当前位置:网站首页>Atomic in golang and CAS operations
Atomic in golang and CAS operations
2022-07-07 01:08:00 【raoxiaoya】
CAS No lock algorithm
To realize no lock (lock-free) There are many ways to implement the non blocking algorithm of , among CAS( Comparison and exchange ,Compare and swap) It's a well-known unlocked algorithm .CAS yes CPU Instructions , In most processor architectures , Include IA32、Space Are used in CAS Instructions ,CAS It's optimistic lock technology , When multiple threads are trying to use CAS When updating the same variable at the same time , Only one of the threads can update the value of the variable , All other threads fail , Failed threads are not suspended , They were told they had lost the competition , And try again .
CAS stay golang The implementation of the
for {
if atomic.CompareAndSwapInt64(&data, old, new) {
return new
}
}
CompareAndSwap Will compare first , If data The value is equal to the old, Then it will perform the replacement operation and return true, If not equal to , It means that it has been operated by other threads, and then it returns false, So it doesn't always succeed , Especially in the case of large concurrency , So use for Circulation comes from rotation . When there are few opportunities for synchronization conflicts , This assumption can lead to a large performance improvement .
Commonly used i++ operation , The process is to read from memory i, Then add 1, Then assign it to memory , Obviously, this process is not atomic , We can use CAS To realize atomization self increment operation .
func AddInt64(addr *int64, inc int64) int64 {
for {
old := *addr
if atomic.CompareAndSwapInt64(addr, old, old+inc) {
return old
}
}
}
therefore , be based on CAS, We can compare and assign values on a memory address first , It guarantees atomicity .
atomic It is generally implemented by assembly language , Such as file src/runtime/internal/atomic/atomic_386.s
CAS Instructions
got it CAS What does it mean after , The next step is to explore CAS Implementation principle of , as well as CAS Of Compare + assignment How the process is atomistic .
CAS Its atomicity is caused by CPU Instructions to achieve , I didn't find the specific code , The following is the online code .
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line // so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
The program will determine whether it is based on the type of current processor cmpxchg Instructions add to lock Prefix . If the program is running on multiprocessors , for cmpxchg Instructions add lock Prefix (lock cmpxchg). conversely , If the program is running on a single processor , Just omit lock Prefix ( The single processor itself maintains the order consistency within the single processor , Unwanted lock Prefix provides memory barrier effect ).
intel Right lock The prefix is described as follows
- Make sure that the memory is read - Change - Write The operation atom executes . stay Pentium And Pentium In the previous processor , with lock Prefixed instructions lock the bus during execution , Make other processors temporarily unable to access memory through the bus . Obviously , It's going to be expensive . from Pentium 4,Intel Xeon And P6 Processor start ,intel In the original bus lock on the basis of a very meaningful optimization : If you want to access the area of memory (area of memory) stay lock The prefix instruction has been locked in the processor's internal cache during execution ( That is, the cache line containing the memory area is currently in exclusive or modified state ), And the memory area is completely contained in a single cache line (cache line) in , Then the processor will execute the instruction directly . Because the cache line will be locked during the execution of the instruction , Other processors can't read / The area of memory to be accessed by this instruction , Therefore, the atomicity of instruction execution can be guaranteed . This operation is called cache locking (cache locking), Cache locking will be greatly reduced lock Prefix instruction execution cost , But when there is a high level of competition between multiprocessors or when the memory address of instruction access is not aligned , It will still lock the bus .
- Prevents the instruction from being reordered with previous and subsequent read and write instructions .
- Flush all data in write buffer to memory .
About CPU The locks are as follows 2 Kind of
1. Use bus lock to ensure atomicity
The first mechanism is to guarantee atomicity through bus locks . If multiple processors read and rewrite shared variables at the same time (i++ It's the classic read rewrite operation ) operation , Then the shared variables will be operated by multiple processors at the same time , So the read rewrite operation is not atomic , After the operation, the value of the shared variable will be inconsistent with the expected value . The reason is that it is possible for multiple processors to read variables from their respective caches at the same time i, Add respectively 1 operation , And then write them into the system memory . So you want to make sure that the operation of reading and rewriting shared variables is atomic , You have to make sure that CPU1 When reading and rewriting shared variables ,CPU2 Cannot operate the cache that caches the memory address of the shared variable .
Processor uses bus lock to solve this problem . The so-called bus lock is to use one provided by the processor LOCK# The signal , When a processor outputs this signal on the bus , Requests from other processors will be blocked , Then the processor can use shared memory exclusively .
2. Use cache lock to guarantee atomicity
The second mechanism is to guarantee atomicity through cache locking . At the same time, we just need to ensure that the operation on a memory address is atomic , But the bus is locked CPU Communication with memory is locked , This makes the locking period , Other processors cannot manipulate data from other memory addresses , So the cost of bus locking is high , Recent processors use cache locking instead of bus locking to optimize in some cases .
Frequently used memory is cached in the memory of the processor L1,L2 and L3 In the cache , Atomic operations can then be performed directly in the processor's internal cache , There is no need to declare a bus lock , In the Pentium 6 And recent processors can use “ Cache lock ” To achieve complex atomicity in a different way . So-called “ Cache lock ” If the cache is in the processor cache line, the memory area is in the LOCK Locked during operation , When it performs a lock operation to write back memory , The processor doesn't say on the bus LOCK# The signal , Instead, change the internal memory address , And allow its cache consistency mechanism to ensure the atomicity of the operation , Because the cache consistency mechanism prevents simultaneous modification of memory area data cached by more than two processors , When other processors write back the data of the locked cache line, the cache line will be invalid .
But there are two cases where the processor does not use cache locking . The first is : When the operation data cannot be cached inside the processor , Or operate data across multiple cache rows (cache line), Then the processor will call the bus lock . The second situation is : Some processors do not support cache locking . about Inter486 And Pentium processors , Even if the locked memory area is in the cache line of the processor, the bus lock will be called .
