当前位置:网站首页>MySQL 29 other database tuning strategies
MySQL 29 other database tuning strategies
2022-07-06 10:29:00 【Protect our party a Yao】
One . Database tuning measures
1.1. The goal of tuning
- As far as possible Save system resources , So that the system can provide a greater load of services .( More throughput ).
- Reasonable structural design and parameter adjustment , To improve user operation Speed of response .( Faster response time ).
- Reduce system bottlenecks , Improve MySQL The overall performance of the database .
1.2. How to locate the tuning problem
How to make sure ? In general , There are several ways :
- User feedback ( The main )
- Log analysis ( The main )
- Server resource usage monitoring
- Database internal condition monitoring
- Other
In addition to active session monitoring , We can also Business 、 Lock wait Wait for monitoring , These can help us to have a more comprehensive understanding of the running state of the database .
1.3. Dimensions and steps of tuning
The object we need to tune is the whole database management system , It includes more than SQL Inquire about , It also includes the deployment and configuration of the database 、 Architecture, etc . From this perspective , The dimension of our thinking is not limited to SQL Optimization is on . Through the following steps, we sort out :
The first 1 Step : Choose the right DBMS
The first 2 Step : Optimize table design
The first 3 Step : Optimizing logical queries
The first 4 Step : Optimize physical queries
Physical query optimization is after determining the logical query optimization , Using physical optimization technology ( Such as index, etc ), Various possible access paths are estimated by calculating the cost model , So as to find the lowest cost among the execution methods as the execution plan . In this section , The key point we need to master is the creation and use of index .
The first 5 Step : Use Redis or Memcached As caching
Apart from being able to SQL In addition to optimizing itself , We can also ask foreign aid to improve the efficiency of inquiry .
Because the data is stored in the database , We need to extract data from the database layer and put it into memory for business logic operations , When the number of users increases , If you query data frequently , It will consume a lot of resources of the database . If we put commonly used data directly into memory , It will greatly improve the efficiency of query .
Key value storage database can help us solve this problem .
The commonly used key value storage databases are Redis and Memcached, They can store data in memory .
The first 6 Step : Library level optimization
- Read / write separation
- Data fragmentation
But it should be noted that , Splitting improves database performance while , It will also increase the cost of maintenance and use .
Two . Optimize MySQL The server
2.1. Optimize server hardware
The hardware performance of the server directly determines MySQL Database performance . The performance bottleneck of hardware directly determines MySQL The speed and efficiency of the database . Improve hardware configuration for performance bottlenecks , Can improve MySQL Database query 、 The speed of updates .
(1) Configure large memory
(2) Configure a high-speed disk system
(3) Reasonable distribution of disks I/O
(4) Configure multiprocessors
2.2. Optimize MySQL Parameters of
- innodb_buffer_pool_size : This parameter is Mysql One of the most important parameters of the database , Express InnoDB Type of Maximum cache size of tables and indexes . It's not just caching Index data , And cache The data table . The bigger this is , The faster the query will be . But this value is too large to affect the performance of the operating system .
- key_buffer_size : Express Size of index buffer . The index buffer is all Thread sharing . Increasing the index buffer can get a better index ( For all reading and rewriting ). Of course , This value is not the greater the better , Its size depends on the size of memory . If this value is too large , It will cause the operating system to change pages frequently , It also reduces system performance . For memory in 4GB This parameter can be set to 256M or 384M .
- table_cache : Express Number of tables opened at the same time . The bigger this is , The more tables you can open at the same time . The larger the physical memory , The larger the setting . The default is 2402, Transfer to 512-1024 The best . This value is not the greater the better , Because too many tables open at the same time will affect the performance of the operating system .
- query_cache_size : Express Query buffer size . It can be done by MySQL Console observation , If Qcache_lowmem_prunes It's worth a lot , It indicates that insufficient buffer often occurs , We need to increase Query_cache_size Value ; If Qcache_hits It's worth a lot , It shows that query buffer is used very frequently , If the value is small, it will affect the efficiency , Then consider not querying the cache ;Qcache_free_blocks, If the value is very large , It indicates that there are many fragments in the buffer .MySQL8.0 After that . This parameter requires and query_cache_type In combination with .
- query_cache_type The value of is 0 when , All queries do not use the query cache . however query_cache_type=0 It doesn't lead to MySQL Release query_cache_size Configured cache memory .
- When query_cache_type=1 when , All queries will use the query cache , Unless... Is specified in the query statement SQL_NO_CACHE , Such as SELECT SQL_NO_CACHE * FROM tbl_name.
- When query_cache_type=2 when , Use... Only in query statements SQL_CACHE keyword , Queries will use the query cache . Using query cache can improve the speed of query , This method is only applicable to the case where there are few modification operations and the same query operations are often performed .
- sort_buffer_size : Represent each The size of the buffer allocated by the thread that needs to be sorted . Increasing the value of this parameter can improve ORDER BY or GROUP BY Speed of operation . The default value is 2 097 144 byte ( about 2MB). For memory in 4GB The recommended settings for the left and right servers are 6-8M, If there is 100 A connection , The total size of the actual allocated sort buffer is 100 × 6= 600MB.
