当前位置:网站首页>[Data Mining] Visual Pattern Mining: Hog Feature + cosinus Similarity / K - means Clustering
[Data Mining] Visual Pattern Mining: Hog Feature + cosinus Similarity / K - means Clustering
2022-07-07 15:06:00 【Zstar - _】
1. Aperçu de l'expérience
Cette expérience utiliseVOC2012Ensemble de données,Tout d'abord, les blocs d'image sont échantillonnés au hasard à partir de l'image,Et utiliserHogMéthode d'extraction des caractéristiques du bloc d'image,Enfin, la similitude cosinus etk-meansRegroupement de deux façons d'exploiter les modèles visuels.
2. Description de l'ensemble de données
Pour cette expérienceVOC2012Ensemble de données.VOC2012Les ensembles de données sont souvent utilisés pour la détection des cibles、Segmentation des images、Expériences de comparaison de réseaux et évaluation des effets des modèles.Pour la tâche de segmentation d'image,VOC2012L'ensemble de validation de la formation pour contient2007-2011Toutes les images correspondantes pour l'année,Contient2913Photos et6929Objectifs,L'ensemble d'essais ne contient que2008-2011Année.
Parce que cet ensemble de données est principalement utilisé dans des tâches telles que la détection de cibles,Donc dans cette expérience,,Utilisé uniquement dans cet ensemble de données8Données de classe.
Lien de téléchargement de l'ensemble de données:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
3. Introduction du modèle d'algorithme
3.1 HogExtraction des caractéristiques
Histogramme du gradient directionnel(Histogram of Oriented Gradient, HOG)Une caractéristique est un descripteur de caractéristique utilisé pour la détection d'objets dans la vision par ordinateur et le traitement d'images.Il est caractérisé par le calcul et la statistique des histogrammes de direction de gradient des régions locales de l'image, Ses principales étapes sont les suivantes: :
- Graissage
Griser l'image , Filtrer les informations de couleur non pertinentes . - Normalisation des espaces de couleurs
AdoptionGammaMéthode de correction pour normaliser l'espace de couleur de l'image d'entrée, Peut ajuster le contraste de l'image ,Réduire l'impact des variations locales de l'ombre et de la lumière sur l'image,En même temps, l'interférence du bruit peut être supprimée. - Calcul du gradient
Calculer le gradient par pixel de l'image(Y compris la taille et l'orientation), Les informations de profil peuvent être saisies ,En même temps, l'interférence de la lumière est encore affaiblie. - CellDivision
Diviser l'image en petitscells,Par8x8TailleCellPar exemple,Comme le montre la figure:
- ChaquecellHistogramme de gradient pour
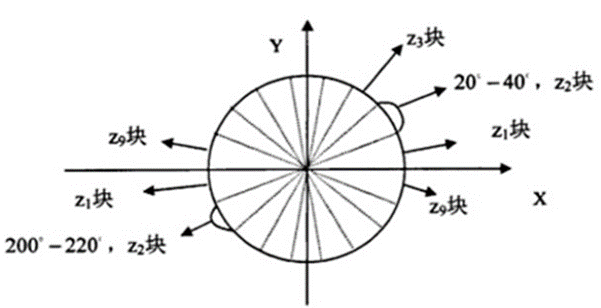
Comme le montre la figure,Oui.360°Divisé en18Part, Chaque angle est 20°.En même temps, Quelle que soit la taille de la direction , C'est - à - dire un total de 9 Catégorie d'angle de partage , Fréquence des statistiques pour chaque catégorie . - Pour chaquecellFormer unblock
Par2x2TailleblockPar exemple,Comme le montre la figure:
La boîte bleue de l'image représente un cell, La case jaune indique un block,Oui.2x2- Oui.cellSe compose d'unblock,En même temps,block L'histogramme de gradient est normalisé à l'intérieur . Il existe quatre méthodes principales de normalisation :
Comme indiqué dans le document original L2-Hys La méthode fonctionne mieux [1], Donc dans cette expérience , La méthode de normalisation est également utilisée L2-Hys. - Bougeblock
ChaqueblockParcell Se déplacer horizontalement et verticalement pour l'espacement , Enfin, tous les vecteurs caractéristiques sont concaténés pour obtenir le bloc d'image HogCaractéristiques.
