当前位置:网站首页>Spatiotemporal deformable convolution for compressed video quality enhancement (STDF)
Spatiotemporal deformable convolution for compressed video quality enhancement (STDF)
2022-07-07 14:48:00 【mytzs123】
Spatio-Temporal Deformable Convolution for Compressed Video Quality Enhancement
Abstract
In recent years , The deep learning method has achieved remarkable success in improving the quality of compressed video . In order to better explore time information , Existing methods usually estimate optical flow for temporal motion compensation . However , Because compressed video may be seriously distorted by various compression artifacts , Therefore, the estimated optical flow is often inaccurate and unreliable , This leads to ineffective quality enhancement . Besides , Optical flow estimation of continuous frames is usually carried out in pairs , This is high computational cost and low efficiency . In this paper , We propose a fast and effective method to enhance the quality of compressed video , By merging a new spatiotemporal deformable fusion (STDF) Scheme to gather time information . say concretely , The STDF Take the target frame and its adjacent reference frame as input , Jointly predict the offset field to deform the spatiotemporal sampling position of convolution . therefore , Deformable convolution in a single space-time (STDC) In the operation, the complementary information from the target frame and the reference frame is fused . A lot of experiments show that , Our method achieves the most advanced performance of compressed video quality enhancement in terms of accuracy and efficiency .
1 Introduction
Now , Video content has become the main part of digital network traffic , And it's still growing (Wien 2015). In order to transmit video with limited bandwidth , Video compression is crucial to significantly reduce the bit rate . However , Compression algorithm , Such as H.264/AVC(Wiegand wait forsomeone ,2003) and H.265/HEVC(Sullivan,Ohm and Wiegand 2013), Usually, various artifacts are introduced into compressed video , Especially at low bit rates . Pictured 1 Shown , Such artifacts may significantly degrade video quality , Lead to experience quality (QoE) falling . Distorted content in low-quality compressed video may also reduce subsequent visual tasks in low bandwidth applications ( For example, identification 、 testing 、 track ) Performance of (Galteri wait forsomeone ,2017 year ;Lu wait forsomeone ,2019 year ). therefore , Enhance the quality of compressed video (VQE) The research of is very important .

In the last few decades , People have done a lot of research on artifact removal or quality enhancement of a single compressed image . traditional method (Foi、Katkovink and Egiazarian 2007;Zhang wait forsomeone ,2013) Reduce artifacts by optimizing the transform coefficients of specific compression standards , Therefore, it is difficult to extend to other compression schemes . With convolution neural networks (CNN) What's new , be based on CNN Image quality enhancement method ( Dong et al ,2015; Tai et al ,2017; Zhang et al ,2017;2019) There have been . They usually learn nonlinear mapping , Direct regression of artifact free images from a large number of training data , So as to efficiently obtain impressive results . However , These methods cannot be directly extended to compressed video , Because they process frames independently , Therefore, time information cannot be used .
On the other hand , The research on quality enhancement of compressed video is still limited . Yang et al . Multi frame quality enhancement is proposed for the first time (MFQE 1.0) Method , To use time information for vector quantization . say concretely , Use the high-quality frame in the compressed video as the reference frame , Through a new multi frame CNN(MF-CNN) Help improve the quality of adjacent low-quality target frames . lately , An upgraded version is introduced MFQE 2.0(Guan wait forsomeone ,2019), To further improve MF-CNN The efficiency of , Achieve state-of-the-art performance . In order to gather information from the target frame and the reference frame , Two kinds of MFQE Methods all adopt the widely used time fusion scheme , This scheme adopts dense optical flow for motion compensation (Kappeler wait forsomeone ,2016;Caballero wait forsomeone ,2017;Xue wait forsomeone ,2017). However , This time fusion scheme may be suboptimal in the task of vector quantization environment . Compression artifacts may seriously distort the video content and destroy the pixel correspondence between frames , Therefore, the estimated optical flow is often inaccurate and unreliable , This leads to ineffective quality enhancement . Besides , Optical flow estimation needs to be repeated for different reference target frame pairs in a paired manner , This involves significantly increasing the computational cost to explore more reference frames .
