当前位置:网站首页>Use dumping to back up tidb cluster data to S3 compatible storage
Use dumping to back up tidb cluster data to S3 compatible storage
2022-07-06 08:03:00 【Tianxiang shop】
This document describes how to put Kubernetes On TiDB The data of the cluster is backed up to compatible S3 On the storage of . In this document “ Backup ”, All refer to full backup ( namely Ad-hoc Full backup and scheduled full backup ).
The backup method described in this document is based on TiDB Operator(v1.1 And above ) Of CustomResourceDefinition (CRD) Realization , Bottom use Dumpling The tool obtains the logical backup of the cluster , Then upload the backup data to compatible S3 On the storage of .
Dumpling Is a data export tool , The tool can store in TiDB/MySQL The data in is exported as SQL perhaps CSV Format , It can be used to complete logical full backup or export .
Use scenarios
If you need to TiDB Cluster data in Ad-hoc Full volume backup or Scheduled full backup Backup to compatible S3 On the storage of , And there are the following requirements for data backup , Consider the backup scheme introduced in this article :
- export SQL or CSV Formatted data
- For single SQL Limit the memory of the statement
- export TiDB Snapshot of historical data
Ad-hoc Full volume backup
Ad-hoc Full backup by creating a custom Backup custom resource (CR) Object to describe a backup .TiDB Operator According to this Backup Object to complete the specific backup process . If an error occurs during the backup , The program will not automatically retry , At this time, it needs to be handled manually .
Current compatibility S3 In storage ,Ceph and Amazon S3 It can work normally after testing . The following provides how to TiDB The data of the cluster is backed up to Ceph and Amazon S3 Examples of these two types of storage . The example assumes that the pair is deployed in Kubernetes tidb-cluster This namespace Medium TiDB colony demo1 Data backup , The following is the specific operation process .
precondition
Use Dumpling Backup TiDB Cluster data to S3 front , Make sure you have the following permissions to back up the database :
mysql.tidbTabularSELECTandUPDATEjurisdiction : Before and after backup ,Backup CR You need a database account with this permission , Used to adjust GC Time .- Global permissions :
SELECT、RELOAD、LOCK TABLES、 andREPLICATION CLIENT.
The following is an example of how to create a backup user :
CREATE USER 'backup'@'%' IDENTIFIED BY '...'; GRANT SELECT, RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'backup'@'%'; GRANT UPDATE, SELECT ON mysql.tidb TO 'backup'@'%';
The first 1 Step :Ad-hoc Full backup environment preparation
Execute the following command , according to backup-rbac.yaml stay
tidb-clusterNamespace creates role-based access control (RBAC) resources .kubectl apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.3.6/manifests/backup/backup-rbac.yaml -n tidb-clusterRemote storage access authorization .
If you use Amazon S3 To back up the cluster , There are three ways to grant permissions , Reference resources AWS Account Authorization Authorized access is compatible S3 Remote storage of ; Use Ceph When testing backup as back-end storage , It's through AccessKey and SecretKey Mode Authorization , Please refer to adopt AccessKey and SecretKey to grant authorization .
establish
backup-demo1-tidb-secretsecret. The secret Store for access TiDB Clustered root Account and key .kubectl create secret generic backup-demo1-tidb-secret --from-literal=password=${password} --namespace=tidb-cluster
The first 2 Step : Back up data to compatible S3 The storage
Be careful
because
rcloneThere is problem , If you use Amazon S3 Store backup , also Amazon S3 Open theAWS-KMSencryption , You need yaml Add the following to the filespec.s3.optionsConfigure to ensure successful backup :spec: ... s3: ... options: - --ignore-checksum
This section provides a variety of ways to store access . Just use the method that suits your situation .
- By importing AccessKey and SecretKey Backup to Amazon S3 Methods
- By importing AccessKey and SecretKey Backup to Ceph Methods
- By binding IAM And Pod Backup to Amazon S3 Methods
- By binding IAM And ServiceAccount Backup to Amazon S3 Methods
Method 1: establish
BackupCR, adopt AccessKey and SecretKey Back up the data to Amazon S3.kubectl apply -f backup-s3.yamlbackup-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster spec: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws secretName: s3-secret region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10GiMethod 2: establish
BackupCR, adopt AccessKey and SecretKey Back up the data to Ceph.kubectl apply -f backup-s3.yamlbackup-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster spec: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: ceph secretName: s3-secret endpoint: ${endpoint} # prefix: ${prefix} bucket: ${bucket} # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10GiMethod 3: establish
BackupCR, adopt IAM binding Pod Back up the data to Amazon S3.kubectl apply -f backup-s3.yamlbackup-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster annotations: iam.amazonaws.com/role: arn:aws:iam::123456789012:role/user spec: backupType: full from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10GiMethod 4: establish
BackupCR, adopt IAM binding ServiceAccount Back up the data to Amazon S3.kubectl apply -f backup-s3.yamlbackup-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster spec: backupType: full serviceAccount: tidb-backup-manager from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi
The above example will TiDB The data of the cluster is fully exported and backed up to Amazon S3 and Ceph On .Amazon S3 Of acl、endpoint、storageClass Configuration items can be omitted . The rest are not Amazon S3 But compatible S3 Storage can be used and Amazon S3 Similar configuration . Refer to the example above Ceph Configuration of , Omit fields that do not need to be configured . More compatible S3 Storage related configuration reference S3 Storage field introduction .