- oin_buffer_size = 8M : Express The size of the buffer that can be used by the federated query operation , and sort_buffer_size equally , The allocated memory corresponding to this parameter is also exclusive to each connection .
- read_buffer_size : Express The size of the buffer allocated for each table scanned when each thread scans continuously ( byte ) . This buffer is needed when the thread reads records continuously from the table .SET SESSION read_buffer_size=n You can set the value of this parameter temporarily . The default is 64K, It can be set to 4M.
- innodb_flush_log_at_trx_commit : Express When to write buffer data to log file , And write the log file to disk . This parameter is for innoDB The engine is very important . This parameter has 3 It's worth , Respectively 0、1 and 2. The default value for this parameter is 1. The value is 0 when , Express Per second 1 Time Write data to the log file and write the log file to disk . Of every business commit It will not trigger any of the previous operations . This mode is the fastest , But it's not safe ,mysqld The crash of the process will result in the loss of all transaction data in the last second . The value is 1 when , Express Every time a transaction is committed Write data to log file and write log file to disk for synchronization . This mode is the safest , But it's also the slowest way . Because every time a transaction is committed or an instruction outside a transaction needs to write the log to (flush) Hard disk . The value is 2 when , Express Every time a transaction is committed Write data to log file , every other 1 second Write log files to disk . This mode is faster , Is better than 0 Security , Only if the operating system crashes or the system is powered down , All transaction data can be lost in the last second .
- nnodb_log_buffer_size : This is a InnoDB Storage engine Buffer used by transaction log . To improve performance , Also write the information first Innodb Log Buffer in , When satisfied innodb_flush_log_trx_commit The corresponding conditions set by the parameter ( Or the log buffer is full ) after , Will write the log to the file ( Or sync to disk ) in .
- max_connections : Express Allow connections to MySQL The maximum number of databases , The default value is 151 . If the state variable connection_errors_max_connections Not zero , And it keeps growing , It means that there are continuous connection requests failed due to the maximum number of database connections , It is possible to consider increasing max_connections Value . stay Linux Under the platform , Good performance server , Support 500-1000 A connection is not difficult , You need to evaluate settings based on server performance . The number of connections Not the bigger the better , Because these connections waste memory resources . Too many connections can lead to MySQL Server dead .
- ack_log : be used for control MySQL monitor TCP The size of the backlog request stack set at port . If MySql The number of connections reached max_connections when , New requests will be stored in the stack , To wait for a connection to release resources , The number of stacks is back_log, If the number of waiting connections exceeds back_log, Will not be granted connection resources , Will be an error .5.6.6 Before version, the default value was 50 , Later versions default to 50 +(max_connections / 5), about Linux The system recommended setting is less than 512 The integer of , But not more than 900. If you need a database to handle a large number of connection requests in a short time , You can consider increasing it appropriately back_log Value .
- thread_cache_size : The size of the number of threads cached in the thread pool , Cache the current thread when the client disconnects , When a new connection request is received, it responds quickly without creating a new thread . This can greatly improve the efficiency of creating connections, especially for applications that use short connections . Then, in order to improve the performance, you can increase the value of this parameter . The default is 60,
- It can be set to pass the following MySQL Adjust the size of the thread pool according to the status value :120.

When Threads_cached less and less , but Threads_connected Never lower , And Threads_created Keep rising , May be increased appropriately thread_cache_size Size .
wait_timeout : Appoint The maximum connection time of a request , about 4GB Left and right memory servers can be set to 5-10.
interactive_timeout : Indicates the number of seconds the server waits for action before closing the connection .
Here is a copy of my.cnf Reference configuration for :
[mysqld]
port = 3306 serverid = 1 socket = /tmp/mysql.sock skip-locking # avoid MySQL External locking of , Reduce
Error probability enhances stability . skip-name-resolve # prohibit MySQL For external connections DNS analysis , Use this option
Items can be eliminated MySQL Conduct DNS Time of resolution . But we need to pay attention , If this option is turned on , Then all remote host connections are authorized
All use IP Address , otherwise MySQL Connection requests will not be processed properly ! back_log = 384
key_buffer_size = 256M max_allowed_packet = 4M thread_stack = 256K
table_cache = 128K sort_buffer_size = 6M read_buffer_size = 4M
read_rnd_buffer_size=16M join_buffer_size = 8M myisam_sort_buffer_size =
64M table_cache = 512 thread_cache_size = 64 query_cache_size = 64M
tmp_table_size = 256M max_connections = 768 max_connect_errors = 10000000
wait_timeout = 10 thread_concurrency = 8 # The value of this parameter is server logic CPU Number *2, In Ben
In the example , The server has 2 Astrophysics CPU, And every physics CPU And support H.T hyper-threading , So the actual value is 4*2=8 skip-
networking # Turn this option on to turn it off completely MySQL Of TCP/IP How to connect , If WEB The server is connected remotely
Mode of access MySQL Do not turn on the database server ! Otherwise, you will not be able to connect properly ! table_cache=1024
innodb_additional_mem_pool_size=4M # The default is 2M innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=2M # The default is 1M innodb_thread_concurrency=8 # Your server CPU
How many is set to how many . It is recommended to use the default value of 8 tmp_table_size=64M # The default is 16M, Transfer to 64-256 Most hang
thread_cache_size=120 query_cache_size=32M
Many situations still need specific analysis !