In order to solve the above problems , We introduce a spatiotemporal deformable fusion for vector quantization environmental tasks (STDF) programme . say concretely , We propose to learn a new spatiotemporal deformable convolution (STDC) To gather time information , At the same time, avoid explicit optical flow estimation .STDC The main idea of is to adaptively deform the spatiotemporal sampling position of convolution , To capture the most relevant context and exclude noisy content , So as to improve the quality of the target frame . So , We use based on CNN To jointly model the correspondence between the target and the reference frame , Accordingly, these sampling positions are regressed in a single reasoning process . The main contributions of this paper are summarized as follows :
We propose an end-to-end CNN Of VQE Task method , This method combines a new STDF Scheme to aggregate time information ; We will propose through analysis and experiments STDF Compared with a priori fusion scheme , And proved its higher flexibility and robustness ; We are VQE The method was evaluated quantitatively and qualitatively on the benchmark data set , It turns out that , This method achieves the most advanced performance in terms of accuracy and efficiency .
2 Related Work
Image and Video Quality Enhancement: In the past decade , More and more works focus on the quality enhancement of compressed images . among , be based on CNN The end-to-end method of has achieved the most advanced performance in the near future . say concretely ,Dong Et al. First introduced a 4 layer AR-CNN To remove all kinds of JPEG Compression artifacts . later ,Zhang They have successfully learned a very deep DnCNN, A residual learning scheme is used for several image restoration tasks . lately ,Zhang Et al. Proposed a deeper network RNAN, It has residual nonlocal attention mechanism , Long dependencies between pixels can be captured , And a new image quality enhancement technology is established . These methods tend to use large cnn To capture the features in the image , This leads to a large number of calculations and parameters . On the other hand ,mfqe1.0 Take the lead in applying multiple frames CNN To use time information to enhance the quality of compressed video , Among them, high-quality frames are used to help enhance the quality of adjacent low-quality frames . In order to use long-distance time information ,Yang Et al. Later introduced an improved convolution length - Short term memory networks , For video quality enhancement . lately ,Guan And so forth MFQE2.0, To upgrade MFQE1.0 Several key components of , And has achieved the most advanced performance in terms of accuracy and speed .
Leveraging Temporal Information: In video related tasks , Utilizing complementary information across multiple frames is critical .Karpathy Et al. First introduced several fusion schemes based on convolution , Video classification based on spatio-temporal information (Karpathy wait forsomeone ,2014).Kappeler Et al. Later studied these fusion schemes for low-level visual tasks (Kappeler wait forsomeone ,2016), And based on total variation (TV) The optical flow estimation algorithm of compensates the motion between consecutive frames to improve the accuracy .Caballero Others further use CNN Instead of based on TV Traffic estimator , To achieve end-to-end training (Caballero wait forsomeone ,2017 year ). Since then , Temporal fusion with motion compensation has been widely used in various visual tasks ( Xue et al 2017; Yang et al 2018; Jin et al 2018; Guan et al 2019). However , These methods rely heavily on accurate optical flow , Due to general problems ( For example, occlusion 、 Big movement ) Or task specific issues ( For example, compress artifacts ), It is difficult to obtain accurate optical flow . To solve this problem , Work has been done to bypass explicit optical flow estimation .Niklaus、Mai and Liu Put forward AdaConv(Niklaus、Mai and Liu 2017), The convolution kernel is adaptively generated by implicitly using motion cues to interpolate video frames .Shi And so on ConvLSTM The Internet , To utilize context information from long-range adjacent frames (Shi wait forsomeone ,2015). In this work , We propose to combine motion cues with convolution , To effectively gather spatiotemporal information , This also omits the explicit estimation of optical flow
Deformable Convolution:Dai Et al. First proposed using learnable sampling offset to enhance regular convolution , Thus, complex geometric transformations are modeled for target detection . later , Some works extend it along the time range , Implicitly capture motion clues of video related applications , And achieved better performance than traditional methods . However , These methods perform deformable convolution in pairs , Therefore, time correspondence across multiple frames cannot be fully explored . In this work , We proposed STDC Consider a video clip together , Instead of dividing it into multiple reference target frame pairs , So as to make more effective use of context information .
