当前位置:网站首页>并发优化总结
并发优化总结
2022-07-04 21:37:00 【51CTO】
涉及到 项目就只写基本了 有些东西无法详细描述就一笔概括了
并发模式: 反应器 主动器 异步完成标记 接收器-连接器
- 反应器 Reactor: 事件驱动应用可以多路分解---分配; 可以逆转控制流; 和好莱坞原则一样:“不要打电话给我们,我们会给你们打电话”;
- 缺点:不能同时支持大量客户和耗时长的客户请求;原因是 反应器在事件多路分解过程中 串行化处理了所有事件;
- 主动器Proactor:和被动响应的反应器模式不同, 主动器模式中客户请求和完成处理请求的程序通过一个异步操作处理; 移步操作完成后,
- 异步操作处理器和指定的主动器Procator组件 将完成事件的多路分解给相关程序,并分配这些程序的钩子方法。处理完一个事件后,就激活另一个异步操作请求
- 异步完成标记:使应用程序能对它在服务中调用异步操作而引起的响应进行有效地多路分解和处理,从而提高异步处理的效率,主要是对主动器模式中任务的多路分解的优化。
- 接收器-连接器:该模式经常和反应器模式结合使用,将网络化系统中同级服务的连接和协作初始化与随后进行的处理分开,该模式允许应用程序配置它们的连接拓扑结构,进行这种配置不依赖于应用程序所提供的服务
Reactor: 如何进行事件的多路分解和分配给相应的服务程序、注意事项有哪些、存在哪些问题?
- 为了提高可扩展性和响应性能,应用程序不应该被单个指示事件所阻塞,否则会降低吞吐响应
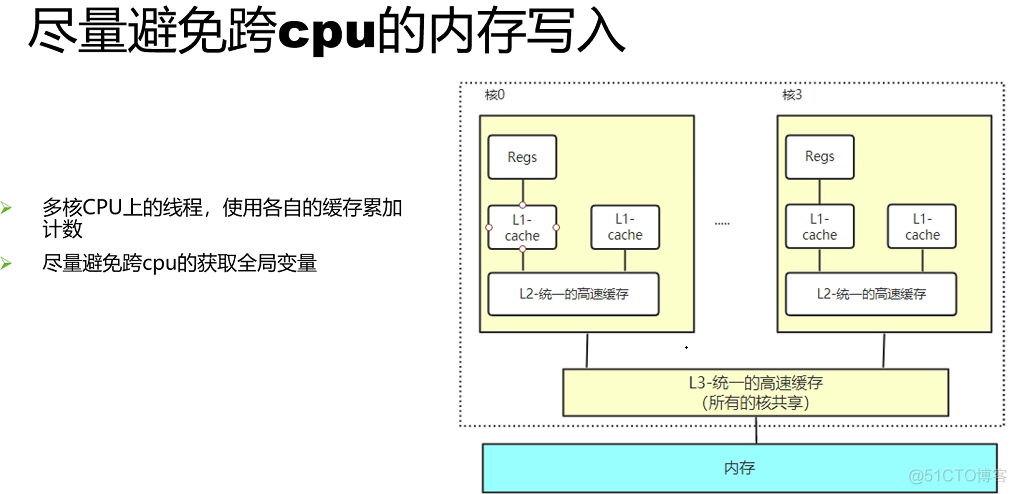
- 为了使吞吐最大,要避免cpu之间任何不必要的语境切换 同步 数据移动
- 新的或改进的服务应该很容易集成已有的指示事件多路分解和分配机制
- 应用层代码尽量不受多线程和同步机制的复杂性影响
解决方案
同步等待多个事件源(如连接的Socket句柄)的指示事件到达。将对事件多路分解以及分配处理事件的服务的机制进行集成;将事件多路分解和分配机制从服务中对指示事件的与应用有关的处理分离出去。
细节:对于应用程序提供的每个服务,引入一个单独的事件处理程序处理某一个事件源的某一类型的事件。在反应器中注册所有的事件处理程序,反应器使用一个同步事件多路分解器等待一个或多个事件源的指示事件。发生指示事件后,同步事件多路分解器通知反应器,后者同步地分配与事件相关的事件处理程序,以便这些事件处理程序可以执行请求的服务。
结构
操作系统提供句柄(handle)来识别像网络连接或打开文件这样的事件源,事件源产生指示事件并对它的进行排队。指示事件可以来自于外部,也可以来源于内部。一旦一个事件源产生了一个指示事件,该提示事件就被送入相关句柄的队列中,句柄被标记为“就绪”。这样不会阻塞调用线程。
同步事件多路分解器(synchronous event demultiplexer)是一个函数。调用该函数,可以等待发生在一组句柄(句柄集)上的一个或多个指示事件。该函数在开始一直阻塞着,直到句柄集上的指示事件通知同步事件多路分解器“该句柄集上的一个或多个句柄变为‘就绪’”,这就意味着在没有阻塞的情况下可以启动一个对句柄的操作。

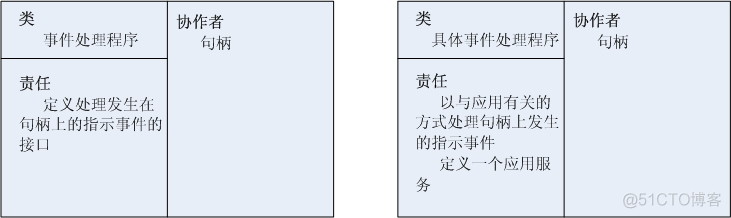