3、 ... and . Optimize database structure
3.1. Split table : Separation of hot and cold data
give an example 1: members members surface Store member login authentication information , There are many fields in this table , Such as id、 full name 、 password 、 Address 、 Telephone 、 Personal description field . Where address 、 Telephone 、 Fields such as personal description are not commonly used , These uncommon fields can be broken down into another table . Name this watch members_detail, Table has member_id、address、telephone、description Etc . In this way, the membership table is divided into two tables , Respectively members surface and members_detail surface .
To create these two tables SQL The statement is as follows :
CREATE TABLE members (
id int(11) NOT NULL AUTO_INCREMENT,
username varchar(50) DEFAULT NULL,
password varchar(50) DEFAULT NULL,
last_login_time datetime DEFAULT NULL,
last_login_ip varchar(100) DEFAULT NULL,
PRIMARY KEY(Id)
);
CREATE TABLE members_detail (
Member_id int(11) NOT NULL DEFAULT 0,
address varchar(255) DEFAULT NULL,
telephone varchar(255) DEFAULT NULL,
description text
);
If you need to query the basic information or detailed information of members , Then you can use the member's id To query . If necessary, the basic information and detailed information of members will be displayed at the same time , Then you can put members Table and members_detail Table for joint query , The query statement is as follows :
SELECT * FROM members LEFT JOIN members_detail on members.id =
members_detail.member_id;
Through this decomposition, the query efficiency of the table can be improved . For tables with many fields and some fields are not used frequently , The performance of the database can be optimized through this decomposition .
3.2. Add middle table
give an example 1: Student information sheet and Class table Of SQL The statement is as follows :
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Now there is a module that needs to often query with student name (name)、 Class name of the student (className)、 Student class monitor (monitor) Student information . You can create one based on this situation temp_student surface .temp_student The student name is stored in the table (stu_name)、 Class name of the student (className) And the student class monitor (monitor) Information . The statement to create the table is as follows :
CREATE TABLE `temp_student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stu_name` INT NOT NULL ,
`className` VARCHAR(20) DEFAULT NULL,
`monitor` INT(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Next , Query relevant information from student information table and class table and store it in temporary table :
insert into temp_student(stu_name,className,monitor)
select s.name,c.className,c.monitor
from student as s,class as c
where s.classId = c.id
in the future , Can be directly from temp_student Query student name in the table 、 Class name and class monitor , Instead of doing joint queries every time . This can improve the query speed of the database .
3.3. Add redundant fields
When designing database tables, we should follow the rules of normal form theory as far as possible , Minimize redundant fields , Make the database design look elegant 、 grace . however , Adding redundant fields reasonably can improve the query speed .
The more normalized the table is , The more relationships between tables , The more you need to join queries . Especially when there is a large amount of data , And when you need to connect frequently , To improve efficiency , We can also consider adding redundant fields to reduce connections .
3.4. Optimize data types
situation 1: Optimize integer type data .
If you encounter an integer type field, you can use INT type . The reason for this is ,INT Type data has a large enough value range , Don't worry about the problem that the data exceeds the value range . At the beginning of the project , First, ensure the stability of the system , It is possible to design field types in this way . But when there is a lot of data , Definition of data type , To a large extent, it will affect the overall execution efficiency of the system .
about Nonnegative type The data of ( Such as the increase ID、 integer IP) Come on , Use unsigned integers first UNSIGNED To store . Because unsigned versus signed , The same number of bytes , The range of stored values is larger . Such as tinyint The sign is -128-127, No sign is 0-255, Double the storage space .
situation 2: You can use either text type or integer type fields , To choose to use an integer type . Compared with text type data , Large integers often occupy Less storage space , therefore , When accessing and comparing , Can take up less memory space . therefore , Where both are available , Try to use integer types , This can improve the efficiency of query . Such as : take IP Convert address to integer data .
situation 3: Avoid using TEXT、BLOB data type .
situation 4: Avoid using ENUM type .
situation 5: Use TIMESTAMP Storage time .
situation 6: use DECIMAL Instead of FLOAT and DOUBLE Store precise floating point numbers .
All in all , When you encounter a project with a large amount of data , Be sure to fully understand the business needs , Reasonably optimize data types , Only in this way can we give full play to the efficiency of resources , Optimize the system .