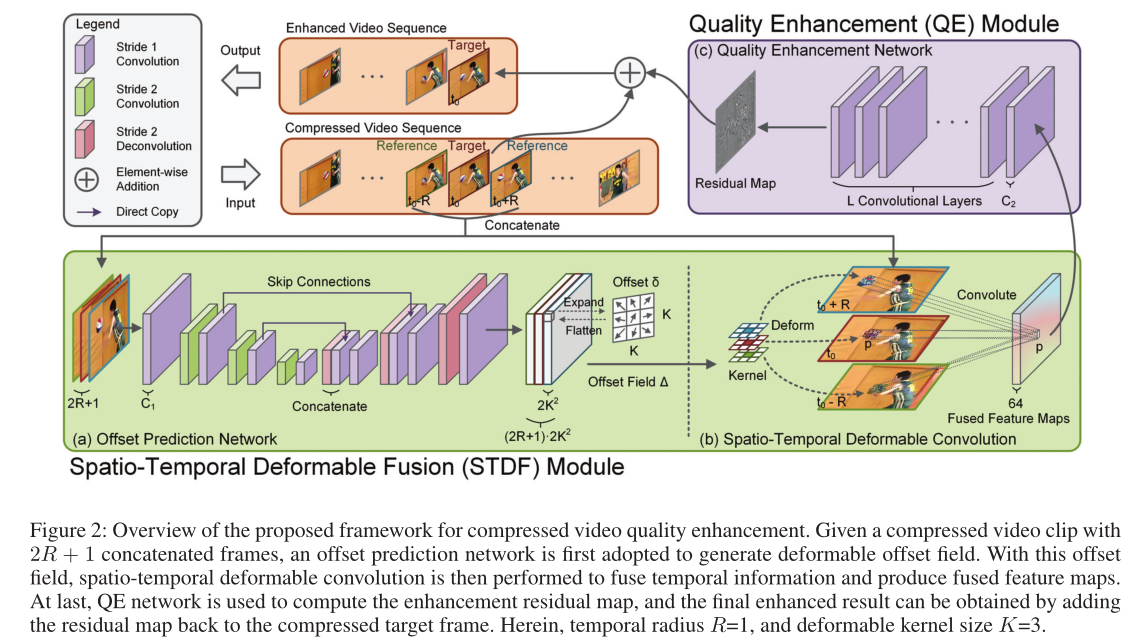
3 Proposed Method
3.1 Overview
Suppose the compressed video is distorted by compression artifacts , The goal of our method is to eliminate these artifacts , So as to improve video quality . say concretely , We compress each frame separately  stay
stay  Enhance when . In order to use time information , We will be back and forth R Frame as reference , To help improve each goal The quality of the . Enhancement results
Enhance when . In order to use time information , We will be back and forth R Frame as reference , To help improve each goal The quality of the . Enhancement results  It can be expressed as :
It can be expressed as :
chart 2 Shows the framework of our approach , The framework is composed of spatiotemporal deformable fusion (STDF) Module and quality enhancement (QE) Module composition .STDF The module takes the target frame and the reference frame as inputs , And the context information is fused by spatiotemporal deformable convolution , Deformable migration is adaptively generated by migration prediction network . then , Through fused feature mapping ,QE The module combines a complete convolution enhancement network to calculate the enhancement results . because STDF Module and QE Modules are convoluted , So we can train our unified framework in an end-to-end way .