3.2 Similitude cosinus
Obtenir le HogAprès les caractéristiques, La classification est effectuée en calculant la similitude cosinus des vecteurs caractéristiques de chaque bloc d'image. ,La formule de calcul de la similitude cosinus est la suivante::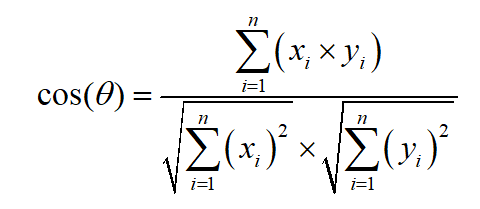
3.3 K-meansRegroupement
Obtenir le HogAprès les caractéristiques,Peut également être utiliséK-means Regroupement pour l'exploration de modèles visuels .K-means Le processus de regroupement est illustré ci - dessous. :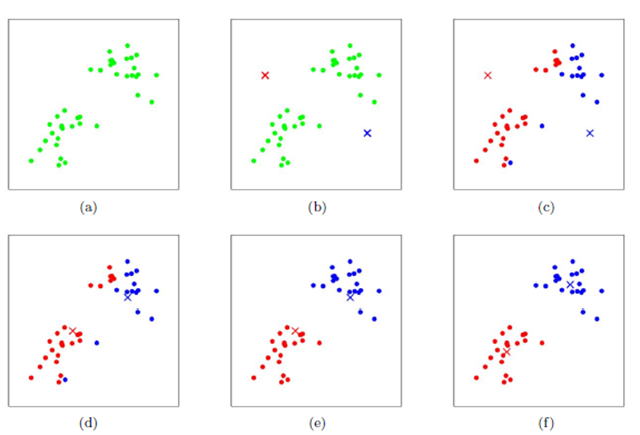
Tout d'abord, deux points sont initialisés au hasard comme centre de regroupement , Calculer la distance entre chaque point et le Centre du cluster , Et le regroupement dans le regroupement le plus proche de ce point .Après, Calculer la moyenne des coordonnées de tous les points de chaque grappe , Et prendre cette moyenne comme nouveau centre de regroupement ;Répétez les deux étapes ci - dessus., Jusqu'à ce que le Centre de regroupement de chaque classe ne change plus , Terminer le regroupement .
4. Indicateurs de fréquence et d'évaluation discriminante
4.1 Indicateurs d'évaluation de la fréquence
Si un motif apparaît plus d'une fois dans une image positive , Est appelé fréquence .Dans cette expérience,, L'indice d'évaluation de la fréquence fait référence à Wang QianAn et al. [2]Critères d'évaluation pour, Définir la formule de fréquence comme suit: :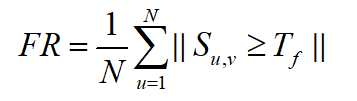
Où,N Représente le nombre total d'échantillons d'une catégorie , S u , v S_{u,v} Su,v Représente un échantillon dans cette classe uEt des échantillonsvSimilitude cosinus de, T f T_f TfSeuil de représentation.
4.2 Indicateurs d'évaluation discriminants
Si une valeur de mode apparaît dans une image positive , Pas dans une image négative , Est appelé discriminant .Dans cette expérience,, Utilisation de la précision moyenne de classification des modèles visuels pour définir la discrimination ,La formule est la suivante::
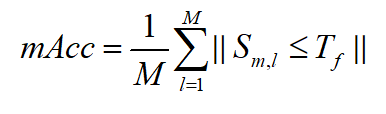
Où,M Indique le nombre total de catégories d'échantillons , S m , l S_{m,l} Sm,l Représente la moyenne des modes visuels de l'échantillon dans la classe mEt des échantillonsvSimilitude cosinus de, T f T_f TfSeuil de représentation.
5. Procédure expérimentale
5.1 Classification des ensembles de données
Cette expérience a utilisé VOC2012Ensemble de données, Les images ne sont pas classées par catégorie . Par conséquent, il est nécessaire de commencer par , .Diviser les images qui contiennent cette catégorie . Tout est utilisé ici 7Catégories:“Voiture、Chevaux、CAT、Les chiens.、Oiseaux、Moutons、Bovins”.
