当前位置:网站首页>基于Pytorch肺部感染识别案例(采用ResNet网络结构)
基于Pytorch肺部感染识别案例(采用ResNet网络结构)
2022-07-06 09:11:00 【一曲无痕奈何】
一、整体流程
1. 数据集下载地址:https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia/download
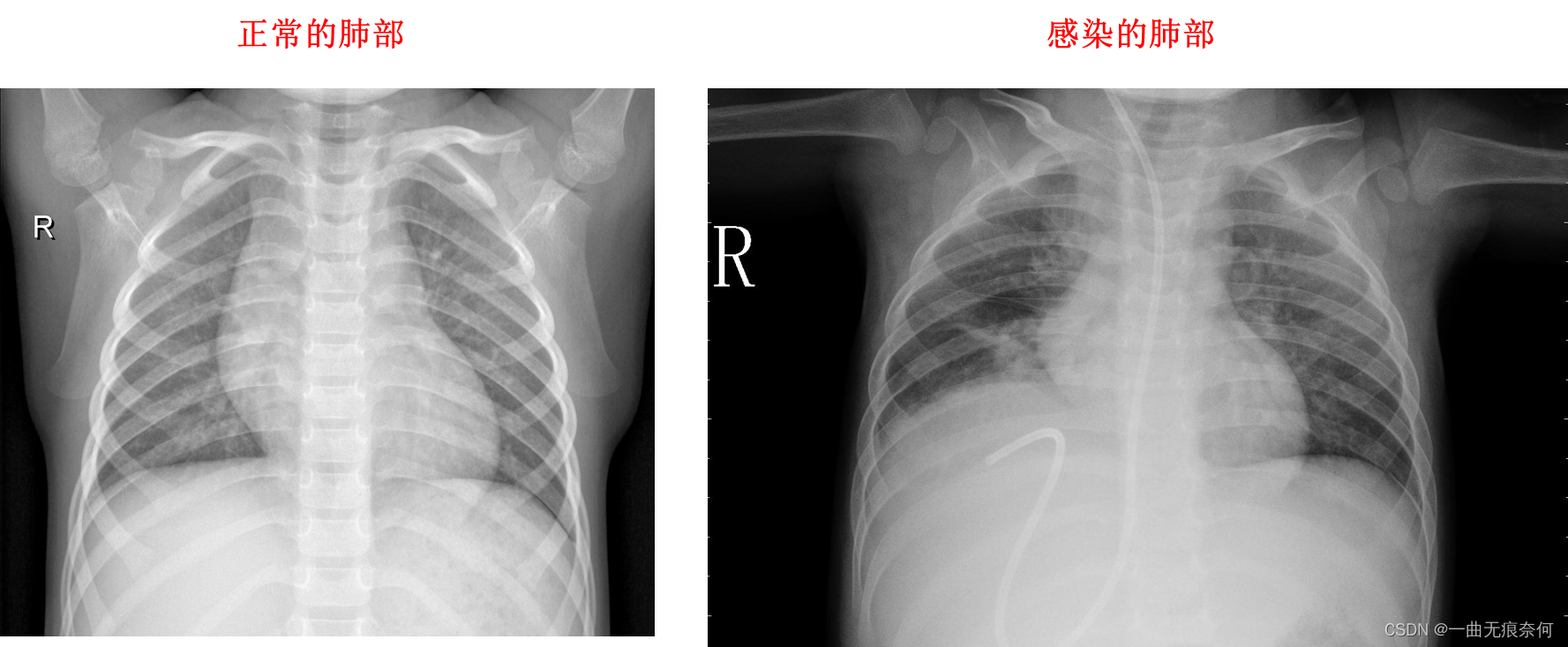
2. 数据集展示

案例主要流程:
第一步:加载预训练模型ResNet,该模型已在ImageNet上训练过。
第二步:冻结预训练模型中低层卷积层的参数(权重)。
第三步:用可训练参数的多层替换分类层。
第四步:在训练集上训练分类层。
第五步:微调超参数,根据需要解冻更多层。
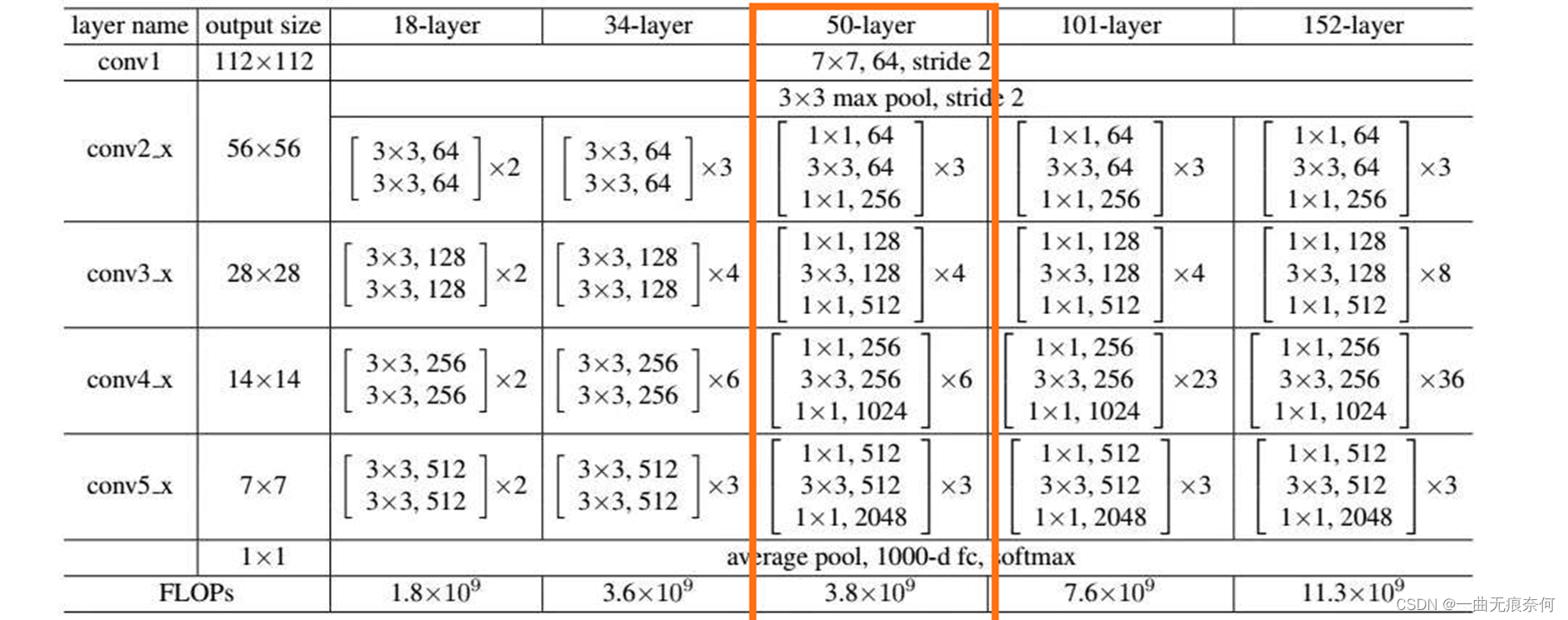
ResNet 网络结构图
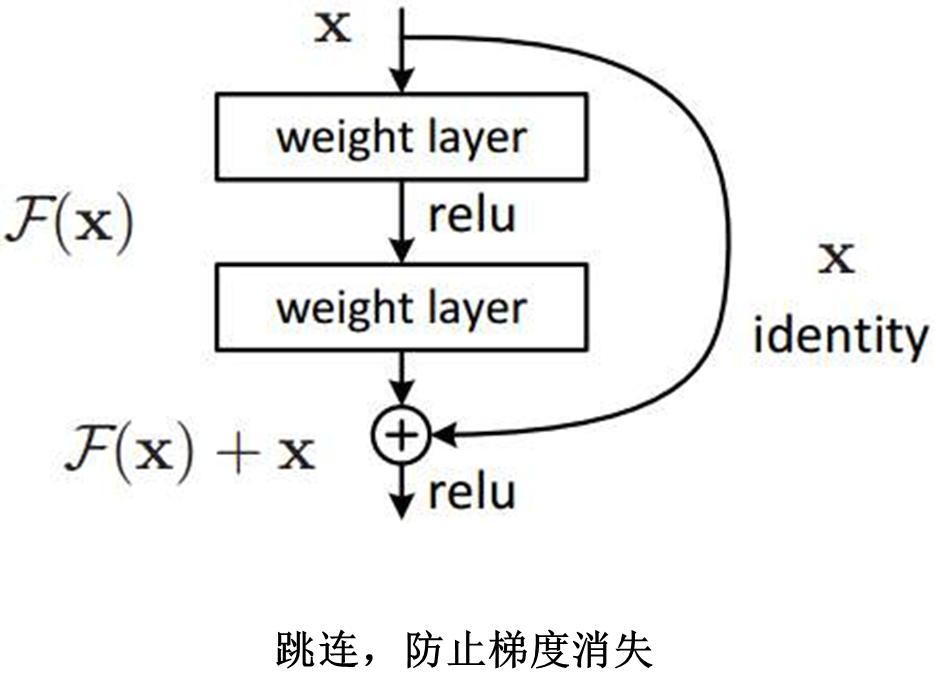
二、显示图片功能
#1加载库
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
import os
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
#2、定义一个方法:显示图片
def img_show(inp, title=None):
plt.figure(figsize=(14,3))
inp = inp.numpy().transpose((1,2,0)) #转成numpy,然后转置
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224,0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
plt.show()
def main():
pass
#3、定义超参数
BATCH_SIZE = 8
DEVICE = torch.device("gpu" if torch.cuda.is_available() else "cpu")
#4、图片转换 使用字典进行转换
data_transforms = {
'train': transforms.Compose([
transforms.Resize(300),
transforms.RandomResizedCrop(300) ,#随机裁剪
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(256),
transforms.ToTensor(), #转为张量
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) #正则化
]),
'val': transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(), #转为张量
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) #正则化
])
}
#5、操作数据集
# 5.1、数据集路径
data_path = "D:/chest_xray/"
#5.2、加载数据集的train val
img_datasets = { x : datasets.ImageFolder(os.path.join(data_path,x),
data_transforms[x]) for x in ["train","val"]}
#5.3、为数据集创建一个迭代器,读取数据
dataloaders = {x : DataLoader(img_datasets[x], shuffle=True,
batch_size= BATCH_SIZE) for x in ["train","val"]
}
# 5.4、训练集和验证集的大小(图片的数量)
data_sizes = {x : len(img_datasets[x]) for x in ["train","val"]}
# 5.5、获取标签类别名称 NORMAL 正常 -- PNEUMONIA 感染
target_names = img_datasets['train'].classes
#6 显示一个batch_size 的图片(8张图片)
#6.1 读取8张图片
datas ,targets = next(iter(dataloaders['train'])) #iter把对象变为可迭代对象,next去迭代