3.2 STDF Module
Spatio-Temporal Deformable Convolution: For compressed video clips  The most direct time fusion scheme , Early fusion (EF), It can be expressed as multi-channel convolution directly applied to compressed frames , As shown below :
The most direct time fusion scheme , Early fusion (EF), It can be expressed as multi-channel convolution directly applied to compressed frames , As shown below :

among F Is the resulting feature mapping ,K Represents the size of the convolution kernel , Is the th of convolution kernel t Channels ,p Represents any spatial location ,pk Represents the regular sampling offset . for example ,pk∈ {(−1,−1),(−1,0),····,(1,1)} about K=3. Although efficient , but EF It is easy to introduce noise content , And reduce the performance of subsequent enhancements due to time movement , Pictured 3 Shown . suffer Dai And so on , To solve this problem , We introduce a new spatiotemporal deformable convolution (STDC) Algorithm , With additional learnable offsets
Is the th of convolution kernel t Channels ,p Represents any spatial location ,pk Represents the regular sampling offset . for example ,pk∈ {(−1,−1),(−1,0),····,(1,1)} about K=3. Although efficient , but EF It is easy to introduce noise content , And reduce the performance of subsequent enhancements due to time movement , Pictured 3 Shown . suffer Dai And so on , To solve this problem , We introduce a new spatiotemporal deformable convolution (STDC) Algorithm , With additional learnable offsets  To enhance the regular sampling offset :
To enhance the regular sampling offset :
![]()
It is worth noting that , Deformable offset δ(t、 p) It's location specific , That is, assigned to a space-time location (t,p) For each convolution window centered δ(t、 p) It's all unique . therefore , Spatial deformation and temporal dynamics in video clips can be modeled simultaneously , Pictured 3 Shown . Because the learnable offset can be fractions , So we follow Dai Et al. Applied differentiable bilinear interpolation to sampling subpixels 
In the past VQE The method is different , Explicit motion compensation is performed before fusion to reduce the influence of temporal motion ,STDC During fusion, motion cues are implicitly combined with position specific sampling . This leads to greater flexibility and robustness , Because the adjacent convolution windows can sample the content independently , Pictured 4 Shown .
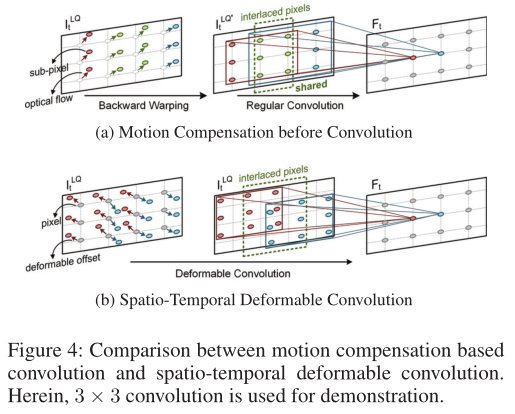
Joint Deformable Offset Prediction:
It is different from the optical flow estimation that only one reference frame pair is processed at a time , We propose a method that takes the whole clip into account , At the same time, the method of jointly predicting all deformable offsets . So , For all spatiotemporal positions in the video clip , We apply the offset prediction network 
Predict the offset field  Used for all spatiotemporal positions in video clips , Such as :
Used for all spatiotemporal positions in video clips , Such as :
![]()
Where frames are connected together as input . Because successive frames are highly correlated , Therefore, the offset prediction of one frame can benefit from other frames , Thus, the time information can be used more effectively than the pairwise scheme . Besides , Joint prediction is more efficient , Because all deformable offsets can be obtained in a single reasoning process .
Pictured 2-(a) Shown , We use based on U-Net Network of (Ronneberger、Fischer and Brox 2015) Make offset prediction , To expand the receptive field , To capture large temporal dynamics . In steps of 2 Convolution layer and deconvolution layer (Zeiler and Fergus 2014) Used for down sampling and up sampling respectively . For steps of 1 The convolution of layer , Use zero fill to maintain feature size . For the sake of simplicity , We set the number of convolution kernels of all convolutions to C1. Except for the last one, which is followed by linear activation to return to the offset field Δ, Correction linear unit (ReLU) Is the activation function of all layers . We don't use any normalization layer in the network .