The above two mechanisms can be realized through Inter Processors provide a lot of LOCK Prefix instructions to achieve . For example, bit test and modify instructions BTS,BTR,BTC, Exchange instructions XADD,CMPXCHG And other operands and logic instructions , such as ADD( Add ),OR( or ) etc. , The memory area operated by these instructions will be locked , So that other processors can't access it at the same time .
lock (lock) The price of
Locks are the easiest way to do concurrency , Of course, the cost is also the highest . When locking in kernel mode, the operating system needs a context switch , Lock 、 Releasing lock will lead to more context switching and scheduling delay , The thread waiting for the lock is suspended until the lock is released . In context switching ,cpu The previously cached instructions and data will be invalidated , Great loss of performance . The operating system judges the multithreaded lock like two sisters arguing over a toy , Then the operating system is the parent who can decide who can get the toy , This is very slow . User mode locking avoids these problems , But in fact, they are only effective when there is no real competition .
CAS shortcoming
1、 CAS Although very efficient to solve the atomic operation , however CAS There are still three major problems .
ABA problem . because CAS It is necessary to check whether there is any change in the lower value when operating the value , Update if nothing changes , But if a value turns out to be A, Turned into B, It's changed again. A, So use CAS Check that its value has not changed , But it actually changed .ABA The solution to the problem is to use version number . Append the version number to the variable , Each time the variable is updated, add one to the version number , that A-B-A Will become 1A-2B-3A.
The cycle time is long and the cost is high . The spin CAS If it doesn't work for a long time , Will give CPU It's very expensive to execute . If JVM It can support pause The efficiency of instruction will be improved ,pause Instructions have two functions , First, it can delay pipeline execution (de-pipeline), send CPU It will not consume too much execution resources , The delay depends on the implementation version , On some processors, the latency is zero . Second, it can avoid memory sequence conflict when exiting the loop (memory order violation) And cause CPU The assembly line is emptied (CPU pipeline flush), So as to improve CPU Efficiency of execution .
Only one atomic operation of shared variables can be guaranteed . When operating on a shared variable , We can use cycles CAS The way to guarantee atomic operation , But when operating on multiple shared variables , loop CAS There is no guarantee of atomicity of operation , You can use the lock at this time , Or there's a clever way , It is to combine multiple shared variables into a shared variable to operate . For example, there are two shared variables i=2,j=a, Merge ij=2a, And then use CAS To operate ij.
2、 Compare the cost CPU resources , Even if there is no competition, I will do some idle work .
3、 It will increase the complexity of program testing , If you don't pay attention to it, there will be problems .
application
CAS The advantage of operation is , The concurrent safe value replacement operation can be completed without forming critical areas and creating mutexes .
This can greatly reduce the loss of program performance caused by synchronization .
Of course ,CAS Operation also has disadvantages . In the case that the value of the operation is changed frequently ,CAS The operation is not so easy to succeed .
1. Increase or decrease
Used for atomic operations of increasing or decreasing ( Hereinafter referred to as atomic enrichment / Reduction of operating ) The function names of are all marked with “Add” The prefix , Followed by the name of the specific type targeted .
however , because atomic.AddUint32 Functions and atomic.AddUint64 The type of the second parameter of the function is uint32 and uint64, Therefore, we cannot reduce the operated value by passing a negative value .atomic.AddUint32(&uint32, ^uint32(-NN-1)) among NN Represents a negative integer .
2. Compare and exchange func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
The value of the first parameter should be a pointer to the value being manipulated . The type of this value is *int32. The types of the last two parameters are int32 type . Their values should represent the old value and the new value of the operated value respectively .CompareAndSwapInt32 After being called, the function will first judge the parameters addr Points to the manipulated values and parameters old Is the value of equal . Only if this judgment has a positive result , This function will use parameters new Replace the old value with the new value . otherwise , Later replacement operations will be ignored .
3. load v := atomic.LoadInt32(&value)
Accept one *int32 Pointer value of type , And will return the value that the pointer value points to . With “ Atomic ” This adjective means , Read it here value At the same time , Any in the current computer CPU There will be no other read or write operations for this value . Such constraints are supported by the underlying hardware .
4. Storage
In the process of storing a value in atoms , whatever CPU Will not read or write to the same value . If we change all writes to this value to atomic operations , Then there will be no case that the read operation for this value is carried out concurrently and half of the value is modified . Atomic value storage operations always succeed , Because it doesn't care what the old value of the operated value is . function atomic.StoreInt32 Will accept two parameters . The first parameter is of type *int 32 Type of , Its meaning is also a pointer to the operated value . The second parameter is int32 Type of , Its value should represent the new value to be stored . Other similar functions will also have similar parameter declaration lists .
5. In exchange for
And CAS Different operation , The atomic exchange operation does not care about the old value of the operated value . It will directly set the new value . But it does a little more than atomic loading . In exchange for , It returns the old value of the operated value . Such operation ratio CAS Fewer constraints on operations , At the same time, it is more powerful than atomic loading operation . With atomic.SwapInt32 Function as an example . It takes two arguments . The first parameter represents the memory address of the operated value *int32 Type values , The second parameter is used to represent the new value . Be careful , This function has a result value . This value is the old value replaced by the new value .atomic.SwapInt32 After function is called , The second parameter value will be placed on the memory address represented by the first parameter value ( That is, modify the operated value ), And return the previous value on the address as the result .
Replace with atomic operations mutex lock
The main reason is , Atomic operations are supported by underlying hardware , The lock is provided by the operating system API Realization . If we achieve the same function , The former is usually more efficient .
边栏推荐
- windows安装mysql8(5分钟)
- mysql: error while loading shared libraries: libtinfo.so.5: cannot open shared object file: No such
- [Niuke classic question 01] bit operation
- . Bytecode structure of class file
- Levels - UE5中的暴雨效果
- Deep understanding of distributed cache design
- gnet: 一个轻量级且高性能的 Go 网络框架 使用笔记
- 线段树(SegmentTree)
- Dell Notebook Periodic Flash Screen Fault
- SuperSocket 1.6 创建一个简易的报文长度在头部的Socket服务器
猜你喜欢