#6.2、将若干正图片平成一副图像
out = make_grid(datas, norm = 4, padding = 10)
#6.3显示图片
img_show(out, title=[target_names[x] for x in targets]) #title拿到类别,也就是标签呢
if __name__ == '__main__':
main()上面代码实现的功能就是展示图片样例 (未完待续)
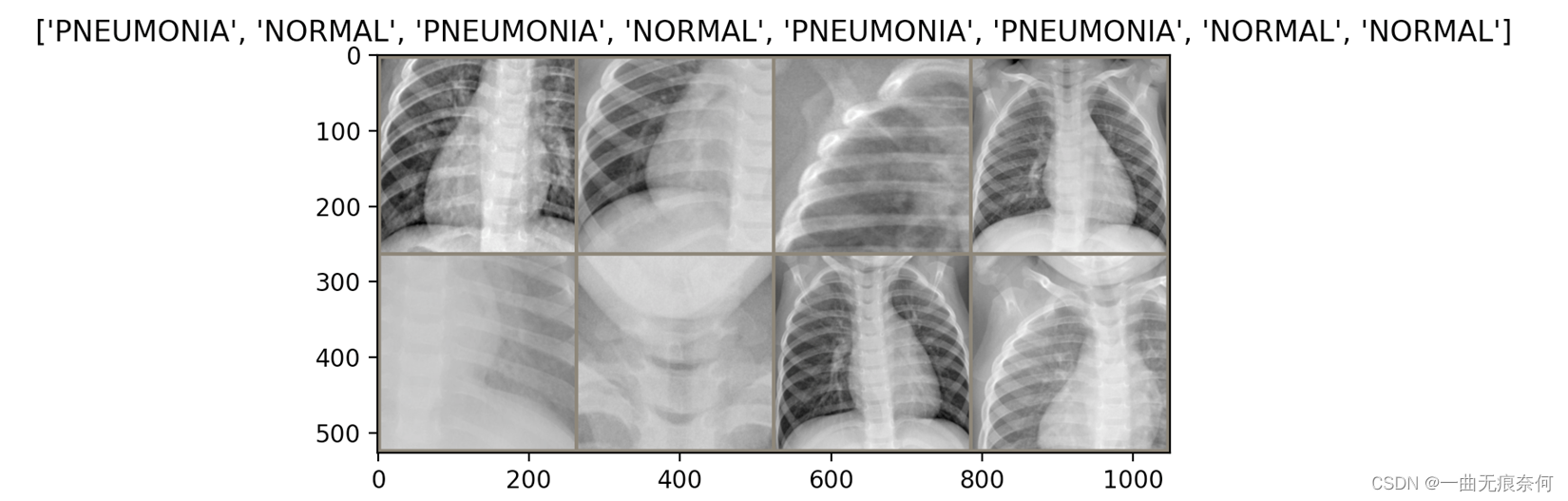
显示数据集中的图片样例:
三、迁移学习,进行模型的微调
迁移学习(Transfer learning) 就是把已经训练好的模型参数迁移到新的模型来帮助新模型训练。
后面这个代码使用Jupyter NoteBook
案例:肺部检测
# 1 加入必要的库
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, transforms, utils, models
import time
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch.utils.tensorboard.writer import SummaryWriter
import os
import torchvision
import copy
# 2 加载数据集
# 2.1 图像变化设置
data_transforms = {
"train":
transforms.Compose([
transforms.RandomResizedCrop(300),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
"val":
transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test':
transforms.Compose([
transforms.Resize(size=300),
transforms.CenterCrop(size=256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224,
0.225])
]),
}
# 3 可视化图片
def imshow(inp, title=None):
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# 6 可视化模型预测
def visualize_model(model, num_images=6):
"""显示预测的图片结果
Args:
model: 训练后的模型
num_images: 需要显示的图片数量
Returns:
无
"""
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (datas, targets) in enumerate(dataloaders['val']):
datas, targets = datas.to(device), targets.to(device)
outputs = model(datas) # 预测数据
_, preds = torch.max(outputs, 1) # 获取每行数据的最大值
for j in range(datas.size()[0]):
images_so_far += 1 # 累计图片数量
ax = plt.subplot(num_images // 2, 2, images_so_far) # 显示图片
ax.axis('off') # 关闭坐标轴
ax.set_title('predicted:{}'.format(class_names[preds[j]]))
imshow(datas.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
# 7 定义训练函数
def train(model, device, train_loader, criterion, optimizer, epoch, writer):
# 作用:声明在模型训练时,采用Batch Normalization 和 Dropout
# Batch Normalization : 对网络中间的每层进行归一化处理,保证每层所提取的特征分布不会被破坏
# Dropout : 减少过拟合
model.train()