3.5. Optimize the speed of inserting records
- MyISAM The engine's table :
① Disable index
② Disable uniqueness check
③ Use batch insert
④ Use LOAD DATA INFILE Bulk import - InnoDB The engine's table
① Disable uniqueness check
② Disable foreign key checking
③ Disable auto submit
3.6. Use non empty constraints
When designing fields , If business permits , It is recommended to use non null constraints as much as possible
3.7. Analysis of the table 、 Checklist and optimization table
3.7.1. Analysis of the table
MySQL Provided in ANALYZE TABLE Statement analysis table ,ANALYZE TABLE The basic syntax of the statement is as follows :
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[,tbl_name]...
default ,MySQL The service will ANALYZE TABLE The sentence reads binlog in , So that in the master-slave architecture , The slave service can synchronize data . You can add parameters LOCAL perhaps NO_WRITE_TO_BINLOG Cancel writing statement to binlog in .
Use ANALYZE TABLE In the process of analyzing the table , The database system will automatically add a to the table Read only lock . During the analysis , Only the records in the table can be read , Records cannot be updated and inserted .ANALYZE TABLE Statements can analyze InnoDB and MyISAM Type of watch , But it doesn't work on views .
ANALYZE TABLE The statistical results after analysis will reflect cardinality Value , This value counts the number of non duplicate values in the column where a key is located in the table . The closer the value is to the total number of rows in the table , When the table join query or index query , The more priority the optimizer chooses to use . That is, the index column cardinality The greater the difference between the value of and the total number of data in the table , Even if the index is used as the query condition , The smaller the probability that the storage engine will use when actually querying . The following is an example to verify .cardinality Can pass SHOW INDEX FROM Table name view .
3.7.2. Checklist
MySQL Can be used in CHECK TABLE Statement to check the table .CHECK TABLE Statement can check InnoDB and MyISAM Whether there is an error in the table of type .CHECK TABLE Statement will also add... To the table during execution Read only lock .
about MyISAM Type of watch ,CHECK TABLE Statement also updates keyword Statistics . and ,CHECK TABLE You can also check the view for errors , For example, the table referenced in the view definition no longer exists . The basic syntax of the statement is as follows :
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
among ,tbl_name Is the name of the table ;option Parameters have 5 A value of , Namely QUICK、FAST、MEDIUM、EXTENDED and CHANGED. The meaning of each option is :
- QUICK : No scanning , Don't check for wrong connections .
- FAST : Only check tables that are not properly closed .
- CHANGED : Only check the tables that have been changed since the last check and those that have not been closed correctly .
- MEDIUM : Scan line , To verify that the deleted connection is valid . You can also calculate the keyword checksums for each row , And use the calculated checksum to verify this .
- EXTENDED : Conduct a comprehensive keyword search for all keywords in each line . This ensures that the table is 100% coincident , But it takes longer .
option Only right MyISAM The type of watch is valid , Yes InnoDB Invalid table of type .
This statement may produce multiple rows of information for the checked table . The last line has a status Msg_type value ,Msg_text Usually it is OK. If you don't get OK, It usually needs to be repaired ; yes OK The instruction sheet is up to date . The table is already up to date , This means that the storage engine does not have to check this table .
3.7.3. Optimization table
The way 1:OPTIMIZE TABLE
MySQL Use in OPTIMIZE TABLE Statement to optimize the table . however ,OPTILMIZE TABLE Statement can only optimize VARCHAR 、 BLOB or TEXT Type field . A table uses the data types of these fields , If already Delete A large part of the data in the table , Or a table with variable length rows ( contain VARCHAR、BLOB or TEXT List of columns ) A lot of to update , You should use OPTIMIZE TABLE To reuse unused space , And sort out the data files debris .
OPTIMIZE TABLE The statement of InnoDB and MyISAM All tables of type are valid . The statement will also add... To the table during execution Read only lock .
OPTILMIZE TABLE The basic syntax of the statement is as follows :
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
LOCAL | NO_WRITE_TO_BINLOG The meaning of the keyword is the same as that of the analysis table , All specify not to write binary log .
completion of enforcement ,Msg_text Show
‘numysql.SYS_APP_USER’, ‘optimize’, ‘note’, ‘Table does not support optimize, doing recreate +
analyze instead’
The reason is... On my server MySQL yes InnoDB Storage engine .
Has it been optimized or not ? Official website !
https://dev.mysql.com/doc/refman/8.0/en/optimize-table.html
stay MyISAM in , Is to analyze this table first , Then I will sort out the relevant MySQL datafile, Then recycle unused space ; stay InnoDB in , Recycling space is simply through Alter table Organize space . During optimization ,MySQL Will create a temporary table , After optimization, the original table will be deleted , Then the temporary table rename Become the original table .
explain : In most settings , There is no need to run OPTIMIZE TABLE. Even if a large number of changes have been made to variable length rows
new , And it doesn't need to run very often , Once a week or Once a month that will do , And you just need to Specific tables function .