Le Code de base de la partition d'exécution est le suivant :
def get_my_classes(Annotations_path, image_path, save_img_path, classes):
xml_path = os.listdir(Annotations_path)
for i in classes:
if not os.path.exists(save_img_path+"/"+i):
os.mkdir(save_img_path+i)
for xmls in xml_path:
print(Annotations_path+"/"+xmls)
in_file = open(os.path.join(Annotations_path, xmls))
print(in_file)
tree = ET.parse(in_file)
root = tree.getroot()
if len(set(root.iter('object'))) != 1:
continue
for obj in root.iter('object'):
cls_name = obj.find('name').text
print(cls_name)
try:
shutil.copy(image_path+"/"+xmls[:-3]+"jpg", save_img_path+"/"+cls_name+"/"+xmls[:-3]+"jpg")
except:
continue
Les résultats après l'exécution du Code sont les suivants :
5.2 Échantillonnage de blocs d'images
Pour échantillonner un bloc d'image , La méthode de coupe aléatoire a été choisie dans cette expérience . Basé sur le point central de chaque image ,In[-Longueur et largeur de l'image/6,Longueur et largeur de l'image/6] Décalage du point central dans les limites de , Pour obtenir un bloc d'image échantillonné , Le processus d'échantillonnage est illustré à la figure :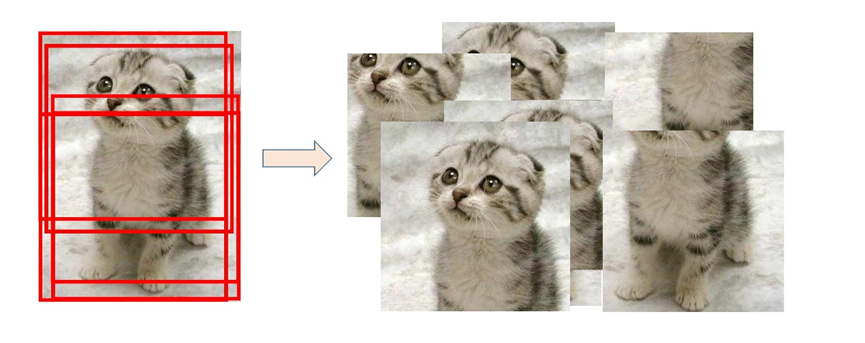
Pour chaque image, L'échantillonnage aléatoire total donne 10 Blocs d'échantillonnage ,Les codes de base sont les suivants::
for each_image in os.listdir(IMAGE_INPUT_PATH):
# Chemin complet par image
image_input_fullname = IMAGE_INPUT_PATH + "/" + each_image
# UtilisationPIL La bibliothèque ouvre chaque image
img = Image.open(image_input_fullname)
# Définir l'image coupée à gauche 、Allez.、A droite、 Coordonnées des pixels sous
x_max = img.size[0]
y_max = img.size[1]
mid_point_x = int(x_max/2)
mid_point_y = int(y_max/2)
for i in range(0, 10):
# Décalage aléatoire du point central
crop_x = mid_point_x + \
random.randint(int(-mid_point_x/3), int(mid_point_x/3))
crop_y = mid_point_y + \
random.randint(int(-mid_point_y/3), int(mid_point_y/3))
dis_x = x_max-crop_x
dis_y = y_max-crop_y
dis_min = min(dis_x, dis_y, crop_x, crop_y) # Obtenir la plage de variation
down = crop_y + dis_min
up = crop_y - dis_min
right = crop_x + dis_min
left = crop_x - dis_min
BOX_LEFT, BOX_UP, BOX_RIGHT, BOX_DOWN = left, up, right, down
# Retour d'une zone rectangulaire à partir de l'image originale ,La zone est un4 Les tuples définissent les coordonnées des pixels en haut à gauche et en bas à droite
box = (BOX_LEFT, BOX_UP, BOX_RIGHT, BOX_DOWN)
# En coursroiTaille
roi_area = img.crop(box)
# Chemin de chaque image après Culture +Nom
image_output_fullname = IMAGE_OUTPUT_PATH + \
"/" + str(i) + "_" + each_image
# Stocker l'image coupée
roi_area.save(image_output_fullname)
5.3 HogExtraction des caractéristiques
Pour chaque bloc d'image , Redimensionner à 256x256,Et la normalisation,ExtraireHogCaractéristiques,Les codes de base sont les suivants::
# Prétraitement des images
def preprocessing(src):
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY) # Convertir l'image en un diagramme en niveaux de gris
img = cv2.resize(gray, (256, 256)) # Calibrageg
img = img/255.0 # Normalisation des données
return img
# ExtractionhogCaractéristiques
def extract_hog_features(X):
image_descriptors = []
for i in range(len(X)):
''' Interprétation des paramètres: orientations:Nombre de directions pixels_per_cell:Taille cellulaire cells_per_block:Taille du bloc block_norm:Méthode facultative de normalisation des blocsL2-Hys(L2Norme) '''
fd, _ = hog(X[i], orientations=9, pixels_per_cell=(
16, 16), cells_per_block=(16, 16), block_norm='L2-Hys')
image_descriptors.append(fd) # Pour assembler toutes les images hogCaractéristiques
return image_descriptors # Toutes les images de la section formation sont retournées hogCaractéristiques
Ici.cellTaille sélectionnée comme(16,16),blockLa taille est(16,16).