total_loss = 0.0 # 总损失初始化为0.0
# 循环读取训练数据,更新模型参数
for batch_id, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 梯度初始化为零
output = model(data) # 训练后的输出
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 参数更新
total_loss += loss.item() # 累计损失
# 写入日志
writer.add_scalar('Train Loss', total_loss / len(train_loader), epoch)
writer.flush() # 刷新
return total_loss / len(train_loader) # 返回平均损失值
# 8 定义测试函数
def test(model, device, test_loader, criterion, epoch, writer):
# 作用:声明在模型训练时,不采用Batch Normalization 和 Dropout
model.eval()
# 损失和正确
total_loss = 0.0
correct = 0.0
# 循环读取数据
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 预测输出
output = model(data)
# 计算损失
total_loss += criterion(output, target).item()
# 获取预测结果中每行数据概率最大的下标
_,preds = torch.max(output, dim=1)
# pred = output.data.max(1)[1]
# 累计预测正确的个数
correct += torch.sum(preds == target.data)
# correct += pred.eq(target.data).cpu().sum()
######## 增加 #######
misclassified_images(preds, writer, target, data, output, epoch) # 记录错误分类的图片
# 总损失
total_loss /= len(test_loader)
# 正确率
accuracy = correct / len(test_loader)
# 写入日志
writer.add_scalar('Test Loss', total_loss, epoch)
writer.add_scalar('Accuracy', accuracy, epoch)
writer.flush()
# 输出信息
print("Test Loss : {:.4f}, Accuracy : {:.4f}".format(total_loss, accuracy))
return total_loss, accuracy
# 定义函数,获取Tensorboard的writer
def tb_writer():
timestr = time.strftime("%Y%m%d_%H%M%S")
writer = SummaryWriter('logdir/' + timestr)
return writer
# 8 模型微调
# 定义一个池化层处理函数
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super().__init__()
size = size or (1,1) # 池化层的卷积核大小,默认值为(1,1)
self.pool_one = nn.AdaptiveAvgPool2d(size) # 池化层1
self.pool_two = nn.AdaptiveMaxPool2d(size) # 池化层2
def forward(self, x):
return torch.cat([self.pool_one(x), self.pool_two(x)], 1) # 连接两个池化层
def get_model():
model_pre = models.resnet50(pretrained=True) # 获取预训练模型
# 冻结预训练模型中所有参数
for param in model_pre.parameters():
param.requires_grad = False