3.8. Summary
These methods have both advantages and disadvantages . such as :
- Change data type , Save storage space while , You should consider that the data cannot exceed the value range ;
- When adding redundant fields , Don't forget to ensure data consistency ;
- Split the big watch , It also means that your query will add new connections , This increases the additional overhead and the cost of operation and maintenance .
therefore , You must balance it with the actual business needs .
Four . Big watch optimization
4.1. Limit the scope of the query
It is forbidden to query statements without any restrictions on the data range . such as : When users are querying the order history , We can control it within a month ;
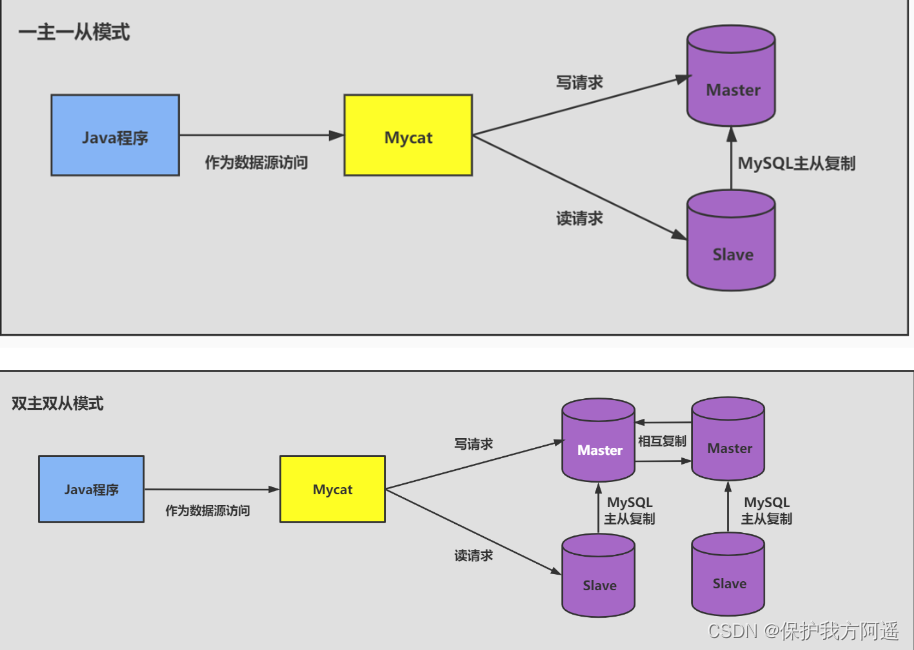
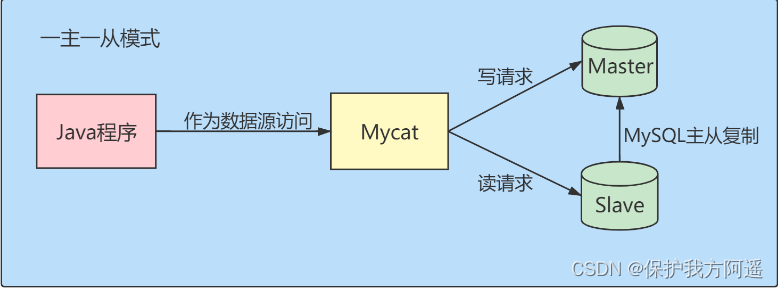
4.2. read / Write separation
Classic database splitting scheme , The main database is responsible for writing , Read from the library .
- One master and one slave mode :
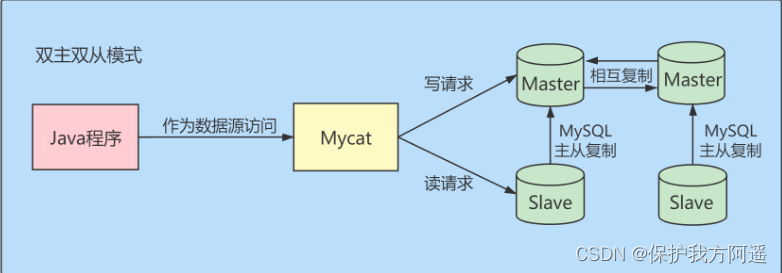
- Dual master dual slave mode :
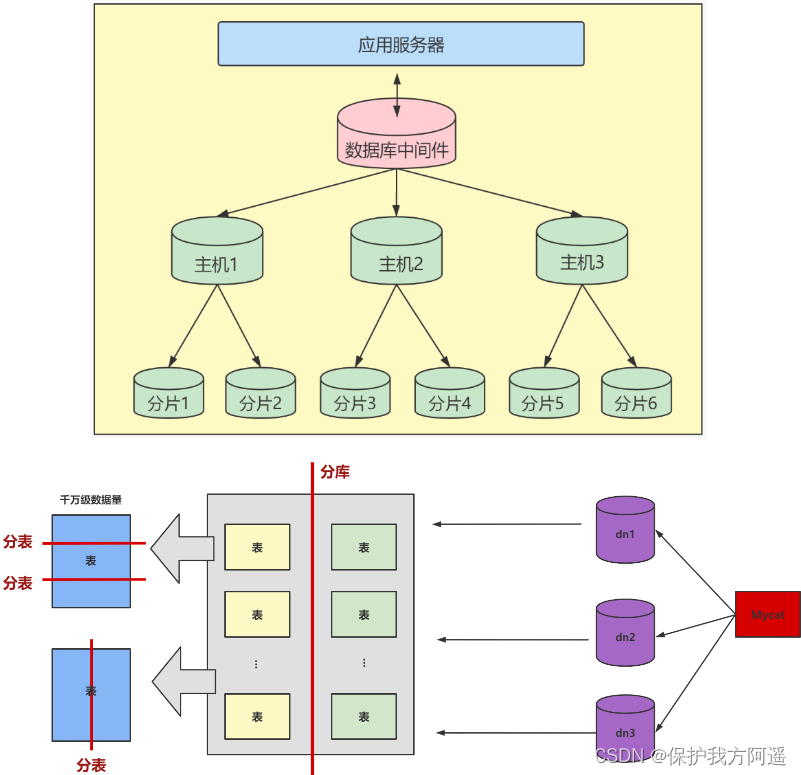
4.3. Split Vertically
When the data level reaches Tens of millions When above , Sometimes we need to cut a database into multiple copies , Put it on different database servers , Reduce access pressure to a single database server .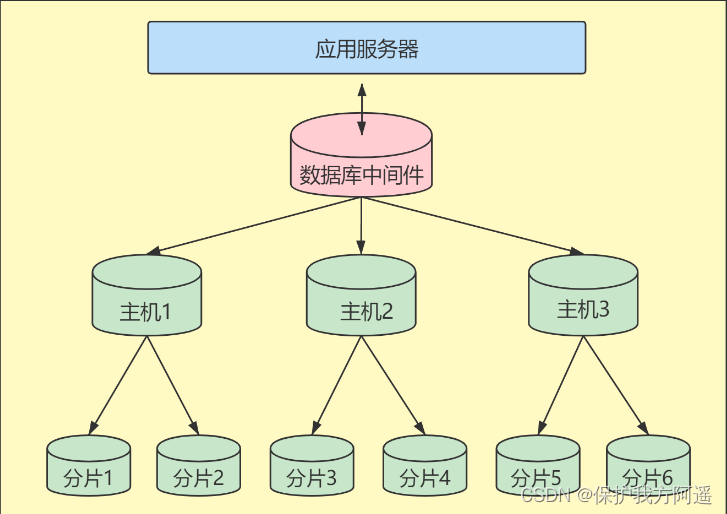
