief history of deep learning (I)
2022-07-07 00:52:00 【Lao Qi】
A brief history of deep learning ( One )
This paper briefly describes the development process of deep learning , This is the first part .
1958 year : The rise of perceptron
1958 year ,Frank Rosenblatt A perceptron is proposed ( notes : Some materials believe that 1957 Put forward in , This article takes Frank Rosenblatt The article 《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》 The time of publication shall prevail ), This is a very simple machine , Later, it became the core and origin of today's intelligent machine . Perceptron is a very simple binary classifier , It can determine whether the input image belongs to a given category . To achieve this , It uses the unit step function as the activation function .
* Unit step function (step function), Also known as Huviside step function (Heaviside step function), Defined as :
For perceptron , If the input value is greater than 0 , The output value is 1 ; conversely , If the input value is less than 0 , The output value is 0 . This is the algorithm of perceptron .
perceptron
Frank It's not just an algorithm , He also built a real algorithm machine , This hardware device is named Mark I. This is a pure electronic device , It has 400 It consists of radio and television detectors , Use potentiometer to realize weight , The weight update in the back propagation is completed by the motor .
Mark I perceptron , The picture is from the National Museum of history
Just as we can see a lot about neural networks in the news media nowadays , At that time, perceptron was also a hot topic .《 The New York times 》 Reported ,“ The Navy hopes that computers can breed walkable 、 Will talk 、 Can read and write 、 It can also copy itself and have self-awareness ”. Even today , The machines we make are still learning to walk 、 speak 、 see 、 Write and so on , and “ consciousness ” There is still debate .Mark I Our goal is only to recognize images , At the time , It can only recognize two kinds of images . After a while , People realize that , More layers must be added ( The perceptron is a layer of neural network ) Only then can the network have the ability to learn complex functions . This produces a multi-layer perceptron (MLPs).
1982~1986 year : Cyclic neural network (RNNs)
A few years after multilayer perceptron solved the problem of image recognition , People began to think about how to model sequential data , For example, text . Cyclic neural network is a kind of neural network used to process sequence data , With the previous multi-layer perceptron (MLP ) The feedforward networks represented by are different , Cyclic neural network (RNNs) There is an internal feedback loop , This helps to remember the information state of each step .
Feedforward networks vs Cyclic neural network
although RNN stay 1982 To 1986 It has been proposed between , But because it has short-term memory problems , Unable to process long input sequences , Because it has not been paid attention , Know that the long-term and short-term memory network appeared later .
1998:LeNet-5: The first convolutional neural network
LeNet-5 It is one of the earliest convolutional neural network frameworks .1998 year ,LeNet-5 For text recognition .LeNet-5 from 3 Part of it is made up of :
- 2 Convolution layers ,
- 2 Sub sampling layer or pooling layer ,
- 3 All connection layers .
There is no activation function in the convolution layer .
As I said before ,LeNet-5 It has been put into commercial application . Here is LeNet-5 The architecture of .
LeNet-5 It was really influential at that time , However , until 20 Years later, it attracted attention ! Not just it , The same is true of the whole convolution network .LeNet-5 The development of is inseparable from the early research results , Such as : One of the earliest 《 Convolutional neural networks 》(Fukushima),《 Back propagation 》(Hinton Published in 1986 year ) and 《 Back propagation is used to recognize handwritten postal codes 》(LeCun Published in 1989 year ).
1998: Long and short term memory (LSTM)
Due to the problem of gradient instability , A simple recurrent neural network (RNN) Cannot handle long sequences , Long and short term memory (LSTM) It can be used to deal with long sequences RNN edition .LSTM It is basically an extreme RNN , Its uniqueness in design lies in the introduction of “ door ”, adopt “ door ” Control the information of each step .
- “ Input gate ” Identify the input sequence ;
- “ Oblivion gate ” Remove all irrelevant information in the input sequence , And store relevant information in long-term memory ;
- “ Update door ” Change the state of neurons ;
- “ Output gate ” Controls the information sent to the next cycle .
LSTM framework . The picture is from MIT 6.S191 Introduction to deep learning
LSTM Good at processing sequences , Make it commonly used in text classification 、 Sentiment analysis 、 speech recognition 、 Image title generation, machine translation and other related sequence businesses .LSTM Powerful , But its computational cost is high . So ,2014 Gate recursive unit was proposed in (GRU), To solve this problem . And LSTM comparison ,GRU Has fewer parameters , And it's also effective .
2012:ImageNet Challenge , The rise of convolutional neural networks
Talk about the history of neural networks and deep learning , It is almost impossible to avoid ImageNet Large scale visual recognition challenges (ImageNet Large Scale Visual Recognition Challenge, abbreviation :ILSVRC) and AlexNet.ILSVRC The only goal of is to evaluate the image classification and target classification ability of the framework based on massive data sets , Many new 、 A powerful and interesting framework was created , Meet and briefly review the process .
- The challenge begins with 2010 year , but 2012 The situation changed in , at that time AlexNet With 15.3% The error rate of ranked top five in the challenge , This error rate is almost half that of the previous winners .AlexNet Include 5 Convolution layers , Then comes the maximum pooling layer , And finally 3 A full connection layer and a softmax Classifier layer .AlexNet It is considered that the deep convolution neural network can deal with the task of visual recognition well . But at that time , The research has not been more in-depth !
- Over the next few years , The convolutional neural network framework becomes larger and larger , The effect is getting better and better . for example , Have 19 Layer of VGG With 7.3% The error rate of won the challenge .
- GoogLeNet Further improvement , Reduce errors to 6.7% .
- 2015 year ,ResNet Reduce the error rate to 3.6%, And show that : Through residual connection , It can train deeper Networks ( exceed 100 layer ), This was impossible at that time . People increasingly find : The deeper the network , The better the result. . This has led to the emergence of other new frameworks , Such as ResNeXt、Inception-ResNet、DenseNet、Xception, wait . Reference material [2] Introduced more about the framework , Please refer to .
ImageNet Challenge . The picture is taken from CS231n.
2014: Deep generation network
The generation network is used to generate or synthesize new data samples from the training set data , Such as images and music . There are many types of generative Networks , But the most popular thing is GANs( Generative antagonistic network ), It is from Ian Goodfellow stay 2014 Created in 2000 .GANs It is mainly composed of a generation network and a discrimination network . The generated network randomly samples from the potential space as input , Its output results try to imitate the real samples in the training set . The input of the discriminant network is the real sample or the output of the generated network , The purpose is to distinguish the output of the generated network from the real sample as much as possible , The generation network should cheat and judge the network as much as possible . The two networks confront each other , Constantly adjust the parameters . Every time you train , The output of the generated network is closer and closer to the real sample , The final goal is that the discriminating network cannot judge whether the output result of the generated network is true .
GANs It is one of the hottest things in the deep learning community , This community is famous for generating unreal images and deep falsification . In resources [3] in , You can learn about GAN More knowledge of .
Generative antagonistic network (GANs)
GANs It is a framework for generating models , Other popular frameworks are : Variational automatic encoder (VAE)、 Automatic encoder and diffusion model .
2017:Transformers and Attention
* There is no right here Transformer and Attention Translate , Part of the reason lies in references [4] As described in , Another reason is lack of talent and learning , Facing different translations of Chinese materials , I don't know how to choose , I don't know which is right or wrong . so , Simply lazy . ”
2017 year ,ImageNet The challenge is over , A new convolutional neural network framework has also emerged , People engaged in computer vision are very satisfied with the current achievements . before , If you want to classify images 、 object detection 、 Image segmentation and so on , It's more troublesome , Now it's very different , Not only is it easy to operate , And it works . People can use GANs Generate realistic images .
It seems that natural language processing (NLP) Behind the CV 了 , There will be big news soon . A purely based on Attention A new neural network framework , Give Way NLP Set off waves again . A few years later ,Attention Mechanisms also occupy cities and territories in other fields , The most obvious is CV . This is based on Attention The framework of is called transformer . Reference material [5] It's a simple introduction , Please refer to . The following figure illustrates Transformer Basic structure .
Attention Is All You Need.
Transformer It has completely changed NLP, At present, it is completely changing the field of computer vision . stay NLP in ,Transformer It has been used in machine translation 、 Text in this paper, 、 speech recognition 、 Text completion 、 Document search, etc …… You can 《Attention is All You Need》^{[6]} This paper is about transformer For more information .
边栏推荐
- 学习使用代码生成美观的接口文档!!!
- Policy Gradient Methods
- VTK volume rendering program design of 3D scanned volume data
- Equals() and hashcode()
- 深度学习之环境配置 jupyter notebook
- @TableId can‘t more than one in Class: “com.example.CloseContactSearcher.entity.Activity“.
- Three methods to realize JS asynchronous loading
- 37 pages Digital Village revitalization intelligent agriculture Comprehensive Planning and Construction Scheme
- Configuring the stub area of OSPF for Huawei devices
- C9 colleges and universities, doctoral students make a statement of nature!
猜你喜欢
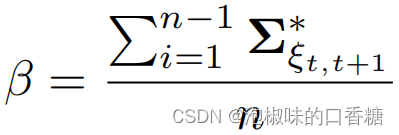
Attention SLAM:一种从人类注意中学习的视觉单目SLAM