随时随地查看远程试验数据与记录——IPEhub2与IPEmotion APP

New feature of Oracle 19C: automatic DML redirection of ADG, enhanced read-write separation -- ADG_ REDIRECT_ DML
Windows installation mysql8 (5 minutes)

Installation and testing of pyflink
![【批处理DOS-CMD命令-汇总和小结】-跳转、循环、条件命令(goto、errorlevel、if、for[读取、切分、提取字符串]、)cmd命令错误汇总,cmd错误](/img/a5/41d4cbc070d421093323dc189a05cf.png)
【批处理DOS-CMD命令-汇总和小结】-跳转、循环、条件命令(goto、errorlevel、if、for[读取、切分、提取字符串]、)cmd命令错误汇总,cmd错误
Set (generic & list & Set & custom sort)
资产安全问题或制约加密行业发展 风控+合规成为平台破局关键
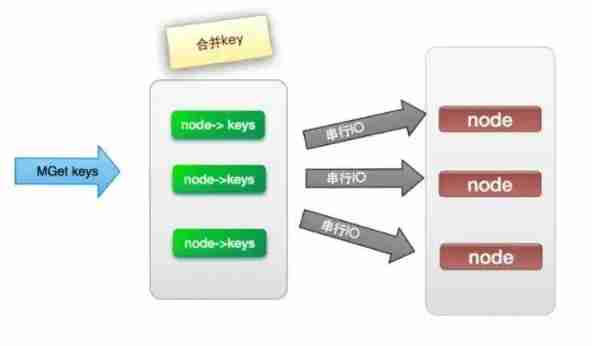
Deep understanding of distributed cache design

阿里云中mysql数据库被攻击了,最终数据找回来了

Equals() and hashcode()
随机推荐
腾讯云 WebShell 体验
There is an error in the paddehub application
How do novices get started and learn PostgreSQL?
Dr selection of OSPF configuration for Huawei devices
第四篇,STM32中断控制编程
【批處理DOS-CMD命令-匯總和小結】-字符串搜索、查找、篩選命令(find、findstr),Find和findstr的區別和辨析
筑梦数字时代,城链科技战略峰会西安站顺利落幕
Deep learning environment configuration jupyter notebook
from . cv2 import * ImportError: libGL. so. 1: cannot open shared object file: No such file or direc
第七篇,STM32串口通信编程
Chapter II proxy and cookies of urllib Library
pytorch之数据类型tensor
Meet the level 3 requirements of ISO 2.0 with the level B construction standard of computer room | hybrid cloud infrastructure
一行代码实现地址信息解析
Deep learning framework TF installation
建立自己的网站(17)
pyflink的安装和测试
阿里云中mysql数据库被攻击了,最终数据找回来了
Distributed cache
View remote test data and records anytime, anywhere -- ipehub2 and ipemotion app