当前位置:网站首页>CSDN问答标签技能树(二) —— 效果优化
CSDN问答标签技能树(二) —— 效果优化
2022-07-06 09:11:00 【Alexxinlu】
目录
系列文章
- CSDN问答标签技能树(一) —— 基本框架的构建
- CSDN问答标签技能树(二) —— 效果优化
- CSDN问答标签技能树(三) —— Python技能树
- CSDN问答标签技能树(四) —— Java技能树
- CSDN问答标签技能树(五) —— 云原生技能树
团队博客: CSDN AI小组
1. 问题背景
本篇文章承接上一篇文章《CSDN问答标签技能树(一) —— 基本框架的构建》。简而言之,是对CSDN问答模块中的各个领域标签,构建一个完整的知识体系,并将问答模块中的内容、用户等,与知识体系进行关联,最终形成一个包含异构结点的只是图谱,更好地为下游NLP任务提供资源基础。
本篇文章主要介绍技能树结构的优化,以及问答内容与技能树匹配的效果优化。
2. 技能树优化
本章主要包括两个部分,一个是技能树结构的优化,另一个是问答内容与技能树匹配的效果优化。
技能树已经扩充到16种语言,但是由于效果较差,故当前重点挑选了2种在CSDN问答模块较流行的编程语言 Python 和 Java,以及现在比较流行的一个概念 云原生 ,该概念包含多个标签,是范围较大的一个知识领域。
2.1 技能树结构优化
技能树的结构主要有两个要求,一个是知识的覆盖度要全,另一个是需要有等级体系。
2.1.1 知识覆盖率
知识的覆盖率在上一篇文章2.1节中已经提到过,主要通过爬取书籍的目录以及学习论坛的目录实现技能树的构建。
这一次更新中,又爬取了更多的书籍目录,用于扩充知识的覆盖率。在后续也会不断增量扩充更多的知识,并且也会考虑增加用户编辑的功能,让用户来编辑和新增知识点。
2.1.2 等级体系
知识是有初中高等级之分的,以python语言为例,大致有如下所示的初步知识骨架:
python
├── 初阶
│ ├── 预备知识
│ ├── 基础语法
│ ├── 进阶语法
│ └── 面向对象编程
├── 中阶
│ ├── 基本技能
│ ├── Web应用开发
│ ├── 网络爬虫
│ └── 桌面应用开发
└── 高阶
├── 科学计算基础软件包NumPy
├── 结构化数据分析工具Pandas
├── 绘图库Matplotlib
├── 科学计算工具包SciPy
├── 机器学习工具包Scikit-learn
├── 深度学习
├── 计算机视觉
└── 自然语言处理
为了让知识体系有等级结构,本文的构思是:首先将构建一个如上图所示的知识骨架,再将获取的所有书籍或学习论坛的目录进行拆分和整合,挂到骨架上相应的结点上。例如:对于一本 python入门 的书籍,将其目录进行拆分并挂到骨架中 初阶 相应的结点上,如果骨架未覆盖相关知识点,则新增结点,如果新增的知识点存在冗余,则无须挂到骨架上。
在具体实施阶段,当前的策略还较为简单,只是通过人工指定的方式,将目录挂到相应的等级结点上,如下所示:
初阶 --> using_python
初阶 --> tutorial_python
初阶 --> reference_python
初阶 --> library_python
初阶 --> liaoxuefeng_python
初阶 --> Python基础教程_第3版
初阶 --> Python编程快速上手_让繁琐工作自动化_第2版
初阶 --> 流畅的Python
初阶 --> Python编程_从入门到实践_第2版
初阶 --> Python从入门到精通
初阶 --> Python_Cookbook_第3版
中阶 --> Python进阶编程
中阶 --> Python核心编程_第3版
中阶 --> Python极客项目编程
中阶 --> Flask_Web开发_基于Python的Web应用开发实战_第2版
中阶 --> 网络爬虫 --> Python3网络爬虫开发实战
高阶 --> Python3高级教程_第3版
高阶 --> Python数据分析基础
高阶 --> 利用Python进行数据分析_原书第2版
高阶 --> Python高级数据分析:机器学习、深度学习和NLP实例
高阶 --> 计算机视觉 --> 实用卷积神经网络:运用Python实现高级深度学习模型
后续将考虑借鉴 决策树 算法构建树的思路,来构建一棵冗余度更低,结构更加合理的技能树。
2.2 匹配算法效果优化
在构建好技能树之后,需要将问答模块中已采纳的问题,基于匹配算法,将其挂到相应的结点上去,作为该结点的数据资源。对于用户新的提问,基于匹配算法,将最相关结点上的已采纳问题推荐给用户,并进一步推荐用户学习技能树上与该结点相邻的相关知识。
2.2.1 匹配算法的优化
在上一篇文章2.4节中,只使用了技能树的叶子结点和提问标题进行匹配,这种方式存在以下缺陷:
- 叶子结点的祖先结点也包含了很多有用的信息,只使用叶子结点将丢失祖先的信息;
- 有些用户的提问并没有具体到描述很详细的叶子结点,可能是概述一大类的非叶子结点;
- 英文关键字在匹配的时候时候起着至关重要的作用,需重点考虑。
故针对以上问题,匹配算法进行了下述的改进:
- 获取技能树中所有节点的路径集合。路径指的是根结点到当前结点的路径;
- 计算提问标题与所有路径的相似度。由于路径中的最后一个结点为要匹配的结点,且层数越大的结点描述更加精确,信息量也更大。故在计算相似度的时候,根据路径中结点的层号来赋予结点的权重,层号越大,权重越大;
- 匹配时,加大英文关键字的权重。
此外,由于路径有长又短,上述算法会更加倾向于匹配较短的路径,较长的路径得分会偏低,故最终的得分,需要基于路径的长度进行归一化。具体的代码实现如下所示:
def get_most_sim_node_paths_to_leaves(self, all_paths_to_leaves, node_id_seg_dict, query, lang):
'''计算用户提问标题与技能树中所有路径的得分 '''
# 第一层(编程语言名)和第二层结点(子目录名)无意义
max_path_len = max([len(m_path) for m_path in all_paths_to_leaves]) - 2
# 对query进行分词
query_seg = word_segmentation(query)
# 去掉当前编程语言的名字
lang_syn_name_list = lang_std_syn_dict[lang]
query_seg = [m_word for m_word in query_seg if m_word not in lang_syn_name_list]
result = {
'score': 0, 'path_to_leaf': []}
for ori_path_to_leaf in all_paths_to_leaves:
# 第一层(编程语言名)和第二层结点(子目录名)无意义
path_to_leaf = ori_path_to_leaf[2:]
score_list = []
num_nodes = len(path_to_leaf)
if num_nodes == 0:
continue
for m_node_id in path_to_leaf:
# 计算两个词序列的相似度
sim_score, _, _ = cal_simlarity(node_id_seg_dict[m_node_id], query_seg, lcs_ratio_threshold=0, alpha=0)
score_list.append(sim_score)
# 在根节点到叶子结点的路径上,去除尾部得分连续为0的,到叶子结点的子路径
score_list.reverse()
non_zero_index = 0
for m_index, sim_score in enumerate(score_list):
if sim_score != 0:
non_zero_index = m_index
break
score_list = score_list[non_zero_index :]
score_list.reverse()
# 如果存在交并比为1的结点,则直接返回根节点到该结点的路径
value_one_flag = False
value_one_index_list = [m_index for m_index, sim_score in enumerate(score_list) if sim_score == 1]
if len(value_one_index_list) != 0:
value_one_index = value_one_index_list[-1]
score_list = score_list[: value_one_index + 1]
value_one_flag = True
# 根据层号赋予结点的权重,同时考虑路径的长度
num_nodes = len(score_list)
final_score = 0.0
denominator = (1.0 + num_nodes) * num_nodes / 2
for m_index, m_score in enumerate(score_list):
floor_score = (m_index + 1) / denominator
final_score += m_score * floor_score
path_len_score = num_nodes / max_path_len
final_score *= path_len_score
if final_score > result['score']:
result['score'] = final_score