事件处理程序定义一个由一个或多个钩子方法组成的接口。钩子方法代表操作,这些操作可用于处理与应用有关的发生在与某事件处理程序相关联的句柄上的指示事件。
具体事件处理程序(concrete event handle)是实现应用程序所提供的特定服务的事件处理程序。每个具体事件处理程序都和一个句柄相关,句柄决定应用程序中的服务。特别是具体事件处理程序实现了钩子方法,这些钩子方法负责处理通过对应的句柄接收来的指示事件。将服务结果写到句柄上,并返回给调用者。
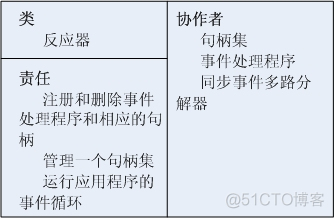
反应器(reactor)定义了一个接口,允许应用程序注册或删除事件处理程序及其相应的句柄,并运行应用程序的事件循环。反应器使用同步事件多路分解器等待在句柄集上发生指示事件。当有指示事件时,反应器首先从发生指示事件的句柄上将每个指示事件多路分解给相应的事件处理程序,然后在句柄上分配合适的钩子方法以处理这些事件。
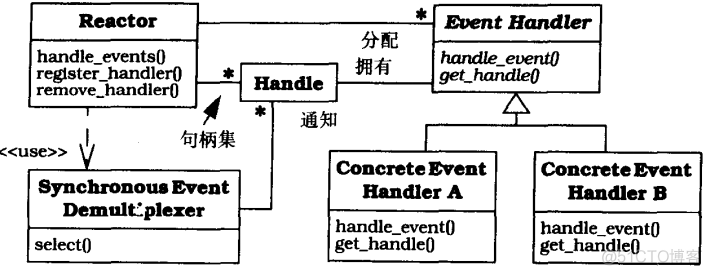
反应器模式结构是:如何将应用中的控制流“倒置”;等待指示事件,多路分解器将这些事件分给具体的应用处理程序,向具体事件处理程序分配钩子方法,
所有做这些的是反应器 而不是应用程序的责任。具体事件处理程序并不调用反应器;而由反应器分配一个具体事件处理程序。这种是“控制逆转”了
反应器组件耦合图
实现
反应器模式的各个部分分成两层:
·多路分解/分配基础设施层的组件。本层执行一个通用的,与应用无关的策略,用于将指示事件多路分解到事件处理程序,然后分配相应的事件处理程序钩子的方法。
·应用层组件。本层定义具体事件处理程序,在具体事件处理程序的钩子方法中进行与应用有关的处理。
1)定义事件处理程序接口。事件处理程序具体指定了由一个或几个钩子方法组成的接口。这些钩子方法代表了处理由反应器接收并分配的指示事件件可用的服务集。
1.1)确定分配目标的类型。为实现反应器的分配策略,一个句柄可以有两类事件处理程序。
·事件处理程序对象(event handler object)。在面向对象的应用中,将事件处理程序与句柄结合起来的一个常用的方法是建立一个事件处理程序对象。
·事件处理程序函数(event handler function)。将事件处理程序与句柄结合起来的另一个策略是向反应器注册一个指向函数的指针。使用函数指针作为分配目标,不用定义继承事件处理程序基类的新的子类,就可以很方便地注册回调函数。
1.2)确定事件处理程序分配接口策略。下一步必须定义事件处理程序时支持的接口类型。假设使用事件处理程序对象而不用函数指针,这里有两种大致的策略:
·单方法分配接口策略(single-method dispatch interface strategy)。该接口只包括一个事件处理方法。使用单方法分配接口策略,就可以在不改变类接口的情况下,支持新的指示事件类型。但是该策略要求在具体事件处理程序的方法中大量使用switch和if语句来处理特定事件,从而降低了可扩展性。
·多方法分配接口策略。该策略是为处理每一类事件创建一个单独的钩子方法。这比单方法分配接口策略更具有扩展性,因为是由反应器实现而不是由具体事件处理程序的方法来进行多路分解的。