The difference between redirectto and navigateto in uniapp
Win10 startup error, press F9 to enter how to repair?

【软件逆向-求解flag】内存获取、逆变换操作、线性变换、约束求解

C9 colleges and universities, doctoral students make a statement of nature!

JWT signature does not match locally computed signature. JWT validity cannot be asserted and should
How to judge whether an element in an array contains all attribute values of an object
C9高校,博士生一作发Nature!
St table

Equals() and hashcode()
随机推荐
C9 colleges and universities, doctoral students make a statement of nature!
Zabbix 5.0:通过LLD方式自动化监控阿里云RDS
Learning notes 5: ram and ROM
Advantages and disadvantages of code cloning
Chapter II proxy and cookies of urllib Library
St table
ActiveReportsJS 3.1中文版|||ActiveReportsJS 3.1英文版
@TableId can‘t more than one in Class: “com.example.CloseContactSearcher.entity.Activity“.
ZYNQ移植uCOSIII
Explain in detail the implementation of call, apply and bind in JS (source code implementation)
第六篇,STM32脉冲宽度调制(PWM)编程
C9高校,博士生一作发Nature!
深度学习之数据处理
深度学习之线性代数
【JokerのZYNQ7020】AXI_ EMC。
Common shortcuts to idea
深入探索编译插桩技术(四、ASM 探秘)
Dr selection of OSPF configuration for Huawei devices
build. How to configure the dependent version number in the gradle file
学习使用代码生成美观的接口文档!!!