Advantages of vertical splitting : Can make column data smaller , Reduce the number of reads in the query Block Count , Reduce I/O frequency . Besides , Vertical partitioning simplifies the structure of tables , Easy to maintain .
Disadvantages of vertical splitting : There will be redundancy in the primary key , Need to manage redundant columns , And will cause JOIN operation . Besides , Vertical splitting makes transactions more complex .
4.4. Horizontal split
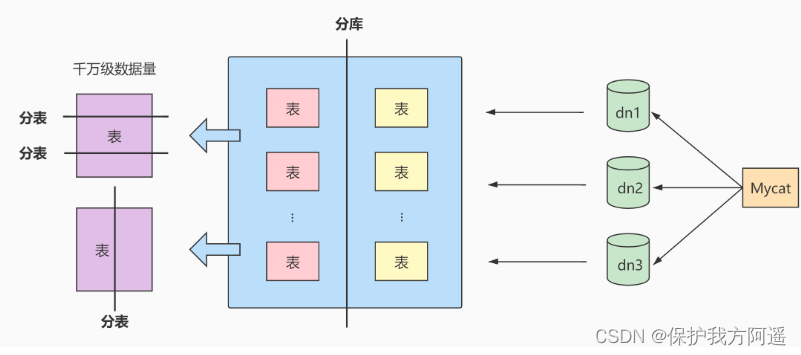
Here are two common solutions for database fragmentation :
- Client agent : Sharding logic at the application end , Packaged in jar In bag , By modifying or encapsulating JDBC Layer to achieve . Dangdang. Com Sharding-JDBC 、 Ali's TDDL It's two more commonly used implementations .
- Middleware agent : Add a proxy layer between application and data . Fragment logic is maintained in middleware services . Mycat 、360 Of Atlas、 Netease's DDB And so on are the implementation of this architecture .
5、 ... and . Other tuning strategies
5.1. Server statement timeout processing
stay MySQL 8.0 Can be set in Server statement timeout limit , The unit can reach Millisecond level . When the interrupted execution statement exceeds the set number of milliseconds , The server will terminate transactions or connections that have little impact on the query , Then report the error to the client .
Set the limit of server statement timeout , You can set the system variable MAX_EXECUTION_TIME To achieve . By default ,MAX_EXECUTION_TIME The value of is 0, There's no time limit for delegates .