2)定义反应器接口。应用程序使用反应器接口注册或删除事件处理程序及相应的句柄,并调用应用程序的事件循环。
3)实现反应器接口。
3.1)开发反应器的实现层次。
3.2)选择一种同步事件多路分解器机制。
3.3)实现一个多路分解表。除了调用同步事件多路分解器等待句柄集发生指示事件之外,反应器实现还要维护一个多路分解表。该表是一个管理者,包含一个格式为<句柄, 事件处理程序, 指示事件类型>的三元组表。反应器实现使用句柄作为关键字和多路分解表中的事件处理程序建立关联。该表也存储了事件处理程序注册到句柄上的指示事件的类型。
3.4)定义反应器的具体实现。
4)确定应用程序所需要的反应器数量。对于某些实时应用程序,通过将不同的反应器与具有不同优先级的线程相关联,可以为不同类型的同步操作处理指示事件提供了不同等级的服务质量。
5)实现具体事件处理程序。
5.1)确定维护具体事件处理程序状态的策略。一个事件处理程序需要维护与特定请求有关的状态信息。
5.2)实现用一个句柄配置各具体事件处理程序的策略。
·硬编码。该策略将句柄或者句柄的包装器外观硬编码到具体事件处理程序中。这种方法很容易实现,但是如果对于不同的用况必须将不同类型的句柄或IPC机制配置到事件处理程序中时,重用性不好。
·类属(generic)方法。一个更通用的策略是在模板化事件处理程序类中以类型为参数来实例化包装器外观。这种方法能产生更灵活和可重用的事件处理程序,虽然在总使用一种句柄类型或者IPC机制的情况下,这种通用性是不必要的。
5.3)实现具体事件处理程序的功能。
优点:
1)事务分离。反应器模式将与应用程序无关的多路分解和分配机制和与应用有关的钩子方法功能分开。与应用无关的机制被设计成可重用的组件。该组件知道如何多路分解指示事件并分配由事件处理程序定义的适当的钩子方法。相反,钩子方法中与应用有关的功能知道如何完成特定类型的服务。
2)模块化,可重用性与可配置性。该模式将事件驱动的应用功能分解成几个组件。它们被松散地集成在反应器中,这种模块化有助于更高级的软件组件重用。
3)可移植性。只要把反应器接口从实现中使用的低层操作系统的同步事件多路分解器函数中分离出来,就可以很容易地跨平台移植使用反应器模式的应用程序。
不足:
1)应用范围受到限制。如果操作系统支持对句柄集的同步事件多路分解,使用反应器模式会很高效。然而,如果操作系统并不提供这类支持,可以在反应器实现中使用多线程模拟反应器模式的语义。
2)非抢先的方式(Non-pre-emptive)。事件处理程序不应该执行耗时长的操作,因为这样会阻塞整个进程,并妨碍反应器对连接到其他句柄上的客户机的响应。
3)调试和测试的复杂性。
MEM:
- 缓存有效原理
- 缓存更新策略
- 缓存使用方法场景------读多写少:
- 内存池
- 线程池
- 对象池
CPU:
- 零拷贝
- IO复用
- protoubuf
- 无锁编程 lock-free lock-wait
- 多线程
- 请求合并 事件合并
- 预先处理
- 延迟处理
- 服务解耦---订阅发布模型 流控缓存

设计:
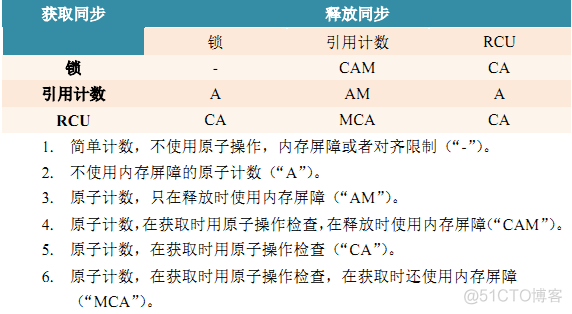
统计计数器如何设计?