3.3 QE Module
QE The main idea of the module is to fully mine the fusion feature mapping F Complementary information in , Thus, an enhanced target frame is generated . In order to use residual learning (Kim、Lee and Lee 2016), We first learn about nonlinear mapping  Enhance the residual with prediction
Enhance the residual with prediction
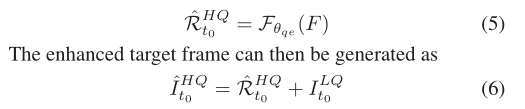
Pictured 2-(c) Shown , We pass another by step 1 Of L The convolution layer CNN To achieve . Except for the last floor , All layers have C2 Convolutional filter , And then there was ReLU Activate . The last convolution layer outputs enhanced residuals . This simple QE The network has no bell and whistle , Can obtain satisfactory enhancement effect .
3.4 Training Scheme
because STDF Module and QE Modules are completely convoluted , So it's differentiable , So we jointly optimize in an end-to-end way  and
and  . The total loss function L Set to enhance the target frame
. The total loss function L Set to enhance the target frame  And the original target frame
And the original target frame  The sum of the square errors between (SSE), As shown below :
The sum of the square errors between (SSE), As shown below :
![]()
Be careful , Since there is no deformable offset ground-truth, Learning of offset prediction network  Is completely unsupervised , Completely by the final loss L drive , This is different from previous work (Yang wait forsomeone 2018;Guan wait forsomeone 2019), These works include auxiliary loss to constrain optical flow estimation .
Is completely unsupervised , Completely by the final loss L drive , This is different from previous work (Yang wait forsomeone 2018;Guan wait forsomeone 2019), These works include auxiliary loss to constrain optical flow estimation .
4 Experiments
4.1 Datasets
follow MFQE 2.0(Guan wait forsomeone ,2019), We have two databases (Xiph.org) and VGEG(VGEG)) Collected 130 Uncompressed video with different resolutions and contents , among 106 For training , The rest is used for verification . In order to test , We use a joint collaboration team from video coding (Ohm wait forsomeone ,2012) Data set of , It includes 18 Uncompressed video . These test videos are widely used for video quality evaluation , About per video 450 frame . We use the latest H.265\/HEVC Reference software HM16.5 2 At low delay P(LDP) Compress all the above videos under configuration , Same as before (Guan wait forsomeone ,2019). Compression is in 4 Different quantitative parameters (QP), namely 22、27、32、37, To evaluate the performance under different compression levels .
4.2 Implementation Details
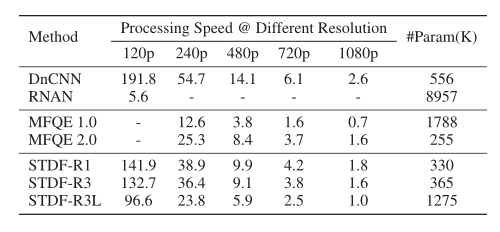
This method is based on Pytork frame , Reference resources MMDetection hold-all (Chen wait forsomeone ,2019) Realize deformable convolution . For training , We randomly crop from the original video and the corresponding compressed video 64×64 Clips as training samples . Further use data to enhance ( That is, rotate or flip ) To make better use of these training samples . We use Adam optimizer(Kingma and Ba 2014) Train all models ,β1=0.9,β2=0.999 and  =1e−8、 Learning rate initially set to 10−4 And keep it throughout the training process . We start from scratch as 4 individual QP Training 4 A model . For evaluation , Same as before , We are only in YUV /YCbCr In the space Y passageway ( That is, the brightness component ) Application quality enhancement . We use incremental peak signal-to-noise ratio (ΔPSNR) And structural similarity (ΔSSIM)(Wang wait forsomeone ,2004) To evaluate quality enhancement performance , This measures the improvement of enhanced video over compressed video . We also evaluated the complexity of quality enhancement methods in terms of parameters and computational costs .