5.4 Excavation par similitude cosinus
Selon tous les blocs d'image HogCaractéristiques, Calcul à l'aide de critères de fréquence et de discrimination ,Les codes de base sont les suivants::
threshold = 0.6
group1 = []
group2 = []
group1.append(X_features[0])
for i in range(1, len(X_features)):
res = cosine_similarity(X_features[0].reshape(1, -1), X_features[i].reshape(1, -1))
if res > threshold:
group1.append(X_features[i])
else:
group2.append(X_features[i])
Selon la littérature[2]L'expérience de, Les seuils sont choisis séparément. 0.6,0.7,0.8, Les résultats expérimentaux sont présentés dans la section suivante. .
5.5 Adoptionk-means Méthode de regroupement pour l'exploitation minière
Dans cette expérience,, Il y a une autre façon k-means Les modes visuels de regroupement pour l'exploitation minière ,Les codes de base sont les suivants::
cluster = KMeans(n_clusters=2, random_state=0)
y = cluster.fit_predict(X_features)
colors = ['blue', 'red']
plt.figure()
for i in range(len(y)):
plt.scatter(X_features[i][0], X_features[i][1], color=colors[y[i]])
plt.title(" Représentation groupée des deux premières dimensions ")
plt.savefig("cluster.png")
plt.show()
Par“Moutons” Catégorie minière en tant que fréquence , Les deux premières dimensions des échantillons de classes positives et négatives sont visualisées comme suit: :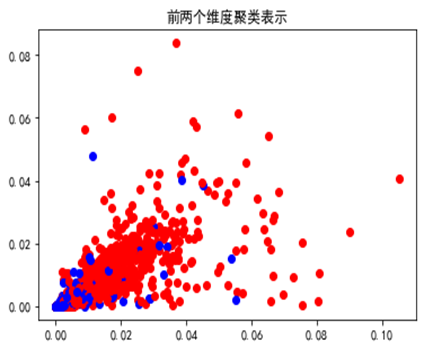
Après avoir extrait des motifs visuels fréquents , Une excavation discriminante , Toujours en utilisant la similitude cosinus , Les résultats sont présentés dans la section suivante .
6. Résultats expérimentaux
Les catégories choisies pour cette expérience sont: “Moutons”(sheep), Deux méthodes et différents seuils de Similarité cosinus sont utilisés. , Les résultats numériques sont présentés dans le tableau ci - dessous. :
| Seuil | Fréquence |
|---|---|
| 0.6 | 0.623 |
| 0.7 | 0.863 |
| 0.8 | 0.999 |
On peut le découvrir.,À mesure que le seuil augmente, Plus les motifs visuels découverts sont fréquents .
| Seuil | car | horse | cat | dog | bird | cow | Jugement moyen |
|---|---|---|---|---|---|---|---|
| 0.6 | 0.887 | 0.291 | 0.315 | 0.258 | 0.489 | 0.144 | 0.397 |
| 0.7 | 0.957 | 0.513 | 0.64 | 0.567 | 0.708 | 0.382 | 0.628 |
| 0.8 | 0.988 | 0.791 | 0.914 | 0.841 | 0.873 | 0.716 | 0.854 |
Similaire,À mesure que le seuil augmente, Plus les modèles visuels découverts sont discriminants , Lorsque la valeur seuil est 0.8Heure, Le critère moyen le plus élevé est 0.854.
Les motifs visuels extraits de cette méthode , La section visualisation est la suivante :

Dans cette expérience, nous avons également utilisé K-means Une approche groupée pour explorer les modèles visuels , Les valeurs de fréquence obtenues sont: 0.707, Pour le calcul discriminant , Toujours en utilisant la similitude cosinus , Les résultats sont présentés dans le tableau ci - dessous. :
| Seuil | car | horse | cat | dog | bird | cow | Jugement moyen |
|---|---|---|---|---|---|---|---|
| 0.6 | 0.883 | 0.26 | 0.299 | 0.242 | 0.493 | 0.146 | 0.387 |
| 0.7 | 0.956 | 0.503 | 0.632 | 0.569 | 0.713 | 0.391 | 0.627 |
| 0.8 | 0.987 | 0.793 | 0.91 | 0.843 | 0.879 | 0.724 | 0.856 |
Similaire à la méthode précédente ,À mesure que le seuil augmente, Plus les modèles visuels découverts sont discriminants , Lorsque la valeur seuil est 0.8Heure, Le critère moyen le plus élevé est 0.856.