基于数组的实现,参考per_cpu变量;多线程中TLS 每线程存储的_thread存储类
结果一致性的要求??
1 unsigned long __thread counter = 0;
2 unsigned long *counterp[NR_THREADS] = { NULL };
3 unsigned long finalcount = 0;
4 DEFINE_SPINLOCK(final_mutex);
5
6 static __inline__ void inc_count(void)
7 {
8 WRITE_ONCE(counter, counter + 1);
9 }
10
11 static __inline__ unsigned long read_count(void)
12 {
13 int t;
14 unsigned long sum;
15
16 spin_lock(&final_mutex);
17 sum = finalcount;
18 for_each_thread(t)
19 if (counterp[t] != NULL)
20 sum += READ_ONCE(*counterp[t]);
21 spin_unlock(&final_mutex);
22 return sum;
23 }
24
25 void count_register_thread(unsigned long *p)
26 {
27 int idx = smp_thread_id();
28
29 spin_lock(&final_mutex);
30 counterp[idx] = &counter;
31 spin_unlock(&final_mutex);
32 }
34 void count_unregister_thread(int nthreadsexpected)
35 {
36 int idx = smp_thread_id();
38 spin_lock(&final_mutex);
39 finalcount += counter;
40 counterp[idx] = NULL;
41 spin_unlock(&final_mutex);
42 }
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
DEFINE_PER_THREAD(unsigned long, counter);
2 unsigned long global_count;
3 int stopflag;
5 static __inline__ void inc_count(void)
6 {
7 unsigned long *p_counter = &__get_thread_var(counter);
9 WRITE_ONCE(*p_counter, *p_counter + 1);
10 }
12 static __inline__ unsigned long read_count(void)
13 {
14 return READ_ONCE(global_count);
15 }
17 void *eventual(void *arg)
18 {
19 int t;
20 unsigned long sum;
22 while (READ_ONCE(stopflag)< 3) {
23 sum = 0;
24 for_each_thread(t)
25 sum += READ_ONCE(per_thread(counter, t));
26 WRITE_ONCE(global_count, sum);
27 poll(NULL, 0, 1);
28 if (READ_ONCE(stopflag)) {
29 smp_mb();
30 WRITE_ONCE(stopflag, stopflag + 1);
31 }
32 }
33 return NULL;
34 }
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
如何设计上限计数器?
分割和同步的设计
资源分配并行快速路径-----每cpu 预留缓存? 通用并行编程方法有:排队、引用计数、RCU
void kref_get(struct kref *kref)
{
WARN_ON(!atomic_read(&kref->refcount));
atomic_inc(&kref->refcount);
smp_mb__after_atomic_inc();
}
int kref_put(struct kref *kref, void (*release)(struct kref *kref))
{
WARN_ON(release == NULL);
WARN_ON(release == (void (*)(struct kref *))kfree);
if (atomic_dec_and_test(&kref->refcount)) {
release(kref);
return 1;
}
return 0;
}
/*初始化kref之后,kref的使用应该遵循以下三条规则:
1)如果你创建了一个结构指针的非暂时性副本,特别是当这个副本指针会被传递到其它执行线程时,你必须在传递副本指针之前执行kref_get():
kref_get(&data->refcount);
2)当你使用完,不再需要结构的指针,必须执行kref_put,如果这是结构指针的最后一个引用,release()函数会被调用,如果代码绝不会在没有拥有引用计数的请求下去调用kref_get(),在kref_put()时就不需要加锁:
kref_put(&data->refcount, data_release);
3)如果代码试图在还没有拥有引用计数的情况下就调用kref_get(),就必须串行化kref_put()和kref_get()的执行,因为很可能在kref_get()执行之前或者执行中,kref_put()就被调用并把整个结构释放掉:
例如,你分配了一些数据并把它传递到其它线程去处理:*/
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
/**
* kref_put - decrement refcount for object.