In the example above ,.spec.dumpling Express Dumpling Related configuration , Can be in options Field assignment Dumpling Operation parameters of , For details, see Dumpling Using document ; By default, this field can be configured without . When you don't specify Dumpling The configuration of ,options The default values of the fields are as follows :
options: - --threads=16 - --rows=10000
more Backup CR For detailed explanation of fields, please refer to Backup CR Field is introduced .
Create good Backup CR after , You can view the backup status through the following commands :
kubectl get bk -n tidb-cluster -owide
To get a Backup job Details of , Please use the following command . For $backup_job_name, Please use the name in the output of the previous command .
kubectl describe bk -n tidb-cluster $backup_job_name
If you want to run again Ad-hoc Backup , You need Delete the backed up Backup CR And recreate .
Scheduled full backup
Users set backup policies to TiDB The cluster performs scheduled backup , At the same time, set the retention policy of backup to avoid too many backups . Scheduled full backup through customized BackupSchedule CR Object to describe . A full backup will be triggered every time the backup time point , The bottom layer of scheduled full backup passes Ad-hoc Full backup . The following are the specific steps to create a scheduled full backup :
The first 1 Step : Regular full backup environment preparation
Same as Ad-hoc Full backup environment preparation .
The first 2 Step : Back up data in full on a regular basis to S3 Compatible storage
Be careful
because rclone There is problem , If you use Amazon S3 Store backup , also Amazon S3 Open the AWS-KMS encryption , You need yaml Add the following to the file spec.backupTemplate.s3.options Configure to ensure successful backup :
spec: ... backupTemplate: ... s3: ... options: - --ignore-checksum
Method 1: establish
BackupScheduleCR Turn on TiDB Scheduled full backup of the cluster , adopt AccessKey and SecretKey Back up the data to Amazon S3:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-s3 namespace: tidb-cluster spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws secretName: s3-secret region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10GiMethod 2: establish
BackupScheduleCR Turn on TiDB Scheduled full backup of the cluster , adopt AccessKey and SecretKey Back up the data to Ceph:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-ceph namespace: tidb-cluster spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: ceph secretName: s3-secret endpoint: ${endpoint} bucket: ${bucket} # prefix: ${prefix} # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10GiMethod 3: establish
BackupScheduleCR Turn on TiDB Scheduled full backup of the cluster , adopt IAM binding Pod Back up the data to Amazon S3:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-s3 namespace: tidb-cluster annotations: iam.amazonaws.com/role: arn:aws:iam::123456789012:role/user spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10GiMethod 4: establish
BackupScheduleCR Turn on TiDB Scheduled full backup of the cluster , adopt IAM binding ServiceAccount Back up the data to Amazon S3:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yamlThe contents of the document are as follows :--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-s3 namespace: tidb-cluster spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" serviceAccount: tidb-backup-manager backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi
After the scheduled full backup is created , You can view the status of scheduled full backup through the following commands :
kubectl get bks -n tidb-cluster -owide
Check all the backup pieces below the scheduled full backup :
kubectl get bk -l tidb.pingcap.com/backup-schedule=demo1-backup-schedule-s3 -n tidb-cluster
From the above example ,backupSchedule The configuration of consists of two parts . Part of it is backupSchedule Unique configuration , The other part is backupTemplate.backupTemplate Specify the configuration related to cluster and remote storage , Fields and Backup CR Medium spec equally , Please refer to Backup CR Field is introduced .backupSchedule For the introduction of unique configuration items, please refer to BackupSchedule CR Field is introduced .
Be careful
TiDB Operator Will create a PVC, This PVC At the same time Ad-hoc Full backup and scheduled full backup , The backup data will be stored in PV, Then upload to remote storage . If you want to delete this after the backup PVC, You can refer to Delete resources First back up Pod Delete , Then take it. PVC Delete .
If the backup and upload to the remote storage are successful ,TiDB Operator Will automatically delete the local backup file . If the upload fails , Then the local backup file will be preserved .
Delete the backed up Backup CR
When the backup is complete , You may need to delete the backup Backup CR. Please refer to Delete the backed up Backup CR.