# 替换ResNet最后的两层网络,返回一个新的模型(迁移学习)
model_pre.avgpool = AdaptiveConcatPool2d() # 池化层替换
model_pre.fc = nn.Sequential(
nn.Flatten(), # 所有维度拉平
nn.BatchNorm1d(4096), # 正则化处理
nn.Dropout(0.5), # 丢掉神经元
nn.Linear(4096, 512), # 线性层处理
nn.ReLU(), # 激活函数
nn.BatchNorm1d(512), # 正则化处理
nn.Dropout(p=0.5), # 丢掉神经元
nn.Linear(512, 2), # 线性层
nn.LogSoftmax(dim=1) # 损失函数
)
return model_pre
def train_epochs(model, device, dataloaders, criterion, optimizer, num_epochs, writer):
"""
Returns:
返回一个训练过后最好的模型
"""
print("{0:>20} | {1:>20} | {2:>20} | {3:>20} |".format('Epoch', 'Training Loss', 'Test Loss', 'Accuracy'))
best_score = np.inf # 假设最好的预测值
start = time.time() # 开始时间
# 开始循环读取数据进行训练和验证
for epoch in num_epochs:
train_loss = train(model, device, dataloaders['train'], criterion, optimizer, epoch, writer)
test_loss, accuracy = test(model, device, dataloaders['val'], criterion, epoch, writer)
if test_loss < best_score:
best_score = test_loss
torch.save(model.state_dict(), model_path) # 保存模型 # state_dict变量存放训练过程中需要学习的权重和偏置系数
print("{0:>20} | {1:>20} | {2:>20} | {3:>20.2f} |".format(epoch, train_loss, test_loss, accuracy))
writer.flush()
# 训练完所耗费的总时间
time_all = time.time() - start
# 输出时间信息
print("Training complete in {:.2f}m {:.2f}s".format(time_all // 60, time_all % 60))
def train_epochs(model, device, dataloaders, criterion, optimizer, num_epochs, writer):
"""
Returns:
返回一个训练过后最好的模型
"""
print("{0:>20} | {1:>20} | {2:>20} | {3:>20} |".format('Epoch', 'Training Loss', 'Test Loss', 'Accuracy'))
best_score = np.inf # 假设最好的预测值
start = time.time() # 开始时间
# 开始循环读取数据进行训练和验证
for epoch in num_epochs:
train_loss = train(model, device, dataloaders['train'], criterion, optimizer, epoch, writer)
test_loss, accuracy = test(model, device, dataloaders['val'], criterion, epoch, writer)
if test_loss < best_score:
best_score = test_loss
torch.save(model.state_dict(), model_path) # 保存模型 # state_dict变量存放训练过程中需要学习的权重和偏置系数
print("{0:>20} | {1:>20} | {2:>20} | {3:>20.2f} |".format(epoch, train_loss, test_loss, accuracy))