* @kref: object.
* @release: pointer to the function that will clean up the object when the
* last reference to the object is released.
* This pointer is required, and it is not acceptable to pass kfree
* in as this function. If the caller does pass kfree to this
* function, you will be publicly mocked mercilessly by the kref
* maintainer, and anyone else who happens to notice it. You have
* been warned.
*
* Decrement the refcount, and if 0, call release().
* Return 1 if the object was removed, otherwise return 0. Beware, if this
* function returns 0, you still can not count on the kref from remaining in
* memory. Only use the return value if you want to see if the kref is now
* gone, not present.
*/
static inline int kref_put(struct kref *kref, void (*release)(struct kref *kref))
{
return kref_sub(kref, 1, release);
}
static inline int kref_put_mutex(struct kref *kref,
void (*release)(struct kref *kref),
struct mutex *lock)
{
WARN_ON(release == NULL);
if (unlikely(!atomic_add_unless(&kref->refcount, -1, 1))) {
mutex_lock(lock);
if (unlikely(!atomic_dec_and_test(&kref->refcount))) {
mutex_unlock(lock);
return 0;
}
release(kref);
return 1;
}
return 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
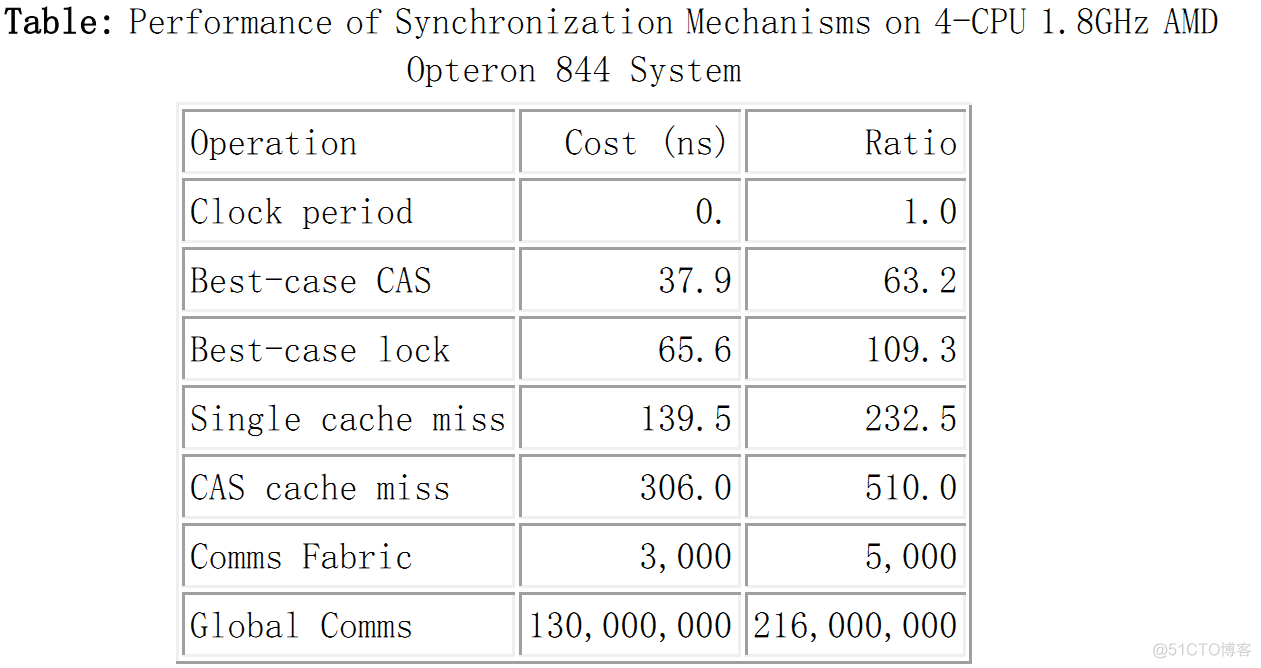
各种基础操作的时钟消耗
http代理服务器(3-4-7层代理)-网络事件库公共组件、内核kernel驱动 摄像头驱动 tcpip网络协议栈、netfilter、bridge 好像看过!!!! 但行好事 莫问前程 --身高体重180的胖子
边栏推荐
- What is business intelligence (BI), just look at this article is enough
- 迷失在Mysql的锁世界
- gtest从一无所知到熟练运用(1)gtest安装
- Redis03 - network configuration and heartbeat mechanism of redis
- GTEST from ignorance to proficiency (3) what are test suite and test case
- [weekly translation go] how to code in go series articles are online!!