result['path_to_leaf'] = ori_path_to_leaf[: num_nodes + 2]
if value_one_flag:
result['score'] = final_score
result['path_to_leaf'] = ori_path_to_leaf[: num_nodes + 2]
break
return result
2.2.2 预处理优化
本任务主要涉及到结点描述与用户提问的匹配,而停用词的存在,以及关键词的质量,都会影响匹配的效果,故需要针对任务的具体特点,进行合适的预处理操作,只保留高质量的关键词,进而提升匹配的效果。
此外,用户提问口语化比较严重,而技能树中结点的描述较为书面化,匹配的时候只要一方的停用词去除干净即可,故本文只分析技能树中结点的描述,这大大降低了预处理操作的工作量。
停用词过滤
之前只使用了网上几个公认的停用词词典进行停用词过滤,但是对于具体领域的任务还是不够。在经过对数据的分析之后,发现一些特定词性的词,对任务基本没有任何作用,主要包括以下词性:pos 中文名 c 连词 e 叹词 h 前缀 k 后缀 m 数词 o 拟声词 p 介词 r 代词 u 助词 w 标点符号 x 字符串 y 语气词 z 状态词 p.s. 以上述首字母开头的词性都算
对于既包含有效词,又包含停用词的词性,通过统计+人工筛选的方法,找出高频的停用词,加入到停用词词典中,共新增159个停用词,如下表所示:
第1列 第2列 第3列 第4列 中 项中 新手 现代 更 不到 新人 近期 快 类时 菜狗 当前 指 萌新 菜鸟 过期 里 求解 菜鸡 需要 前 有配 兄弟 使用 帮 刚入 高手 三大 找 这是 自学 停用词 手 前辈 谢谢 — 坑 一串 感谢 哪几个 时 请求 仁兄 找不到 加 刚刚 作业 萌新刚 学 至少 疯了 刚入坑 刚 麻烦 老师 同一个 问 解答 牛人 下个月 谢 急! 这题 帮帮忙 下 急求 题目 看不懂 上 救救 源码 啊啊啊 后 舅舅 做题 在线等 内 救急 之间 太难了 外 救命 容易 家人们 间 求求 烦琐 兄弟们 新 球球 庞大 小老弟 旧 求助 合适 这道题 大 求教 神秘 这个题 小 跪求 离奇 考试题 先 大神 完整 一道题 将 大佬 最好 源代码 未 指教 重新 编程题 不 指点 简单 转换成 最 小白 复杂 题怎么写 仍 孩子 正确 题怎么做 可 帮忙 错误 求源代码 是 帮帮 直接 haha 有 哥哥 间接 课程设计 想要 姐姐 常用 从根本上 中将 妹妹 所有 一切都是 初学 小妹 忽略 臭名昭彰 打烊 小弟 更加 独一无二 几个 大哥 一定 基于词性的bigram词组
对于分词器错误切分的词,合并bigram词组,且bigram表义更明确,能提升匹配的正确率。具体而言,根据词性,对相邻的词进行拼接,形成更大的词组单元。通过观察数据,获得以下常见的需要拼接的词性组合:first pos second pos d q d v d n f q h n h v h a n k n n n q n s p.s. 以上述首字母开头的词性都算
2.2.3 增加其他类结点
有些用户的提问已经超出了当前领域,或者难以在技能树上进行穷举,故另外增加了一个其他类的结点,用于匹配该类问题。例如对于 Python 标签,其他类结点,又细分为以下三个类别:
others
├── 其他类别标签问题
├── 应用类问题
├── 第三方包问题
其他类问题的判断主要通过规则实现,对与上述三类问题,规则如下:
- 其他类别标签问题
不包含当前领域标签,却包含其他领域标签的提问标题。
- 应用类问题
re.compile(r'((如何|怎么).*?(计算|实现|制作)|练习|题目)')
- 第三方包问题
re.compile(r'(工具包|(?:第三方|[a-z]+?)库|py(?!thon)[a-z0-9]+|安装[a-z0-9]+|[a-z0-9]+的安装)')
2.3 匹配效果
在进行以上的优化之后,具体的效果提升如下所示,使用的评价标准是正确率(Accuracy)。
| 领域标签 | baseline | now |
|---|---|---|
| Python | 54% | 78% |
| Java | 57% | 82% |
| 云原生 | - | - |
p.s. 由于云原生的有效数据较少,故还未构建数据集,并进行效果测试。
3. 总结与下一步计划
技能树已经支持16棵,本文重点优化了 Python、Java、云原生 三个领域标签的技能树,主要包括技能树结构的优化,以及匹配算法的优化。
下一步计划:
- 技能树结构进一步升级:借鉴 决策树 算法构建树的思路,来构建一棵冗余度更低,结构更加合理的技能树;
- 云原生数据资源的构建;
- 扩充其他类型的数据资源。当前只使用了问答的数据资源,后续将考虑使用CSDN其他模块的异构数据资源,包括:博客、课程、视频、专栏、用户收藏夹等。
相关链接
P.S.