=1e−8、 Learning rate initially set to 10−4 And keep it throughout the training process . We start from scratch as 4 individual QP Training 4 A model . For evaluation , Same as before , We are only in YUV /YCbCr In the space Y passageway ( That is, the brightness component ) Application quality enhancement . We use incremental peak signal-to-noise ratio (ΔPSNR) And structural similarity (ΔSSIM)(Wang wait forsomeone ,2004) To evaluate quality enhancement performance , This measures the improvement of enhanced video over compressed video . We also evaluated the complexity of quality enhancement methods in terms of parameters and computational costs .
4.3 Comparison to State-of-the-arts
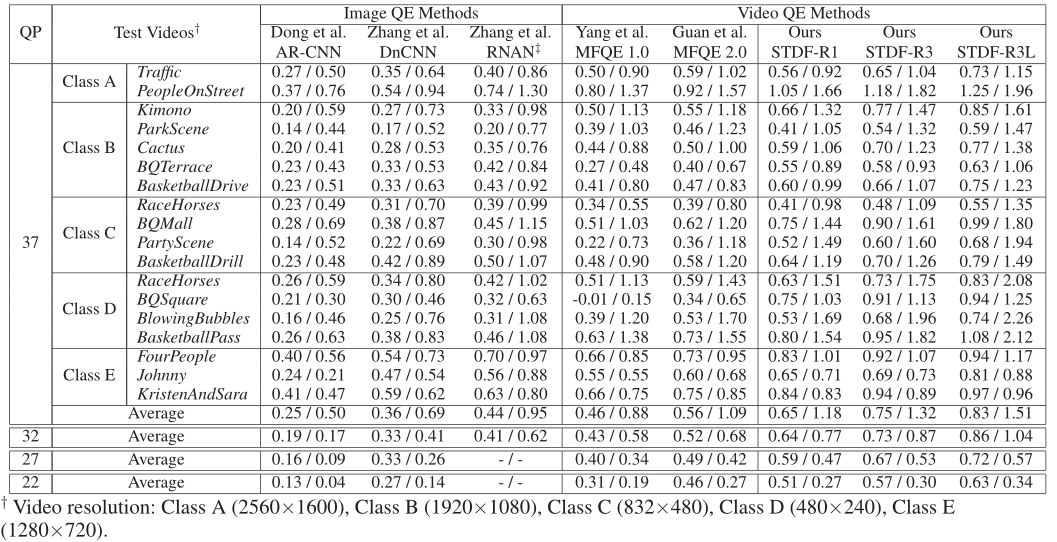
We will present the method with the most advanced images / Video quality enhancement methods 、AR-CNN(Dong wait forsomeone ,2015)、DnCNN(Zhang wait forsomeone ,2017)、RNAN(Zhang) And so on ,2019),MFQE 1.0( Yang et al ,2018) and MFQE 2.0( Guan et al ,2019). For a fair comparison , All image quality enhancement methods are retrained on our training set . The results of video quality enhancement methods are cited from (Guan wait forsomeone ,2019). We evaluated three variants of the method with different configurations ( For more information , Please refer to the previous section ).1) STDF-R1,R=1,C1=32,C2=48,L=8.2) STDF-R3,R=3,C1=32,C2=48,L=8.3) STDF-R3L,R=3,C1=64,C2=64,L=16.
Quantitative Results: surface 1 And table 2 The quantitative results of accuracy and model complexity are given respectively . Can be observed , Our approach is 18 The average of test videos is always better than that of all comparison methods ΔPSNR and ΔSSIM. More specifically , stay QP37, our STDF-R1 be better than mfqe2.0 For most videos , And it has faster processing speed and similar parameters . We noticed that , our STDF-R1 Just use the previous and subsequent frames as a reference , Unlike mfqe2.0 Use high-quality adjacent frames , Thus, the computational cost of searching those high-quality frames in advance is saved . With the radius of time R Add to 3, our STDF-R3 Try to use more time information , So as to further improve the average ΔPSNR by 0.75db, Than mfqe2.0 high 34%, Than mfqe1.0 high 63%, Than RNAN high 70%. Because of the proposed STDF High efficiency of the module ,STDF-R3 The overall speed of is still higher than mfqe2.0 fast . Besides , After expansion STDF-R3L Of ΔPSNR achieve 0.83db, It shows that this method still has room for improvement . Similar results can be found in ΔSSIM And other things QP.