SET GLOBAL MAX_EXECUTION_TIME=2000;
SET SESSION MAX_EXECUTION_TIME=2000; # Specify the number of users in this session SELECT Statement timeout
5.2. Create a global common tablespace
5.3. MySQL 8.0 New characteristics : Hide the help of index for tuning
边栏推荐
- ① BOKE
- Chrome浏览器端跨域不能访问问题处理办法
- Jar runs with error no main manifest attribute
- 15 medical registration system_ [appointment registration]
- Transactions have four characteristics?
- MySQL实战优化高手02 为了执行SQL语句,你知道MySQL用了什么样的架构设计吗?
- jar运行报错no main manifest attribute
- Write your own CPU Chapter 10 - learning notes
- Routes and resources of AI
- Super detailed steps to implement Wechat public number H5 Message push
猜你喜欢
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?

jar运行报错no main manifest attribute

Sichuan cloud education and double teacher model
PyTorch RNN 实战案例_MNIST手写字体识别
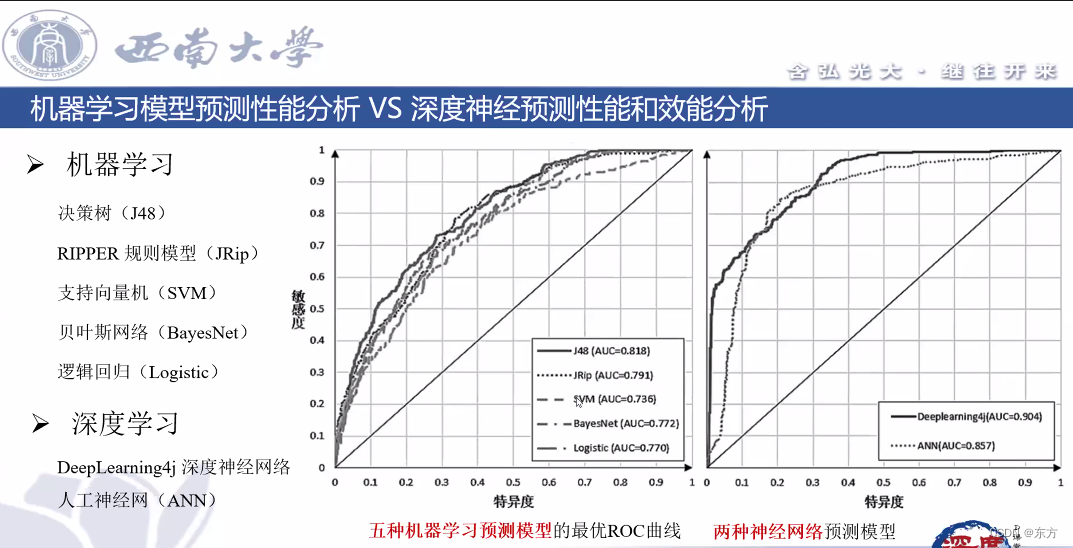
Southwest University: Hu hang - Analysis on learning behavior and learning effect
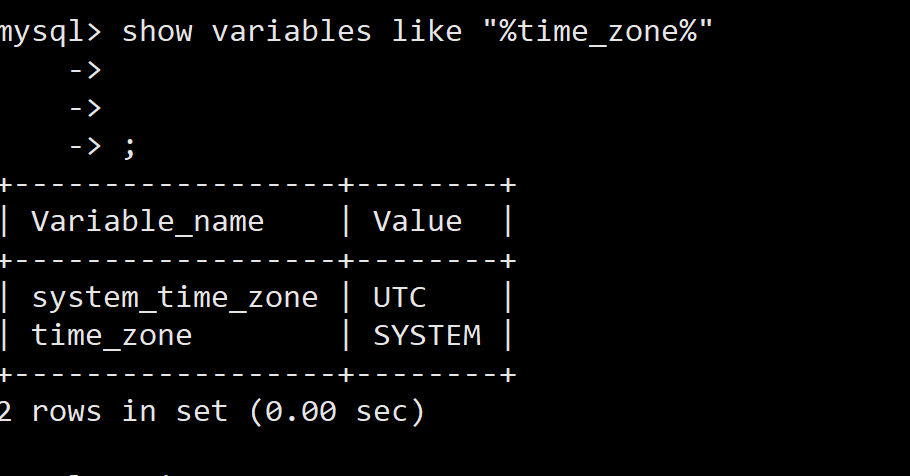
Docker MySQL solves time zone problems
![[unity] simulate jelly effect (with collision) -- tutorial on using jellysprites plug-in](/img/1f/93a6c6150ec2b002f667a882569b7b.jpg)
[unity] simulate jelly effect (with collision) -- tutorial on using jellysprites plug-in