该系列文章会持续进行更新。希望NLP等领域的同仁、老师和专家能够提供宝贵的建议,谢谢!
边栏推荐
- Global and Chinese market of transfer switches 2022-2028: Research Report on technology, participants, trends, market size and share
- Discriminant model: a discriminant model creation framework log linear model
- CSDN-NLP:基于技能树和弱监督学习的博文难度等级分类 (一)
- MySQL combat optimization expert 03 uses a data update process to preliminarily understand the architecture design of InnoDB storage engine
- MySQL 29 other database tuning strategies
- MySQL25-索引的创建与设计原则
- A necessary soft skill for Software Test Engineers: structured thinking
- Water and rain condition monitoring reservoir water and rain condition online monitoring
- [paper reading notes] - cryptographic analysis of short RSA secret exponents
- Good blog good material record link
猜你喜欢
Implement context manager through with
软件测试工程师必备之软技能:结构化思维
Implement sending post request with form data parameter
CSDN-NLP:基于技能树和弱监督学习的博文难度等级分类 (一)
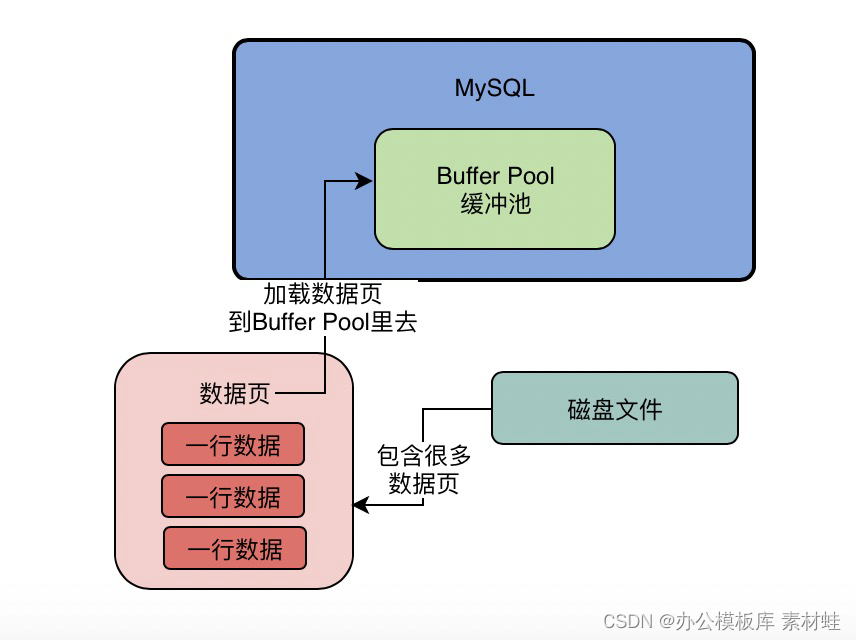
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
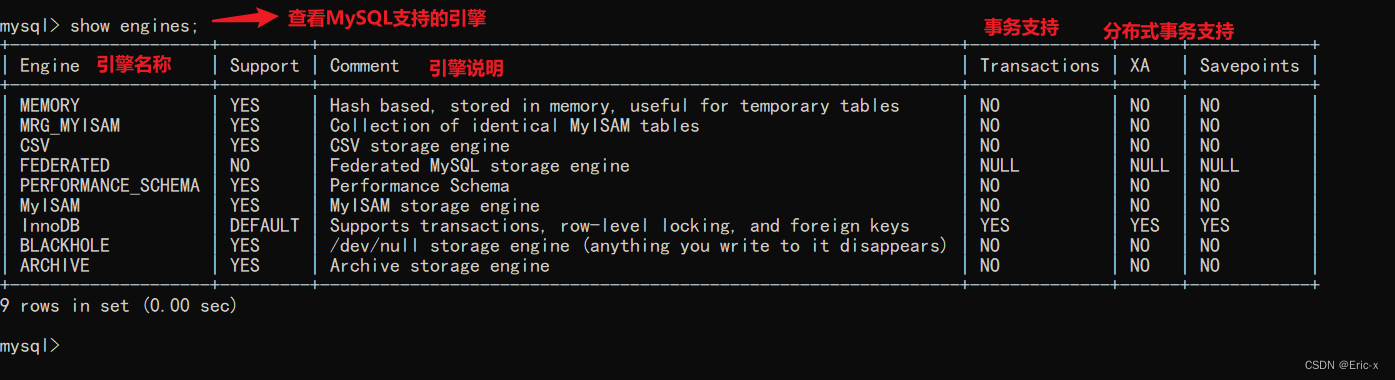
The underlying logical architecture of MySQL
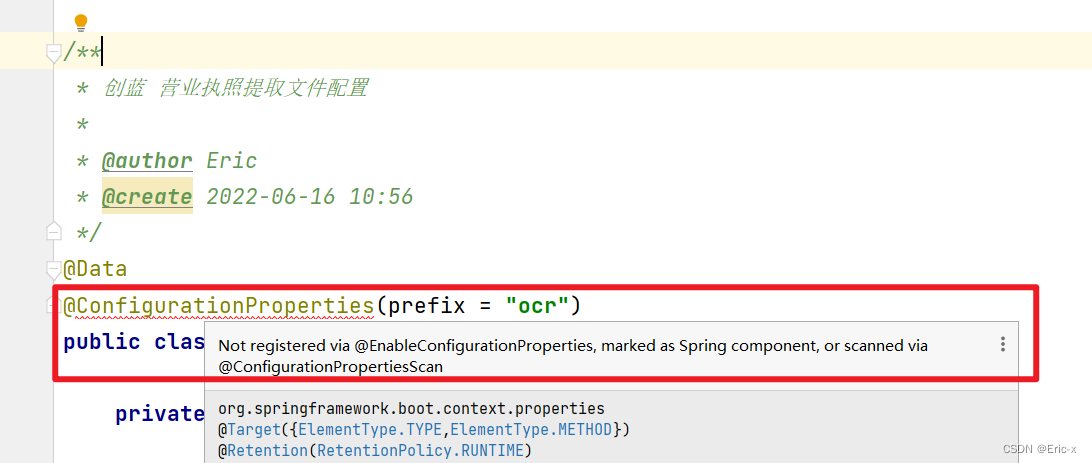
Not registered via @enableconfigurationproperties, marked (@configurationproperties use)
Unicode decodeerror: 'UTF-8' codec can't decode byte 0xd0 in position 0 successfully resolved
A necessary soft skill for Software Test Engineers: structured thinking