writer.flush()
# 训练完所耗费的总时间
time_all = time.time() - start
# 输出时间信息
print("Training complete in {:.2f}m {:.2f}s".format(time_all // 60, time_all % 60))
def misclassified_images(pred, writer, target, data, output, epoch, count=10):
misclassified = (pred != target.data) # 记录预测值与真实值不同的True和False
for index, image_tensor in enumerate(data[misclassified][:count]):
# 显示预测不同的前10张图片
img_name = '{}->Predict-{}x{}-Actual'.format(
epoch,
LABEL[pred[misclassified].tolist()[index]],
LABEL[target.data[misclassified].tolist()[index]],
)
writer.add_image(img_name, inv_normalize(image_tensor), epoch)
# 9 训练和验证
# 定义超参数
model_path = 'model.pth'
batch_size = 16
device = torch.device('gpu' if torch.cuda.is_available() else 'cpu') # gpu和cpu选择
# 2.2 加载数据
data_path = "D:/chest_xray/" # 数据集所在的文件夹路径
# 2.2.1 加载数据集
image_datasets = {x : datasets.ImageFolder(os.path.join(data_path, x), data_transforms[x]) for x in ['train', 'val', 'test']}
# 2.2.2 为数据集创建iterator
dataloaders = {x : DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'val', 'test']}
# 2.2.3 训练集和验证集的大小
data_sizes = {x : len(image_datasets[x]) for x in ['train', 'val', 'test']}
# 2.2.4 训练集所对应的标签
class_names = image_datasets['train'].classes # 一共有2个:NORMAL正常 vs PNEUMONIA肺炎
LABEL = dict((v, k ) for k, v in image_datasets['train'].class_to_idx.items())
print("-" * 50)
# 4 获取trian中的一批数据
datas, targets = next(iter(dataloaders['train']))
# 5 显示这批数据
out = torchvision.utils.make_grid(datas)
imshow(out, title=[class_names[x] for x in targets])
# 将tensor转换为image
inv_normalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.255]
)
writer = tb_writer()
images, labels = next(iter(dataloaders['train'])) # 获取一批数据
grid = torchvision.utils.make_grid([inv_normalize(image) for image in images[:32]]) # 读取32张图片
writer.add_image('X-Ray grid', grid, 0) # 添加到TensorBoard
writer.flush() # 将数据读取到存储器中
model = get_model().to(device) # 获取模型
criterion = nn.NLLLoss() # 损失函数
optimizer = optim.Adam(model.parameters())