Routes and resources of AI
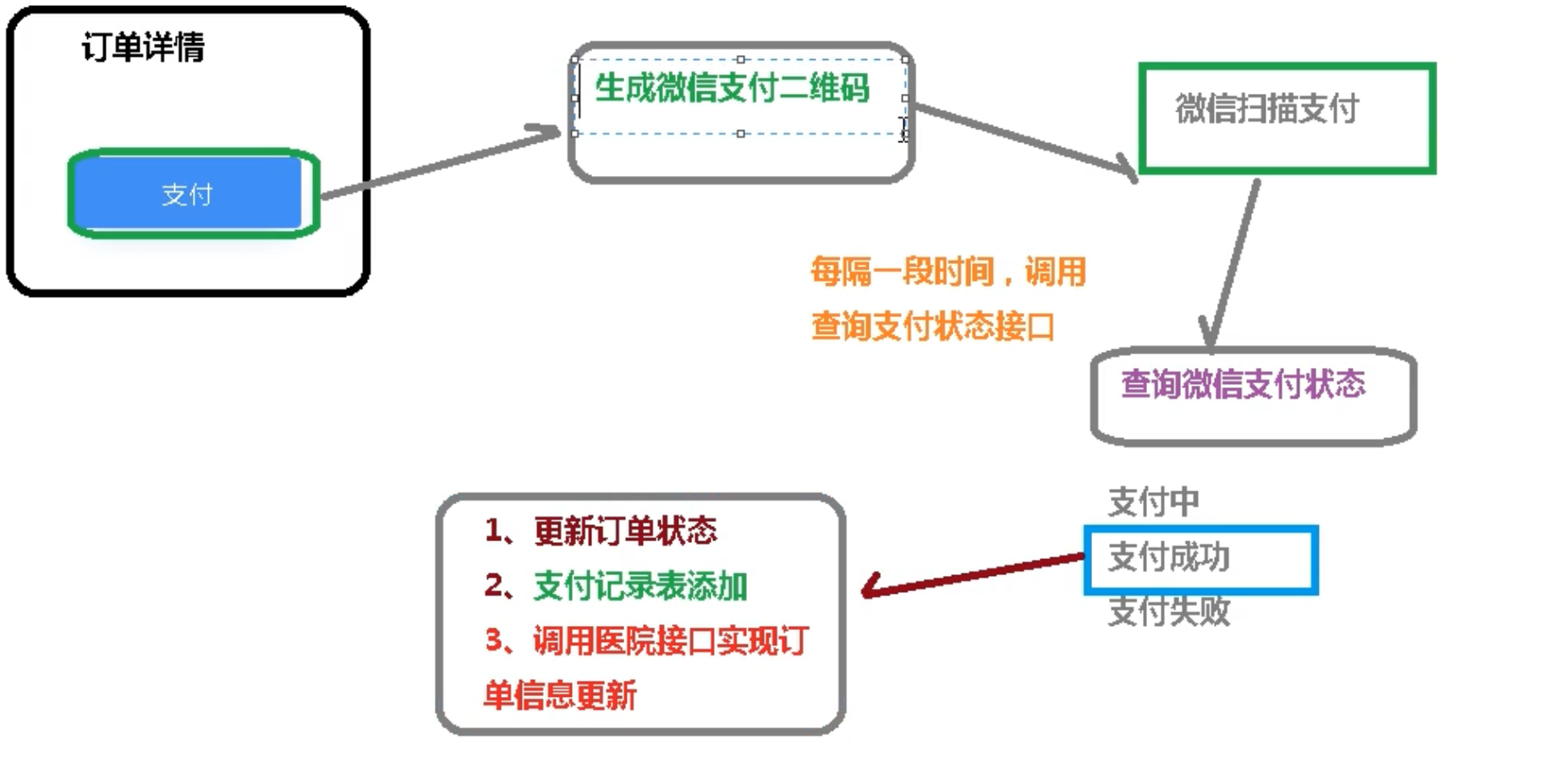
17 医疗挂号系统_【微信支付】
13 医疗挂号系统_【 微信登录】
随机推荐
软件测试工程师发展规划路线
MySQL实战优化高手06 生产经验:互联网公司的生产环境数据库是如何进行性能测试的?
MySQL实战优化高手07 生产经验:如何对生产环境中的数据库进行360度无死角压测?
What is the current situation of the game industry in the Internet world?
MySQL36-数据库备份与恢复
[after reading the series] how to realize app automation without programming (automatically start Kwai APP)
MySQL的存储引擎
A necessary soft skill for Software Test Engineers: structured thinking
flask运维脚本(长时间运行)
MySQL Real Time Optimization Master 04 discute de ce qu'est binlog en mettant à jour le processus d'exécution des déclarations dans le moteur de stockage InnoDB.
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
Advantages and disadvantages of evaluation methods
The 32-year-old fitness coach turned to a programmer and got an offer of 760000 a year. The experience of this older coder caused heated discussion
数据库中间件_Mycat总结
基于Pytorch肺部感染识别案例(采用ResNet网络结构)
MySQL实战优化高手12 Buffer Pool这个内存数据结构到底长个什么样子?
Const decorated member function problem
Anaconda3 installation CV2
How to build an interface automation testing framework?
[paper reading notes] - cryptographic analysis of short RSA secret exponents