Mysql23 storage engine
随机推荐
MySQL20-MySQL的数据目录
评估方法的优缺点
How to find the number of daffodils with simple and rough methods in C language
Software test engineer development planning route
[leectode 2022.2.13] maximum number of "balloons"
text 文本数据增强方法 data argumentation
Water and rain condition monitoring reservoir water and rain condition online monitoring
实现以form-data参数发送post请求
MySQL的存储引擎
MySQL combat optimization expert 03 uses a data update process to preliminarily understand the architecture design of InnoDB storage engine
Global and Chinese market of operational amplifier 2022-2028: Research Report on technology, participants, trends, market size and share
CSDN-NLP:基于技能树和弱监督学习的博文难度等级分类 (一)
MySQL combat optimization expert 07 production experience: how to conduct 360 degree dead angle pressure test on the database in the production environment?
Mysql32 lock
February 13, 2022 - Maximum subarray and
MySQL combat optimization expert 06 production experience: how does the production environment database of Internet companies conduct performance testing?
MySQL combat optimization expert 04 uses the execution process of update statements in the InnoDB storage engine to talk about what binlog is?
[programmers' English growth path] English learning serial one (verb general tense)
ByteTrack: Multi-Object Tracking by Associating Every Detection Box 论文阅读笔记()
Database middleware_ MYCAT summary