边栏推荐
- MFC sends left click, double click, and right click messages to list controls
- 1204 character deletion operation (2)
- 49. Sound card driven article collection
- [research materials] 2021 live broadcast annual data report of e-commerce - Download attached
- A Closer Look at How Fine-tuning Changes BERT
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- [Yugong series] February 2022 U3D full stack class 011 unity section 1 mind map
- wincc7.5下载安装教程(Win10系统)
- Circuit breaker: use of hystrix
- [KMP] template
猜你喜欢

Artcube information of "designer universe": Guangzhou implements the community designer system to achieve "great improvement" of urban quality | national economic and Information Center
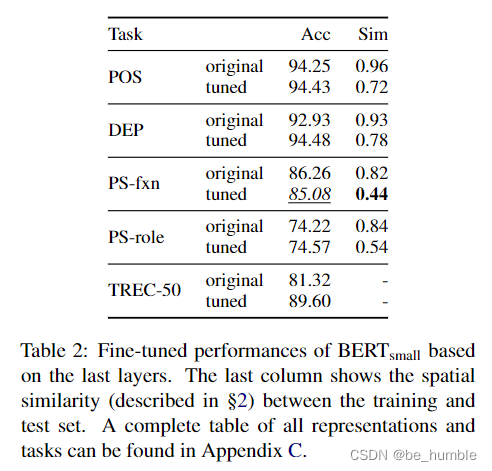
A Closer Look at How Fine-tuning Changes BERT
matplotlib. Widgets are easy to use
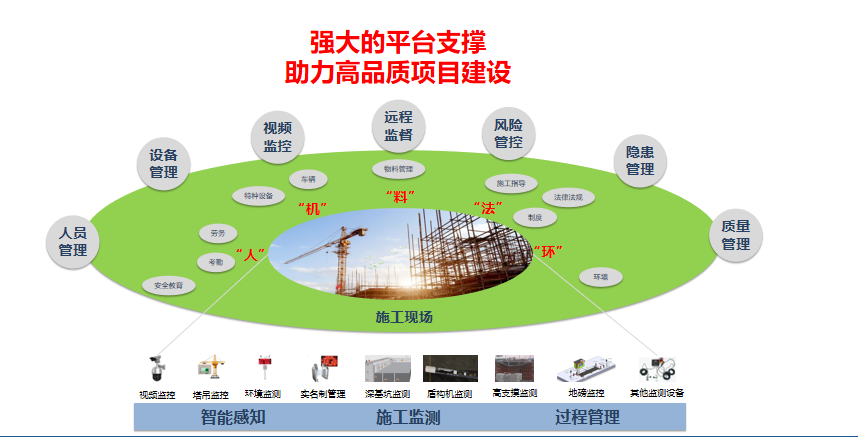
Solution: intelligent site intelligent inspection scheme video monitoring system
Asia Pacific Financial Media | "APEC industry +" Western Silicon Valley invests 2trillion yuan in Chengdu Chongqing economic circle to catch up with Shanghai | stable strategy industry fund observatio
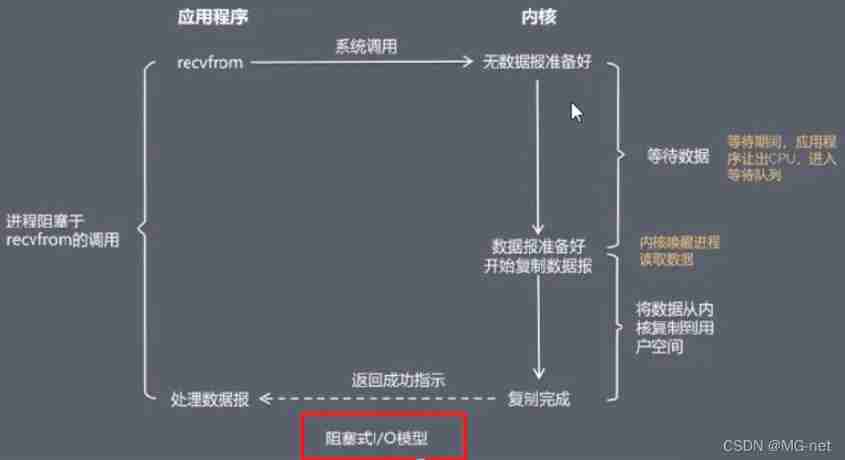
Epoll and IO multiplexing of redis
好用的TCP-UDP_debug工具下载和使用
Machine learning - decision tree
Parameter self-tuning of relay feedback PID controller
![[nonlinear control theory]9_ A series of lectures on nonlinear control theory](/img/a8/03ed363659a0a067c2f1934457c106.png)
[nonlinear control theory]9_ A series of lectures on nonlinear control theory
随机推荐
Parameter self-tuning of relay feedback PID controller
Sanzi chess (C language)
2.10transfrom attribute
【Redis】NoSQL数据库和redis简介
[Yugong series] February 2022 U3D full stack class 010 prefabricated parts
数据治理:误区梳理篇
使用 Dumpling 备份 TiDB 集群数据到兼容 S3 的存储
Chinese Remainder Theorem (Sun Tzu theorem) principle and template code
Type of data in energy dashboard
MEX有关的学习
Understanding of law of large numbers and central limit theorem
CAD ARX gets the current viewport settings
Yu Xia looks at win system kernel -- message mechanism
Onie supports pice hard disk
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
你想知道的ArrayList知识都在这
Oracle time display adjustment
Wireshark grabs packets to understand its word TCP segment
让学指针变得更简单(三)
1202 character lookup