Qualitative Results: chart 5 Provides 4 Qualitative results of test videos . It can be seen that , Compressed frame due to various compression artifacts (ringing in Kimono and blurring in F ourPeople) And serious distortion , Although image quality enhancement methods can appropriately reduce these artifacts , But the generated frames often become too blurred and lack details . On the other hand , The video quality enhancement method achieves better enhancement effect with the help of the reference frame . And MFQE 2.0 comparison , our STDF The model is more robust to compression artifacts , It can better explore spatiotemporal information , So as to better restore the structural details .
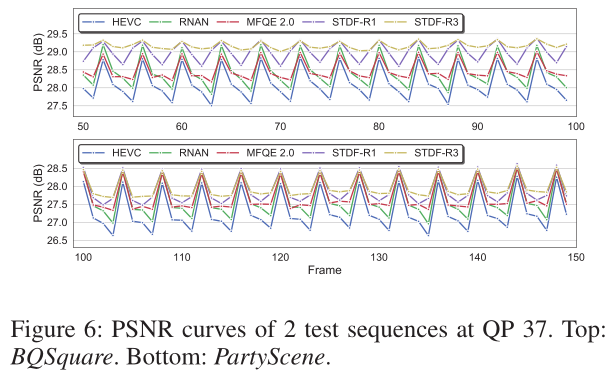
Quality Fluctuation: According to observation , There are significant quality fluctuations in compressed video (Guan wait forsomeone ,2019 year ), This can seriously undermine time consistency and reduce QoE. In order to study how our method can help achieve this , We are in the picture 6 It's drawn in 2 Peak signal-to-noise ratio curve of sequences . It can be seen that , our STDF-R1 The model can effectively enhance most low-quality frames , And mitigate quality fluctuations . By taking the time radius R Expand to 3, our STDF-R3 The model can utilize adjacent high-quality frames , So as to obtain better performance than other comparison methods .
4.4 Analysis and Discussions
In this section , We conducted ablation studies and further analysis . For a fair comparison , We only performed ablation experiments on the fusion scheme , And will QE The network is fixed to L=8,C2=48, All models are trained according to the same protocol and rules ΔPSNR/ΔSSIM stay qp37 From the B Class to E All test videos of class are averaged . Use in 480p Floating point calculation on video (FLOPs) To evaluate and calculate the cost .
Effectiveness of STDF :
In order to prove STDF Effectiveness of time fusion , We compare it with the previous two fusion schemes , Early fusion (EF) And early motion compensation (EFMC). say concretely , about EFMC programme , We chose two based on CNN Optical flow estimator for motion compensation .1) EF_STMC,MFQE 2.0 Motion compensation of light space transformer used in (STMC) The Internet .2) EF_FlowNetS,FlowNet Larger networks used in . We are at different time radii R Next training model to evaluate scalability .
chart 7 The comparison results are shown . We can observe that , All reference frame methods are better than single frame baseline, The validity of using time information is proved . When R=1 when ,STDF stay ΔPSNR Performance is significantly better than EF and EFMC And the amount of calculation is quite , explain STDF Can make better use of time information . With R Further increase in , Interestingly ΔEF-STMC The peak signal-to-noise ratio of decreases ,EF-FlowNetS The peak signal-to-noise ratio of is only slightly improved . We think the reason is twofold . First , It is difficult for optical flow estimators to capture motion with long intervals , This leads to the invalid use of additional reference frames . secondly , Training samples with different exercise intensity may confuse the optical flow estimator , Especially for those with relatively low capacity EF-STMC. by comparison , The proposed STDF Consider the entire video segment , Force the offset prediction network to learn different intensity movements at the same time . therefore ,STDF Of ΔPSNR With R Continuously improve with the increase of . Besides , With R An increase in ,STDF The calculation of increases faster than EF-STMC and EF-FlowNetS Much slower , explain STDF More efficient .