train_epochs(model, device, dataloaders, criterion, optimizer, range(0,10), writer)
writer.close()
# 9 训练和验证
# 定义超参数
model_path = 'model.pth'
batch_size = 16
device = torch.device('gpu' if torch.cuda.is_available() else 'cpu') # gpu和cpu选择
# 2.2 加载数据
data_path = "D:/chest_xray/" # 数据集所在的文件夹路径
# 2.2.1 加载数据集
image_datasets = {x : datasets.ImageFolder(os.path.join(data_path, x), data_transforms[x]) for x in ['train', 'val', 'test']}
# 2.2.2 为数据集创建iterator
dataloaders = {x : DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'val', 'test']}
# 2.2.3 训练集和验证集的大小
data_sizes = {x : len(image_datasets[x]) for x in ['train', 'val', 'test']}
# 2.2.4 训练集所对应的标签
class_names = image_datasets['train'].classes # 一共有2个:NORMAL正常 vs PNEUMONIA肺炎
LABEL = dict((v, k ) for k, v in image_datasets['train'].class_to_idx.items())
print("-" * 50)
# 4 获取trian中的一批数据
datas, targets = next(iter(dataloaders['train']))
# 5 显示这批数据
out = torchvision.utils.make_grid(datas)
imshow(out, title=[class_names[x] for x in targets])
# 将tensor转换为image
inv_normalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.255]
)
writer = tb_writer()
images, labels = next(iter(dataloaders['train'])) # 获取一批数据
grid = torchvision.utils.make_grid([inv_normalize(image) for image in images[:32]]) # 读取32张图片
writer.add_image('X-Ray grid', grid, 0) # 添加到TensorBoard
writer.flush() # 将数据读取到存储器中
model = get_model().to(device) # 获取模型
criterion = nn.NLLLoss() # 损失函数
optimizer = optim.Adam(model.parameters())
train_epochs(model, device, dat 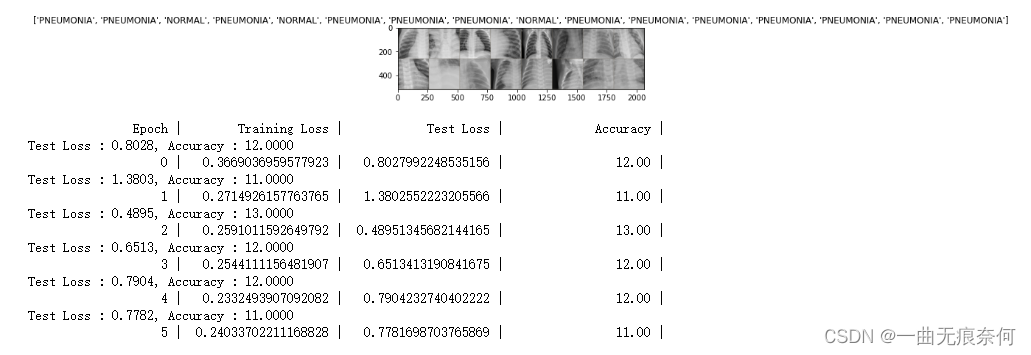
边栏推荐
- UEditor国际化配置,支持中英文切换
- Delayed note learning
- Contest3145 - the 37th game of 2021 freshman individual training match_ C: Tour guide
- Super detailed steps for pushing wechat official account H5 messages
- 百度百科数据爬取及内容分类识别
- The appearance is popular. Two JSON visualization tools are recommended for use with swagger. It's really fragrant
- What should the redis cluster solution do? What are the plans?