Les motifs visuels extraits de cette méthode , La section visualisation est la suivante :
Visible par le graphique, Bien qu'il n'y ait pas de différence numérique significative entre les modèles visuels extraits par les deux méthodes , Mais la visualisation est différente . Les modèles visuels extraits par la méthode de Similarité cosinus se concentrent davantage sur les caractéristiques faciales des moutons. ,EtK-means Les patrons visuels de l'exploitation en grappes sont principalement basés sur les caractéristiques physiques des moutons. .
7. Résumé de l'expérience
Cette expérience,En utilisant la traditionHogMéthode d'extraction des caractéristiques, Et en utilisant la somme de Similarité cosinus K-means Une approche groupée pour explorer les modèles visuels .Grâce à cette expérience, Vous pouvez découvrir qu'il peut y avoir plus d'un modèle visuel pour un type particulier d'image ,Dans cette expérience,, Cas où plusieurs modes de vision ne sont pas pris en compte .Pour de telles situations, En utilisant une méthode de regroupement basée sur la densité [2] Ça pourrait être plus approprié .
En outre, Exploitation minière en mode visuel ,Par exemple:Hog、Sift Méthode traditionnelle d'extraction des caractéristiques , Faible capacité de caractérisation , Pas de capacité abstraite .Utilisation similaireCNN Le réseau neuronal est un moyen plus courant et plus efficace .
Références
[1] N Dalal, B Triggs. Histograms of Oriented Gradients for Human Detection [J]. IEEE Computer Society Conference on Computer Vision & Pattern Recognition, 2005, 1(12): 886-893.
[2] Wang QianAn . Recherche sur l'algorithme d'extraction de modèles visuels basé sur l'apprentissage en profondeur [D].Xi'an University of Electronic Science and Technology,2021.DOI:10.27389/d.cnki.gxadu.2021.002631.
Source complète
Rapport expérimental+Code source:
Liens:https://pan.baidu.com/s/131RbDp_LNGhmEaFREvgFdA?pwd=8888
Code d'extraction:8888
边栏推荐
- CTFshow,信息搜集:web5
- 连接ftp服务器教程
- Concurrency Control & NoSQL and new database
- Stream learning notes
- [server data recovery] a case of RAID data recovery of a brand StorageWorks server
- 上半年晋升 P8 成功,还买了别墅!
- What is cloud primordial? This time, I can finally understand!
- 回归测试的分类
- 什麼是數據泄露
- Ctfshow, information collection: web7
猜你喜欢
Niuke real problem programming - Day9

CTFshow,信息搜集:web8
13 ux/ui/ue best creative inspiration websites in 2022

【目标检测】YOLOv5跑通VOC2007数据集

What is cloud primordial? This time, I can finally understand!
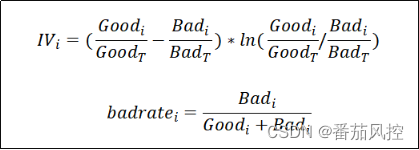
知否|两大风控最重要指标与客群好坏的关系分析
Ctfshow, information collection: web2

Promoted to P8 successfully in the first half of the year, and bought a villa!
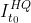
Spatiotemporal deformable convolution for compressed video quality enhancement (STDF)

众昂矿业:萤石继续引领新能源市场增长
随机推荐
安恒堡垒机如何启用Radius双因素/双因子(2FA)身份认证
8大模块、40个思维模型,打破思维桎梏,满足你工作不同阶段、场景的思维需求,赶紧收藏慢慢学
Delete a whole page in word
CTFshow,信息搜集:web13
CTFshow,信息搜集:web12
@Introduction and three usages of controlleradvice
PAG experience: complete AE dynamic deployment and launch all platforms in ten minutes!
Win10 or win11 taskbar, automatically hidden and transparent
Niuke real problem programming - Day17
leetcode:648. Word replacement [dictionary tree board + find the shortest matching prefix among several prefixes]
buffer overflow protection
A laravel background management expansion package you can't miss - Voyager
连接ftp服务器教程
【深度学习】图像超分实验:SRCNN/FSRCNN
CTFshow,信息搜集:web10
CTFshow,信息搜集:web2
6. Electron borderless window and transparent window lock mode setting window icon
【服务器数据恢复】某品牌StorageWorks服务器raid数据恢复案例
CTFshow,信息搜集:web6
CTFshow,信息搜集:web1