Effectiveness of STDC:
The proposed STDC It has location specific sampling characteristics , It has higher flexibility and robustness than the traditional motion compensation fusion method . To test this , We introduced a variant of the method , use EFMC Replace STDC. To be specific ,EFMC The optical flow estimator in is modified from the offset prediction network , The output layer of the network is modified to be used for flow estimation instead of offset prediction . According to the table 3, Although with EFMC Instead of STDC Time parameter and FLOPs A slight improvement , But on the whole, R=1 and R=3 At the time of the ΔPSNR Fall separately 0.04 dB and 0.08 dB. This proves the proposed STDC The effectiveness of the
Effectiveness of Joint Offset Prediction:
A joint prediction method is proposed to generate STDC Deformable offset of . To prove its effectiveness , We replace it with a pairwise prediction scheme . To be specific , We modify the input layer and output layer of the offset prediction network , Make offset prediction for each reference target pair respectively . From the table 3 We can see that ΔPSNR and ΔSSIM The joint prediction scheme using two-way scheme decreases at the same time , Greatly improved FLOPs, It shows that the joint prediction scheme can make better use of time information , It has high efficiency .
5 Conclusion
We propose a fast and effective method to enhance the quality of compressed video , This method combines a new spatiotemporal deformable convolution to gather the time information of continuous frames . On the benchmark dataset , Our method is superior to previous methods in accuracy and efficiency . We believe that , The proposed spatiotemporal deformable convolution can also be extended to other low-level visual tasks related to video , Including super resolution 、 Recovery and frame synthesis , To achieve efficient time information fusion
边栏推荐
- Instructions d'utilisation de la trousse de développement du module d'acquisition d'accord du testeur mictr01
- In the field of software engineering, we have been doing scientific research for ten years!
- Infinite innovation in cloud "vision" | the 2022 Alibaba cloud live summit was officially launched
- GAN发明者Ian Goodfellow正式加入DeepMind,任Research Scientist
- 小程序目录结构
- PG基础篇--逻辑结构管理(锁机制--表锁)
- ES日志报错赏析-trying to create too many buckets
- Demis Hassabis谈AlphaFold未来目标
- JS image to Base64
- EfficientNet模型的完整细节
猜你喜欢

Five pain points for big companies to open source
Because the employee set the password to "123456", amd stolen 450gb data?

Webrtc audio anti weak network technology (Part 1)

leetcode:648. 单词替换【字典树板子 + 寻找若干前缀中的最短符合前缀】

How bad can a programmer be? Nima, they are all talents
Notes de l'imprimante substance: paramètres pour les affichages Multi - écrans et multi - Résolutions
【历史上的今天】7 月 7 日:C# 发布;Chrome OS 问世;《仙剑奇侠传》发行

MicTR01 Tester 振弦采集模塊開發套件使用說明
时空可变形卷积用于压缩视频质量增强(STDF)

Navigation - are you sure you want to take a look at such an easy-to-use navigation framework?
随机推荐
Equipment failure prediction machine failure early warning mechanical equipment vibration monitoring machine failure early warning CNC vibration wireless monitoring equipment abnormal early warning
Decrypt the three dimensional design of the game
KITTI数据集简介与使用
Electronic remote error
Leetcode - Sword finger offer 05 Replace spaces
低代码平台中的数据连接方式(下)
Data connection mode in low code platform (Part 2)
2022年13个UX/UI/UE最佳创意灵感网站
C 6.0 language specification approved
Hangdian oj2092 integer solution
How bad can a programmer be? Nima, they are all talents
Oracle Linux 9.0 正式发布
MLGO:Google AI发布工业级编译器优化机器学习框架
半小时『直播连麦搭建』动手实战,大学生技术岗位简历加分项get!
6、Electron无边框窗口和透明窗口 锁定模式 设置窗口图标
Cascading update with Oracle trigger
Simple use of websocket
A laravel background management expansion package you can't miss - Voyager
LeetCode 648. Word replacement
6. Electron borderless window and transparent window lock mode setting window icon