- PostgreSQL基本结构——表
- 置信区间的画法
- MP3是如何诞生的?
- # 2156. 查找给定哈希值的子串-后序遍历
猜你喜欢
Master the use of auto analyze in data warehouse
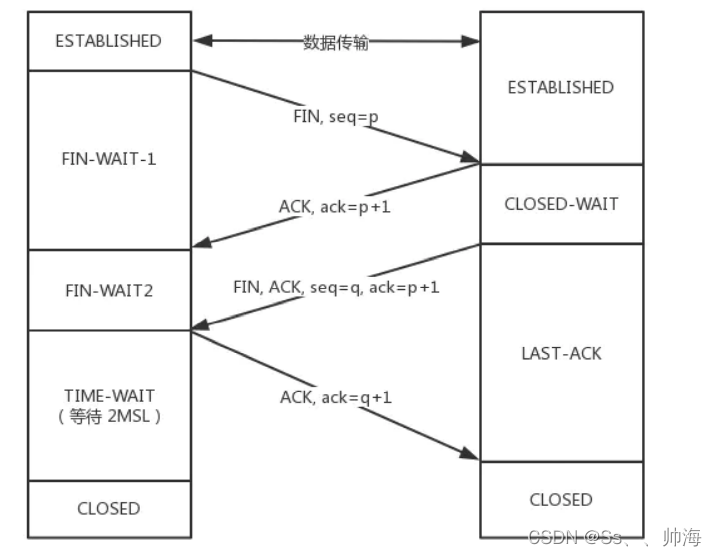
TCP shakes hands three times and waves four times. Do you really understand?
Bookmark
一文掌握数仓中auto analyze的使用
Super detailed tutorial, an introduction to istio Architecture Principle and practical application
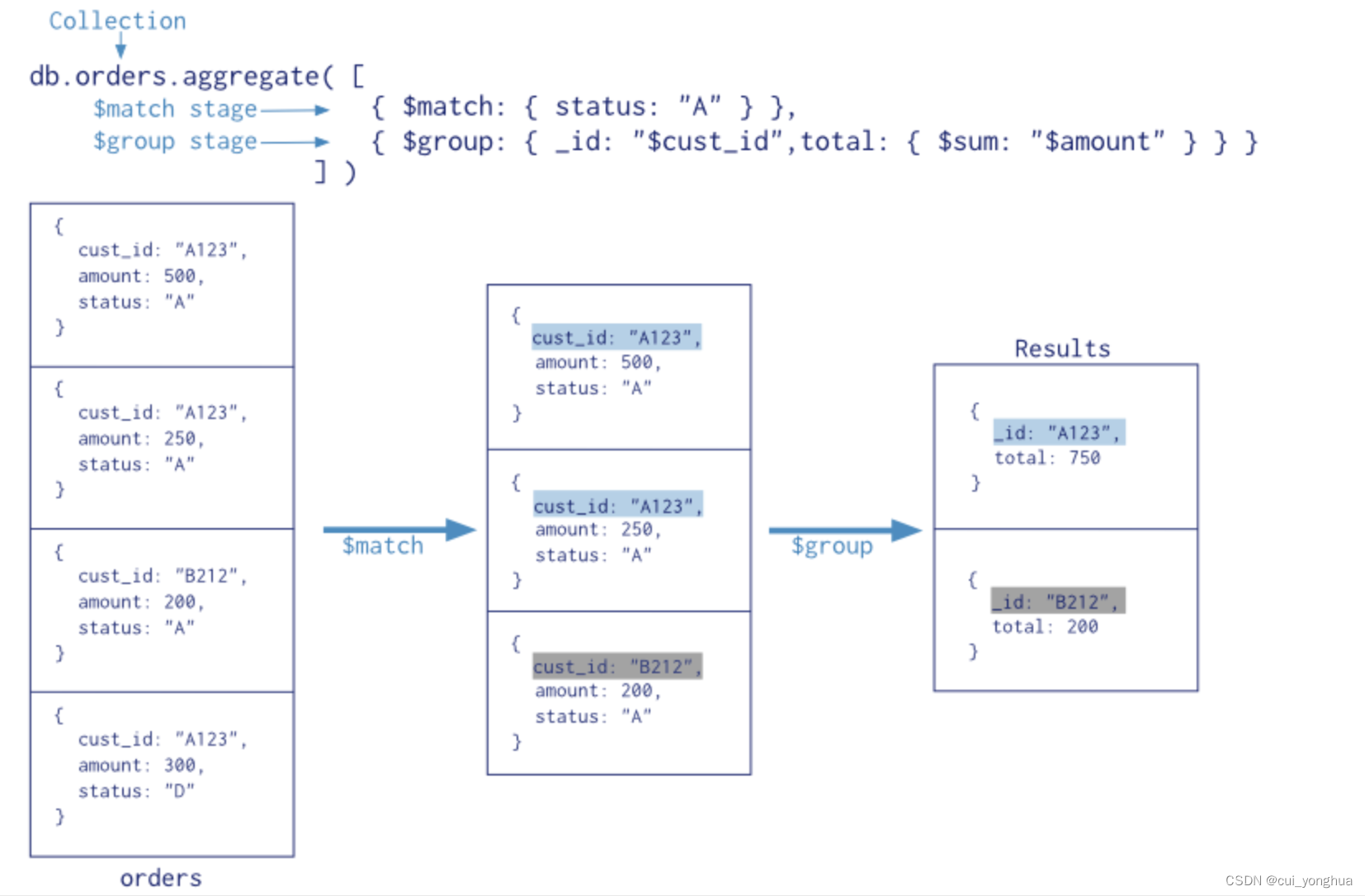
MongoDB聚合操作总结

Redis03 - network configuration and heartbeat mechanism of redis

How to implement Devops with automatic tools
![Compréhension approfondie du symbole [langue C]](/img/4b/26cf10baa29eeff08101dcbbb673a2.png)
Compréhension approfondie du symbole [langue C]

湘江鲲鹏加入昇腾万里伙伴计划,与华为续写合作新篇章
随机推荐
Three or two things about the actual combat of OMS system
Go语言循环语句(第10课中3)
湘江鲲鹏加入昇腾万里伙伴计划,与华为续写合作新篇章
Monitor the shuttle return button
能源势动:电力行业的碳中和该如何实现?
Caduceus从未停止创新,去中心化边缘渲染技术让元宇宙不再遥远
gtest从一无所知到熟练使用(4)如何用gtest写单元测试
MP3是如何诞生的?
ArcGIS 10.2.2 | solution to the failure of ArcGIS license server to start
Rotary transformer string judgment
Which securities company has the lowest Commission for opening an account online? I want to open an account. Is it safe to open an account online
【活动早知道】LiveVideoStack近期活动一览
[leetcode] 17. Letter combination of telephone number
保证接口数据安全的10种方案
Interpreting the development of various intelligent organizations in maker Education
Delphi SOAP WebService 服务器端多个 SoapDataModule 实现相同的接口方法,接口继承
HDU - 2859 Phalanx(DP)
淘宝商品评价api接口(item_review-获得淘宝商品评论API接口),天猫商品评论API接口
类方法和类变量的使用
el-tree结合el-table,树形添加修改操作