- 15 医疗挂号系统_【预约挂号】
- C杂讲 文件 初讲
- 如何让shell脚本变成可执行文件
猜你喜欢
Not registered via @enableconfigurationproperties, marked (@configurationproperties use)
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd0 in position 0成功解决
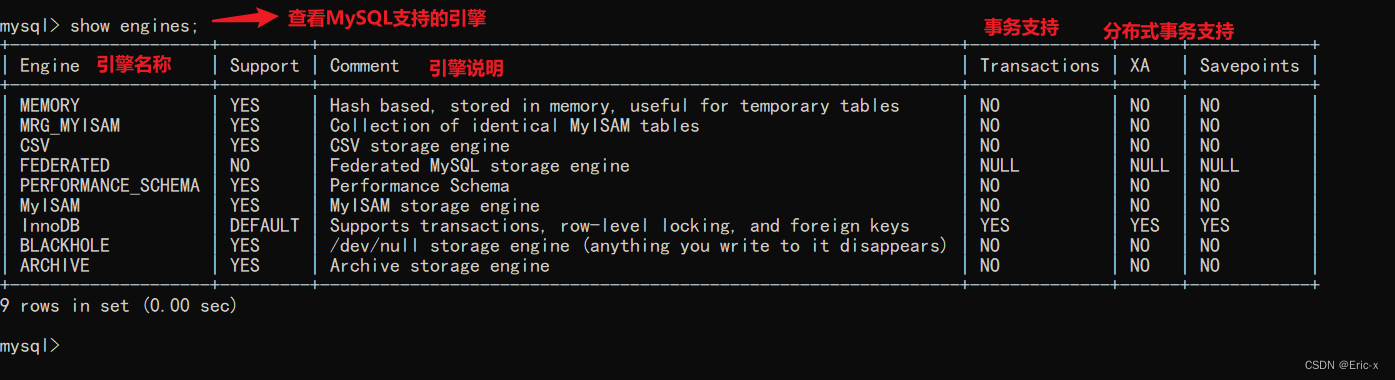
The underlying logical architecture of MySQL
cmooc互联网+教育

Sichuan cloud education and double teacher model
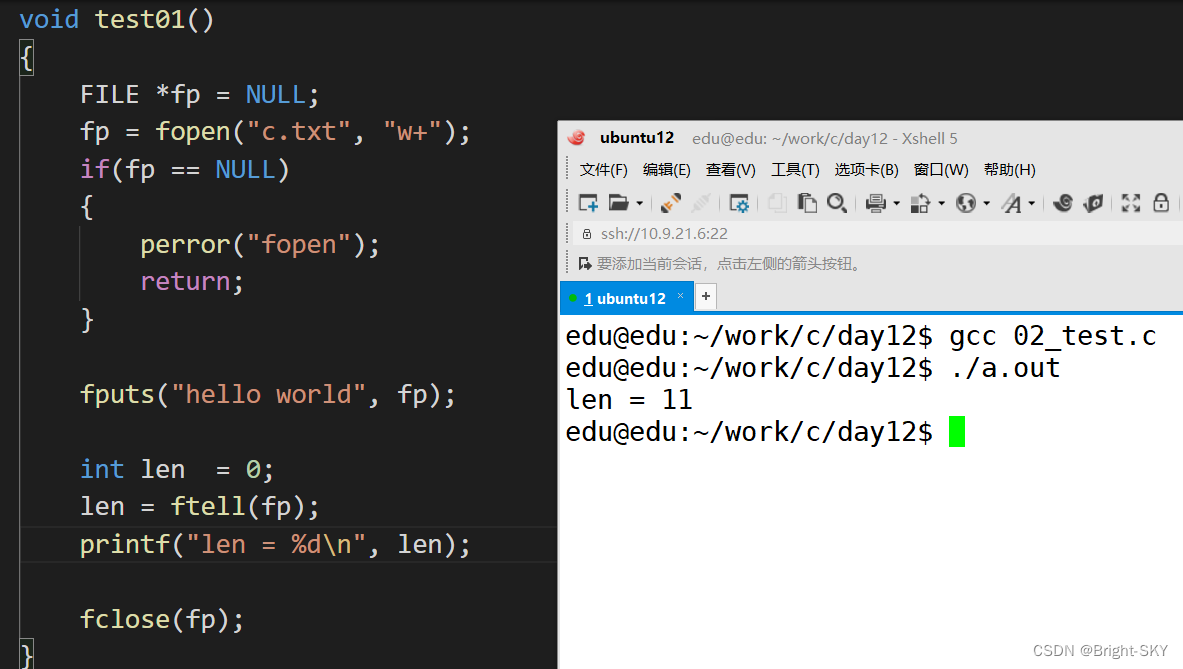
C杂讲 文件 续讲
Contrôle de l'exécution du module d'essai par panneau dans Canoe (primaire)

如何让shell脚本变成可执行文件
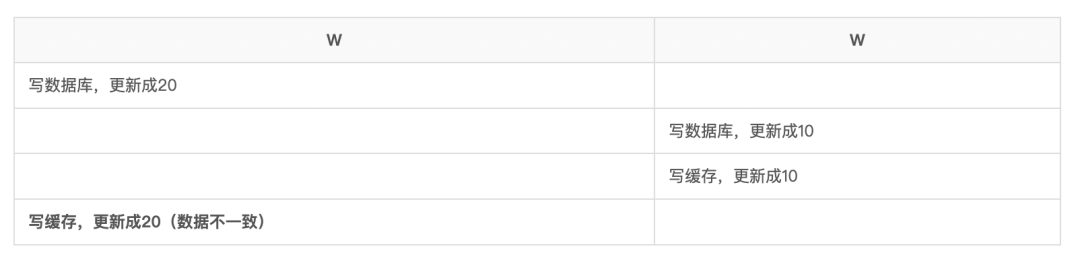
再有人问你数据库缓存一致性的问题,直接把这篇文章发给他
Redis集群方案应该怎么做?都有哪些方案?
随机推荐
Vh6501 Learning Series
[flask] crud addition and query operation of data
History of object recognition
MySQL real battle optimization expert 11 starts with the addition, deletion and modification of data. Review the status of buffer pool in the database
MySQL real battle optimization expert 08 production experience: how to observe the machine performance 360 degrees without dead angle in the process of database pressure test?
Use xtrabackup for MySQL database physical backup
解决在window中远程连接Linux下的MySQL
百度百科数据爬取及内容分类识别
简单解决phpjm加密问题 免费phpjm解密工具
Control the operation of the test module through the panel in canoe (primary)
text 文本数据增强方法 data argumentation
Mexican SQL manual injection vulnerability test (mongodb database) problem solution
14 医疗挂号系统_【阿里云OSS、用户认证与就诊人】
If someone asks you about the consistency of database cache, send this article directly to him
MySQL實戰優化高手08 生產經驗:在數據庫的壓測過程中,如何360度無死角觀察機器性能?
112 pages of mathematical knowledge sorting! Machine learning - a review of fundamentals of mathematics pptx
Not registered via @EnableConfigurationProperties, marked(@ConfigurationProperties的使用)
MySQL实战优化高手05 生产经验:真实生产环境下的数据库机器配置如何规划?
Preliminary introduction to C miscellaneous lecture document
Good blog good material record link